ES 7.7.0 数据迁移
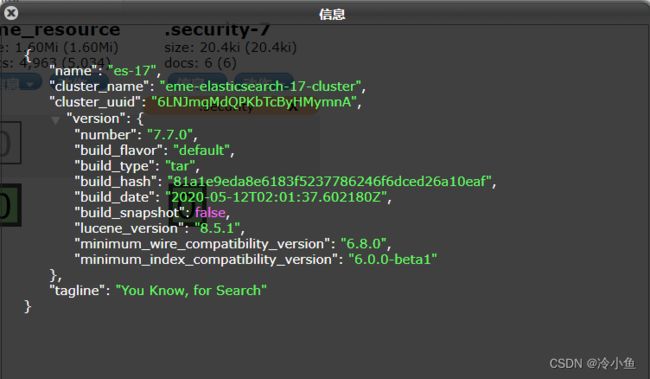
本文使用 elasticdump 做数据迁移,支持在线和离线俩种方式,适用于数据量比较小的情况。
1、Node 安装
由于elasticdump 依赖于 node,首先需要安装下node。
1.1、 Linux 安装
$ wget https://nodejs.org/dist/v10.15.0/node-v10.15.0-linux-x64.tar.xz
$ tar -xf node-v10.15.0-linux-x64.tar.xz
#配置相关的环境变量
$ vim /etc/profile
> PATH=$PATH:/software/node-v10.15.0-linux-x64/bin
$ source /etc/profile
1.2、Windows安装
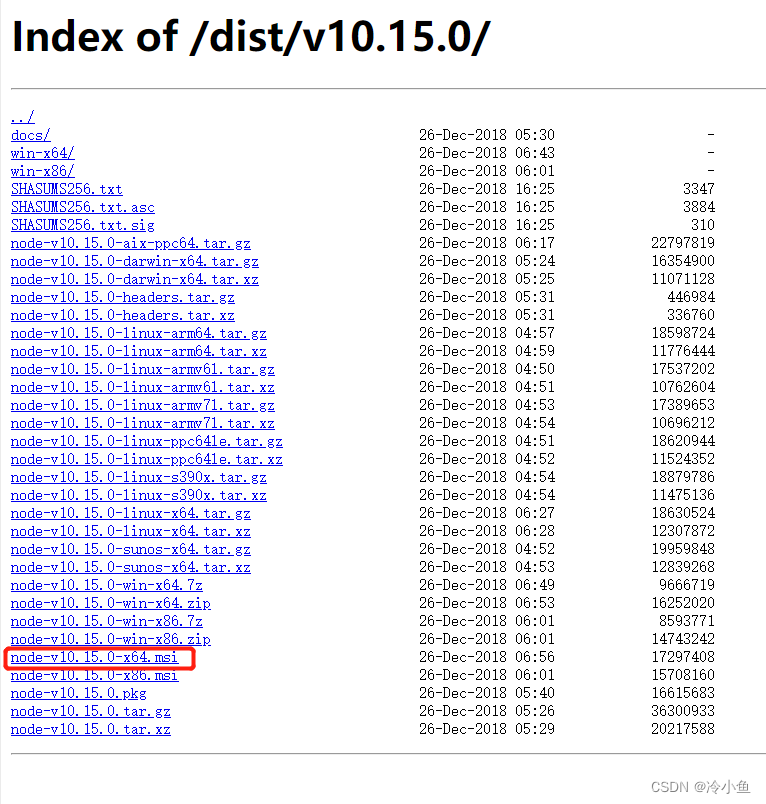
选择对应的windows版本一路下一步即可,以下是64位的安装包标注:
2、安装 elasticdump
linux和windows基本相同,建议全局安装下:
#本地安装和全局安装的区别在于它是否自动给你设置环境变量,其他的没有区别
# 本地安装
$ npm install elasticdump
$ ./bin/elasticdump
# 全局安装
$ npm install elasticdump -g
$ elasticdump
3、数据迁移
ES索引的迁移需要一个个的迁移,并且分:analyzer、mapping、data三部分。
备注:
http://production.es.com:9200/my_index 为源索引
http://staging.es.com:9200/my_index 为目标索引
“” 为换行符,一行可以不用写
如果es是有用户密码做为鉴权的,则需要修改下URL:
# 注意 elasticdump 提供给了--httpAuthFile 参数来做认证
--httpAuthFile When using http auth provide credentials in ini file in form
`user=<username>
password=<password>`
# 只需要写一个ini文件 ,文件中写入用户名和密码就可以了# 这里其实还有另外一个好的方法# 在--input参数和--output参数的的url中添加账号密码# 例如
elasticdump \
--input=http://prod-username:prod-passowrd@production.es.com:9200/my_index \
--output=http://stage-username:stage-password@staging.es.com:9200/my_index \
--type=data
3.1、在线迁移
#拷贝analyzer分词
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=http://staging.es.com:9200/my_index \
--type=analyzer
#拷贝映射
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=http://staging.es.com:9200/my_index \
--type=mapping
'#拷贝数据
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=http://staging.es.com:9200/my_index \
--type=data
3.2、离线迁移
3.2.1 备份
# 备份索引数据到文件里:
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=/data/my_index_mapping.json \
--type=mapping
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=/data/my_index.json \
--type=data
# 备份到标准输出,且进行压缩(这里有一个需要注意的地方,我查询索引信息有6.4G,用下面的方式备份后得到一个789M的压缩文件,这个压缩文件解压后有19G):
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=$ \
| gzip > /data/my_index.json.gz
# 把一个查询结果备份到文件中
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=query.json \
--searchBody '{"query":{"term":{"username": "admin"}}}'
3.2.2 恢复
# 将备份文件的数据导入ES
elasticdump \
--input=./data.json \
--output=http://es.com:9200
4、Docker 环境下ES迁移
# 镜像下载
$ docker pull taskrabbit/elasticsearch-dump
# 下面还是例子:通过镜像导出数据到本地
# 创建一个文件夹用于保存导出数据
$ mkdir -p /root/data
# 下面需要对路径进行映射并执行命令(导出mapping)
$ docker run --rm -ti -v /data:/tmp taskrabbit/elasticsearch-dump \
--input=http://production.es.com:9200/my_index \
--output=/tmp/my_index_mapping.json \
--type=mapping
# 导出(data)
$ docker run --rm -ti -v /root/data:/tmp taskrabbit/elasticsearch-dump \
