Elasticsearch入门使用篇
一,搜索的概念和软件的安装
1.什么是搜索
搜索:计算机根据用户输入的关键词进行匹配,从已有的数据库中摘录出相关的记录反馈给用户。
常见的全网搜索引擎,有百度、谷歌这样搜索网站。
除此,搜索技术在垂直领域也有广泛的使用,比如淘宝、京东搜索商品,万芳、知网搜索期刊,CSDN中搜索问题贴。也都是基于海量数据的搜索。
以电商网站为例,展示搜索功能的使用
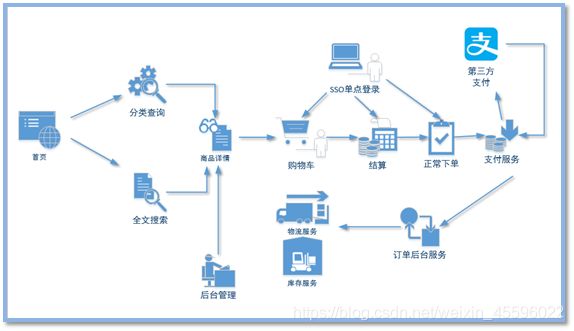
2.对比传统关系型数据库和搜索
1)传统关系型数据库

弊端:库存量单位
对于传统的关系型数据库对于关键词的查询,只能逐字逐行的匹配,性能非常差。
匹配方式不合理,比如搜索“小密手机”,如果用like进行匹配, 根本匹配不到。但是考虑使用者的用户体验的话,除了完全匹配的记录,还应该显示一部分近似匹配的记录,至少应该匹配到“手机”。
而且,模糊查询存在like关键字,会使索引失效。
2)专业全文索引引擎
全文搜索引擎目前主流的索引技术就是倒排索引的方式。
传统的保存数据的方式
记录→单词
而倒排索引的保存数据的方式
单词→记录
例如:搜索“华为手机”
数据库保存数据如下:
搜索时只能匹配一条id为2的数据
| 商品ID | 商品标题 | 商品价格 |
|---|---|---|
| 1 | 小米手机 | 1999 |
| 2 | 华为手机 | 4999 |
| 3 | 小米电视 | 2999 |
| 4 | … | … |
搜索引擎基于分词技术构建倒排索引!存储数据如下:
| 分词 | 文档ID | 文档 |
|---|---|---|
| 小米 | 1,3 | Document->[{1,小米手机,1999},{3,小米电视,2999}] |
| 华为 | 2 | Document->[{2,华为手机,4999}] |
| 手机 | 1,2 | Document->[{1,小米手机,1999},{2,华为手机,4999}] |
| 电视 | 3 | Document->[{3,小米电视,2999}] |
| … |
用户搜索时,会把搜索的关键词也进行分词,会把“华为手机”分词分成:华为和手机两个词。
这样的话,先用【华为】进行匹配,得到id为2的文档ID,再用【手机】进行匹配,得到id为1,2的文档ID。
那么全文索引通常,还会根据匹配程度进行打分,显然2号记录能匹配的次数更多。所以显示的时候以评分进行排序的话,2号记录会排到最前面。
3.ElasticSearch
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎。
它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
ES可以使用Java开发,并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
4.Lucene与ElasticSearch
咱们之前讲的处理分词,构建倒排索引等等,都是这个叫lucene做的。那么,能不能说这个Lucene就是搜索引擎呢?还不能。
Lucene只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的服务框架搭建起来进行应用。
目前市面上流行的搜索引擎软件,主流的就两款:Elasticsearch和Solr,这两款都是基于Lucene搭建的,可以独立部署启动的搜索引擎服务软件。由于内核相同,所以两者除了服务器安装、部署、管理、集群以外,对于数据的操作 修改、添加、保存、查询等等都十分类似。
5.ElasticSearch对比Solr
| ElasticSearch | Solr | |
|---|---|---|
| 管理方式 | 自身带有分布式协调管理功能 | 利用 Zookeeper 进行分布式管理 |
| 数据格式 | 仅支持json文件格式 | 支持更多格式的数据 |
| 功能与拓展 | 本身更注重于核心功能,高级功能多由第三方插件提供 | 官方提供的功能更多 |
| 表现 | 在处理实时搜索应用时效率明显低于 ElasticSearch | Solr 在传统的搜索应用中表现好于 ElasticSearch |
6.软件的介绍与安装
1)服务器
![]()
解压就可以使用。启动命令:elasticsearch.bat
2)客户端工具
![]()
解压就可以使用,只需要修改配置文件的少量配置。
配置文件位置:G:\es\kibana-6.8.1-windows-x86_64\config\kibana.yml
3)中文分词插件
![]()
只需要把它解压到G:\es\elasticsearch-6.8.1\plugins\ik就可以使用。注意压缩包不能放在该目录下。
二, ElasticSearch相关概念(术语)
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
用Mysql这样的数据库存储就会容易想到建立一张User表,有balabala的字段等,在ElasticSearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
| Elasticsearch | 索引(Index) | 类型(Type) | 文档(Documents) | 字段(Fields) |
|---|---|---|---|---|
| 关系数据库(MySQL) | 数据库(DataBase) | 表(Table) | 行(Rows) | 列(Columns) |
1.索引
一个索引就是一个拥有几分相似特征的文档的集合。
Elasticsearch索引的精髓:一切设计都是为了提高搜索的性能。
2.类型Type
在一个索引中,你可以定义一种或多种类型。
一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。
3.字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。
4.映射 mapping
mapping是处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引等等。
这些都是映射里面可以设置的,其它就是处理ES里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
5.文档 document
一个文档是一个可被索引的基础信息单元。
比如:你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
6.接近实时
ElasticSearch是一个接近实时(Near Real Time,简称NRT)的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)。
三,ElasticSearch的客户端操作
客户端工具:发送http请求(RESTful风格**)操作:**9200端口
使用**Postman**发送请求直接操作
使用**ElasticSearch-head-master**图形化界面插件操作
使用Elastic**官方**数据可视化的平台**Kibana**进行操作【推荐】
Java代码操作:9300端口
`Elasticsearch`提供的`Java API `客户端进行操作
`Spring Data ElasticSearch` 持久层框架进行操作
1.创建索引库
PUT /shopping
在kibana中,不用写地址和端口,/shopping是简化写法,真实请求地址是:
http://127.0.0.1:9200/shopping
响应结果
#! Deprecation: the default number of shards will change from [5] to [1] in 7.0.0; if you wish to continue using the default of [5] shards, you must manage this on the create index request or with an index template
