深入代码优化 (二) 使用SIMD优化程序
在现代 CPU 中,并行性操作大致分为三种类型:
(1)指令级并行,主要由 cpu 流水线技术,乱序执行技术等技术完成。
(2)线程级并行,主要依靠多核多线程技术实现。
(3)数据级并行,主要依靠 SIMD (单指令多数据) 来实现。
指令级并行和线程级并行这两种技术不在本文进行讨论,本文将详细介绍 SIMD 及其使用方法。
SIMD 介绍
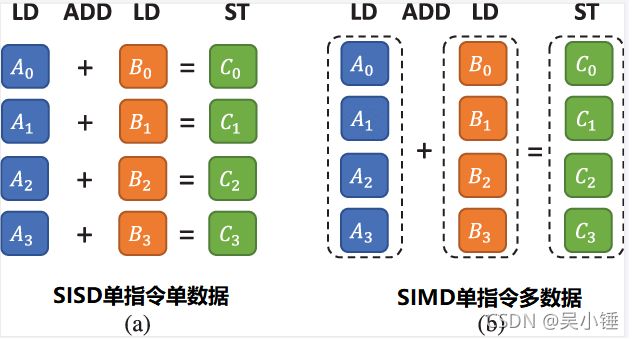
SIMD 是 CPU 硬件设计的一部分,并且是可以通过指令集架构 (ISA) 直接访问。SIMD 描述了具有多个处理元件的计算机同时对多个数据执行相同操作的过程。
以加法指令为例,单指令单数据 (SISD) 的 CPU 对加法指令译码后,执行部件先访问内存,取得第一个操作数,之后再一次访问内存,取得第二个操作数,随后才能进行求和运算。而在支持 SIMD 的 CPU 中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使 SIMD 特别适合于多媒体应用等数据密集型运算。
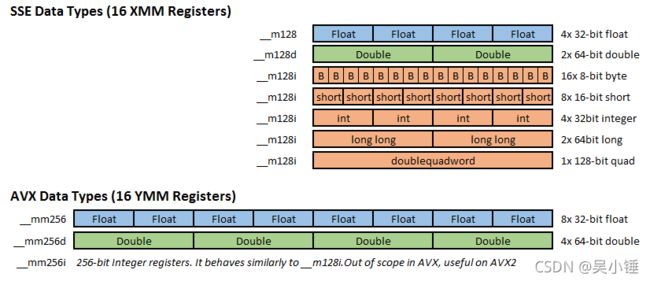
英特尔的第一个 IA-32 SIMD 指令集是 MMX 指令集。它沿用了 x87 时代的浮点寄存器,使 CPU 无法对浮点数进行 SIMD 操作,只能处理整数。SIMD 流指令扩展 (SSE) 是 x86 架构的 SIMD 指令集扩展,最早是由 Intel 设计并在1999年推出的奔腾3系列 CPU 中引入。SSE 浮点指令在新的独立寄存器 XMM 上运行,并扩展了一些在 MMX 寄存器上运行的整数指令。SSE 包含了70条新指令,其中大部分都适用于单精度浮点数据类型 (float) 。
SSE最初添加了8个新的128位寄存器,XMM0 - XMM7,在 AMD64 拓展里面,又额外添加了8个寄存器,XMM8 - XMM15,这个拓展也被引入到了 Intel64 位处理器 (IA-64) 架构中。不过寄存器XMM8 - XMM15 只能用来处理 64bit 的操作数。SSE2 进一步支持双精度浮点数,由于寄存器长度没有变长,所以只能支持2个双精度浮点计算或是4个单精度浮点计算。另外,它在这组寄存器上实现了整型计算,从而代替了 MMX。
在 Intel 的 AVX 指令集中,将 SSE 的128位数据通道拓宽到256位,并由此产生的寄存器称之为YMM。并且 AVX 全面兼容 SSE/SSE2/SSE3/SSE4,也就是 YMM 寄存器的低128位就是 XMM 寄存器。
现代编译器有三种方式来支持 SIMD:
(1)编译器能够在没有用户干预的情况下生成 SIMD 代码,称之为自动矢量化。
(2)用户可以插入 Intrinsics 函数实现 SIMD。
(3)用户可以使用矢量 C++ 类 (仅限ICC编译器) 来实现 SIMD。
1. 自动矢量化
在程序编写过程中,可能会经常遇到以下循环的方式,一次执行许多数字的加法。
for (i = 0; i < n; i ++)
c[i] = a[i] + b[i];在 gcc 编译器中,如果添加了 -ftree-vectorize 编译选项 (O2已包含此优化选项),那么编译器可以自动将这类循环转换成矢量操作序列。
下面以 vector.c 做实验,看看编译器怎么实现适量自动化。
[root@wuhan ~]# cat vector.c
#include
#define N 100000
#define M 1024
int a[M], b[M], c[M];
int main()
{
int i, j;
for (j = 0; j < N; j ++)
for (i = 0; i < M; i ++)
c[i] = a[i] + b[i];
return 0;
} 对其进行编译运行,第一次编译不带 -ftree-vectorize,即期望编译器不对这段代码进行自动矢量化。第二次带上 -ftree-vectorize,期望编译器能对其进行自动矢量化。由于 -ftree-vectorize 只在 -O1 优化下才生效,所以两次编译也都带了 -O1 进行。
[root@wuhan ~]# gcc vector.c -O1 -o no_vector
[root@wuhan ~]# time ./no_vector
real 0m0.110s
user 0m0.108s
sys 0m0.001s
[root@wuhan ~]# gcc vector.c -O1 -o with_vector -ftree-vectorize
[root@wuhan ~]# time ./with_vector
