深入解析 KaiwuDB 分布式 SQL 引擎架构的五大服务组件
导读
与传统关系型数据库相比,分布式数据库系统具有多集群、多节点、高并发等特性,这就需要分布式数据库的 SQL 引擎能够在满足用户常规的 SQL 请求以外,提供多集群、多节点协同计算的能力,从而提高查询效率。本文将介绍 KaiwuDB 的 SQL 引擎架构特点,以及其中各大服务组件的技术原理与工作流程。
分布式数据库架构
目前业界最流行的分布式数据库主要分为两种架构。一种是以 Google Spanner 为代表的 Shared nothing 架构,另一种是以 AWS Auraro 为代表的计算/存储分离架构。
Spanner 是 shared nothing 的架构,内部维护了自动分片、分布式事务、弹性扩展能力,数据存储还是需要 sharding,plan 计算也需要涉及多台机器,也就涉及了分布式计算和分布式事务。
Auraro 主要思想是计算和存储分离架构,使用共享存储技术,这样就提高了容灾和总容量的扩展。但是在协议层,只要是不涉及到存储的部分,本质还是单机实例的 SQL 引擎,不涉及分布式存储和分布式计算,这样就和传统数据库兼容性非常高。
浪潮 NewSQL KaiwuDB 完美地继承了 Spanner 的设计理念,实现了基于对等架构的分布式 SQL 引擎。
KaiwuDB 的 SQL 引擎
KaiwuDB 的 SQL 引擎在传统的 SQL 引擎基础上,引入了分布式的概念,通过多个集群节点协同计算更高效的执行用户 SQL 查询,总体架构图如下:

SQL 引擎静态结构,包含五大服务
集群中每个节点 node 都独有连接服务(Connectivity Service)、编译服务(Compile Service) 和缓存服务(Cache Service)三大服务,可以完成用户的 SQL 查询执行的前端准备工作。
同时,所有节点又共同组成了分布式的目录服务(Distibuted Catalog Service)和分布式的执行服务(Distibuted Execute Service),通过这两个服务完成了多个 node 节点的协同执行,提高了分布式 SQL 引擎的执行性能。最终将结构化数据,转化为底层存储可识别的 KV 编码对,通过 Batch 批处理发送到事务层进行处理。

SQL 引擎执行流程
下文将对这五大服务进行展开介绍。
1.连接服务 Connectivity Service
KaiwuDB 采用的是对等架构,集群中的任意节点都可以作为接入节点。同时,KaiwuDB 支持 PostgreSQL 协议,SQL 查询可以通过各种支持 PostgreSQL 协议的驱动发送到集群。
连接服务流程如下:
- 用户通过后台守护进程进行连接器管理,为每个客户端构建新的 Executor。
- 当用户从客户端发起指令后,从客户端接收和解包流。
- 执行完毕后,将操作结果打包返回给客户端。
- 用户的每一次操作,都被认为是一个单独的事务操作。
2.分布式目录服务 Dist Catalog Service
KaiwuDB 的 Dist Catalog Service 不仅实现了传统关系数据库的 schema metadata,包含了常用的库、表、列、模式等数据库元数据,而且实现了元数据信息的高可用,以及分布式访问。元数据采用多副本存储、分布式存储,保证少于一半数据不可用的情况下,元数据信息仍然可用。而且每个对等节点在启动时会直接内存化元数据路由表的第一级 Root Meta Range 数据,保证任意节点都能访问到需要的元数据信息。
Catalog 信息发生变化时,首先会更新到元数据存储的写入节点,通过 Raft 协议同步到多副本。同时使得各个节点的 Catalog 缓存失效,在使用时进行异步的更新,保证各节点数据的一致性。
3.编译服务 Compile Service
