数据架构最新趋势:Data Fabric 和 Data Mesh (值得收藏)
近日,有幸受邀参与全球Data Architect Summit 2022, Data Fabric 和 Data Mesh作为当前行业的热点,在会上引起了广泛的讨论。借此机会谈谈对这两个热门数据架构的看法。
首先,从传统Data Hub ( 中央强管控模式)到Data Fabric与Data Mesh这两种新型数据架构发生了哪些变革?
-
Data Hub通过中央强管控schema-on-wirte,适用于大部分RDBMS为后台的系统。
-
Data Fabric通过中央协作,对于采用NewSQL数据库schemaless无法进行强管控,以schema-on-read的模式针对Active Metadata进行管理。
-
Data Mesh分而治之,按业务领域拆分,基于业务领域的数据产品和元数据进行领域间的交互。

由上图可以看出,Data Fabric与Data Mesh是截然不同的。Data Fabric仍然是基于中心化,以智能化的Active Metadata为核心来支撑复杂的数据治理。而Data Mesh是将数据治理拆分到各业务领域,分而治之,分别产出业务领域的数据产品。
Data Fabric
近几年,Forrester和Gartner均对Data Fabric密切关注。由下图可见,Data Fabric核心是Active Metadata, 即通过增强学习和知识图谱建立Active Metadata支撑数据集成与数据分析。
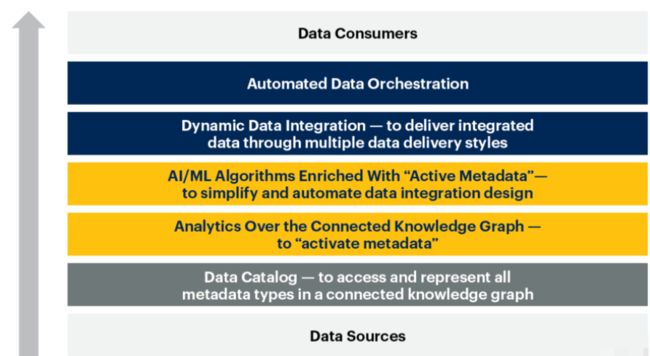
这里的“主动元数据”是相对传统的“被动元数据”有意差异化的,传统元数据被采集之后、通过简单地搜索和查询场景来支撑使用。但元数据自身是可以再次进行深度挖掘。例如,基于关联度线索做出有价值的推荐,提高数据可信度,进一步支撑数据开发和数据编排。所以,数据编排智能化与数据虚拟化也是Data Fabric的重要组成部分。
Data Fabric数据架构方法论由一系列工具组合来落地,由专业的人用专业的工具来解决特定场景的问题,包括:
1. 定位可信数据的数据资产目录
2. 基于知识图谱激活元数据
3. 基于机器学习形成Active Metadata以指导和简化数据集成
4. 动态数据集成(这里包括数据虚拟化技术)
5. 自动数据加工编排

落地工具
Datablau DDC数据资产目录管理平台,早在2020发布的V5.0就已经具备了基于知识图谱的数据资产管理模块,通过知识图谱进行增强学习,提升数据资产关联度和可信度。同时,基于知识图谱智能推荐数据资产标签和数据安全分类分级。

Data Mesh
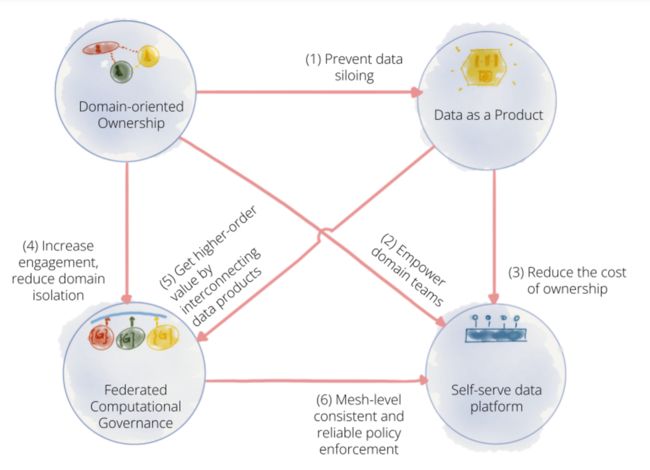
Data Mesh由Thoughtworks的技术顾问 Zhamak Dehghani 于一年多前提出,从DDD领域驱动设计(用于开发微服务)、DevOps(自动化和自助服务基础设施)中汲取灵感,并将其应用于数据世界。鉴于Data Mesh是咨询公司提出来的,所以更多是一种思想和方法论。Data Mesh强调打破数据湖的模式,不建议先汇集再治理,而是缩小每个业务领域的业务运营和分析之间的差距,重新调整数据的产生方式和消费方式,来设计更可靠的数据平台。
Data Mesh是以数据产品为单元,每个数据产品定义为公司已经治理好的数据源,每个数据产品具有专门的所有权、生命周期管理和服务水平协议。通过设计、治理、开发将数据产品呈现给组织的其他成员,供其他团队使用,从而为在整个组织中共享数据提供值得信赖的来源。可以简单理解为治理好、管控好的数据集。
Data Fabric与Data Mesh的差异比较
实际上,不同的公司基于自身的数据特征(数据量、数据敏捷度、数据类型等)、安全策略、技术储备、性能要求、资金成本等, 对于Data Fabric或Data Mesh会有不同的落地方案。总之,Data Mesh更多地是关注于人和过程而不是技术架构,而Data Fabric是一种技术架构方法,它以一种智能的方式来应对数据和元数据的复杂性。

