Kubernetes容器网络(三):容器跨主机Overlay网络、路由模式实验
前言
前三篇文章我们分别介绍了Docker网络原理、Flannel网络原理、Calico网络原理,本文将通过实验的方式带你进一步理解容器跨主机网络实现
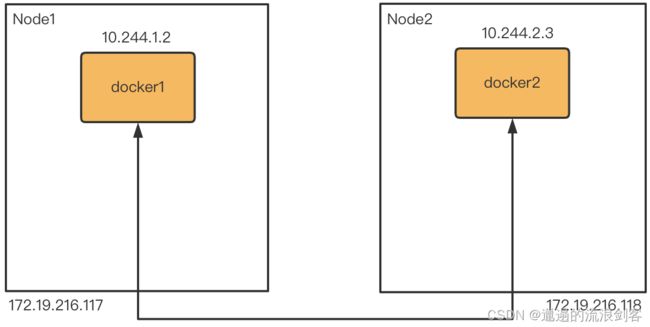
两个容器docker1和docker2分别位于节点Node1和Node2,如何实现容器的跨主机通信呢?一般来说有两种实现方式:
- 封包模式:利用Overlay网络协议在节点间建立隧道,容器之间的网络包被封装在外层的网络协议包中进行传输,例如:Flannel UDP、Flannel VXLAN、Calico IPIP
- 路由模式:容器间的网络包传输全部用三层网络的路由转发来实现,例如:Flannel host-gw、Calico
1、容器跨主机Overlay网络实验
1)、Flannel VXLAN
VXLAN(Virtual Extensible LAN)是一种网络虚拟化技术,它将链路层的以太网帧封装到UDP包中进行传输
VXLAN包的结构如下:

最内层是原始的二层以太网帧,外面加上一个VXLAN header,其中最重要的是VNI字段,它用来唯一标识一个VXLAN。也就是说,可以使用不同的VNI来区分不同的虚拟二层网络
在VXLAN header外面封装了正常的UDP包。VXLAN在UDP之上,实现了一个虚拟的二层网络,连接在这个虚拟二层网络上的主机可以相互通信
参照Flannel VXLAN的实现方案如下:

1)配置内核参数,允许IP forwarding
分别在Node1、Node2上执行:
sudo sysctl net.ipv4.conf.all.forwarding=1
2)创建容器
在Node1上执行:
sudo ip netns add docker1
在Node2上执行:
sudo ip netns add docker2
3)创建Veth pairs
分别在Node1、Node2上执行:
sudo ip link add veth0 type veth peer name veth1
4)将Veth的一端放入容器
在Node1上执行:
sudo ip link set veth0 netns docker1
在Node2上执行:
sudo ip link set veth0 netns docker2
5)创建bridge
分别在Node1、Node2上安装bridge-utils并创建bridge br0:
yum install -y bridge-utils
sudo brctl addbr br0
6)将Veth的另一端接入bridge
分别在Node1、Node2上执行:
sudo brctl addif br0 veth1
7)为容器内的网卡分配IP地址,并激活上线
在Node1上执行:
sudo ip netns exec docker1 ip addr add 10.244.1.2/24 dev veth0
sudo ip netns exec docker1 ip link set veth0 up
在Node2上执行:
sudo ip netns exec docker2 ip addr add 10.244.2.3/24 dev veth0
sudo ip netns exec docker2 ip link set veth0 up
8)Veth另一端的网卡激活上线
分别在Node1、Node2上执行:
sudo ip link set veth1 up
9)为bridge分配IP地址,并激活上线
在Node1上执行:
sudo ip addr add 10.244.1.1/24 dev br0
sudo ip link set br0 up
在Node2上执行:
sudo ip addr add 10.244.2.1/24 dev br0
sudo ip link set br0 up
10)将bridge设置为容器的缺省网关
在Node1上执行:
sudo ip netns exec docker1 route add default gw 10.244.1.1 veth0
在Node2上执行:
sudo ip netns exec docker2 route add default gw 10.244.2.1 veth0
11)创建VXLAN虚拟网卡
VXLAN需要在宿主机上创建一个虚拟网络设备对VXLAN的包进行封装和解封装,实现这个功能的设备称为VTEP(VXLAN Tunnel Endpoint)。宿主机之间通过VTEP建立隧道,在其中传输虚拟二层以太网帧
在Node1上创建vxlan0:
sudo ip link add vxlan0 type vxlan \
id 0 \
local 172.19.216.117 \
dev eth0 \
dstport 4789 \
nolearning
为vxlan0分配IP地址并激活:
sudo ip addr add 10.244.1.1/32 dev vxlan0
sudo ip link set vxlan0 up
