Python对文件的创建和读写操作
Python对文件的创建和读写操作
Python提供了文件读写的方法,并且提供了内置的CSV模块,可以对文本文件和二进制文件方便的进行读写操作。除此之外,Python还提供了os模块和shutil模块可以对文件和目录进行查询、创建、删除等操作。本章将详细介绍文件操作的这些方法和模块。
7.1 文件的概念及类型
Python使用文件对象来处理文件,文件对象根据读写模式决定如何读取文件数据。
7.1.1 文件类型
计算机已经成为了日常工作中必不可少的工具,在使用计算机的过程中会接触各种格式的文件:文档.doc,图片.png、.jpg等,视频.mp4,音频.mp3等。文件是指保存于存储介质上的信息集合。存储介质可以是纸张、计算机磁盘、U盘或者其他电子媒介。按存储格式可将文件分为文本文件和二进制文件。
文本文件是一种典型的顺序文件,其文件的逻辑结构又属于流式文件。文本文件根据字符编码保存或读取由字符组成的文本,一个字符占一个或多个字节。常见的文本文件扩展名有txt、.doc.、.docx、.wps、csv。
二进制文件存储的是数据的二进制编码(位0和位1),将数据在内存中的存储形式复制到文件中。二进制文件没有字符编码,按字节存储和读取,文件的存储格式与用途无关,通常可以用来保存图片(.bmp、.gif、.jpg、.pic、.png、.tif)、音频(.mp3、.wma)、视频(.mp4)等。
7.1.2 CSV文件的基本概念
CSV(Comma-Separated Values)逗号分隔值文件格式,是一种通用相对简单的纯文本文件格式,被广泛应用在程序之间转移表格数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。因为大量程序都支持某种CSV变体,至少是作为一种可选择的输入/输出格式。"CSV"并不是一种单一的、定义明确的格式。在实践中,"CSV"泛指具有以上特征的任何文件。建议使用WORDPAD或是记事本来打开csv文件,也可使用EXCEL打开,但是需要注意编码格式。
7.1.3 JSON文件的基本概念
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。易于人阅读和编写。同时也易于机器解析和生成。它基于ECMAScript(欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据,易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
JSON 是 JS 对象的字符串表示法,它使用文本表示一个 JS 对象的信息,本质是一个字符串。JSON 可以和JS对象互相转换。
任何支持的类型都可以通过 JSON 来表示,例如字符串、数字、对象、数组等。但是对象和数组是比较特殊且常用的两种类型。
对象:对象是一个无序的"键:值"对集合。使用花括号{}将"键:值"对包裹起来 。每个"键"后有":"冒号;“键:值"对之间使用”,"逗号分隔。在面向对象的语言中,键为对象的属性,值为对应的属性值。键可以使用整数或字符串来表示,值可以是任意类型。类似Python中的字典结构。对象结构:
{"key01": "value01", "key02": "value02,....}
数组:数组使用方括号 [] 包裹起来的内容,数据结构为 [“java”, “javascript”, “vb”, …] 的索引结构。数组是一种比较特殊的数据类型,使用索引获取数组中的元素,类似于Python中的列表,数组值的类型可以是任意类型。数组结构:
[{"firstName": "Brett", "lastName":"McLaughlin"},
{"firstName":"Jason", "lastName":"Hunter"}]
简单来说,JSON 可以将 JavaScript 对象中表示的一组数据转换为字符串,然后可以在网络或者程序之间轻松地传递这个字符串,并在需要的时候将它还原为各编程语言所支持的数据格式。
7.2 Python读取文件
Python提供了open()函数用来处理文件,并返回其关联的文件对象。在对文件进行处理过程都需要使用到这个函数,
如果该文件无法被打开,会抛出 OSError。open()函数的语法如下:
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 文件路径(相对路径或者绝对路径)
- mode: 文件打开模式
- buffering: 设置缓冲
- encoding: 编码格式,一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
参数mode为控制文件打开的模式,可选项详情如下:
| 模式 | 描述 |
|---|---|
| t | 文本模式 。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