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "shopping"
}
“acknowledged” : true, 代表操作成功
“shards_acknowledged” : true, 代表分片操作成功
“index” : “shopping” 表示创建的索引库名称
注意:创建索引库的分片数默认5片,在7.0.0之后的ElasticSearch版本中,默认1片;
重复添加:报错,已经存在

2.查看所有索引
GET /_cat/indices?v
表头的含义(查看帮助信息:GET /_cat/indices?help)
| health | 当前服务器健康状态: green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
|---|---|
| status | 索引打开、关闭状态 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副分片数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除,段合并时被清理) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
3.查看某个索引
GET /shopping
响应结果
{
"shopping" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1586587411462",
"number_of_shards" : "5",
"number_of_replicas" : "1",
"uuid" : "VCl1hHsJQDe2p2dn46o0NA",
"version" : {
"created" : "6080199"
},
"provided_name" : "shopping"
}
}
}
}
内容解释
{
"shopping【索引库名】" : {
"aliases【别名】" : { },
"mappings【映射】" : { },
"settings"【索引库设置】 : {
"index【索引】" : {
"creation_date【创建时间】" : "1586587411462",
"number_of_shards【索引库分片数】" : "5",
"number_of_replicas【索引库副本数】" : "1",
"uuid【唯一标识】" : "VCl1hHsJQDe2p2dn46o0NA",
"version【版本】" : {
"created" : "6080199"
},
"provided_name【索引库名称】" : "shopping"
}
}
}
}
4.删除索引
DELETE /shopping
响应结果
{
"acknowledged" : true
}
5.类型及映射操作
1)创建类型映射
有了索引库,等于有了数据库中的database。
接下来就需要建索引库(index)中的类型(type)了,类似于数据库(database)中的表(table)。创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,在创建索引库的类型时,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
给shopping这个索引库添加了一个名为product的类型,并且在类型中设置了4个字段:
title:商品标题
subtitle: 商品子标题
images:商品图片
price:商品价格
put /shopping/product/_mapping
{
"properties":{
"title":{
"type":"text",
"analyzer":"ik_max_word"
},
"subtitle":{
"type":"text",
"analyzer":"ik_max_word"
},
"images":{
"type":"keyword",
"index":false
},
"price":{
"type":"float",
"index":true
}
}
}
响应结果
{
"acknowledged" : true
}
类型名称:就是前面将的type的概念,类似于数据库中的表
字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
type:类型,Elasticsearch中支持的数据类型非常丰富,说几个关键的:
①String类型,又分两种:
text:可分词
keyword:不可分词,数据会作为完整字段进行匹配
②Numerical:数值类型,分两类
基本数据类型:long、interger、short、byte、double、float、half_float
浮点数的高精度类型:scaled_float
③Date:日期类型
④Array:数组类型
⑤Object:对象
index:是否索引,默认为true,也就是说你不进行任何配置,所有字段都会被索引。
true:字段会被索引,则可以用来进行搜索
false:字段不会被索引,不能用来搜索
store:是否将数据进行独立存储,默认为false
原始的文本会存储在**_source**里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source里面提取出来的。当然你也可以独立的存储某个字段,只要设置"store": true即可,获取独立存储的字段要比从_source中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。
analyzer:分词器,这里的ik_max_word即使用ik分词器
2)查看类型映射
GET /shopping/product/_mapping
响应结果
{
"shopping" : {
"mappings" : {
"product" : {
"properties" : {
"images" : {
"type" : "keyword",
"index" : false
},
"price" : {
"type" : "float"
},
"subtitle" : {
"type" : "text",
"analyzer" : "ik_max_word"
},
"title" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
}
}
}
3) 创建索引库同时进行映射配置(常用)
PUT /shopping2
{
"settings": {},
"mappings": {
"product":{
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"subtitle":{
"type": "text",
"analyzer": "ik_max_word"
},
"images":{
"type": "keyword",
"index": false
},
"price":{
"type": "float",
"index": true
}
}
}
}
}
响应结果
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "shopping2"
}
4)【文档操作】【基本CURD操作】
1.新建文档
POST /shopping/product
{
"title":"小米手机",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
响应结果
{
"_index" : "shopping",
"_type" : "product",
"_id" : "indGaHEB1ahbZ0SRrXt3",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
响应结果解释
{
"_index【索引库】" : "shopping",
"_type【类型】" : "product",
"_id【主键id】" : "indGaHEB1ahbZ0SRrXt3",
"_version【版本】" : 1,
"result【操作结果】" : "created",
