【Fine Tune】神经网络调优总结
参考:A Comprehensive guide to Fine-tuning Deep Learning Models in Keras code: github
目录
1 为什么要调优:
2 什么时候调优:
3 调优技巧
4 调优方法(VGG16 )
5 调优VGG16 分类Cats. vs Dogs
5.1 准备数据
5.2 网络结构
5.3 构建网络
5.3 测试评估
5.4 Explore冻结层数
6 调优 ResNet50
6.1 ResNet50 结构特点
6.2 调优问题
6.3 手动:建立/修改/训练 模型
6.5 预测评估
6.6 自动:用keras.applicaitons.resnet50构建网络
总结
1 为什么要调优:
一个深度神经网络模型,会包含成千上万的参数。参数越多,需要的样本数量也会随之增长。所以当我们在一个小的训练集上建立如此大的神经网络时,模型的泛化能力非常差,就会非常容易发生过拟合。所以实践中,为了在较小的训练集上建立深度神经网络模型并且避免发生过拟合,就会利用调优方法,即:将一个已经在较大的数据集上(例如ImageNet)训练好的网络模型,在自己的小数据集上继续训练。但是要保证,两个数据集不能毫不相关,这样才能保证预训练好的模型所学习到的特征是可以被利用的。
2 什么时候调优:
神经网络的底层学习到的特征,通常是基础特征。通常情况下,当我们的小数据集与预训练所用的大数据集相似时,就可以利用这些基础特征来继续训练网络,即调优。
当我们的数据集具有一些特殊性(医疗,中国书法),我们无法找到在相关领域预训练好的模型,此时就不得不从头开始训练网络了。
当我们的数据集非常小,并且找到的预训练模型的最后几层都是全连接层时,就会非常容易发生过拟合。经验来说,当数据有几千个,那么通过数据增益(翻转、裁剪等),调优后结果还是不错的。
3 调优技巧
- 将最后一层(softmax层)去掉,更换为符合当前任务的softmax层。如ImageNet上预训练的网络执行的是有1000个类别的分类任务,而当前数据集有num_classes个类别,那么就更改为Dense(num_classes,activation='softmax')
- 使用较小的学习率,一般为原lr的十分之一大小(将预训练网络的权重作为初始化权重,比随机效果好得多,所以尽量避免开始就大幅改变权重 )
- 冻结前几层网络的权重(底层学习到的特征都是基础的通用的特征,可以继续使用)
一般框架里面都会有一些预训练好的模型,方便直接调用——keras :application
4 调优方法(VGG16 )
Method 1:从头建立、修改、训练模型
from keras.layers import Input, Dense, Conv2D, MaxPooling2D,Flatten,Dropout,\
Activation,Reshape,merge,ZeroPadding2D,AveragePooling2D
from keras.models import Sequential
from keras.optimizers import SGD
from sklearn.metrics import log_loss
img_rows=224
img_cols=224
channel=3
num_classes=2
batchsize=10
epochs=5
#Method 1
def vgg16_model(img_rows,img_cols,channel=1,num_classes=None):
model=Sequential()
# No.1 two conv layers
model.add(ZeroPadding2D((1,1),input_shape=(img_rows,img_cols,channel)))
model.add(Conv2D(64,(3,3),activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(64,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
#No.2 two conv layers
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(128,(3,3),activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(128,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
#No.3 three conv layers
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(256,(3,3),activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(256,(3,3),activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(256,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
#No.4 three conv layers
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512,(3,3),activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512,(3,3),activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
#No.5 three conv layers
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512,(3,3),activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512,(3,3),activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Conv2D(512,(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
#No.6 Fully connected
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
#加载权值(500M)https://drive.google.com/file/d/0Bz7KyqmuGsilT0J5dmRCM0ROVHc/view?usp=sharing
model.load_weights('vgg16_weights.hs')
#去掉最后一层全连接层softmax,替换成符合自己任务的softmax
model.pop()
model.outputs=[model.layers[-1].output]
model.layers[-1].outbound_nodes=[]
model.add(Dense(num_classes,activation='softmax'))