打开文件后,Python用一个文件指针记录当前读写位置。使用"a"模式打开文件时,文件指针指向文件尾;以"r"模式打开时,文件指针指向文件头。Python始终在文件指针的位置读写数据,读取或写入一个数据后,根据数据长度,向后移动文件指针。
通常,Python使用内存缓冲区缓存文件数据。文件使用完后需要使用close()方法关闭文件,文件关闭时,Python将缓存的数据写入文件,然后关闭文件,并释放对文件的引用。Python会关闭未使用的文件。示例如下:
file = open('homework.txt', mode='w', encoding='utf8')
# file为文件对象,使用完成后需要关闭
file.close() # 关闭文件
运行代码后会在同级目录下创建出homework.txt的文本文件,如图7-1所示:

open()函数打开文件使用完后需要使用close()将文件关闭,如果不进行关闭操作,可能会引起其他程序调用该文件时文件被占用的错误。Python还提供了with语句可以和open()函数一起使用,with语句会自动将打开的文件关闭,示例如下:
>>> with open('filename', mode='r') as f:
... print(f.read())
7.2.1 读取文本文件
文本文件homework.txt的内容如下,读取文本内容将使用该文件说明如何读取文本内容:
这是第一行内容: hello
这是第二行内容: python
这是第三行内容: python is the best
使用open()函数打开文件后会创建一个文件对象,对文件对象进行只读操作,参数mode选择’r’,方法如下:
- file.read([size]):从文件中读取指定的字节数,如果未给定字节数或字节数为负则读取所有。示例如下:
>>> file = open('homework.txt', mode='r', encoding='utf8') # 只读方式打开文件
>>> print(file.read()) # 未指定参数,读取所有
这是第一行内容: hello
这是第二行内容: python
这是第三行内容: python is the best
>>> file.close()
>>> file = open('homework.txt', mode='r', encoding='utf8') # 只读方式打开文件
>>> print(file.read(5)) # 指定读取5个字符
这是第一行
>>> file.close()
- file.readline([size]): 从文件中读取整行,包括 “\n” 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 “\n” 字符。
>>> file = open('homework.txt', mode='r', encoding='utf8')
>>> print(file.readline()) # 未指定参数,只读取一行
这是第一行内容: hello
>>> file.close()
>>> file = open('homework.txt', mode='r', encoding='utf8')
>>> print(file.readline(5)) # 指定读取5个字符
这是第一行
>>> file.close()
- file.readlines([sizeint]):从文件中读取所有行直到结束(遇到结束符 EOF)并返回列表,每一行的字符串作为一个列表元素,结束符 EOF 返回空字符串。
>>> file = open('homework.txt', mode='r', encoding='utf8')
>>> print(file.readlines()) # 未指定参数,读取所有行
['这是第一行内容: hello\n', '这是第二行内容: python\n', '这是第三行内容: python is the best']
>>> file.close()
>>> file = open('homework.txt', mode='r', encoding='utf8')
>>> print(file.readlines(5)) # 指定读取5个字符
['这是第一行内容: hello\n']
>>> file.close()
7.2.2 读取二进制文件
图像文件7-2.png的内容如下,读取图像内容将使用该图像说明如何使用二进制读取图像内容:

二进制文件读取的是bytes字符串,使用open()函数打开文件创建文件对象,该文件为图像需要进行二进制读取操作,参数mode选择’rb’,示例如下:
>>> file = open('7-2.png', mode='rb')
>>> img = file.read() # 读取图像、视频、音频等文件时需要全部读取
>>> print(img) # 打印二进制的图像编码
b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x01\x00H\x00H\x00\x00\xff\xdb\x00C\x00\r\t\n\x0b\n\x08\r\x0b\n\x0b\x0e\x0e\r\x0f\x13 \x15\x13\x12\x12\x13\'\x1c\x1e\x17 .)10.)-,3:J>36F7...内容太长,省略