"_shards【分片】" : {
"total【总数】" : 2,
"successful【成功】" : 1,
"failed【失败】" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
可以看到结果显示为:created,是创建成功了。 另外,需要注意的是,在响应结果中有个_id字段,这个就是这条文档数据的唯一标识,以后的增删改查都依赖这个id作为唯一标示。可以看到id的值为:indGaHEB1ahbZ0SRrXt3,这里我们新增时没有指定id,所以是ES帮我们随机生成的id。
多创建几条语句
POST /shopping/product/2
{
"title":"华为手机",
"images":"http://www.gulixueyuan.com/hw.jpg",
"price":4999.00
}
POST /shopping/product/3
{
"title":"小米电视",
"images":"http://www.gulixueyuan.com/xmds.jpg",
"price":5999.00
}
2.查看文档
GET /shopping/product/indGaHEB1ahbZ0SRrXt3
响应结果
{
"_index" : "shopping",
"_type" : "product",
"_id" : "indGaHEB1ahbZ0SRrXt3",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "小米手机",
"images" : "http://www.gulixueyuan.com/xm.jpg",
"price" : 3999.0
}
}
响应结果解释
{
"_index【索引库】" : "shopping",
"_type【类型】" : "product",
"_id【主键id】" : "indGaHEB1ahbZ0SRrXt3",
"_version【版本】" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found【查询结果】" : true,
"_source【源文档信息】" : {
"title" : "小米手机",
"images" : "http://www.gulixueyuan.com/xm.jpg",
"price" : 3999.0
}
}
_source:源文档信息,所有的数据都在里面。
_id:这条文档的唯一标示
found:查询结果,返回true代表查到,false代表没有
3.自定义ID新建文档
POST /shopping/product/1
{
"title":"小米手机",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
响应结果
{
"_index" : "shopping",
"_type" : "product",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
主键id变为指定的id
4.修改文档
请求url不变,请求体变化,会将原有数据内容覆盖。
POST /shopping/product/1
{
"title":"华为手机",
"images":"http://www.gulixueyuan.com/hw.jpg",
"price":4999.00
}
响应结果
{
"_index" : "shopping",
"_type" : "product",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}
可以看到result结果是:updated,使用GET /shopping/product/1查询,发现数据被更新。
5.根据id修改某一个字段
POST /shopping/product/1/_update
{
"doc": {
"price":3000.00
}
}
响应结果:
{
"_index" : "shopping",
"_type" : "product",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 8,
"_primary_term" : 1
}
可以看到result结果是:updated,使用GET /shopping/product/1查询,发现数据被更新。
6.删除一条文档
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
Elasticsearch会在段合并时(磁盘碎片整理)进行删除内容的清理。
DELETE /shopping/product/1
响应结果
{
"_index" : "shopping",
"_type" : "product",
"_id" : "1",
"_version" : 3,
"result" : "deleted",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}
可以看到result结果是:deleted,数据被删除。如果删除不存在的文档,result:not_found
例如:DELETE /shopping/product/11主键不存在
{
"_index" : "shopping",
"_type" : "product",
"_id" : "11",
"_version" : 1,
"result" : "not_found",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
7.根据条件删除文档
POST /shopping/product/_delete_by_query
{
"query":{
"match":{
"title":"手机"
}
}
}
响应结果
{
"took" : 33,
"timed_out" : false,
"total" : 2,
"deleted" : 2,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
响应结果解释
{
"took【耗时】" : 33,
"timed_out【是否超时】" : false,
"total【总数】" : 2,
"deleted【删除总数】" : 2,
"batches" : 1,
"version_conflicts" : 0,
"noops" : 0,
"retries" : {
"bulk" : 0,
"search" : 0
},
"throttled_millis" : 0,
"requests_per_second" : -1.0,
"throttled_until_millis" : 0,
"failures" : [ ]
}
5)请求体查询【基本查询】
1.请求体查询
Elasticsearch基于JSON提供完整的查询DSL来定义查询。
DSL(Domain Specific Language):领域特定语言
2.基础数据
POST /shopping/product/1
{
"title":"小米手机",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
POST /shopping/product/2
{
"title":"华为手机",
"images":"http://www.gulixueyuan.com/hw.jpg",
"price":4999.00
}
POST /shopping/product/3
{
"title":"小米电视",
"images":"http://www.gulixueyuan.com/xmds.jpg",
"price":5999.00
}
3.基本查询
1)查询所有(match_all)
GET /shopping/_search
{
"query": {
"match_all": {}
}
}
GET /{索引库}/_search
{
"query":{
"查询类型":{
"查询条件":"查询条件值"
}
}
}
“query”:这里的query代表一个查询对象,里面可以有不同的查询属性
“查询类型”:例如:match_all(代表查询所有), match,term , range 等等