#冻结前10层的权重
for layer in model.layers[:10]:
layer.trainable=False
#调整学习率,缩小十倍
sgd=SGD(lr=0.001,decay=0.000006,momentum=0.9,nesterov=True)
model.compile(optimizer=sgd,loss='categorical_crossentropy',\
metrics=['accuracy'])
return model
vgg16=vgg16_model(img_rows,img_cols,channel,num_classes)
print(vgg16.summary())
history=vgg16.fit(X_train,Y_train,batch_size=batchsize,epochs=epochs,\
validation_data=(X_valid,Y_valid),verbose=1)
#预测
pred_test=vgg16.predict(X_test,batch_size=batchsize,verbose=1)
score=log_loss(Y_test,pred_test)Method 2: 利用keras application 中现有的模型,读入、修改、训练
from keras.applications.vgg16 import VGG16
VGG16_model=VGG16()
print(type(VGG16_model))#默认Model 函数式类型
print(VGG16_model.summary())
#要改为Sequential序贯类型(线性结构,更为简单),逐层复制
model3=Sequential()
for layer in VGG16_model.layers:
model3.add(layer)
#将 Model类型的VGG16完全复制转化为 Sequential类型
print(model3.summary())
#删除最后一层
model3.layers.pop()
#替换最后一层为适合的softmax层
model3.add(Dense(num_classes,activation='softmax')) 5 调优VGG16 分类Cats. vs Dogs
5.1 准备数据
1 遍历读取目录中的文件方法:for file name in os.listdir(path)
2 openCV读取图片,类型是list,需要转换成array: np.array(data)
3 cv2.resize(image,size),方便转换图像尺寸
4 try ...except...结构,适合 error 处理
5 数据读取后要检查样本分布的均匀性:pd.Series(label).value_counts() #ndarray类型不能直接用value_counts()
#导入工具包
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.model_selection import train_test_split
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
#准备数据
path="./kaggle/train" #./是当前目录 ../是父级目录
img_rows=224
img_cols=224
channel=3
IMAGE_SIZE=(img_rows,img_cols)
channel=3
label=[]
data=[]
i=0
for filename in os.listdir(path):
if i%10==0: # 图像共25000太多,只取十分之一处理
image_data=cv2.imread(os.path.join(path,filename),1)
#0 读入灰色,1 彩色,-1 alpha通道即透明度
image_data=cv2.resize(image_data,IMAGE_SIZE) #固定尺寸读入
if filename.startswith("dog"):
label.append(1)
elif filename.startswith("cat"):
label.append(0)
try:
data.append(image_data/255) #归一化
except:
label=label[:len(label)-1]
i+=1
#处理的所有图像数据,都保证是array类型,非list
type(data) #data类型是list,需要转换为 np.ndarray
image_data.shape #(224,224,3)
data=np.array(data)
data.shape#(2500,224,224,3)
type(data) #numpy.ndarray
type(label) #list
label=np.array(label)
label.shape #(2500,)
type(label) #numpy.ndarray
sns.countplot(label) # array 没有value_counts(),要先转化成series
pd.Series(label).value_counts() #1250-1,1250-0 样本均衡
#划分训练集和验证集
train_data,valid_data,train_label,valid_label=train_test_split(\
data,label,test_size=0.2,random_state=42)5.2 网络结构
13 convs(2+2+3+3+3)+3(fc)=16

5.3 构建网络
1 VGG16模型默认是Model函数式,要转换为Sequensial序贯式,新建,遍历原模型逐层复制
2 删除层:model.layers.pop() ;冻结前n层权重:for layer in model.layers[:n]:layer.trainable=False
3 注意最后的分类层:num_classes (如二分类问题,如果不one-hot-encoder,num_classes=1,loss='binary_crossentropy';若one-hot编码,则num_classes为2,loss='categorical_crossentropy')
4 最后分类层的activation:与compile中的loss相关,如果 'categorical_crossentropy'----'softmax';'binary_crossentropy'--'sigmoid'
5 冻结了所有卷积层,每个epoch 20分钟左右;若冻结所有网络,只剩最后一层,训练时间虽快,但效果不好
from keras.layers import Input, Dense, Conv2D, MaxPooling2D,Flatten,Dropout,\
Activation,Reshape,merge,ZeroPadding2D,AveragePooling2D
from keras.models import Sequential
