Impala 架构了解
Impala 整体架构了解
一 Impala官网
PB级大数据实时查询分析引擎,具有实时、批处理、多并发等优点,提供对HDFS、Hbase数据的低延迟 SQL 查询;Impala 不使用 MapReduce,通过分布式查询引擎访问数据,比 Hive 快一个数量级的性能;Hive 适合于长时间批处理分析,Impala 适合于实时 SQL 查询
用途
Impala 提高了基于 Hadoop 的 SQL 查询性能。实时查询HDFS 或 HBase 数据。Impala 与 Hive 有相同元数据、SQL 语法 、ODBC ,为面向批处理或实时查询提供统一平台
二 IMPALA & HIVE
1.1 Impala相对于Hive所使用的优化技术
1、不使用 MapReduce 因为其实面向批处理模式,而不是交互式的SQL执行
2、使用LLVM产生运行代码,针对特定查询生成特定代码,加快执行效率
3、更好的 IO 调度,Impala 知道数据块所在的磁盘位置,且支持直接数据块读取和本地代码计算 checksum
4、通过选择合适的数据存储格式可得到最好性能(Impala支持多种存储格式)
5、最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递
1.2 Impala 与 Hive 的不同
1、执行计划
Hive: 依赖 MapReduce 执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce… 模型。一个 Query 被编译成多轮 MapReduce,会有更多的写中间结果。由于 MapReduce 执行框架本身的特点,过多的中间过程会增加整个 Query 的执行时间
Impala: 把执行计划为一棵执行树,分发执行计划到各个 Impalad 执行查询,不像 Hive 把它组合成管道型的map->reduce 模式,保证 Impala 更好的并发性和避免不必要的中间 sort 与 shuffle
2、数据流
Hive: 推的方式,下层节点完成后将数据主动推给上层节点
Impala: 拉的方式,上层节点主动向下层节点要数据,数据流式返回客户端,只要有数据被处理完,即返回而不用等全部处理完,更符合 SQL 交互式查询
3、调度
Hive: 任务调度依赖于Hadoop的调度策略
Impala: 调度由自己完成,目前只有一种调度器simple-schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。调度器目前还比较简单,在 SimpleScheduler::GetBackend 中可以看到,现在还没有考虑负载,网络IO状况等因素进行调度。但目前 Impala 已经有对执行过程的性能统计分析,应该以后版本会利用这些统计信息进行调度
5、容错
Hive: 依赖于Hadoop的容错能力
Impala: 在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误
三 Apache Impala概念和架构
Impala 是一个分布式并行处理(MPP)数据库引擎。由不同守护进程组成,运行在CDH集群中
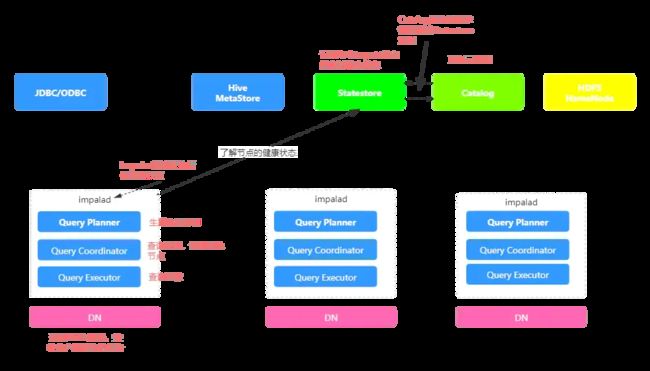
impalad
impalad 是 impala 的核心组件,它是一个守护进程,运行在集群每个数据节点(DataNode)上,负责读取和写入数据文件;并行化查询请求并在整个集群中分配工作;将中间查询结果传输回中央协调器节点;接受从 impala-shell 传递的命令,Hue、JDBC 或 ODBC传输的查询。
Impala 守护进程与 statestore 一直保持通信,以确认哪些节点是健康的,可以接受新任务
在CDH 5.12 / Impala 2.9和更高版本中,可以控制哪些主机充当查询协调器,哪些主机充当查询执行器,以提高大型集群中高并发负载的可伸缩性
当集群中的任何 Impala 节点创建、修改或删除任何类型的对象时,或者当 Impala 处理插入(INSERT )或加载(LOAD DATA)操作时,它们也会接收来自 catalogd 守护进程 (在Impala 1.2中引入) 的广播消息。这种后台通信使得在Impala 1.2之前,跨节点协调元数据所需的刷新(REFRESH )或设置元数据失效(INVALIDATE METADATA )功能的操作次数降到最低