>>> file.close()
7.3 Python写入文件
文本文件homework.txt的内容如下,写入文本内容将使用该文件说明如何写入文本内容:
这是第一行内容: hello
这是第二行内容: python
这是第三行内容: python is the best
使用open()函数打开文件后会创建一个文件对象,对文件对象进行写入操作,参数mode可选择’w’,‘w+’,‘a’,‘a+’,‘r+’,方法如下:
-
file.write(str):用于向文件中写入指定字符串。
- 使用’w’模式打开文件
# 使用'w'模式打开文件 >>> file = open('homework.txt', mode='w', encoding='utf8') >>> str01 = '这是第四行: Learn Python well' >>> file.write(str01) >>> file.close()写入完毕后,手动打开homework.txt,发现文本内容仅有一行,其他三行均被删除,如下所示:
这是第四行: Learn Python well使用’w’模式打开文件时会将文件内原有的内容删除,删除原内容后从文件开头写入,因此文件只保存当前写入的内容。使用’w+'模式也是同样的效果,'w+'模式不仅可以进行写入还可以进行读取操作。
- 使用’a’模式打开文件
# 使用'a'模式打开文件 >>> file = open('homework.txt', mode='a', encoding='utf8') >>> str01 = '\n这是第四行: Learn Python well' >>> file.write(str01) >>> file.close()写入完毕后,手动打开homework.txt,如下所示:
这是第一行内容: hello 这是第二行内容: python 这是第三行内容: python is the best 这是第四行: Learn Python well使用’a’模式打开文件时不会将文件内原有的内容删除,会在原文件结尾处进行写入新内容。使用’a+'模式也是同样的效果,'a+'模式不仅可以进行写入还可以进行读取操作。
-
file.writelines(sequence):用于向文件中写入一序列的字符串。这一序列字符串可以是由迭代对象产生的,如一个字符串列表。换行需要制定换行符 \n。
>>> file = open('homework.txt', mode='w', encoding='utf8') >>> list01 = ['python\n', 'is\n', 'the\n', 'best\n'] >>> file.writelines(list01)写入完毕后,手动打开homework.txt,如下所示:
python is the best
7.3.1 写入文本文件
写入文本文件open()函数的参数mode可选择’w’,‘w+’,‘a’,‘a+’,‘r+’,示例如下:
- 使用’a’模式打开文件
file = open('homework.txt', mode='a', encoding='utf8')
list01 = ['python\n', 'is\n', 'the\n', 'best\n']
file.writelines(list01)
写入完毕后,手动打开homework.txt,如下所示:
python
is
the
best
python
is
the
best
- 使用’r+'模式打开文件,用于写入
file = open('homework.txt', mode='r+', encoding='utf8')
list01 = ['python\n', 'is\n', 'the\n', 'best\n']
file.writelines(list01)
写入完毕后,手动打开homework.txt,如下所示:
python
is
the
best
-
使用’r+'模式打开文件,用于读取
>>> file = open('homework.txt', mode='r+', encoding='utf8') >>> print(file.read()) python is the best
7.3.2 写入二进制文件
读取图像7-2.png并将其写入文件file_new中,步骤如下:
-
使用’rb’模式打开文件,用于读取:
>>> file = open('7-2.png', mode='rb') >>> f = file.read() # f为二进制的字符串 -
使用’wb’模式打开文件,用于写入:
>>> file_new = open('7-3.png', mode='wb') >>> file_new.write(f) # 将二进制字符串f写入新创建的7-3.png文件中写入完成后文件夹中会出现’7-3.png’的图像,如下图所示:

- 使用PIL库的Image模块可以自动调用计算机中的图片查看程序打开新创建的图片7-3.png,代码如下:
from PIL import Image
im = Image.open('7-3.png', mode='r') # 使用Image模块中的open方法读取图像
im.show() # 显示图像
图像能够正常打开显示,表示读取和写入成功。打开后的图像显示如下:

7.4 认识os模块及shutil模块
文件操作通常会涉及到目录操作。目录就是文件夹,目录中可以存储子目录和文件信息。Python中的os模块和shutil模块提供了非常丰富的方法对文件和目录进行处理。
7.4.1 os模块
os模块提供了一种使用与操作系统相关的功能的便捷式途径。如复制、创建、修改、删除文件及文件夹。os模块提供了一个可移植的方法来使用操作系统的功能,使得程序能够跨平台使用,同一个程序可以在Windows和Linux等操作系统中运行。使用时要先导入os模块,代码如下:
import os
1.系统操作
os.sep:返回系统路径的分隔符
Linux类系统的路径分隔符是“/”,windows系统的分隔符是“\”
>>> print(os.sep) # 返回系统路径的分隔符
\
os.name:返回当前平台操作系统
当返回的值为posix时,则为Linux系统;返回值为nt时,则为Windows系统
>>> print(os.name) # 输出当前操作系统类型
nt
>>> if os.name == 'posix':
... print('Linux')
>>> elif os.name == 'nt':
... print('Windows')
>>> else:
... print('其他')
Windows
os.environ 系统的环境变量,输出为一个字典形式,可以通过key得到具体信息
>>> print(os.environ)
os.environ.get(‘PATH’) 获得指定的环境变量的内容
result = os.environ
print(result)
print(result['PATH'])
os.getenv(‘PATH’)获得指定的环境变量的内容
>>> print(os.getenv('PATH'))
2.查询工作路径
os.getcwd():查询当前工作路径
>>> print(os.getcwd())
3.对目录进行操作
os.listdir(目录名称) :列出目录中的所有文件以及目录,返回一个列表。
>>> print(os.listdir('../第七章/'))
['7-2.png', '7-3.png', 'homework.txt', 'public', 'test.py']
os.mkdir(目录名称) :创建一个目录,不能递归创建,目录存在时再创建报错。
>>> os.mkdir('../第七章/test/')
os.makedirs(目录名称) :递归创建目录,目录存在时再创建报错。
>>> os.makedirs('../第七章/test/test01/test02/')
os.rmdir(目录名称):删除一个空目录,不能递归删除,目录不存在时以及存在文件时候报错。
>>> os.rmdir('../第七章/test/test01/test02/')
os.removedirs(目录名称):递归删除目录,目录不存在时以及存在文件时候报错。
>>> os.removedirs('./public/dir2/tops2/toto2')
4.对文件以及目录进行重命名
os.rename(‘oldname’, ‘newname’):当新名字已经被使用的时候,重命名失败。
>>> print(os.listdir('/public'))
>>> os.rename('/public/toto','/public/lala')
>>> os.rename('/public/dir','/public/top')
>>> print(os.listdir('/public'))
5.path模块
1.判断
os.path.exists(文件/目录):判断文件/目录是否存在,若存在返回True 否则返回False
>>> print(os.path.exists('/public/toto'))
os.path.isdir(目标):判断目标是否为目录,若是返回True 否则返回False
>>> print(os.path.isdir('/public/lala'))
os.path.isfile(目标):判断目标是否为文件,若是返回True 否则返回False
>>> print(os.path.isfile('/public/top'))
os.path.isabs(目标路径):判断是否为绝对路径,若是返回True 否则返回False
>>> print(os.path.isabd('/public/top'))
-
path模块对文件/目录路径以及名称进行处理