from keras.optimizers import SGD
from sklearn.metrics import log_loss
#可以避免模型重建和权值加载,利用keras applications中已有的vgg16模型,直接复制,修改
from keras.applications.vgg16 import VGG16
VGG16_model=VGG16()
print(type(VGG16_model))#默认Model 函数式类型
VGG16_model.summary()
#要改为Sequential序贯类型(线性结构,更为简单),逐层复制
model3=Sequential()
for layer in VGG16_model.layers:
model3.add(layer)
model3.summary()
#删除最后一层
model3.layers.pop()
model3.summary()
#冻结前面卷积层的权值
for layer in model3.layers[:-3]:
layer.trainable=False
#替换最后一层为适合的softmax层(这里binary_crossentropy,activation选择sigmoid)
#若label编码,则可以选择category——crossentropy,activation=softmax
#本例中二分类问题,没有编码,所以class number设为1(编码时设为2)
num_classes=1
batchsize=10
epochs=10
model3.add(Dense(num_classes,activation='sigmoid'))
print(model3.summary())
sgd=SGD(lr=0.001,decay=0.000006,momentum=0.9,nesterov=True)
model3.compile(optimizer=sgd,loss='binary_crossentropy',metrics=['accuracy'])
#查看学习曲线
fig,(ax1,ax2)=plt.subplots(2,1,figsize=(8,8))
ax1.plot(history.history['loss'],color='b',label="Train loss")
ax1.plot(history.history['val_loss'],color='r',label="Valid loss")
ax1.set_xticks(np.arange(0,epochs,1))
ax1.set_yticks(np.arange(0,1,0.1))
ax2.plot(history.history['acc'],color='b',label="Train acc")
ax2.plot(history.history['val_acc'],color='r',label="Valid acc")
ax2.set_xticks(np.arange(0,epochs,1))
lengend=plt.legend(loc='best',shadow=True)
plt.tight_layout()
plt.show()

5.3 测试评估
1 生成测试集的时候注意查看样本分布均匀性
2 将概率圆整为0-1,np.round( ) ,注意round()不能操作np.ndarray类型
3 评分方法:from sklearn import metrics (分类任务评分accuracy/presicion/fi/ROC、回归任务评分MSE/RMSE...),也可以自己创建评估函数
#保存模型,方便下次加载
#model3.save('./fine_tune/cat_dog_vgg.h5')
#生成测试集
del data #删除原加载的原数据,释放内存
del label
del train_data
del valid_data
test_data=[]
test_label=[]
i=1
for filename in os.listdir(path):
if i%3==0 and i%10!=0 and i%2==0: #读取大约3333张数据
image_data=cv2.imread(os.path.join(path,filename),1)
#0-读入灰色,1-彩色,-1alpha通道即透明度
image_data=cv2.resize(image_data,IMAGE_SIZE) #固定尺寸读入
if filename.startswith("dog"):
test_label.append(1)
elif filename.startswith("cat"):
test_label.append(0)
try:
test_data.append(image_data/255) #归一化
except:
test_label=test_label[:len(label)-1]
i+=1
#类型转换:
image_data.shape #(224,224,3)
test_data=np.array(test_data)
test_data.shape#(3333,224,224,3)
test_label=np.array(test_label) #将 list 转化为 array
test_label.shape #(3333,)
#查看样本分布均匀性
sns.countplot(test_label) # array 没有value_counts(),要先转化成series
pd.Series(test_label).value_counts()
#3333还是多,再次划分,减少测试量,最终取1000
split,test_data1,split_label,test_label1=train_test_split(test_data,test_label,test_size=0.3,random_state=42)
pd.Series(test_label1).value_counts()
#预测
test_pred=model3.predict(test_data1,batch_size=batchsize)
test_pred1=np.round(test_pred)#将预测的概率值转化为0-1值,此处操作类型为numpy.ndarray,需要用numpy.round进行圆整
#评价测试结果
from sklearn import metrics #准确率,适合二分类评价
score=metrics.accuracy_score(test_pred1,test_label1)
print(score)#0.918
print(metrics.accuracy_score(test_pred1,test_label1,normalize=False))#返回预测正确的个数
#scores=model3.evaluate(test_pred1,test_label1)# evaluate 需要test_data作为输入,直接给出评价5.4 Explore冻结层数
冻结权值范围的影响
冻结前面所有网络层只训练最后一个全连接层,时间会更快一些(4/5),但是准确度(valid_accu=0.854)低于冻结卷积层训练三个全连接层(valid_accu=0.912),在测试集上的准确率为0.814,下降约10%(原0.918)