⻆⾊名称为Impala Daemon,是在每个节点上运⾏的进程,是Impala的核⼼组件,进程名是Impalad
Impalad服务由三个模块组成:Query Planner、Query Coordinator和Query Executor,前两个模块组成前端,负责接收SQL查询请求,解析SQL并转换成执⾏计划,交由后端执⾏
状态存储进程 Statestored
statestore 只需在集群的某一个主机上运行,负责检查集群中所有 DataNode 上的 impalad 状态,并不断地将其结果转发给每个守护进程
statestore 是当群集状态出错时提供帮助,对 Impala 集群运行不重要。若 statestore 不运行了 impalad 将继续运行,但如果这时其它的 impalad 脱机,集群就变得不健壮了。当 statestore重新上线时,它会重新建立与 impalad 的通信,并恢复其监控功能
负载平衡和高可用性的大多数考虑都适用于impalad守护进程。statestored 和catalogd 守护进程对高可用性没有特殊要求,因为这些守护进程的问题不会导致数据丢失。如果这些守护进程由于某个主机的中断而不可用,您可以停止Impala服务,删除Impala StateStore和Impala目录服务器角色,然后在另一个主机上添加这些角色,并重新启动Impala服务
目录服务进程catalogd
作为metadata访问网关,从Hive Metastore等外部catalog中获取元数据信息,放到impala自己的catalog结构中。impalad执行ddl命令时通过catalogd由其代为执行,该更新则由statestored广播
目录服务避免了执行更改元数据语句时要执行 REFRESH(刷新) 和 INVALIDATE METADATA(使元数据无效) 操作(HIVE创建一个表、加载数据等操作时,需要在这个节点上 REFRESH 再执行查询)
当数据更改操作通过 Impala执行,不需要 REFRESH ,若这些操作通过 Hive 或直接在 HDFS 中操作数据文件,那么只需要在一个 Impala 节点上执行更新即可,不需要在所有节点上执行一回
系统启动时,元数据加载和缓存是异步的,因此 Impala 可以立即开始接受请求。如果需要 Impala 等待所有元数据在接受任何请求之前加载好,可以设置 catalogd 配置选项 —— load_catalog_in_background=false
负载均衡和高可用适用于 impalad,statestored 和 catalogd 无高可用性,因为不会导致数据丢失。若某个主机的中断而不可用,可以停止 Impala 服务,删除 Impala StateStore 和 Impala 目录服务器角色,在另一个主机上添加这些角色,并重新启动Impala服务
catalogd 会在 Impala 集群启动的时候加载 hive 元数据信息到 Impala,其他时候不会主动加载,需要使用invalidate metadata,refresh命令;由于⼀个集群需要⼀个 catalogd 以及⼀个 statestored 进程,⽽且 catalogd 进程所有请求都是经过 statestored 进程发送,所以官⽅建议让 statestored 进程与 catalogd 进程安排同个节点
四 查询过程

具体流程
1.Client提交任务 Client发送⼀个SQL查询请求到任意⼀个Impalad节点,会返回⼀个 queryId ⽤于之后的客户端操作
2.生成查询计划(单机计划、分布式执行计划) SQL提交到Impalad节点之后,Analyser 依次执⾏ SQL 的词法分析、语法分析、语义分析等操作;从MySQL元数据库中获取元数据,从HDFS的名称节点中获取数据地址,以得到存储这个查询相关数据的所有数据节点
-
单机执行计划:根据上⼀步对SQL语句的分析,由Planner先⽣成单机的执⾏计划,该执⾏计划是有PlanNode组成的⼀棵树,这个过程中也会执⾏⼀些SQL化,例如Join顺序改变、谓词下推等
-