real 0m0.029s
user 0m0.028s
sys 0m0.000s从运行耗时可以看出,矢量化编译 (-ftree-vectorize) 之后性能大大提升。再将这段程序的汇编码打印出来,可以看出矢量化编译之后,汇编码里面使用了 XMM 寄存器。前面介绍过了,XMM 寄存器可以同时装载4个 int 类型的数据,并对其进行相同的操作,这也就是性能提升的关键。
| [root@wuhan ~]# gcc vector.c -O1 -S [root@wuhan ~]# cat vector.s .file "vector.c" .text .globl main .type main, @function main: .LFB11: .cfi_startproc movl $100000, %ecx jmp .L2 .L6: subl $1, %ecx je .L4 .L2: movl $0, %eax .L3: movl b(%rax), %edx addl a(%rax), %edx movl %edx, c(%rax) addq $4, %rax cmpq $4096, %rax jne .L3 jmp .L6 .L4: movl $0, %eax ret .cfi_endproc .LFE11: .size main, .-main .comm c,4096,32 .comm b,4096,32 .comm a,4096,32 .ident "GCC: (GNU) 8.4.1 20200928 (Red Hat 8.4.1-1)" .section .note.GNU-stack,"",@progbits |
[root@wuhan ~]# gcc vector.c -O1 -ftree-vectorize -S |
上面的代码很容易自动矢量化,我们再来对比一下这两段代码:
| #include #define N 100000 int main() |
#include #define N 100000 int main() |
区别之处已加粗显示,分别将他们编成汇编码,再进行对比:
| [root@wuhan ~]# gcc vector2.c -O1 -ftree-vectorize -S [root@wuhan ~]# cat vector2.s |
[root@wuhan ~]# gcc vector2.c -O1 -ftree-vectorize -S [root@wuhan ~]# cat vector2.s |
显然右侧程序的汇编码使用了 XMM 寄存器,而左边的程序却没有。
假如他们都会进行矢量化,那么以下4条操作是要同时进行的,假如 a[0] = 0, a[1] = 1, a[2] = 2...,那么左边的程序运行完之后,得到的结果 a[1] = 0, a[2] = 1, a[3] = 2...。但实际上,左边程序运行完之后应该得到的结果是 a[1] = 0, a[2] = 0, a[3] = 0...。所以,如果左边的程序也矢量化,那么程序的结果就是错误的。而右边的程序却不受影响,虽然右边程序 a[i+4] 的值也依赖于 a[i],但是他们地址相差128位,而XMM寄存器刚好是128位宽,矢量化运行之后也不影响本来的结果。
| a[1] = a[0]; a[2] = a[1]; a[3] = a[2]; a[4] = a[3]; |
a[4] = a[0]; a[5] = a[1]; a[6] = a[2]; a[7] = a[3]; |
自动矢量化,就像任何循环优化或其他编译优化一样,必须准确地保留程序行为。在执行期间必须遵守所有的依赖项,以防止出现错误结果。如果出现处理不了的循环依赖,那么循环依赖必须独立于矢量化指令执行。
要矢量化一个程序,编译器必须首先了解语句之间的依赖关系,并在必要时重新对齐它们。 一旦映射了依赖关系,编译器必须正确安排实现指令,将适当的候选者更改为矢量指令,并用这些指令对多个数据项进行操作。
编译器进行矢量自动化优化通常会经历一下三个步骤:
(1)建立依赖图。识别哪些语句依赖于哪些其他语句。这包括检查每个语句并识别语句访问的每个数据项,将数组访问修饰符映射到函数以及检查每个访问对所有语句中其他访问的依赖关系。依赖图包含了距离不大于矢量大小的所有局部依赖。 如果矢量寄存器为 128 位,数组类型为 32 位,则矢量大小为 128/32 = 4。所有其他非循环依赖项都不应使其矢量化无效,因为他们不会调用相同的矢量指令。