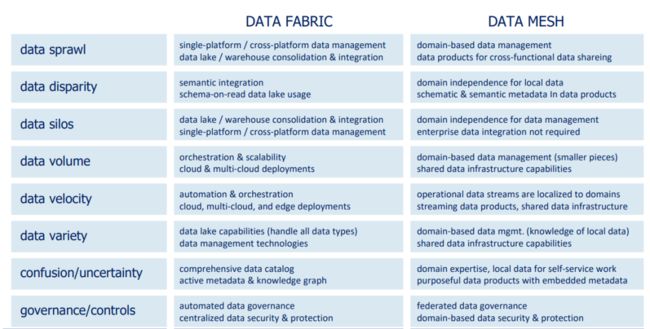
下面从更细的维度,对Data Fabric与Data Mesh进行详细分析。 可以看到Data Mesh更强调基于业务领域。 而Data Fabric试图依赖中心化的数据湖与数据资产目录。
下面是引入Data Mesh前后的架构图,可以看到基于业务领域进行数据治理,开放分享治理好的数据产品,数据产品用来补充和支撑各种数据应用场景。

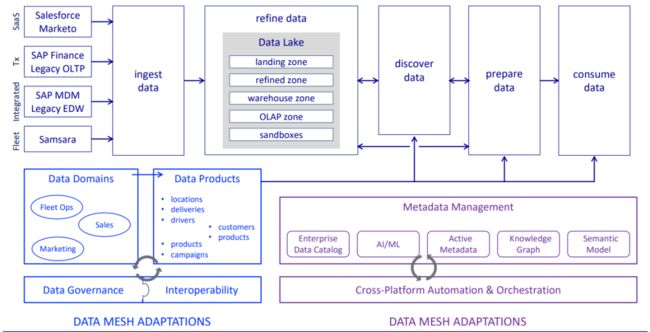
总结
在我看来,华为今天数据管理的形态与Data Mesh有异曲同工之处。业务部门驱动,流程IT作为赋能部门,以项目制帮助业务线构建数据底座,也有不少数据能力强的业务部门直接就“自给自足”。最终构建了一个个Data Domain & Data Product(业务领域数据产品),以业务线为单位从源端进行数据治理。
对于国内大多数企业来讲,距离走上Data Mesh这条路还很长。业务部门对数据重要性的认知,对数据价值的认识,及对保护企业数据资产的意识还很薄弱,更缺乏治理和挖掘数据资产价值的紧迫感。当前仍然停留在IT部门和数据传统部门建系统的阶段,业务部门还是被动配合,远不具备自己构建业务领域数据产品的动力和能力。
而Data Fabric更贴合国内当前阶段的建设思路:基于强管控、大集中的模式,不断优化元数据的上下文内容和关联关系,加速数据开发过程。国内对数据资产目录认知仍然是“被动元数据”,而且偏重管理视角,却很少从提升数据的使用效率和数据质量的角度去考虑数据资产目录的能力。从数据资源目录到数据资产目录,从“被动元数据”到“主动元数据”还有巨大的提升空间。
原创作者:
王琤 Allen Datablau 创始人兼CEO
曾任CA ERwin全球研发负责人,2006年加入CA,十几年经验在数据建模领域,客户多来自世界500强、美国银行(BOA)、SunTrust、AT&T、壳牌等深度参与建设银行新一代系统数据模型设计。多项专利和论文关于统一(关系型与非关系型)数据建模。复旦大学、北京航空航天大学 客座讲师。IEEE member、 OMG member、DAMA member。