为了让Node1上访问10.244.2.0/24网段的数据包能进入隧道,需要增加如下的路由规则:
sudo ip route add 10.244.2.0/24 dev vxlan0
在Node2上执行相应命令:
sudo ip link add vxlan0 type vxlan \
id 0 \
local 172.19.216.118 \
dev eth0 \
dstport 4789 \
nolearning
sudo ip addr add 10.244.2.1/32 dev vxlan0
sudo ip link set vxlan0 up
sudo ip route add 10.244.1.0/24 dev vxlan0
12)手工更新ARP和FDB
虚拟设备vxlan0会用ARP和FDB(forwarding database)数据库中记录的信息,填充网络协议包,建立节点间转发虚拟网络数据包的隧道
我们知道,在二层网络上传输IP包,需要先根据目的IP地址查询目的MAC地址,这就是ARP(Address Resolution Protocol)协议的作用。我们应该可以通过ARP查询到其他节点上容器IP地址对应的MAC地址,然后填充在VXLAN内层的网络包中
FDB是记录网桥设备转发数据包的规则。虚拟网络数据包根据上面定义的路由规则,从br0进入了本机的vxlan0隧道入口,应该可以在FDB中查询到隧道出口的MAC地址应该如何到达,这样,两个VTEP就能完成隧道的建立
vxlan为了建立节点间的隧道,需要一种机制,能让一个节点的加入、退出信息通知到其他节点。Flannel会在节点启动的时候采用某种机制自动更新其他节点的ARP和FDB数据库。现在我们的实验只能在两个节点上手动更新ARP和FDB
首先在两个节点上查询到设备vxlan0的MAC地址,在我当前的环境:
Node1上vxlan0的MAC地址是02:40:77:fd:c1:aa,Node2上vxlan0的MAC地址是2e:0e:84:db:30:0e
然后在Node1上增加ARP和FDB的记录:
sudo ip neighbor add 10.244.2.3 lladdr 2e:0e:84:db:30:0e dev vxlan0
sudo bridge fdb append 2e:0e:84:db:30:0e dev vxlan0 dst 172.19.216.118
确认下执行结果:
[root@node1 ~]# arp -n
Address HWtype HWaddress Flags Mask Iface
...
10.244.2.3 ether 2e:0e:84:db:30:0e CM vxlan0
ARP中已经记录了Node2上容器IP对应的MAC地址。再查看FDB的情况:
[root@node1 ~]# sudo bridge fdb
...
2e:0e:84:db:30:0e dev vxlan0 dst 172.19.216.118 self permanent
根据最后一条新增规则,就可以知道如何到达Node2上隧道的出口vxlan0。隧道两端是使用UDP进行传输,即容器间通讯的二层以太网帧是靠UDP在宿主机主机之间通信
类似的,在Node2上执行下面的命令:
sudo ip neighbor add 10.244.1.2 lladdr 02:40:77:fd:c1:aa dev vxlan0
sudo bridge fdb append 02:40:77:fd:c1:aa dev vxlan0 dst 172.19.216.117
13)测试容器的跨节点通信
现在,容器docker1和docker2之间就可以相互访问了
从docker1访问docker2,在Node1上执行:
sudo ip netns exec docker1 ping -c 3 10.244.2.3
从docker2访问docker1,在Node2上执行:
sudo ip netns exec docker2 ping -c 3 10.244.1.2
2)、Calico IPIP
ipip即IPv4 in IPv4,在IPv4报文的基础上再封装一个IPv4报文,是Linux原生支持的一种三层隧道
参照Calico IPIP的实现方案如下:

1)配置内核参数允许IP forwarding,创建容器、Veth pairs、bridge,设置IP,激活虚拟设备
在Node1上执行:
sudo sysctl net.ipv4.conf.all.forwarding=1
sudo ip netns add docker1
sudo ip link add veth0 type veth peer name veth1
sudo ip link set veth0 netns docker1
sudo brctl addbr br0
sudo brctl addif br0 veth1
sudo ip netns exec docker1 ip addr add 10.244.1.2/24 dev veth0
sudo ip netns exec docker1 ip link set veth0 up