分布式并⾏物理计划:将单机执⾏计划转换成分布式并⾏物理执⾏计划,物理执⾏计划由⼀个个的Fragment组成,Fragment之间有数据依赖关系,处理过程中要在原有的执⾏计划之上加⼊⼀些ExchangeNode和DataStreamSink信息等。
-
Fragment : sql⽣成的分布式执⾏计划的⼀个⼦任务
-
DataStreamSink:传输当前的Fragment输出数据到不同的节点
-
3.任务调度和分发
Coordinator将Fragment(⼦任务)根据数据分区信息发配到不同的Impalad节点上执⾏,Impalad节点接收到执⾏Fragment请求交由Executor执⾏
4. Fragment之间的数据依赖
每⼀个Fragment的执⾏输出通过DataStreamSink发送到下⼀个Fragment,Fragment运⾏过程中不断向coordinator节点汇报当前运⾏状态
5. 结果汇总
查询的SQL通常情况下需要有⼀个单独的Fragment⽤于结果的汇总,它只在Coordinator节点运⾏,将多个节点的最终执⾏结果汇总,转换成ResultSet信息
6. 获取结果
客户端调⽤获取ResultSet的接⼝,读取查询结果
单机执行计划
以⼀个SQL例⼦来展示查询计划
select
t1.n1,
t2.n2,
count(1) as c
from t1 join t2 on t1.id = t2.id
join t3 on t1.id = t3.id
where t3.n3 between ‘a’ and ‘f’
group by t1.n1, t2.n2
order by c desc
limit 100;

分析上图流程:
-
第一步去扫描t1表中的需要的数据 n1、id 列,再扫描 t2 表需要的数据 n2、id 列,然后这部分数据进行Join操作
-
t1 表和 t2 表关联后,同样的操作,将中间结果表和 t3 进行关联 Join,此处 Impala 会使用谓词下推优化,只读取需要的数据进行表 Join
-
将最后的结果数据进行聚合操作
分布式执行计划
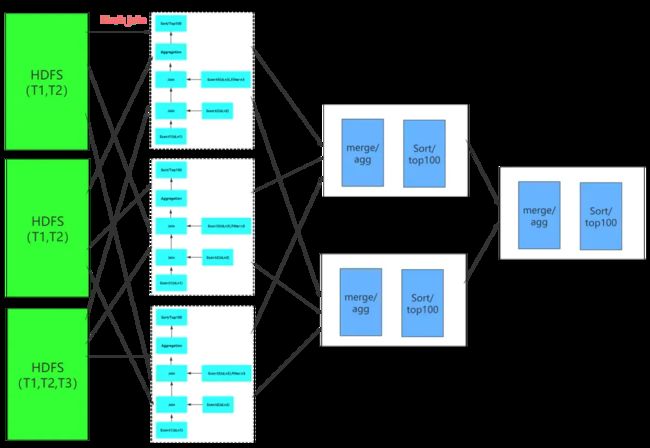
分布式执⾏计划中涉及到多表的 Join,Impala 会根据表的⼤⼩来决定 Join 的⽅式,主要有两种分别是 HashJoin 与Broadcast Join,上⾯分布式执⾏计划中可以看出 T1,T2 表⼤⼀些,⽽ T3 表⼩⼀些,所以对于 T1 与T2的 Join Impala 选择使⽤ Hash Join,对于T3表选择使⽤ Broadcast ⽅式,直接把 T3 表⼴播到需要Join的节点上
分布式并行计划流程
- T1 和 T2 使⽤ Hash join,此时需要按照 id 的值分别将 T1 和 T2 分散到不同的 Impalad 进程,但是相同的 id会散列到相同的Impalad进程,这样每⼀个Join之后是全部数据的⼀部分
- T1 与 T2 Join 之后的结果数据再与 T3 表进⾏Join,此时 T3 表采⽤ Broadcast ⽅式把⾃⼰全部数据(id列)⼴播到需要的 Impala 节点上
- T1,T2,T3 Join 之后再根据 Group by 执⾏本地的预聚合,每⼀个节点的预聚合结果只是最终结果的⼀部分(不同的节点可能存在相同的group by的值),需要再进⾏⼀次全局的聚合
- 全局的聚合同样需要并⾏,则根据聚合列进⾏ Hash 分散到不同的节点执⾏ Merge 运算(其实仍然是⼀次聚合运算),⼀般情况下为了较少数据的⽹络传输, Impala会选择之前本地聚合节点做全局聚合⼯作
T1,T2,T3 Join 之后再根据 Group by 执⾏本地的预聚合,每⼀个节点的预聚合结果只是最终结果的⼀部分(不同的节点可能存在相同的group by的值),需要再进⾏⼀次全局的聚合 - 全局的聚合同样需要并⾏,则根据聚合列进⾏ Hash 分散到不同的节点执⾏ Merge 运算(其实仍然是⼀次聚合运算),⼀般情况下为了较少数据的⽹络传输, Impala会选择之前本地聚合节点做全局聚合⼯作
- 通过全局聚合之后,相同的 key 只存在于⼀个节点,然后对于每⼀个节点进⾏排序和 TopN 计算,最终将每⼀个全局聚合节点的结果返回给 Coordinator 进⾏合并、排序、limit计算,返回结果给⽤户