“查询条件”:查询条件会根据类型的不同,写法也有差异
2)匹配查询(match)
GET /shopping/_search
{
"query": {
"match": {
"title": "小米手机"
}
}
}
在上面的案例中,不仅会查询到电视,而且与小米相关的都会查询到。
某些情况下,我们需要更精确查找,我们希望这个关系变成and,可以这样做:
GET /shopping/_search
{
"query": {
"match": {
"title": {
"query": "小米手机",
"operator": "and"
}
}
}
}
3) 多字段匹配查询(multi_match)
multi_match与match类似,不同的是它可以在多个字段中查询。
# 请求方法:GET
#fields属性:设置查询的多个字段名称
GET /shopping/_search
{
"query": {
"multi_match": {
"query": "小米",
"fields": ["title","subtitle"]
}
}
}
4) 关键词精确查询(term)
term查询,精确的关键词匹配查询,不对查询条件进行分词。
# 请求方法:GET
GET /shopping/_search
{
"query": {
"term": {
"title": {
"value": "小米"
}
}
}
}
5) 多关键词精确查询(terms)
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。
如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件,类似于mysql的in
# 请求方法:GET
GET /shopping/_search
{
"query": {
"terms": {
"price": [3999,5999]
}
}
}
6)【请求体查询】【结果过滤】
1.指定查询条件
默认情况下,ElasticSearch在搜索的结果中,会把文档中保存在_source的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source的过滤
# 请求方法:GET
GET /shopping/_search
{
"_source": ["title","price"],
"query": {
"terms": {
"price": [3999]
}
}
}
2. 过滤指定字段:includes和excludes
我们也可以通过:
includes:来指定想要显示的字段
excludes:来指定不想要显示的字段
# 请求方法:GET
GET /shopping/_search
{
"_source": {
"includes": ["title","price"]
},
"query": {
"terms": {
"price": [3999]
}
}
}
GET /shopping/_search
{
"_source": {
"excludes": ["images"]
},
"query": {
"terms": {
"price": [3999]
}
}
}
7)【请求体查询】【高级查询】
1. 布尔组合(bool)
bool把各种其它查询通过must(必须 )、must_not(必须不)、should(应该)的方式进行组合
# 请求方法:GET
GET /shopping/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "小米"
}
}
],
"must_not": [
{
"match": {
"title": "电视"
}
}
],
"should": [
{
"match": {
"title": "手机"
}
}
]
}
}
}
2. 范围查询(range)
range 查询找出那些落在指定区间内的数字或者时间。range查询允许以下字符:
| 操作符 | 说明 |
|---|---|
| gt == (greater than) | 大于> |
| gte == (greater than equal) | 大于等于>= |
| lt == (less than) | 小于< |
| lte == (less than equal) | 小于等于<= |
# 请求方法:GET
GET /shopping/_search
{
"query": {
"range": {
"price": {
"gte": 2500,
"lte": 4000
}
}
}
}
3.模糊查询
返回包含与搜索字词相似的字词的文档。
编辑距离是将一个术语转换为另一个术语所需的一个字符更改的次数。这些更改可以包括:
更改字符(box → fox)
删除字符(black → lack)
插入字符(sic → sick)
转置两个相邻字符(act → cat)
为了找到相似的术语,fuzzy查询会在指定的编辑距离内创建一组搜索词的所有可能的变体或扩展。然后查询返回每个扩展的完全匹配。
通过fuzziness修改编辑距离。一般使用默认值AUTO,根据术语的长度生成编辑距离。
0…2
必须完全匹配
3…5
允许一次编辑
>5
允许进行两次编辑
GET /shopping/_search
{
"query": {
"fuzzy": {
"title": {
"value": "ccple"
}
}
}
}
GET /shopping/_search
{
"query": {
"fuzzy": {
"title": {
"value": "ccple",
"fuzziness": 2
}
}
}
}
8)【请求体查询】【查询排序】
1.单字段排序
sort 可以让我们按照不同的字段进行排序,并且通过order指定排序的方式。desc降序,asc升序。
# 请求方法:GET
GET /shopping/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
2.多字段排序
假定我们想要结合使用 price和 _score(得分) 进行查询,并且匹配的结果首先按照价格排序,然后按照相关性得分排序:
# 请求方法:GET
GET /shopping/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "desc"
}
},
{
"_score":{
"order": "desc"
}
}
]
}
9)【请求体查询】【高亮查询】
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮。
高亮查询请求
ElasticSearch可以对查询内容中的关键字部分,进行标签和样式(高亮)的设置。
在使用match查询的同时,加上一个highlight属性:
pre_tags:前置标签
post_tags:后置标签
fields:需要高亮的字段
title:这里声明title字段需要高亮,后面可以为这个字段设置特有配置,也可以空
# 请求方法:GET
GET /shopping/_search
{
"query": {
"match": {
"title": "华为"
}
},
"highlight": {
"pre_tags": "",
"post_tags": "",
"fields": {
"title": {}
}
}
}
10)【请求体查询】【分页查询】
from:当前页的起始索引,默认从0开始。 from = (pageNum - 1) * size
size:每页显示多少条
# 请求方法:GET
GET /shopping/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "desc"
}
},
{
"_score":{
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
四,ElasticSearch集群
1.相关概念
1.单点故障问题
单台服务器,往往都有最大的负载能力,超过这个阈值,服务器性能就会大大降低甚至不可用。单点的elasticsearch也是一样,那单点的es服务器存在哪些可能出现的问题呢?