(2)聚类。使用依赖图,优化器可以对强连接组件 (SCC) 进行聚类,并将可矢量化语句与其余语句分开。例如,一个程序的循环内包含三个语句组:(SCC1+SCC2)、SCC3 和 SCC4,其中只有第二组 (SCC3) 可以矢量化。那么最终的程序将包含三个循环,每个循环一个语句组,只有中间的循环被矢量化。 优化器不能在不违反语句执行顺序的情况下将第一个与最后一个连接起来,因为这很可能会保证不了数据有效性。
(3)监测惯用语法,一些不明显的依赖可以根据特定的习惯用法进一步优化。例如,下面的数据依赖项可以进行矢量化,因为可以获取右侧值然后将其存储在左侧值上,因此数据不会在赋值中发生变化。
a[i] = a[i+1]; /* 不同于a[i+1] = a[i], a[i+1] = a[i]不能矢量化 */2. 插入 Intrinsics 函数 (内在函数) 实现 SIMD
对于程序员来说,intrinsics 看起来就像普通的库函数。只要包含了相关的头文件,就可以使用内在函数。如果要将4个整数和另外4个整数相加,可以使用 _mm_add_epi32 内在函数。这个函数的声明包含在

intrinsics 与库函数不同的是,intrinsics 是直接在编译器中实现的。上面的 _mm_add_epi32 SSE2内在函数通常编译成一条指令 paddd。__m128i 内置数据类型是四个整数型的矢量,每个 32 位,总共 128 位。编译器将发出两条指令:第一条将参数从内存加载到寄存器中,第二条将四个值相加。通常来说,CPU 调用一个库函数所花费的时间,可能是调用 intrinsics 的数倍。
包含足够数量的矢量 intrinsics 或嵌入等效汇编源代码的过程称为手动矢量化。现代编译器和库已经使用内在函数、汇编或两者的组合实现了很多东西。例如,memset,memcpy 或 memmove 标准 C 库函数的实现就使用 SSE2 指令以获得更好的性能。然而,在高性能计算、游戏开发或编译器开发等细分领域之外,即使是非常有经验的 C 和 C++ 程序员在很大程度上也不熟悉 SIMD 内在函数。
下面函数是使用 intrinsics 函数来实现 c[i] = a[i] + b[i] 。
[root@wuhan ~]# cat vector_sse2.c
#include
#include
#define N 100000
#define M 1024
int a[M], b[M], c[M];
int add_sse2(int size, int *a, int *b, int *c) {
int i = 0;
for (; i + 4 <= size; i += 4) {
/* 加载 a, b 数组的 128 位块 */
__m128i ma = _mm_loadu_si128((__m128i*) &a[i]);
__m128i mb = _mm_loadu_si128((__m128i*) &b[i]);
/* 128 位块矢量相加 */
ma = _mm_add_epi32(ma, mb);
/* 将相加结果存储到 c 数组的 128 位块 */
_mm_storeu_si128((__m128i*) &c[i], ma);
}
}
int main()
{
for (int i = 0; i < N; i ++)
add_sse2(M, a, b, c);
return 0;
} 将文件编成汇编码,汇编码包含了 paddd %xmm1, %xmm0
[root@wuhan ~]# gcc vector_sse2.c -O1 -S
[root@wuhan ~]# cat vector_sse2.s
.file "vector_sse2.c"
.text
.comm a,4160,32
.comm b,4096,32
.comm c,4096,32
.globl add_sse2
.type add_sse2, @function
add_sse2:
.LFB503:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $40, %rsp
movl %edi, -132(%rbp)
movq %rsi, -144(%rbp)
movq %rdx, -152(%rbp)
movq %rcx, -160(%rbp)
movl $0, -4(%rbp)
jmp .L2
.L6:
movl -4(%rbp), %eax
cltq
leaq 0(,%rax,4), %rdx
movq -144(%rbp), %rax
addq %rdx, %rax
movq %rax, -128(%rbp)
movq -128(%rbp), %rax
movdqu (%rax), %xmm0
movaps %xmm0, -32(%rbp)
movl -4(%rbp), %eax
cltq
leaq 0(,%rax,4), %rdx
movq -152(%rbp), %rax