KaiwuDB 的编译服务包括了 SQL 前端和 SQL 中端功能,SQL 前端实现了传统数据库的 Scanner、Parser、SQL 语法、SQL 语义以及数据库对象和权限校验的处理,生成了 AST(抽象语法树)。
SQL 中端实现了数据库的优化器的功能。优化器负责给执行引擎提供输入,它接收来自 SQL 前端解析好的 AST 树,然后需要从所有可能的计划中选择代价最优的计划提供给执行引擎。
KaiwuDB 的优化器是基于 Cascades 论文实现的搜索框架。从数据库的发展历程来看,基于 Cascades 的搜索框架已经成为了业界标准,包括商业数据库 SQL Server 以及开源数据库 GP/ORCA 都采用 Cascades 实现。编译服务的整体架构如下:

SQL 引擎编译服务结构图
如上图所示,Client 端输入的 SQL 语句通过 go-yacc 层的词法、语法、语意义解析为 AST 语法树,经过 Memo construction 转换为 CBO 初始的 Memo 树。Memo 由一些列等价的 group 组成,每个 group 表示一个逻辑等价表达式集合,Memo 本身是树状结构化的,可以代表查询语句,但是又不包含大量的元数据信息,可以被缓存以提高执行效率,这点在 Cache Service 中会给出解析。构造好的 Memo 直接应用于基本的 RBO 转换。之后,Memo 数据根据统计信息经过 CBO 优化(等价发掘和最优化Cost)选择转换为最优路径的计划。
RBO 根据指定的优先顺序规则,对指定的表进行执行计划的选择。比如在规则中:索引的优先级大于全表扫描。
当某些 SQL 语句的写法并不利于快速从存储中查询数据的场景下,RBO 会对其进行相应转化,例:
SELECT * FROM t1 ,t2 WHERE t1.a > 4 AND t2.b >5;
如果先进行笛卡尔积再进行过滤条件时,则会产生很多不必要的元组。但是如果先过滤 t1 , t2 的关系,在进行笛卡尔积,那么表达式的消耗将大大减少。在进行过滤时,能做到一个select算子中就做到算子中,不能的话,就在具有过滤需要的列时及时做好,比如 a.a > 5 and b.b > 10 and a.c > a.b,第一个和第二个条件都可以推到 select 算子中,在这两个算子上面立即加一个 a.c > a.b 的过滤条件。
CBO 则基于统计信息对代价进行代价预估,得到一条较优的查询路径。例如:我们在做三个表连接的时候,如果有统计信息的话,我们就可以知道,哪两个表先做连接会使接下来执行的代价更小,因为在做 hashjoin 时,我们总希望小的表先进入,然后制作成一个小的 hashtable,因为 hashtable 比较小,所以之后的大表在做 join 的时候,就会有更高的命中率。
4.缓存服务 Cache Service
KaiwuDB 提供了两种类型的缓存服务,主要是用来提高数据访问效率,减少重复消耗。
第一种是 Session 级的 Querycache,主要是缓存用户 SQL 语句指纹对应的 Memo 树数据结构,减少同一 Session 的 SQL 语句多次构建逻辑计划的开销。SQL 语句指纹含有 SQL 语句的相关 Catalog 信息和权限等校验信息。
在重用 Memo 之前,会对 Memo 是否过期进行检查:解析元数据所依赖的每个数据源和 schema,以便检查完全限定的对象名是否仍解析为相同对象的相同版本,检查和时间相关的类型的构造和比较方式,以及用户是否仍有足够的权限访问这些对象。如果依赖项不再是最新的,则判定该 Memo 过期,需要重新构建。
第二种是集群级别的元数据相关 Cache。其中 Catalog 信息包含了数据库常用的 scheme 信息和元数据路由信息。元数据路由信息由 Dist Catalog service 提供。通过元数据路由信息集群任意节点可以访问到所有需要的元数据或者数据。