sudo ip link set veth1 up
sudo ip addr add 10.244.1.1/24 dev br0
sudo ip link set br0 up
sudo ip netns exec docker1 route add default gw 10.244.1.1 veth0
在Node2上执行:
sudo sysctl net.ipv4.conf.all.forwarding=1
sudo ip netns add docker2
sudo ip link add veth0 type veth peer name veth1
sudo ip link set veth0 netns docker2
sudo brctl addbr br0
sudo brctl addif br0 veth1
sudo ip netns exec docker2 ip addr add 10.244.2.3/24 dev veth0
sudo ip netns exec docker2 ip link set veth0 up
sudo ip link set veth1 up
sudo ip addr add 10.244.2.1/24 dev br0
sudo ip link set br0 up
sudo ip netns exec docker2 route add default gw 10.244.2.1 veth0
2)加载ipip
sudo modprobe ipip
通过lsmod | grep ipip查看内核是否加载
[root@node1 ~]# lsmod | grep ipip
ipip 16384 0
tunnel4 16384 1 ipip
ip_tunnel 32768 1 ipip
当系统加载ipip模块或者创建一个ipip设备时,Linux内核会在每个命名空间中创建一个tunl0默认设备,属性为local=any和remote=any
tunl0是工作在one-to-many模式下的,当系统接收到ipip协议数据包时,如果内核找不到local/remote属性与数据包中源地址或目标地址更匹配的另一个ipip设备,内核会触发回退,将报文转发到tunl0
此时tunl0构造一个新的数据包,源地址是本机IP,目的地址是网关IP,从默认路由设备发出
[root@node1 ~]# ip tunnel show tunl0
tunl0: any/ip remote any local any ttl inherit nopmtudisc
[root@node1 ~]# ifconfig tunl0
tunl0: flags=128<NOARP> mtu 1480
tunnel txqueuelen 1000 (IPIP Tunnel)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
激活tunl0
sudo ip link set tunl0 up
3)添加路由规则
在Node1上执行:
sudo ip route add 10.244.2.0/24 dev tunl0 via 172.19.216.118 onlink
这条路由规则的含义是:目的IP地址属于10.244.2.0/24网段的IP包。应该经过本机的tunl0设备发出去;并且,它的下一跳(next-hop)是Node2的IP地址
docker1访问docker2的IP包进入IP隧道设备之后,就会被Linux内核的IPIP驱动接管。IPIP驱动会将这个IP包直接封装在一个宿主机网络的IP包中,如下所示:

经过封装后的新的IP包的目的地址(Outer IP Header部分),正是原IP包的下一跳地址,即Node2的IP地址:172.19.216.118。而IP包本身,则会被直接封装成新IP包的Payload。这样,原先从docker1访问docker2的IP包就被伪装成了一个从Node1到Node2的IP包
当这个IP包到达Node2时,Node2的网络内核栈会使用IPIP驱动进行解包,从而拿到原始的IP包。然后,原始IP包就会经过路由规则和Veth pairs设备到达目的容器docker2内部
类似的,在Node2上执行下面的命令:
sudo ip route add 10.244.1.0/24 dev tunl0 via 172.19.216.117 onlink
4)测试容器的跨节点通信
现在,容器docker1和docker2之间就可以相互访问了
从docker1访问docker2,在Node1上执行:
sudo ip netns exec docker1 ping -c 3 10.244.2.3
从docker2访问docker1,在Node2上执行:
sudo ip netns exec docker2 ping -c 3 10.244.1.2
2、容器跨主机通信路由模式实验
宿主机将它负责的容器IP网段,以某种方式告诉其他节点,然后每个节点根据收到的宿主机-容器IP网段的映射关系,配置本机路由表