addq %rdx, %rax
movq %rax, -120(%rbp)
movq -120(%rbp), %rax
movdqu (%rax), %xmm0
movaps %xmm0, -48(%rbp)
movdqa -32(%rbp), %xmm0
movaps %xmm0, -96(%rbp)
movdqa -48(%rbp), %xmm0
movaps %xmm0, -112(%rbp)
movdqa -96(%rbp), %xmm1
movdqa -112(%rbp), %xmm0
paddd %xmm1, %xmm0
movaps %xmm0, -32(%rbp)
movl -4(%rbp), %eax
cltq
leaq 0(,%rax,4), %rdx
movq -160(%rbp), %rax
addq %rdx, %rax
movq %rax, -56(%rbp)
movdqa -32(%rbp), %xmm0
movaps %xmm0, -80(%rbp)
movdqa -80(%rbp), %xmm0
movq -56(%rbp), %rax
movups %xmm0, (%rax)
addl $4, -4(%rbp)
.L2:
movl -4(%rbp), %eax
addl $3, %eax
cmpl %eax, -132(%rbp)
jg .L6
nop
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE503:
.size add_sse2, .-add_sse2
.globl main
.type main, @function
main:
.LFB504:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $0, -4(%rbp)
jmp .L8
.L9:
movl $c, %ecx
movl $b, %edx
movl $a, %esi
movl $1024, %edi
call add_sse2
addl $1, -4(%rbp)
.L8:
cmpl $99999, -4(%rbp)
jle .L9
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE504:
.size main, .-main
.ident "GCC: (GNU) 8.4.1 20200928 (Red Hat 8.4.1-1)"
.section .note.GNU-stack,"",@progbits测试一下这个程序的性能, 比前面介绍的直接使用矢量化优化的程序性能还要好一些。
| [root@wuhan ~]# gcc vector.c -O1 -o with_vector -ftree-vectorize real 0m0.029s |
[root@wuhan ~]# gcc vector_sse2.c -o vector_sse2 -O1 real 0m0.020s |
3. 利用 C++ 类 (ICC编译器专用)
使用该方法依赖于环境里面安装了 Intel ICC 编译器。ICC 编译器集成在 Intel oneAPI 开发套件里面,下载链接:Download the Intel® oneAPI Base Toolkit
直接在 linux 上用 yum 安装:
(1)在 /temp 文件夹底下创建 YUM 的 repo 文件
tee > /tmp/oneAPI.repo << EOF
[oneAPI]
name=Intel® oneAPI repository
baseurl=https://yum.repos.intel.com/oneapi
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://yum.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB
EOF(2)将新建的 repo 文件移到 /etc/yum.repos.d
sudo mv /tmp/oneAPI.repo /etc/yum.repos.d(3)使用 yum 命令安装 Intel® oneAPI Base Toolkit
sudo yum install intel-basekit(4)在使用编译器之前运行setvars.sh设置环境变量
source /opt/intel/oneapi/setvars.sh intel64(5)安装结束,查看编译器版本
[root@wuhan ~]# icpx --version
Intel(R) oneAPI DPC++/C++ Compiler 2021.4.0 (2021.4.0.20210924)