单台机器存储容量有限
单服务器容易出现单点故障,无法实现高可用
单服务的并发处理能力有限
所以,为了应对这些问题,我们需要对elasticsearch搭建集群
集群中节点数量没有限制,大于等于2个节点就可以看做是集群了。一般出于高性能及高可用方面来考虑集群中节点数量都是3个以上。
2.集群的相关概念
1)集群cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是elasticsearch。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
2)节点node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。
默认情况下,每个节点都会被安排加入到一个叫做elasticsearch的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做elasticsearch的集群中。
3) 分片和复制 shards&replicas
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,ElasticSearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
1)允许你水平分割/扩展你的内容容量。
2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
2.集群搭建

1.准备三台elasticsearch服务器
2.修改每台服务器配置
修改每台服务器对应的\config\elasticsearch.yml配置文件
1)node1节点:
#节点1的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.threshold_enabled: false
#节点名称,必须不一样
node.name: node-1
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9201
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9301
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
2)node2节点
#节点2的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.threshold_enabled: false
#节点名称,必须不一样
node.name: node-2
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9202
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9302
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
3)node3节点
#节点3的配置信息:
#集群名称,保证唯一
cluster.name: my-elasticsearch
#默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.threshold_enabled: false
#节点名称,必须不一样
node.name: node-3
#必须为本机的ip地址
network.host: 127.0.0.1
#服务端口号,在同一机器下必须不一样
http.port: 9203
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9303
#设置集群自动发现机器ip集合
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
3.启动各个节点服务器
先清理掉之前数据:删除elasticsearch-cluster\node*\data目录下的nodes目录
双击elasticsearch-cluster\node*\bin\elasticsearch.bat
启动三个节点
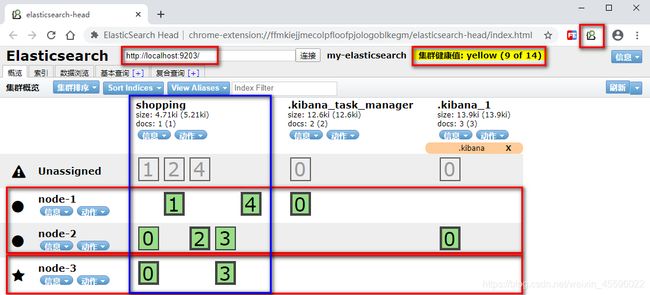
3.集群测试
安装ES插件ElasticSearch-head
将插件拖入到谷歌浏览器
更多工具,拓展程序
![]()
服务器运行状态:
Green
所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
yellow
所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把 yellow 想象成一个需要及时调查的警告。
red
至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
五,ElasticSearch编程操作
1创建工程,引入坐标
<properties>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>5.6.8version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>transportartifactId>
<version>5.6.8version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-to-slf4jartifactId>
<version>2.9.1version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>1.7.24version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-simpleartifactId>
<version>1.7.21version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.12version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
dependencies>
2.创建索引index
步骤:
1)创建一个Java工程
2)添加jar包,添加maven的坐标
3)编写测试方法实现创建索引库
1、创建一个Settings对象,相当于是一个配置信息。主要配置集群的名称。
2、创建一个客户端Client对象
3、使用client对象创建一个索引库
4、关闭client对象
@Test
public void test() throws Exception {
Settings setting = Settings.builder()
.put("cluster.name", "my-application")
.build();
TransportClient client = new PreBuiltTransportClient(setting);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
client.admin().indices().prepareCreate("index_db").get();
client.close();
}
3.创建映射mapping
步骤:
1)创建一个Settings对象
2)创建一个Client对象
3)创建一个mapping信息,应该是一个json数据,可以是字符串,也可以是XContextBuilder对象
4)使用client向es服务器发送mapping信息
5)关闭client对象
@Test
public void test2()throws Exception{
Settings setting = Settings.builder()
.put("cluster.name", "my-application")
.build();
TransportClient client = new PreBuiltTransportClient(setting);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
XContentBuilder builder= XContentFactory.jsonBuilder()
.startObject()
.startObject("t_user")
.startObject("properties")
.startObject("name")
.field("type","text")
.field("analyzer","ik_max_word")
.field("store",true)
.endObject()
.startObject("age")
.field("type","integer")
.field("index",true)
.field("store",true)
.endObject()
.startObject("email")
.field("type","text")
.field("analyzer","ik_max_word")
.field("store",true)
.endObject()
.endObject()
.endObject()
.endObject();
client.admin().indices().preparePutMapping("index_db").setType("t_user").setSource(builder).get();
builder.close();
client.close();
//GET /index_db/t_user/_mapping
}

4.创建文档
步骤:
1)创建一个Settings对象
2)创建一个Client对象
3)创建一个文档对象,创建一个json格式的字符串,或者使用XContentBuilder
4)使用Client对象吧文档添加到索引库中
5)关闭client
4.1通过XContentBuilder
@Test
public void test4() throws Exception{
// 创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my-application").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//创建文档信息
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.field("name", "尹会东")
.field("age", 23)
.field("email",
"[email protected]")
.endObject();
// 建立文档对象
/**
* 参数一blog1:表示索引对象
* 参数二article:类型
* 参数三1:建立id