这样对于容器间跨节点的IP包,就可以根据本机路由表获得到达目的容器的网关地址,即目的容器所在的宿主机地址。接着把IP包封装成二层以太网帧时,将目的MAC地址设置为网关的MAC地址,IP包就可以通过二层网络送达目的容器所在的宿主机
至于用什么方式将宿主机-容器IP网段的映射关系发布出去,不同项目采用了不同的实现方案:
- Flannel:将这些信息集中存储到etcd中,每个节点从etcd自动获取数据,更新宿主机路由表
- Calico:使用BGP(Border Gateway Protocol)协议交换共享路由信息,每个宿主机都是运行在它之上的容器的边界网关
路由模式的工作原理其实就是将每个子网的下一跳设置成了该子网对应的宿主机的IP地址,要求宿主机之间是二层连通的
如果宿主机之间跨了网段怎么办?宿主机之间的二层网络不通,虽然知道目的容器所在的宿主机,但没办法将目的MAC地址设置为那台宿主机的MAC地址。
Calico有两种解决方案:
- IPIP模式,在跨网段的宿主机之间建立隧道
- 让宿主机之间的路由器学习到容器路由规则,每个路由器都知道某个容器IP网段是哪个宿主机负责的,容器间的IP包就能正常路由了
实验方案如下:
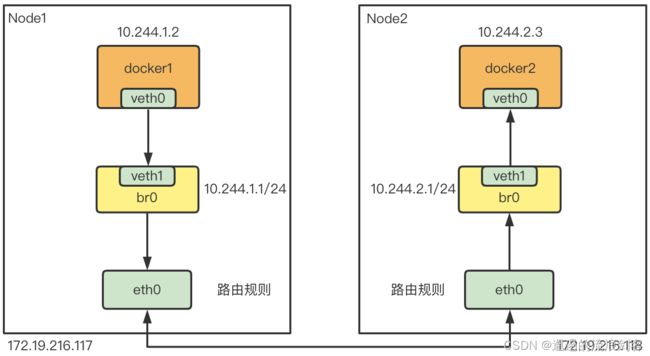
路由模式的实验比较简单,关键在于宿主机上路由规则的配置。为了简化实验,这些路由规则都是我们手工配置,而且两个节点之间二层网络互通,没有跨网段
1)配置内核参数允许IP forwarding,创建容器、Veth pairs、bridge,设置IP,激活虚拟设备
在Node1上执行:
sudo sysctl net.ipv4.conf.all.forwarding=1
sudo ip netns add docker1
sudo ip link add veth0 type veth peer name veth1
sudo ip link set veth0 netns docker1
sudo brctl addbr br0
sudo brctl addif br0 veth1
sudo ip netns exec docker1 ip addr add 10.244.1.2/24 dev veth0
sudo ip netns exec docker1 ip link set veth0 up
sudo ip link set veth1 up
sudo ip addr add 10.244.1.1/24 dev br0
sudo ip link set br0 up
sudo ip netns exec docker1 route add default gw 10.244.1.1 veth0
在Node2上执行:
sudo sysctl net.ipv4.conf.all.forwarding=1
sudo ip netns add docker2
sudo ip link add veth0 type veth peer name veth1
sudo ip link set veth0 netns docker2
sudo brctl addbr br0
sudo brctl addif br0 veth1
sudo ip netns exec docker2 ip addr add 10.244.2.3/24 dev veth0
sudo ip netns exec docker2 ip link set veth0 up
sudo ip link set veth1 up
sudo ip addr add 10.244.2.1/24 dev br0
sudo ip link set br0 up
sudo ip netns exec docker2 route add default gw 10.244.2.1 veth0
2)添加路由规则
在Node1上执行:
sudo ip route add 10.244.2.0/24 via 172.19.216.118
在Node2上执行:
sudo ip route add 10.244.1.0/24 via 172.19.216.117
当docker1访问docker2时,IP包会从veth到达br0,然后根据Node1上刚设置的路由规则,访问10.244.2.0/24网段的网关地址为Node2,这样,IP包就能路由到Node2了
同时,Node2的路由表中包含这样的一条规则:
[root@node2 ~]# ip route
...
10.244.2.0/24 dev br0 proto kernel scope link src 10.244.2.1
到达Node2的IP包,会根据这条规则路由到网桥br0,最终到达docker。反过来从docker2访问docker1的过程也是类似
小结
两种容器跨主机的通信方案我们都实验了一下,现在做个简单总结对比:
- 封包模式对基础设施要求低,三层网络通就可以了。但封包、解包带来的性能损耗较大
- 路由模式性能好,但要求二层网络连通,或者在跨网段的情况下,要求路由器能配合学习路由规则
参考:
Docker跨主机Overlay网络动手实验
Docker跨主机通信路由模式动手实验