使用Intel VTune Profiler进行性能分析及优化
初识Intel® VTune™ Profiler
Intel VTune Profiler是一个全平台的性能分析工具,可以帮助你快速发现和分析应用程序及整个系统的性能瓶颈。工具支持分析本地或远程的Windows,Linux及Android应用,这些应用可以部署在CPU,GPU,FPGA等硬件平台上。支持分析的语言包括:DPC++, C,C++,C#,Fortran,OpenCL,Python,Go,Java,汇编等。

VTune集成了多种性能分析方法
性能快照(Performance Snapshot)生成程序性能问题的分析总结。在总结报告里,会推荐你采用哪些具体的分析手段进行下一步的分析和优化。
算法(ALGORITHM)可以帮助你分析程序中所采用的算法的效率,理解程序最花时的地方在哪里。算法分析组包含了热点,异常探测,内存消耗三种分析方法。
热点(Hotspots)专注在一个具体的可执行文件,识别消耗cpu时钟最多的函数,可以直观的展示程序的线程信息及每个函数的调用栈信息。
异常探测(Anomaly Detection)可以帮助你在循环迭代中识别性能异常。
内存消耗(Memory Consumption)探索随时间而变化的内存消耗,并分析运行期间分配和释放的内存对象。
微架构(Microarchitecture)分析组包含了可以评估代码运行效率的一系列分析类型。
微架构探索(Microarchitecture Exploration) 有助于识别影响应用程序性能的最重要的硬件问题。在进行硬件级分析时,可以将此分析类型作为起点。
内存访问(Memory Access)用于识别内存访问中的一些问题,特别适用于NUMA架构中。
并行(Parallelism )分析组介绍了基于计算敏感的应用程序的分析类型。在进行更有针对性的分析之前,可以先用此类方法分析整体的应用程序性能。
线程(Threading)展示应用程序在当前cpu分布下的线程化情况,识别占用CPU时间较长的函数和可能导致cpu等待的一些非必要同步问题。
HPC性能表征(HPC Performance Characterization )可以评估计算敏感型或含有大量浮点运算的应用程序的运算及内存使用效率,可以作为理解整个应用程序性能的起点。
输入和输出(I/O)基于一些硬件事件来分析设备的PCIe和I/O带宽消耗,DDIO的使用效率,程序的数据面(DPDK和SPDK)利用率。
硬件加速器(Accelerators)组包含了用于应用程序及系统的CPU、GPU和FPGA使用情况的分析方法。
GPU卸载(GPU Offload)适用于使用GPU进行渲染,视频处理和计算的应用程序。它可以分析应用程序是的瓶颈是受限于CPU还是GPU。
GPU热点(GPU Compute/Media Hotspots)针对GPU绑定的应用程序,分析GPU内核执行的每一行代码,并能识别出由内存延迟或低效的内核算法造成的性能问题。
CPU/FPGA交互(CPU/FPGA Interaction)分析每个FPGA加速器的利用率,并确定最耗时的FPGA计算任务。
平台分析(Platform Analysis)用于监控应用程序的系统行为和电力使用情况。
系统概述(System Overview)是一种基于硬件事件的采样分析,监控目标系统的通用行为,并识别限制性能的平台级因素。
平台采样(Platform Profiler)分析收集系统在一段时间内满负荷运行的数据,并深入了解整个系统配置、性能和行为。集合在VTune Profiler外部的命令提示符上运行,并可以在web浏览器中查看结果。
安装并使用VTune
软件下载地址:
Download the Intel® oneAPI Base Toolkit
操作系统选择Windows,安装类型选择Local,VTune包含在Intel的oneAPI套件当中。在windows客户端,可以通过SSH远程连接到服务器,采集相关进程数据到客户端进行性能分析,性能分析结果将在可视化图形界面展示。