*/
client.prepareIndex("index_db", "t_user", "1").setSource(builder).get();
//释放资源
client.close();
}

4.2使用Jackson转换实体
实体类
/**
* @author yinhuidong
* @createTime 2020-06-04-0:26
*/
public class User {
private Integer id;
private String name;
private Integer age;
private String email;
public User() {
}
pom.xml
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-coreartifactId>
<version>2.8.1version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-databindartifactId>
<version>2.8.1version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-annotationsartifactId>
<version>2.8.1version>
dependency>
测试
@Test
//创建文档(通过实体转json)
public void test5() throws Exception{
// 创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my-application").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// 描述json 数据
//{id:xxx, title:xxx, content:xxx}
User user = new User(2,"张三",20,"[email protected]");
ObjectMapper objectMapper = new ObjectMapper();
// 建立文档
client.prepareIndex("index_db", "t_user", user.getId().toString())
.setSource(objectMapper.writeValueAsString(user).getBytes(), XContentType.JSON).get();
//释放资源
client.close();
}
5.查询文档操作
1、根据id搜索
QueryBuilder queryBuilder = QueryBuilders.idsQuery().addIds("1", "2");
2、根据Term查询(关键词)
QueryBuilder queryBuilder = QueryBuilders.termQuery("title", "北方");
3、QueryString查询方式(带分析的查询)
QueryBuilder queryBuilder = QueryBuilders.queryStringQuery("速度与激情").defaultField("title");
查询步骤:
1)创建一个Client对象
2)创建一个查询对象,可以使用QueryBuilders工具类创建QueryBuilder对象。
3)使用client执行查询
4)得到查询的结果。
5)取查询结果的总记录数
6)取查询结果列表
7)关闭client
5.1关键词查询
@Test
public void testTermQuery() throws Exception{
//1、创建es客户端连接对象
Settings settings = Settings.builder().put("cluster.name", "my-application").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//2、设置搜索条件
SearchResponse searchResponse = client.prepareSearch("index_db")
.setTypes("t_user")
.setQuery(QueryBuilders.termQuery("name", "张三")).get();
//3、遍历搜索结果数据
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
//System.out.println("t_user:" + searchHit.getSource().get("t_user"));
}
//4、释放资源
client.close();
}
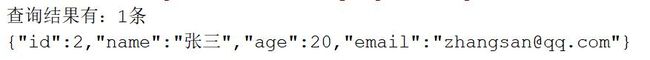
5.2字符串查询
@Test
public void testStringQuery() throws Exception{
//1、创建es客户端连接对象
Settings settings = Settings.builder().put("cluster.name", "my-application").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//2、设置搜索条件
SearchResponse searchResponse = client.prepareSearch("index_db")
.setTypes("t_user")
.setQuery(QueryBuilders.queryStringQuery("尹会东")).get();
//3、遍历搜索结果数据
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
}
//4、释放资源
client.close();
}
5.3 使用文档ID查询文档
@Test
public void testIdQuery() throws Exception {
Settings settings = Settings.builder().put("cluster.name", "my-application").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
//client对象为TransportClient对象
SearchResponse response = client.prepareSearch("index_db")
.setTypes("t_user")
//设置要查询的id
.setQuery(QueryBuilders.idsQuery().addIds("1"))
//执行查询
.get();
//取查询结果
SearchHits searchHits = response.getHits();
//取查询结果总记录数
System.out.println(searchHits.getTotalHits());
Iterator<SearchHit> hitIterator = searchHits.iterator();
while(hitIterator.hasNext()) {
SearchHit searchHit = hitIterator.next();
//打印整行数据
System.out.println(searchHit.getSourceAsString());
}
}

6.查询文档分页操作
6.1批量插入数据
@Test
//批量插入100条数据
public void test9() throws Exception{
// 创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my-application").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
ObjectMapper objectMapper = new ObjectMapper();
for (int i = 1; i <= 100; i++) {
// 描述json 数据
User article = new User(2+i,"李四",25,"[email protected]");
// 建立文档
client.prepareIndex("index_db", "t_user", article.getId().toString())
.setSource(objectMapper.writeValueAsString(article).getBytes(),XContentType.JSON).get();
}
//释放资源
client.close();
}

6.2 分页查询
在client对象执行查询之前,设置分页信息。
然后再执行查询
//执行查询
SearchResponse searchResponse = client.prepareSearch("index_hello")
.setTypes("article")
.setQuery(queryBuilder)
//设置分页信息
.setFrom(0)
//每页显示的行数
.setSize(5)
.get();
分页需要设置两个值,一个from、size
from:起始的行号,从0开始。
size:每页显示的记录数
@Test
//分页查询
public void test10() throws Exception {
// 创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my-application").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// 搜索数据
SearchRequestBuilder searchRequestBuilder = client.prepareSearch("index_db").setTypes("t_user")
.setQuery(QueryBuilders.matchAllQuery());//默认每页10条记录
// 查询第2页数据,每页20条
//setFrom():从第几条开始检索,默认是0。
//setSize():每页最多显示的记录数。
searchRequestBuilder.setFrom(0).setSize(5);
SearchResponse searchResponse = searchRequestBuilder.get();
SearchHits hits = searchResponse.getHits(); // 获取命中次数,查询结果有多少对象
System.out.println("查询结果有:" + hits.getTotalHits() + "条");
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next(); // 每个查询对象