--input=http://192.168.56.104:9200/test_index \
--output=/tmp/elasticdump_export.json \
--type=data
-----------------------------------------------------------------------------
# 以下内容为ES -> ES的数据迁移例子
$ docker run --rm -ti taskrabbit/elasticsearch-dump \
--input=http://production.es.com:9200/my_index \
--output=http://staging.es.com:9200/my_index \
--type=mapping
$ docker run --rm -ti taskrabbit/elasticsearch-dump \
--input=http://production.es.com:9200/my_index \
--output=http://staging.es.com:9200/my_index \
--type=data
5、附录
# Copy an index from production to staging with analyzer and mapping:
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=http://staging.es.com:9200/my_index \
--type=analyzer
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=http://staging.es.com:9200/my_index \
--type=mapping
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=http://staging.es.com:9200/my_index \
--type=data
# Backup index data to a file:
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=/data/my_index_mapping.json \
--type=mapping
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=/data/my_index.json \
--type=data
# Backup and index to a gzip using stdout:
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=$ \
| gzip > /data/my_index.json.gz
# Backup the results of a query to a file
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=query.json \
--searchBody='{"query":{"term":{"username": "admin"}}}'
# Copy a single shard data:
elasticdump \
--input=http://es.com:9200/api \
--output=http://es.com:9200/api2 \
--params='{"preference" : "_shards:0"}'
# Backup aliases to a file
elasticdump \
--input=http://es.com:9200/index-name/alias-filter \
--output=alias.json \
--type=alias
# Import aliases into ES
elasticdump \
--input=./alias.json \
--output=http://es.com:9200 \
--type=alias
# Backup templates to a file
elasticdump \
--input=http://es.com:9200/template-filter \
--output=templates.json \
--type=template
# Import templates into ES
elasticdump \
--input=./templates.json \
--output=http://es.com:9200 \
--type=template
# Split files into multiple parts
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=/data/my_index.json \
--fileSize=10mb
# Import data from S3 into ES (using s3urls)
elasticdump \
--s3AccessKeyId "${access_key_id}" \
--s3SecretAccessKey "${access_key_secret}" \
--input "s3://${bucket_name}/${file_name}.json" \
--output=http://production.es.com:9200/my_index
# Export ES data to S3 (using s3urls)
elasticdump \
--s3AccessKeyId "${access_key_id}" \
--s3SecretAccessKey "${access_key_secret}" \
--input=http://production.es.com:9200/my_index \
--output "s3://${bucket_name}/${file_name}.json"