原因:全连接层负责提取更加抽象的语义特征,预训练模型的抽象特征与猫狗图像集的不够吻合,仅靠最后一层全连接层的调整需要更多次的训练。若最后三层全连接层一起调整,则提取的抽象语义特征会更加接近本训练集,模型可以更快地达到好的性能。


6 调优 ResNet50

6.1 ResNet50 结构特点
- 共50层,五个stage: 1(conv1)+【3(conv2)+4(conv3)+6(conv4)+3(conv5)】x3(blocks)+1(fc)=50
- stage1:padding(3)->conv(64,(7,7),strides=(2,2))->Maxpooling(pool_size=(3,3),strides=(2,2))
- 2~5 stages,每个里面都有shortcut(将第一conv的输入与第三层conv的输出相加)。只有第一个block是conv_block:包含3个conv,kernel_size[ 1, 3, 1];其他blocks是identity_block,相当于重复,kernel_size=[ 1, 3, 1]
- conv_block和identity_block的区别:conv_block的conv1层的输入x与第三层conv的output尺度不一样,shortcut时,需要对x做1x1卷积升维,x_shortcut=x->conv(filters3)->batchnorm,维度刚好是filters3的数量,然后再与conv3的output相加add(x_short,x) ;而indentity_block接在conv_block后面,相当于重复conv_block,其输入x与conv3的output维度相同,shortcut时直接相加add(x_shortcut,x)
- 每个identity_block,不改变尺度:conv1和conv3都是 1x1,stride都是1,不改变尺度,3x3时stride=2,但是padding='same',也不改变尺度,所以shortcut时不需要考虑尺度,因为都没有变,只需要保证channel相同
- 但conv_block里面尺度是改变的,除了stage2的conv1的stride=1,其他stage的conv1 的strides都是2,尺寸都会改变,所以x_shortcut进行conv时,stride要和其一样,也是2
- 这样每个stage后,图片尺寸都减半,filters的数量都加倍。【64,64,256】【128,128,512】【256,256,1024】【512,512,2048】
- 每个block里面,前两个conv层都是:conv->batchnorm->activation(relu)。第三个conv层与前两个不一样,conv-batchnorm后先加shortcut,再activation:conv->batchnorm->add(x_shortcut)->activation(relu),
- BatchNormalization(axis=3)(x),axis=3,表示的是channel的index(batch,w,h,channel)channel_last
- 最后AveragePooling的pool_size和input_shape大小有关,如果是64x64,stage5输出是(2,2,2048),所以pool_size=2;如果 input_shape(224,224,),stage5输出是(7,7,2048),所以pool_size=7
6.2 调优问题
- Model模型与Sequential不同,从头到尾函数式的形式X=f()(X),最后model=Model(inputs=X_input,outputs=X),X_input=Input(input_shape)占位
- 先复原原模型,load_weights,再修改
- 替换softmax层时不能用pop(),因为非Sequential形式。需要根据层的输入变量和name,取出softmax前面的pooling层,然后添加Dense(classes,activation='sigmoid')。所以pooling层及其之后的变量名和前面的需要有所区别。原:X_fc=AveragePooling2D(pool_size=(7,7),name='avg_pool')(X) ->X_fc=Flatten()(X_fc) ->X_fc=Dense(1000,activation='sigmoid',name='fc'+str(classes),kernel_initializer=glorot_uniform(seed=0))(X_fc) -> model=Model(inputs=X_input,outputs=X_fc,name='ResNet50')——替换:X_new=AveragePooling2D(pool_size=(7,7),name='avg_pool')(X)
X_new=Flatten()(X_new)
X_new=Dense(classes,activation='sigmoid',name='new_fc')(X_new)
6.3 手动:建立/修改/训练 模型
#fine_tune ResNet50
"""
构建模型
"""
#model:
from keras.models import Model
from keras import layers
from keras.layers import Input,Dense,Conv2D,BatchNormalization,Activation,MaxPooling2D,\
AveragePooling2D,Dropout,Flatten,ZeroPadding2D
from keras.initializers import glorot_uniform #Glorot均匀分布初始化方法,又称Xavier均匀初始化
from keras.optimizers import SGD
from sklearn.metrics import log_loss
#定义每个stage的初始卷积层(short_cut连接时x与output维度不同,要对x做filters3的1X1卷积,
#而identity模块接在其后面,input和output维度相同,short_cut时直接相加不需要1x1卷积)
def conv_block(X,f,filters,stage,block,s=2):
"""
x:input
f:第二层卷积核的尺寸,3
filters:卷积核数量
stage:命名层的位置(共5个stage)
block:每个stage(2-5)又分为不同的block(3+4+6+3)
s:stride大小,此处都是2
"""
conv_name_base='res'+str(stage)+block+'_branch'
bn_name_base='bn'+str(stage)+block+'_branch'
f1,f2,f3=filters
X_shortcut=X
#第一个卷积层(stride为定义的(s,s)) 只有stage2的conv1 的s=1,其他stage的conv1都是s=2 ???
