MySQL浅谈

存储引擎
“存储”的意思的存储数据。“引擎”源于发动机,它是发动机中的核心,故可以理解成 它是数据库的核心(比较尬......)。
常见的Mysql存储引擎:
Innodb引擎(5.5版本之后Mysql默认引擎):
Innodb引擎提供了对数据库ACID事务的支持,并且还提供了行级锁和外键的约束
四大特性:
-
插入缓冲(insert buffer)
-
二次写(double write)
-
自适应哈希索引(ahi)
-
预读(read ahead)
而且InnoDB 实现了 SQL 的四种隔离级别,默认是 REPEATABLE READ
SQL四种隔离级别:
READ UNCOMMITED(未提交读)
在RERAD UNCOMMITED级别,事务中的修改,即使没有提交,对其他事务也都是可见的。事务可以读取未提交的数据,这也成为脏读。这种隔离级别性能极快,但无法应用。
READ COMMITED (不可重复读)
大多数数据库系统的默认隔离级别都是READ COMMITED(比如 oracle、sqlserver)。READ COMMITED 满足前面提到的隔离性的简单定义:一个事务开始时,只能看到已经提交的事务所做的修改。简而言之就是一个事务从开始到提交之前,所做的任何修改对其他事务都是不可见的,导致两次执行同样的查询,可能会得到不一样的结果。
REPEATABLE READ (可重复读)
REPEATABLE READ (可重复读) 解决了脏读问题。该级别保证了在同一个事务中多次读取同样的记录的结果是一致的。可重复读隔离级别无法解决幻读的问题。幻读指的是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读 取该范围的记录时,会产生幻行。InnoDB存储引擎通过多版并发控制解决了幻读问题。
可重复读(REPEATABLE READ)是Mysql 默认的事务隔离级别,其中InnoDB主要通过使用MVVC【多版本并发控制(Multi-Version Concurrency Control, MVCC)ps:具体实现原理可以自行百度,需仔细研读,初读基本上都是云里雾里】 支撑高并发,使用Next-Key Locking的策略来避免幻读。
SERIALIZABLE(可串行化)
SERIALIZABLE是最高的隔离级别。它通过强制事务串行,避免了前面说的幻读问题。,SERIALIZABLE简单粗暴会在读的每一行数据上都加上锁,必然会导致大量的超时和锁竞争问题。实际应用中也很少用到这个隔离级别,没有并发和数据一致性的强烈要求才会用到。
再延伸聊一聊事务:

原子性(Atomicity): 事务是最小的执行单位,不允许分割。要么全部成功,要么全部回滚;
一致性(Consistency): 数据在执行事务前后保持一致性,多个事务对同一个数据读取的结果是相同的;
隔离性(Isolation): 一个事务在提交之前对于其他事务都是不可见的(你看不见我....)
持久性(Durability): 一个事务被提交之后。它对数据库中数据的改变是持久的,数据库挂了或者重启对我没有影响,事务满足持久化是为了能应对数据库崩溃的情况。
ACID非平级关系,看似简单,其实水很深......

MyIASM引擎(5.5版本之前Mysql默认引擎):不提供事务的支持,只支持表级锁,没有行级锁,优点是占用空间小,处理系统快。
MEMORY引擎(演示系统可用):所有的数据都在内存中,数据处理极快,但系统重启或者断电就无了......
常问MyISAM与InnoDB区别:
InnoDB 是事务型的,可以使用 Commit 和 Rollback 语句,而且还支持行级锁和外键,但MyISAM不支持,只支持表级锁。MyISAM在查询上比InnoDB更快,但是在INSERT、UPDATE、DELETE稍逊一筹。MyISAM 支持压缩表和空间数据索引,InnoDB的表需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。
说到这,来聊一聊索引.....
什么是索引?
索引是一种特殊的文件(InnoDB的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。简单的说 索引就是数据库的目录,索引的实现通常使用B树及B+树。
索引优缺点?
优点:可以大大加快数据的检索速度,在查询的过程中提高系统性能
缺点:需要消耗时间去创建和维护索引,且索引会占据物理空间
聚簇索引和非聚簇索引
何为“聚簇”,意思就是数据行被按照一定顺序一个个紧密地排列在一起存储。
通常一个表只能有一个聚簇索引,在聚簇索引中,叶子结点即存储了真实的数据行,不再有另外单独的数据页
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = ‘张三’"去查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
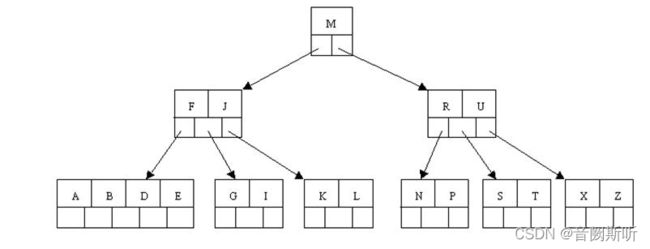
Innodb中聚簇索引的结构如图:

聚簇索引不适用于频繁更新的列、频繁修改的索引列和小数目的不同值
非聚簇索引:非聚簇索引的叶子节点仍然是索引文件,只是这个索引文件中包含指向对应数据块的指针,当通过非聚簇索引查找行,存储引擎需要在非聚簇索引中找到相应的叶子节点,获得行的主键值,然后使用主键去聚簇索引中查找数据行,这需要两次B-Tree查找。
说到这,不得不提下B-Tree......

B-Tree是为磁盘等外存储设备设计的一种平衡查找树:
磁盘IO时间
磁盘读取依靠的是机械运动,分为寻道时间、旋转延迟、传输时间,三个部分耗时相加就是一次磁盘IO的时间。因为一次磁盘IO的时间大概未9ms,所以计算采用了一种方式:预读;
预读
每一次IO时,不仅仅把当前磁盘地址的数据加载到内存,同时也把相邻数据也加载到内存缓冲区中。
B-Tree的特性:
①每个节点最多拥有m个子树
②有叶子节点都在同一层、每个节点最多可以有m-1个key,并且以升序排列
③根节点至少有2个子树
上图就透彻了
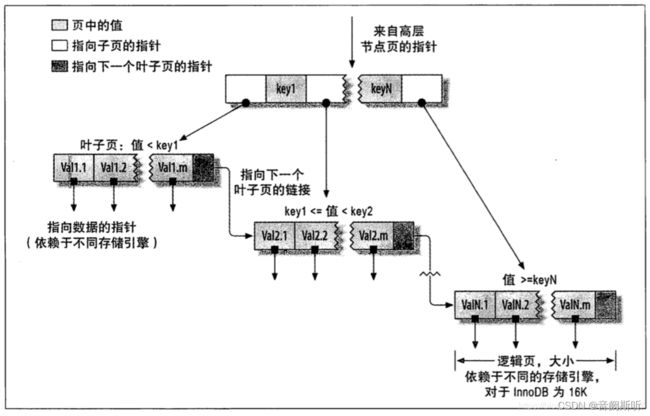
B+TREE(B树的变种,查询性能更优,InnoDB存储引擎就是用B+Tree实现其索引结构)的特性:
①所有叶子节点之间都有一个链指针
②所有分支节点和根节点都同时存在于子节点中,在子节点元素中是最大或者最小的元素
③根节点和分支节点中不保存数据,只用于索引,所有数据都保存在叶子节点中
还是不多说,上图......
想要了解更多的可以看下《高性能 MySQL》......书中自有黄金屋~
B树和B+树的区别
-
在B树中,你可以将键和值存放在内部节点和叶子节点;但在B+树中,内部节点都是键,没有值,叶子节点同时存放键和值。
-
B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。
问平时开发建立索引有哪些注意点:
①最左前缀原则
(最左优先,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配)
②有外键的数据列一定要建立索引
③频繁作为查询条件的字段才去创建索引
④数据类型为text,bit的字段或更新频繁字段没必要建立索引
使用索引势必会带来需要定期维护的代价,而且不必要的索引还会导致查询变慢,得不偿失~

最后提一下MySQL的悲观锁和乐观锁:
悲观锁:需要依靠数据库提供的锁机制,在对记录进行修改前,先尝试为该记录加上排他锁,如果失败则表明该条记录正在被修改,只有等待其修改完成或者处理异常,如果成功,则该条记录就在事务完成之后自动解锁。考虑到MySQL默认使用autocommit模式,需要关闭才可使用悲观锁。
常见问题: select ...from .. for update 可能会导致整张表锁住,如果查询的列没有使用索引,行级锁不生效,Mysql会使用表级锁直接锁表--
乐观锁:常见实现方式CAS(Compare and Swap),CAS应该大家算比较熟悉的就是
多个线程尝试修改数据时只允许一个线程修改记录,其他的线程可再次尝试~
so 就带来了经典问题 ABA问题(不会还有人不知道吧~ 度娘)
解决方案: version控制、时间戳~ 它们有共同的特性就是顺序递增
电商系统应该极少使用悲观锁,其他并发量较低的系统可以考虑使用悲观锁,因为乐观锁并未真正加锁,使用不当会导致更新失败的概率变大,导致系统的不稳定就得不偿失啦~