5.分布式执行服务 Dist Execution Service
KaiwuDB 的 SQL 引擎整体设计模型参考了 Volcano 模型[1],Volcano 模型的提出者是 Goetz Graefe,其 1994 年发表此文,并于 2017 年获得 Edgar F. Codd(关系模型奠基人)创新奖。
KaiwuDB 的分布式执行提出了一些与 Map-Reduce 类似,但与 Map-Reduce 的执行模型又完全不同的概念。
KaiwuDB 的逻辑计划由优化后的 Memo 自底而上构建出一个 Plan node 树状结构,为后续构建物理计划添加一些额外的表信息,列信息等。
分布式执行的关键思想是如何从逻辑执行计划到物理执行计划,这里主要涉及两方面的处理,一个是计算的分布式处理,一个是数据的分布式处理。
一旦生成了物理计划,系统就需要将其拆分并分布到各个 node 之间进行运行。每个 node 负责本地调度数据处理器 data processors 和输入同步器 synchronizers。node还需要能够彼此通信以将输出 output router 连接到 input synchronizer。特别是,需要一个 streaming interface 来连接这些组件。为了避免额外的同步成本,需要足够灵活的执行环境以满足上面的所有这些操作,以便不同的 node 除了执行计划初始的调度之外,可以相对独立的启动相应的数据处理工作,而不会受到 gateway 节点的其他编排影响。
KaiwuDB 的集群中的 Gateway node 创建一个 Scheduler 调度器,它接受一组 flow,设置输入和输出相关的信息,创建本地 processor 并开始执行。在 node 对输入和输出数据进行处理的时候,我们需要对 flow 进行一些控制,通过这种控制,我们可以拒绝 request 中的某些请求。

执行 Flow 示意图
每个 Flow 表示整个物理计划中跨节点执行的一个完整片段,由 processors 和 streams 组成,可以完成该片段的数据拉取、数据计算处理和最终得数据输出。如下图所示:
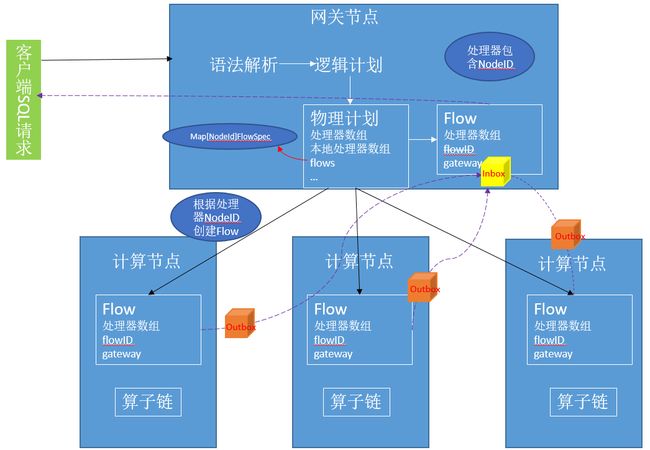
计划执行示意图
对于跨节点的执行,Gateway node 首先会序列化对应的 FlowSpec 为 SetupFlowRequest,并通过 grpc 发送到远端 node,远端 node 接收后,会先还原 flow,并创建其包含的 processor 和交互使用的 stream(TCP 通道),完成执行框架的搭建,之后开始由网关节点发起驱动的多节点计算。Flow 之间通过 box 缓存池进行异步调度,实现整个分布式框架的并行执行。
对于本地执行,就是并行执行,每个 processor,synchronizer 和 router 都可以作为 goroutine 运行,它们之间由 channel 互联。这些 channel 可以缓冲信道以使生产者和消费者同步。
为实现分布式并发执行,KaiwuDB 在执行时引入了 Router 的概念,对于 JOIN 和AGGREGATOR 等复杂算子根据数据分布特征,实现了三种数据再分布方式,mirror_router、hash_router 和 range_router,通过数据再分布实现 processor 算子内部拆分为两阶段执行,第一阶段在数据所在节点做部分数据的处理,处理后结果,根据算子类型会进行再分布后,第二阶段汇集处理,从而实现了单个算子多节点协作执行。
小结
本文介绍了基于谷歌 Spanner 论文设计的分布式 NewSQL 数据库 KaiwuDB 的 SQL 引擎架构,并详细介绍了每个节点中的连接服务、编译服务、缓存服务,以及系统中的分布式目录服务、分布式执行服务五大服务组件的技术原理与工作流程。