#Model 模式,输入X放最后括号外面
X=Conv2D(f1,(1,1),strides=(s,s),name=conv_name_base+'2a',kernel_initializer=glorot_uniform(seed=0))(X)
X=BatchNormalization(axis=3,name=bn_name_base+'2a')(X)#axis表示的是channel的index(batch,width,height,channel)
X=Activation('relu')(X)
#第二个卷积层:第二和第三个卷积的stride=(1,1) ,kernerl_size=3,若要保留原尺寸不变,需要padding=same
X=Conv2D(f2,(f,f),strides=(1,1),padding='same',name=conv_name_base+'2b',kernel_initializer=glorot_uniform(seed=0))(X)
X=BatchNormalization(axis=3,name=bn_name_base+'2b')(X)#axis表示的是channel的index(batch,width,height,channel)
X=Activation('relu')(X)
#第三个卷积层
X=Conv2D(f3,(1,1),strides=(1,1),name=conv_name_base+'2c',kernel_initializer=glorot_uniform(seed=0))(X)
X=BatchNormalization(axis=3,name=bn_name_base+'2c')(X)#axis表示的是channel的index(batch,width,height,channel)
#X=Activation('relu')(X) 每一个stage的第三个conv,batchNormalization后,需要加上short_cut,再activation
#shortcut,x与output 维度不同,先1x1卷积改变维度,维度是f3大小
X_shortcut=Conv2D(f3,(1,1),strides=(s,s),name=conv_name_base+'1')(X_shortcut) #strides=(s,s),与conv1的stride保持一致,尺寸才相同
X_shortcut=BatchNormalization(axis=3,name=bn_name_base+'1')(X_shortcut)
#连接shortcut与output
X=layers.add(inputs=[X,X_shortcut])
X=Activation('relu')(X)
return X
#定义接在conv_block后面的indentity_block,所有strides=(1,1)
def identity_block(X,f,filters,stage,block):
conv_name_base='res'+str(stage)+block+'_branch'
bn_name_base='bn'+str(stage)+block+'_branch'
f1,f2,f3=filters
X_shortcut=X
#第一个卷积层(stride为定义的(s,s)) 只有stage2的conv_block 的s=1,其他都是s=2 ???
