数据优化——分库分表(三)中间件讲解
数据优化——分库分表(一)概念及运用场景-详解
数据优化——分库分表(二)策略讲解
数据优化——分库分表(四)高级策略
1 中间件的类型
1.1 PROXY模式
相当于把中间件作为一个独立的服务了,它将接收到的SQL 语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
1.2 CLIENT模式
中间件在Driver或者连接池的基础之上,增加了一层封装。我们使用时,以Java开发为例,需要先引入一个jar包。中间件接收持久层产生的sql,同样对sql进行分析等操作,然后才落实到具体的库上。
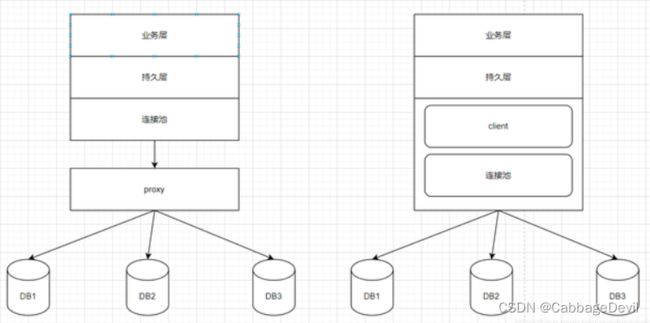
1.3 区别
- proxy模式需要部署多节点服务,增加了网络IO,影响到了性能,但是对代码基本没有入侵性,方便易用。
- client模式与其相反,不影响到性能,但是对代码有入侵性,需要管理配置。
2 中间件的简单介绍
中间件世面上很多,按上面的规则做了一下简单的分类和介绍

2.1 proxy模式
- mysql-proxy
mysql-proxy是mysql官方提供的mysql中间件服务,上游可接入若干个mysql-client,后端可连接若干个mysql-server。很多中间件都基于它进行了魔改。
- cobar(Alibaba)
Cobar 是由 Alibaba 开源的 MySQL 分布式处理中间件,它可以在分布式的环境下看上去像传统数据库一样提供海量数据服务。不过最近的一次维护也是两年前的事了。
- mycat
mycat是在cobar基础上研发出来的,对 cobar 的代码进行了彻底的重构,使用 NIO 重构了网络模块,并且优化了 Buffer 内核,增强了聚合,Join 等基本特性,同时兼容绝大多数数据库成为通用的数据库中间件。
- drds
阿里云分布式关系型数据库服务 Distributed Relational Database Service ,前身是 TDDL。似乎现在又升级了变为PolarDB-X,具体看看他们的文档了。
- sharding-sphere
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。
- atlas
Atlas 是由 360 Web平台部基础架构团队开发维护的一个基于 MySQL 协议的数据中间层项目。它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用 Atlas 运行的 MySQL 务,每天承载的读写请求数达几十亿条。
- heisenberg
百度的熊照大佬编写的一款基于MySQL协议之上的分库分表中间件服务器,支持各种灵活(velocity脚本自定义)的分库分表规则,做到应用和分库分表相隔离。
- Oceanus
58同城数据库中间件,按其官方的描述,致力于打造一个功能简单、可依赖、易于上手、易于扩展、易于集成的解决方案,甚至是平台化系统。文档链接如下:
- Vitess
Vitess一直为YouTube所有的数据库提供服务,据其官方描述,它是一款用于部署、扩展和管理大型MySQL实例集群的数据库解决方案。
- OneProxy
OneProxy是由原支付宝首席架构师楼方鑫大佬开发,保留了 MySQL-Proxy 0.8.4官方版本上其协议处理和软件框架,然后对软件做了大量优化,极大增强了系统的并发能力。
2.2 client模式
- TDDL(Taobao Distributed Data Layer)
淘宝根据自己的业务特点开发了TDDL(Taobao Distributed Data Layer )框架,别名 “头都大了”,主要解决了分库分表对应用的透明化以及异构数据库之间的数据复制。基于JDBC规范,没有server,以client-jar的形式存在,引⼊项⽬即可使⽤。开源功能⽐较少,阿⾥内部使⽤为主。
- sharding-jdbc(apache)
据官网描述,定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- zebra(美团点评)
Zebra是一个基于JDBC API协议上开发出的高可用、高性能的数据库访问层解决方案,是美团点评内部使用的数据库访问层中间件。
- zdal(支付宝)
Zdal是支付宝自主研发的数据中间件产品,也是采用标准的JDBC规范。Zdal主要提供分库分表,结果集合并,sql解析,数据库failover动态切换等功能,提供互联网金融行业的数据访问层统一解决方案,目前已经在支付宝的交易,支付,会员,金融等大部分关键应用上使用,并且在2013年双11大促中运行稳定。
3 通常使用之sharding和mycat的详细介绍