System.out.println(searchHit.getSourceAsString()); // 获取字符串格式打印
System.out.println("id:" + searchHit.getSource().get("id"));
System.out.println("title:" + searchHit.getSource().get("title"));
System.out.println("content:" + searchHit.getSource().get("content"));
System.out.println("-----------------------------------------");
}
//释放资源
client.close();
}

7.查询结果高亮显示
(1)高亮的配置
1)设置高亮显示的字段
2)设置高亮显示的前缀
3)设置高亮显示的后缀
(2)在client对象执行查询之前,设置高亮显示的信息。
(3)遍历结果列表时可以从结果中取高亮结果。
@Test
//高亮查询
public void test11() throws Exception{
// 创建Client连接对象
Settings settings = Settings.builder().put("cluster.name", "my-application").build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// 搜索数据
SearchRequestBuilder searchRequestBuilder = client
.prepareSearch("index_db").setTypes("t_user")
.setQuery(QueryBuilders.termQuery("name", "张三"));
//设置高亮数据
HighlightBuilder hiBuilder=new HighlightBuilder();
hiBuilder.preTags("");
hiBuilder.postTags("");
hiBuilder.field("title");
searchRequestBuilder.highlighter(hiBuilder);
//获得查询结果数据
SearchResponse searchResponse = searchRequestBuilder.get();
//获取查询结果集
SearchHits searchHits = searchResponse.getHits();
System.out.println("共搜到:"+searchHits.getTotalHits()+"条结果!");
//遍历结果
for(SearchHit hit:searchHits){
System.out.println("String方式打印文档搜索内容:");
System.out.println(hit.getSourceAsString());
System.out.println("Map方式打印高亮内容");
System.out.println(hit.getHighlightFields());
System.out.println("遍历高亮集合,打印高亮片段:");
Text[] text = hit.getHighlightFields().get("t_user").getFragments();
for (Text str : text) {
System.out.println(str);
}
}
//释放资源
client.close();
}
六,Spring Data ElasticSearch
1.Spring Data ElasticSearch 简介
1) 什么是Spring Data
Spring Data是一个用于简化数据库访问,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快捷,并支持map-reduce框架和云计算数据服务。 Spring Data可以极大的简化JPA的写法,可以在几乎不用写实现的情况下,实现对数据的访问和操作。除了CRUD外,还包括如分页、排序等一些常用的功能。
Spring Data的官网:http://projects.spring.io/spring-data/
2)什么是SpringDataElasticSearch
Spring Data ElasticSearch 基于 spring data API 简化 elasticSearch操作,将原始操作elasticSearch的客户端API 进行封装 。Spring Data为Elasticsearch项目提供集成搜索引擎。Spring Data Elasticsearch POJO的关键功能区域为中心的模型与Elastichsearch交互文档和轻松地编写一个存储库数据访问层。
官方网站:http://projects.spring.io/spring-data-elasticsearch/
2.Spring Data ElasticSearch 入门案例
1)创建普通java工程,导入相关坐标
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>6.8.1version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>transportartifactId>
<version>6.8.1version>
dependency>
<dependency>
<groupId>org.springframework.datagroupId>
<artifactId>spring-data-elasticsearchartifactId>
<version>3.2.0.RELEASEversion>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.plugingroupId>
<artifactId>transport-netty4-clientartifactId>
exclusion>
exclusions>
dependency>
2)创建Spring配置文件,引入SpringDataElasticSearch名称空间
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/data/elasticsearch
http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch-1.0.xsd
">
beans>
3)编写实体类
/**
* @author yinhuidong
* @createTime 2020-06-04-0:26
*/
public class User {
private Integer id;
private String name;
private Integer age;
private String email;
....
}
4)编写Mapper层
/**
* @author yinhuidong
* @createTime 2020-06-04-10:32
*/
@Repository
public interface UserMapper extends ElasticsearchRepository<User,Integer> {
}
5)编写服务层
public interface UserService {
void save(User user);
}
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserMapper mapper;
@Override
public void save(User user) {
mapper.save(user);
}
}
6)编写Spring的配置文件
<elasticsearch:repositories base-package="com.example.mapper"/>
<context:component-scan base-package="com.example.service"/>
<elasticsearch:transport-client id="client" cluster-nodes="127.0.0.1:9300" cluster-name="my-application"/>
<bean id="elasticsearchTemplate" class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="client">constructor-arg>
bean>
7)配置实体类
基于spring data elasticsearch注解配置索引、映射和实体的关系
//文档对象,索引信息,文档类型
@Document(indexName = "index_db",type = "t_user")
public class User {
@Id//文档主键,唯一标识 (是否存储,是否分词,类型)
@Field(store = true,type = FieldType.Keyword,index = false)
private Integer id;
//analyzer = "ik_max_word" 指定分词器
@Field(store = true,type = FieldType.Text,analyzer = "ik_max_word")
private String name;
@Field(store = true,type = FieldType.Integer)
private Integer age;
@Field(store = true,type = FieldType.Text,analyzer = "ik_max_word")
private String email;
}
注解解释
@Document(indexName="index_db",type="t_user"):
indexName:索引的名称(必填项)
type:索引的类型
@Id:主键的唯一标识
@Field(index=true,analyzer="ik_max_word",store=true,searchAnalyzer="ik_smart",type = FieldType.text)
index:是否设置分词
analyzer:存储时使用的分词器
searchAnalyze:搜索时使用的分词器
store:是否存储
type: 数据类型
8)测试
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class TestSpring {
@Autowired
private ElasticsearchTemplate template;
@Autowired
private UserService service;
@Test