#Model 模式,输入X放最后括号外面
X=Conv2D(f1,(1,1),strides=(1,1),name=conv_name_base+'2a',kernel_initializer=glorot_uniform(seed=0))(X)
X=BatchNormalization(axis=3,name=bn_name_base+'2a')(X)#axis表示的是channel的index(batch,width,height,channel)
X=Activation('relu')(X)
#第二个卷积层:第二和第三个卷积的stride=(1,1)
X=Conv2D(f2,(f,f),strides=(1,1),padding='same',name=conv_name_base+'2b',kernel_initializer=glorot_uniform(seed=0))(X)
X=BatchNormalization(axis=3,name=bn_name_base+'2b')(X)#axis表示的是channel的index(batch,width,height,channel)
X=Activation('relu')(X)
#第三个卷积层
X=Conv2D(f3,(1,1),strides=(1,1),name=conv_name_base+'2c',kernel_initializer=glorot_uniform(seed=0))(X)
X=BatchNormalization(axis=3,name=bn_name_base+'2c')(X)#axis表示的是channel的index(batch,width,height,channel)
#X=Activation('relu')(X) 每一个stage的第三个conv,batchNormalization后,需要加上short_cut,再activation
#连接shortcut与output,维度相同,直接相加
X=layers.add(inputs=[X,X_shortcut])
X=Activation('relu')(X)
return X
#构建网络
def ResNet50(input_shape=(224,224,3),classes=1000):
"""
ONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3
-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER
"""
X_input=Input(input_shape) #只是一个占位符,表示一个指定shape的数据
#stage1
X=ZeroPadding2D((3,3))(X_input) #零填充
X=Conv2D(64,(7,7),strides=(2,2),name='conv1',kernel_initializer=glorot_uniform(seed=0))(X)
#kernel_size=7,strides=2,pad=3,尺寸减半224-->112
X=BatchNormalization(axis=3,name='bn_conv1')(X)
X=Activation('relu')(X)
X=MaxPooling2D((3,3),strides=(2,2))(X) #重叠池化 112->55
#stage2,3blocks,同一个stage内filters数量一样
X=conv_block(X,f=3,filters=[64,64,256],stage=2,block='a',s=1)
X=identity_block(X,f=3,filters=[64,64,256],stage=2,block='b')
X=identity_block(X,f=3,filters=[64,64,256],stage=2,block='c')
#stage3,4blocks
X=conv_block(X,f=3,filters=[128,128,512],stage=3,block='a',s=2)
X=identity_block(X,f=3,filters=[128,128,512],stage=3,block='b')
X=identity_block(X,f=3,filters=[128,128,512],stage=3,block='c')
X=identity_block(X,f=3,filters=[128,128,512],stage=3,block='d')
#stage4,6blocks
X=conv_block(X,f=3,filters=[256,256,1024],stage=4,block='a',s=2)
X=identity_block(X,f=3,filters=[256,256,1024],stage=4,block='b')
X=identity_block(X,f=3,filters=[256,256,1024],stage=4,block='c')
X=identity_block(X,f=3,filters=[256,256,1024],stage=4,block='d')
X=identity_block(X,f=3,filters=[256,256,1024],stage=4,block='e')
X=identity_block(X,f=3,filters=[256,256,1024],stage=4,block='f')
#stage5,3blocks
X=conv_block(X,f=3,filters=[512,512,2048],stage=5,block='a',s=2)
X=identity_block(X,f=3,filters=[512,512,2048],stage=5,block='b')
X=identity_block(X,f=3,filters=[512,512,2048],stage=5,block='c')
#AveragePooling
X_fc=AveragePooling2D(pool_size=(7,7),name='avg_pool')(X) #此处需要重新命名,为了后面替换softmax
#pool_size与input_shape有关系,为了最后输出为(1,1,2048),当
#intput_shape=(64,64)时,pool_size=3
#input_shape=(224,224)时,pool_size=7
#output layer
X_fc=Flatten()(X_fc)
#X_fc=Dense(1000,activation='softmax',name='fc'+str(classes),kernel_initializer=glorot_uniform(seed=0))(X_fc)
X_fc=Dense(1000,activation='sigmoid',name='fc'+str(classes),kernel_initializer=glorot_uniform(seed=0))(X_fc)