举例这两个是因为sharding是代表“client模式”,mycat是代表“proxy模式”,也是平时我们项目中使用到比较多的中间件之一。
官网: https://shardingsphere.apache.org/
3.1 sharding生态
上面说sharding代表“client模式”,其实是也不是,准确的来说是sharding-jdbc代表“client模式”,而sharding其实是一个技术生态。
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。 它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它通过关注不变,进而抓住事物本质。关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、多数据副本、数据加密、影子库压测等功能,以及 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。 开发者能够像使用积木一样定制属于自己的独特系统。Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,仍在不断增加中。
ShardingSphere 已于2020年4月16日成为 Apache 软件基金会的顶级项目。
3.1.1 sharding-jdbc
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。

3.1.2 sharding-proxy
其实sharding-proxy与mycat一样,都是“proxy模式”,所以说sharding是一个生态。不仅仅是只有“client模式”的sharding-jdbc。它定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL/PostgreSQL版本,它可以使用任何兼容MySQL/PostgreSQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat等)操作数据,对DBA更加友好。
- 向应用程序完全透明,可直接当做MySQL/PostgreSQL使用。
- 适用于任何兼容MySQL/PostgreSQL协议的的客户端。
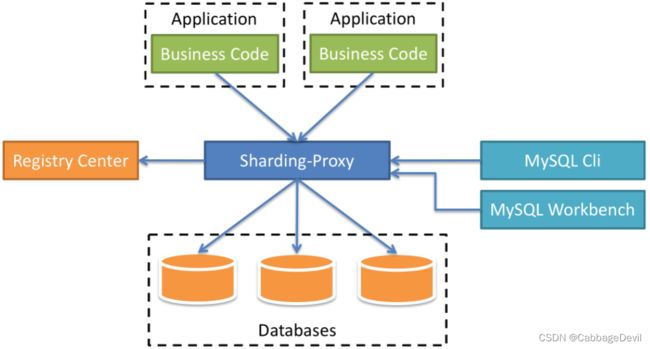
3.1.3 sharding-sidecar
定位为Kubernetes的云原生数据库代理,以Sidecar的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的的啮合层,即Database Mesh,又可称数据网格。
Database Mesh的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互有效的梳理。使用Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
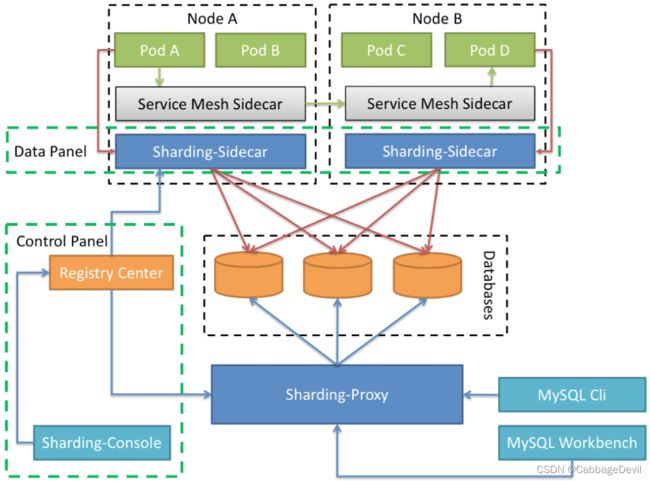
3.1.4 三个组件的对比
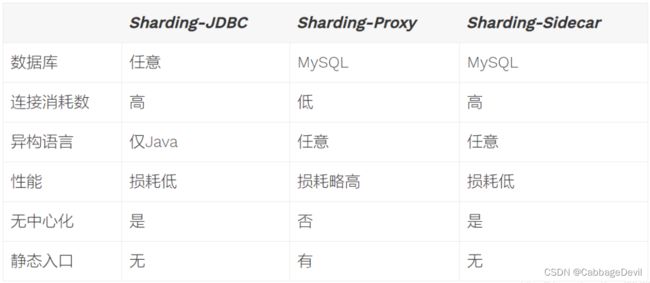
3.2 mycat
是不是感觉看完sharding生态觉得mycat都不需要学习了。其实也不然,每个方案都有每个方案的不同,使用sharding生态或许可以保证你更完善的解决方案,同时也带来了学习成本,而mycat就简单易用,原理容易理解,加上是java编写的项目,对于纯java生态来说也比较方便根据自己的业务改写。现在也有了mycat2,相信功能和性能也会更加强大。
官网: http://www.mycat.org.cn/
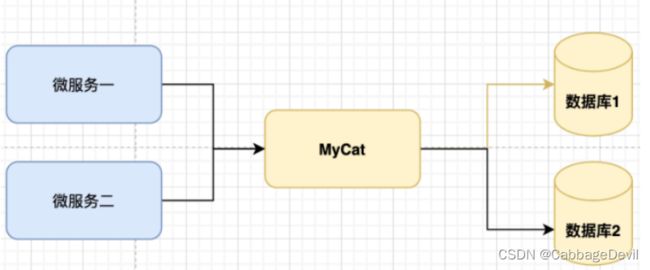
业务架构
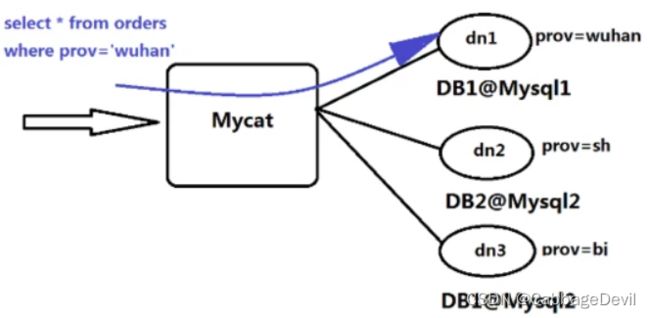
工作原理
3.3 面试题
sharding-JDBC和mycat的区别?
- 相同点:
- 两者设计理念相同,主流程都是SQL解析–>SQL路由–>SQL改写–>结果归并
- 不同点:
sharding-JDBC
- 基于jdbc驱动,不⽤额外的proxy,在本地应⽤层重写Jdbc原⽣的⽅法,实现数据库分片形式
- 是基于 JDBC 接⼝的扩展,是以 jar 包的形式提供轻量级服务的,性能高
- 代码有侵⼊性
mycat - 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server伪装成⼀个 MySQL 数据库
- 客户端所有的jdbc请求都必须要先交给MyCat,再有MyCat转发到具体的真实服务器
- 缺点是效率偏低,中间包装了⼀层
- 代码⽆侵⼊性