public void test(){
//创建索引
template.createIndex(User.class);
//创建映射
template.putMapping(User.class);
}
@Test
public void test2(){
service.save(new User(1,"尹会东",23,"[email protected]"));
}
}

3.SpringDataElasticSearch基本操作
服务层代码
public interface UserService {
//保存
void save(User user);
//删除
void remove(User user);
//查询全部
Iterable<User>findAll();
//分页查询
Page<User>findByPage(Pageable pageable);
}
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserMapper mapper;
@Override
public void save(User user) {
mapper.save(user);
}
@Override
public void remove(User user) {
mapper.delete(user);
}
@Override
public Iterable<User> findAll() {
return mapper.findAll();
}
@Override
public Page<User> findByPage(Pageable pageable) {
return mapper.findAll(pageable);
}
}
测试类
/**
* @author yinhuidong
* @createTime 2020-06-04-10:54
*/
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:applicationContext.xml")
public class TestSpring {
@Autowired
private ElasticsearchTemplate template;
@Autowired
private UserService service;
@Test
public void test(){
//创建索引
template.createIndex(User.class);
//创建映射
template.putMapping(User.class);
}
@Test
public void test2(){
service.save(new User(5,"赵六",23,"[email protected]"));
}
@Test
public void test3(){
service.remove(new User(1,"尹会东",23,"[email protected]"));
}
@Test
public void test4(){
Iterable<User> iterable = service.findAll();
iterable.forEach(System.out::println);
}
@Test
public void test5(){
//Pageable pageable = PageRequest.of(1,10);
service.findByPage(new Pageable() {
@Override
public int getPageNumber() {
return 0;
}
@Override
public int getPageSize() {
return 2;
}
@Override
public long getOffset() {
return 0;
}
@Override
public Sort getSort() {
return null;
}
@Override
public Pageable next() {
return null;
}
@Override
public Pageable previousOrFirst() {
return null;
}
@Override
public Pageable first() {
return null;
}
@Override
public boolean hasPrevious() {
return false;
}
}).forEach(System.out::println);
}
}
4.常用查询命名规则与测试
| 关键字 | 命名规则 | 解释 | 示例 |
|---|---|---|---|
| and | findByField1AndField2 | 根据Field1和Field2获得数据 | findByTitleAndContent |
| or | findByField1OrField2 | 根据Field1或Field2获得数据 | findByTitleOrContent |
| is | findByField | 根据Field获得数据 | findByTitle |
| not | findByFieldNot | 根据Field获得补集数据 | findByTitleNot |
| between | findByFieldBetween | 获得指定范围的数据 | findByPriceBetween |
| lessThanEqual | findByFieldLessThan | 获得小于等于指定值的数据 | findByPriceLessThan |
mapper
@Repository
public interface UserMapper extends ElasticsearchRepository<User,Integer> {
//根据名字查询
List<User> findByName(String name);
//根据名字查询并分页
Page<User> findByName(String name, Pageable pageable);
}
service
//根据名字查询
List<User> findByName(String name);
//根据名字查询并分页
Page<User>findByName(String name,Pageable pageable);
serviceimpl
@Override
public List<User> findByName(String name) {
return mapper.findByName(name);
}
@Override
public Page<User> findByName(String name, Pageable pageable) {
return mapper.findByName(name,pageable);
}
Test
@Test
public void test6(){
service.findByName("尹会东").forEach(System.out::println);
}
@Test
public void test7(){
PageRequest request = PageRequest.of(0, 3);
service.findByName("三",request).forEach(System.out::println);
}
public Sort getSort() {
return null;
}
@Override
public Pageable next() {
return null;
}
@Override
public Pageable previousOrFirst() {
return null;
}
@Override
public Pageable first() {
return null;
}
@Override
public boolean hasPrevious() {
return false;
}
}).forEach(System.out::println);
}
}
### 4.常用查询命名规则与测试
| 关键字 | 命名规则 | 解释 | 示例 |
| ------------- | --------------------- | -------------------------- | --------------------- |
| and | findByField1AndField2 | 根据Field1和Field2获得数据 | findByTitleAndContent |
| or | findByField1OrField2 | 根据Field1或Field2获得数据 | findByTitleOrContent |
| is | findByField | 根据Field获得数据 | findByTitle |
| not | findByFieldNot | 根据Field获得补集数据 | findByTitleNot |
| between | findByFieldBetween | 获得指定范围的数据 | findByPriceBetween |
| lessThanEqual | findByFieldLessThan | 获得小于等于指定值的数据 | findByPriceLessThan |
#### mapper
```java
@Repository
public interface UserMapper extends ElasticsearchRepository {
//根据名字查询
List findByName(String name);
//根据名字查询并分页
Page findByName(String name, Pageable pageable);
}
service
//根据名字查询
List<User> findByName(String name);
//根据名字查询并分页
Page<User>findByName(String name,Pageable pageable);
serviceimpl
@Override
public List<User> findByName(String name) {
return mapper.findByName(name);
}
@Override
public Page<User> findByName(String name, Pageable pageable) {
return mapper.findByName(name,pageable);
}
Test
@Test
public void test6(){
service.findByName("尹会东").forEach(System.out::println);
}
@Test
public void test7(){
PageRequest request = PageRequest.of(0, 3);
service.findByName("三",request).forEach(System.out::println);
}