#二分类,sigmoid--binary_crossentropy
model=Model(inputs=X_input,outputs=X_fc,name='ResNet50')
weights_path='resnet50_weights_tf_dim_ordering_tf_kernels.h5'
model.load_weights(weights_path)
#替换softmax层,Model模式不能直接pop
#提取出avg_pool层,上面的X_fc=Average..,一定是X_fc,不能用X=Average,需要换一个名字
#否则此处调用时Avera()(X)默认会取出上面的output:X
X_new=AveragePooling2D(pool_size=(7,7),name='avg_pool')(X)
X_new=Flatten()(X_new)
X_new=Dense(classes,activation='sigmoid',name='new_fc')(X_new) #二分类,sigmoid-binarycrossentropy
model=Model(inputs=X_input,outputs=X_new,name='ResNet50')
return model
model=ResNet50(input_shape=(224,224,3),classes=1)
sgd=SGD(lr=0.001,decay=0.000006,momentum=0.9,nesterov=True)
model.compile(optimizer=sgd,loss='binary_crossentropy',metrics=['accuracy'])
#model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy'])
print(model.summary())
"""
训练模型
"""
batchsize=10
epochs=10
history=model.fit(train_data,train_label,batch_size=batchsize,epochs=epochs,\
validation_data=(valid_data,valid_label),verbose=1) 
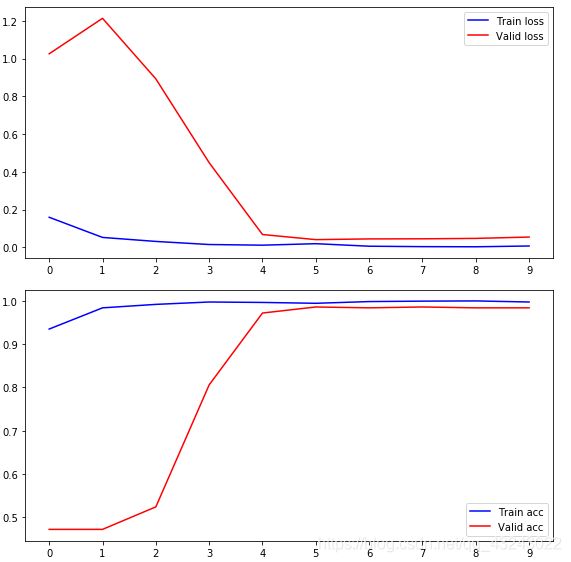
6.5 预测评估
#预测
test_pred=model.predict(test_data1,batch_size=batchsize)
test_pred1=np.round(test_pred)
from sklearn import metrics #准确率,适合二分类评价
score=metrics.accuracy_score(test_pred1,test_label1)
print(score)#0.979
score1=metrics.confusion_matrix(test_label1,test_pred1)
print(score1)
#[[521 5]
#[ 16 458]]6.6 自动:用keras.applicaitons.resnet50构建网络
from keras.applications.resnet50 import ResNet50
from keras.models import Sequential
from keras.layers import Flatten,Dense
from keras.optimizers import SGD
"""
ResNet50(include_top=True, weights='imagenet',
input_tensor=None, input_shape=None,
pooling=None,
classes=1000)
#input_tensor=Input(input_shape),占位符
#input_shape=(224,22,4,3)
#classes 只有在include_top=True才可选
#pooling(='avg'or'max')只有在include_top=False才可选
#include_top=False,weights会加载无softmax层的weights(no_top_weights)
#weights=None,随机初始化权值
"""
#print(ResNet50(include_top=False,input_shape=(224,224,3)).summary())
model=Sequential()
model.add(ResNet50(include_top=False,input_shape=(224,224,3)))
#当include_top=False,input_shape并没有默认为(224,224,3),要特别声明input_shape
model.add(Flatten()) #一定要加入Flatten,将三维变为二维
model.add(Dense(1,activation='sigmoid'))
print(model.summary())
type(model)
sgd=SGD(lr=0.001,decay=0.000006,momentum=0.9,nesterov=True)
model.compile(optimizer=sgd,loss='binary_crossentropy',metrics=['accuracy'])
batchsize=10
epochs=10
history=model.fit(train_data,train_label,batch_size=batchsize,epochs=epochs,\
validation_data=(valid_data,valid_label),verbose=1)
#评估
score=metrics.accuracy_score(test_pred1,test_label1)
print(score)#0.986
score1=metrics.confusion_matrix(test_label1,test_pred1)
print(score1)
#[[514 12]
#[ 2 472]]

总结
- 相同的数据集,测试集,相同的epoch,batchsize,optimizer,loss,ResNet50调优结果明显优于VGG16(accuracy提升接近6个百分点,0.918->0.979):ResNet证明解决了网络退化问题后,随着网络的深度增加,模型的性能会得到提升。
- 网络的全连接层十分重要。ResNet50仅仅一个全连接层,调优过程很快就有很好的效果。VGG16有三个全连接层,只有调整所有的三个fc才会更快的达到较好的效果。调优时如果网络最后接有多个fc,需要多种尝试,对几层fc调整效果会更好?具体任务具体分析。
- ResNet50调优时,前几个epochs,模型性能有一个显著的提升,随后慢慢趋于平稳:预训练模型学习到的基础特征与本训练集是非常相似的,所以无需要较大改动,权值只需要轻微变动,所以以较小的学习率训练几轮后,便可以达到较好的性能。