os.path.abspath(文件/目录):以绝对路径显示文件或者目录,此处的文件或者目录是绝对路径的时候,不做改变,输出原有的内容,当不是绝对路径的时候,将当前所在的位置的绝对路径添加到输入的文件或者目录相对路径前面,形成绝对路径。
>>> print(os.path.abspath('/lala/tops'))
os.path.join(路径1,路径2):将路径1 和路径2 连接起来,如果路径2 为绝对路径则输出路径2。
>>> print(os.path.join('toto/lele','/lala/tops'))
os.path.basename(文件/目录的路径):返回文件或者目录名称
>>> print(os.path.basename('toto/lele/lala/tops'))
os.path.dirname(文件/目录的路径): 返回指定文件或者目录的上层路径
>>> print(os.path.dirname('toto/lele/lala/tops'))
os.path.splitext(文件):将文件后缀进行分离,返回一个元组,元组的第一个元素为除过文件名称后缀剩余部分,第二个元素为文件后缀;当文件没有后缀的时候,第二个元素为空。
>>> print(os.path.splitext('toto/lele.html'))
>>> print(os.path.splitext('toto/lele'))
os.path.split(‘文件/目录’):将给出的文件或者目录进行分离,返回一个元组,第一个元素为除过目标文件或者目录之外剩余的路径,第二个元素为文件或者目录名称;当只有文件或者目录名称时候,第一个元素为空。
print(os.path.split('/haha/lele/yeye/toto'))
print(os.path.split('toto'))
7.4.2 shutil模块
os 模块提供了创建文件、删除文件、查看文件属性的操作,还提供了对文件路径的操作,但是对于文件的复制、移动、压缩、打包等操作没有提供相应的函数。但是Python提供了另外一个高阶文件操作的模块作为os模块的补充。shutil模块提供了一系列对文件和文件集合的高阶操作。 特别是提供了一些支持文件拷贝和删除的函数。
1.复制文件
shutil模块提供了一系列复制功能的函数,如下表所示:
| 函数 | 说明 |
|---|---|
| shutil.copyfileobj(fsrc, fdst[, length]) | 将文件类对象 fsrc 的内容拷贝到文件类对象 fdst。 |
| shutil.copyfile(src, dst, *, follow_symlinks=True) | 将名为 src 的文件的内容(不包括元数据)拷贝到名为 dst 的文件并以尽可能高效的方式返回 dst。 |
| shutil.copymode(src, dst, *, follow_symlinks=True) | 从 src拷贝权限位到 dst,src 和 dst均为路径类对象或字符串形式的路径名。 |
| shutil.copystat(src, dst, *, follow_symlinks=True) | 从 src 拷贝权限位、最近访问时间、最近修改时间以及旗标到 dst。 |
| shutil.copy(src, dst,*, follow_symlinks=True) | 将文件src拷贝到文件或目录dst。 src和dst应为路径类对象或字符串。 |
| shutil.copy2(src, dst, *, follow_symlinks=True) | 类似于 copy(),区别在于copy2()还会尝试保留文件的元数据。 |
| shutil.copytree(src,dst, symlinks=False, ignore=None, copy_function=copy2, ignore_dangling_symlinks=False, dirs_exist_ok=False) | 将以 src为根起点的整个目录树拷贝到名为 dst的目录并返回目标目录。 dirs_exist_ok指明是否要在 dst或任何丢失的父目录已存在的情况下引发异常。 |
常用的函数详情如下:
shutil.copy(src, dst)可以将文件src拷贝到文件或目录dst。如果dst是目录,则会使用src相同的文件名创建,文件权限也会复制,返回值是复制后的文件绝对路径字符串,如果dst是文件,则覆盖文件中的内容,示例如下:
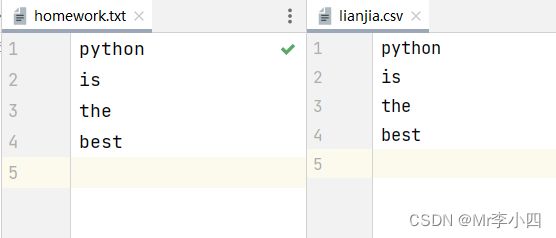
>>> shutil.copy(shutil.copy('homework.txt', 'lianjia.csv'))
# 运行完后'lianjia.csv'中的内容会被'homework.txt'中的内容覆盖。
如图7-5所示:
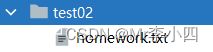
>>> shutil.copy('homework.txt', './test02/')
# 运行完后,在test02目录中会出现'homework.txt'文件
如图7-6所示:
shutil.copyfile(src, dst)可以从src文件复制内容到dst文件。dst必须是完整的目标文件名。返回值是复制后的文件绝对路径字符串,示例如下:
>>> import shutil
>>> shutil.copyfile('test.py', './test02/homework.txt')
如果src和dst是同一文件,就会引发错误shutil.Error。dst文件必须是可写的,否则将引发异常IOError。如果dst文件已经存在,则它会被替换。
2.删除文件和目录
shutil模块提供了删除文件和目录的函数,详情如下:
-
shutil.rmtree():删除路径指定的文件夹,并且删除这个文件夹中所有的文件和子文件夹,永久删除,使用时必须谨慎,语法如下:
shutil.rmtree(path, ignore_errors=False, onerror=None)参数path必须指向一个目录(但不能是一个目录的符号链接)
示例如下:
>>> import shutil >>> import os >>> os.makedirs('../第七章/test/test01/test02/') # 创建目录 >>> shutil.rmtree('../第七章/test/') # 删除目录
3.移动文件或目录
-
shutil.move() :可以将指定的文件或文件夹移动到目标路径下,返回值是移动后的文件绝对路径字符串,语法如下:
shutil.move(src, dst, copy_function=copy2)示例如下:
文件路径如图7-7所示:

>>> shutil.move('../第七章/test/test01/test02/', '../第七章/')
执行上述代码后test02的路径会发生变化,如图7-8 所示:

4.压缩与解压文件
shutil模块也提供了用于创建和读取压缩和解压文件的高层级工具:
shutil.make_archive():创建一个压缩文件( zip 或 tar)并返回其名称,语法如下:
shutil.make_archive(base_name, format, root_dir, owner, group, logger])
参数说明:
- base_name:要创建的文件名称,包括路径,去除任何特定格式的扩展名。
- format:压缩格式,可以是 “zip”, “tar”, “gztar” , “bztar” 或 “xztar”。
- root_dir: 要压缩的文件夹路径(默认当前目录)。
- owner:用户,默认当前用户。
- logger:用于记录日志,通常是logging.Logger对象。
示例如下:
>>> import shutil
>>> shutil.make_archive('D:\\python\\code\\第七章\\test\\test01', 'zip', root_dir='D:\\python\\code\\第七章\\test02')
shutil.unpack_archive():解压一个压缩包文件,语法如下:
shutil.unpack_archive(filename[, extract_dir[, format]])
参数说明:
- filename:是压缩文件的完整路径。
- extract_dir: 是压缩文件解压的文件夹路径。
- format:是解压格式,可以是 “zip”, “tar”, “gztar” , “bztar” 或 “xztar”。
示例如下:
>>> shutil.unpack_archive('D:\\python基础\\code\\第七章\\test\\test01.zip', 'D:\\code\\第七章\\test\\test01', 'zip')
bztar" 或 “xztar”。
- root_dir: 要压缩的文件夹路径(默认当前目录)。
- owner:用户,默认当前用户。
- logger:用于记录日志,通常是logging.Logger对象。
示例如下:
>>> import shutil
>>> shutil.make_archive('D:\\python\\code\\第七章\\test\\test01', 'zip', root_dir='D:\\python\\code\\第七章\\test02')
shutil.unpack_archive():解压一个压缩包文件,语法如下:
shutil.unpack_archive(filename[, extract_dir[, format]])
参数说明:
- filename:是压缩文件的完整路径。
- extract_dir: 是压缩文件解压的文件夹路径。
- format:是解压格式,可以是 “zip”, “tar”, “gztar” , “bztar” 或 “xztar”。
示例如下:
>>> shutil.unpack_archive('D:\\python基础\\code\\第七章\\test\\test01.zip', 'D:\\code\\第七章\\test\\test01', 'zip')