Target: x86_64-unknown-linux-gnu
Thread model: posix
InstalledDir: /opt/intel/oneapi/compiler/2021.4.0/linux/bin使用 C++ 类进行 SIMD 操作允许在单个操作中对数组或数据向量进行操作。同样是计算 c[i] = a[i] + b[i],用传统数组的方法表示如下:
int a[4], b[4], c[4];
for (i=0; i<4; i++) /* 需要4次迭代 */
c[i] = a[i] + b[i]; /* 分别计算 c[0], c[1], c[2], c[3] */在 ICC 编译器中可以使用 Ivec 类来表示 (需要添加头文件 dvec.h)
Is32vec4 ivecA, ivecB, ivecC; /* 只需要一次迭代 */
ivecC = ivecA + ivecB; /* 计算 ivecC0, ivecC1, ivecC2, ivecC3 */所以可以把前面示例的程序改造如下:
[root@wuhan ~]# cat vector_class.cpp
#include
#include
using namespace std;
#define N 100000
#define M 1024
Is32vec4 a[M/4], b[M/4], c[M/4];
int main()
{
for (int i = 0; i < N; i ++)
for (int j = 0; j < M/4; j ++)
c[j] = a[j] + b[j];
return 0;
} 把程序变成汇编码,检查一下是否用了 XMM 寄存器,C++ 汇编码编译出来太长了,就不贴全部源码。果然 paddd 指令和 XMM 寄存器也都使用了。
[root@wuhan ~]# icpx vector_class.cpp -O1 -S
[root@wuhan ~]# cat vector_class.s | grep -i xmm
movaps %xmm0, c(%rbx)
movdqa %xmm0, (%rsp) # 16-byte Spill
paddd (%rsp), %xmm0 # 16-byte Folded Reload
movaps 16(%rsp), %xmm0
movaps (%rdi), %xmm0
movaps %xmm0, (%rdi)总结
SIMD 的使用不是那么简单,一般程序员也不太会使用 Intrinsics 函数或者 Ivec 类来优化 SIMD,基本上都是靠编译器帮我们进行自动矢量化。
想要代码能尽量的自动矢量化,以下几点其实是我们可以做到的:
- 避免使用全局指针和全局变量以帮助编译器生成 SIMD 代码。
- 使用尽可能小的 SIMD 数据类型,通过使用更长的 SIMD 矢量长度来实现更多的并行性。
- 合理安排循环的嵌套,以便最内层的嵌套没有迭代间的依赖关系。尤其要避免在较早的迭代中存储数据,而在往后的迭代中加载该数据。
- 避免在循环内使用条件分支。
- 保持循环变量表达式简单。
参考文献:
《64-ia-32-architectures-optimization-manual》
https://www.intel.com/content/www/us/en/develop/documentation/oneapi-dpcpp-cpp-compiler-dev-guide-and-reference/top/compiler-reference/libraries/intel-c-class-libraries/c-classes-and-simd-operations.html
https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions
Intel® Intrinsics Guide
CS3330: A quick guide to SSE/SIMD
https://www.eidos.ic.i.u-tokyo.ac.jp/~tau/lecture/parallel_distributed/2018/slides/pdf/simd2.pdf
Basics of SIMD Programming
Improving performance with SIMD intrinsics in three use cases - Stack Overflow Blog
https://en.wikipedia.org/wiki/Automatic_vectorization
SIMD指令学习笔记 - 浊酒恋红尘 - 博客园