使用VTune分析性能有两种方法:
1. 通过VTune客户端,直接启动程序或者附着到程序进程上,抓取相关数据进行分析。
2. 通过perf工具,抓取报告,导入到VTune客户端进行数据分析。
VTune直连进行性能分析
只需简单4步,即可一键分析性能。
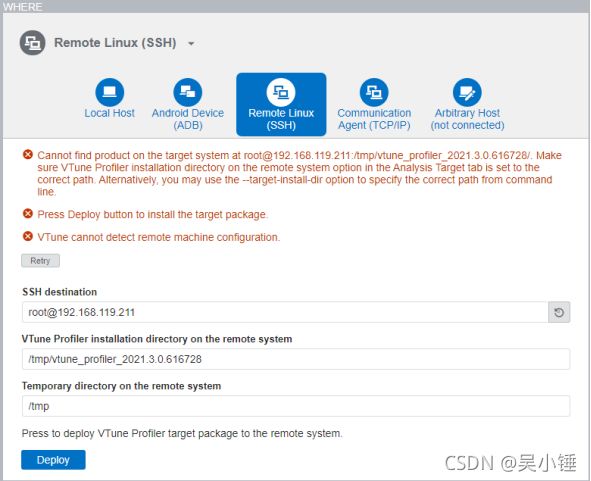
第一步,Where,指定目标程序所在位置
选择Remote Linux,通过SSH远程连接,指定服务器IP,点击Deploy,一键部署服务器端相关配置。
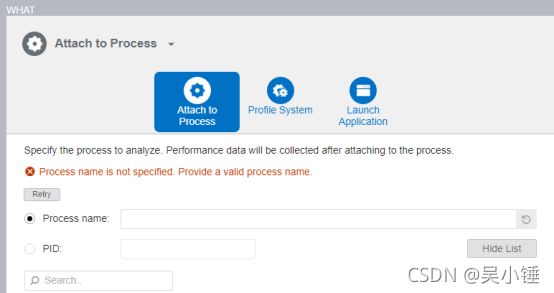
第二步,WHAT,选择目标进程
选择Attach to Process, 会弹出搜索框,直接搜索进程名字,找到正在运行的进程PID,填入即可。
第三步,HOW,选择性能分析方法
每种性能分析方法的概述在上面已经介绍过了,选择适合自己的就行。

第四步,添加代码路径和库路径
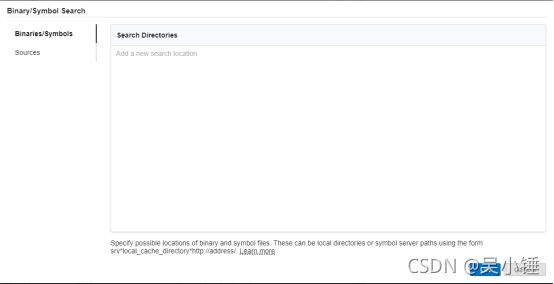
点击软件右下角的Binary/Symbol Search按钮,添加源代码所在路径,动态库的路径会自动搜索,无需手动添加。注意,程序编译的时候需要带 -g 选项,否则结果显示的热点分布将和实际情况有较大出入。

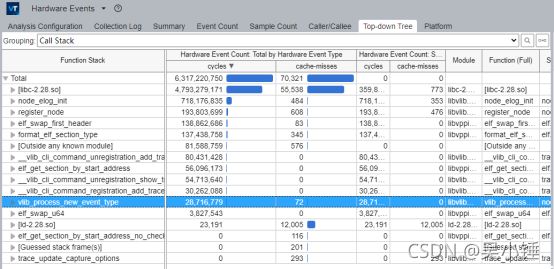
分析结果展示如下,切换不同的标签栏,可以查看不同的结果展示方式。

选择Top-down Tree可以自顶向下查看热点函数分布。
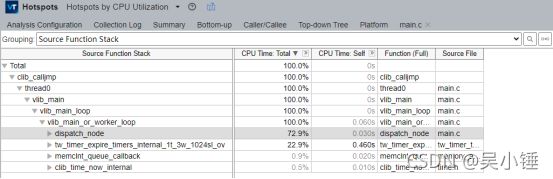
如果代码及库路径正确,双击函数,即可查看函数内部的热点分布详情,以及对应的汇编代码。

Perf生成报告,VTune进行分析
只需要简单2步,就可以分析性能。
第一步,到服务器上用perf采集进程数据。
perf相关用法请参考 Linux perf Examples
[root@localhost ~]# perf record -F 99 -e cycles,cache-misses -ag -p 66029 -- sleep 100
[root@localhost ~]# ls perf.data
perf.data
[root@localhost ~]# mv perf.data data.perf 这里的-e cycles,cache-misses表示采集的事件类型,-p 66029为进程的pid,sleep 100表示采集时间持续100秒。
采集结束会生成perf.data文件,可以在linux端直接使用perf report查看性能报告,但是展示方式不够友好。可以将其重命名为data.perf,.perf是VTune客户端可以导入的数据格式。
perf list列出了可以采样的事件
[root@localhost ~]# perf list
List of pre-defined events (to be used in -e):
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
...第二步,将data.perf导入VTune
点击VTune客户端左侧导入按钮,将data.perf文件导入进去,即可进行性能分析。同样地,在分析之前,应确保代码和库路径配置正确。
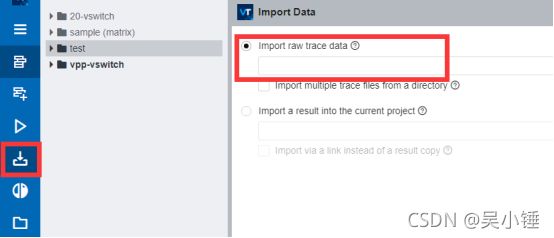
生成报告如下所示,可以展示cycles和cache-misses数据。