Elasticsearch入门介绍及Linux安装
前言
Elasticsearch是一款分布式高性能的全文搜索引擎,为什么会需要这个呢,像我们平常使用的最多的存储工具就是Mysql,在业界也是非常有名的,我们大部分结构化数据都是用它来存储的,sql语言的操作也是非常方便,而且它也提供了索引机制,但是Mysql在一种特殊情况下搜索数据会非常慢,因为mysql使用的是正排索引,因此才有了Elasticsearch技术
正排索引和倒排索引
比如现在数据库上有如下的数据
id |
name |
content |
1 |
周星驰 |
周星驰是个伟大的喜剧演员 |
2 |
周星星 |
周星星是个普通演员 |
3 |
刘德华 |
刘德华也是个很不错的演员 |
正排索引
假设我们使用mysql要查询content里面包含演员的数据出来,那我我们会写类似的语句查询
select * from user where content like '%演员%'
这个机制底层的原理是循环所有的数据,比如拿id为1的content属性然后跟%演员%进行匹配,如果符合那么就拿出来,很明显这种机制缺陷是很大的,假设你的数据有100万条呢?可想而知会有多慢,所以才会渐渐有了Elasticsearch这种技术(当然最先出来的是Lucene,Solr等,但是这里不讨论,有兴趣自己进行百度,顺便说一下,百度搜索其实就是Elasticsearch的使用场景)
倒排索引
那么Elasticsearch是如何解决正牌索引的呢,首先这里还有个概念,叫分词,这也是倒排索引的核心,理解了这个你就很容易理解倒排索引了
比如id为1的content为:周星驰是个伟大的喜剧演员,所谓的分词就是把这个句子进行拆分,但是如何拆分取决于分词器,你可以把分词器想象为一个工具,把一个句子根据特定的算法切割为几个词语,这里我假设分词器对句子分为了以下的内容
周星驰、是个伟大的、喜剧、演员
Elasticsearch会维护一种倒排索引表,解设id为1的倒排索引变会这么记录
这里的id是倒排索引表的,word是拆的词,index是上面表格的id
id |
word |
index |
1 |
周星驰 |
1 |
2 |
是个伟大的 |
1 |
3 |
喜剧 |
1 |
4 |
演员 |
1 |
接着我们再对id为2,3的数据进行分词(注意下面都是解设),最终的数据结果如下
id |
word |
index |
1 |
周星驰 |
1 |
2 |
是个伟大的 |
1 |
3 |
喜剧 |
1 |
4 |
演员 |
1 |
5 |
周星星 |
2 |
6 |
是个普通 |
2 |
7 |
演员 |
2 |
8 |
刘德华 |
3 |
9 |
也是个很不错的 |
3 |
10 |
演员 |
3 |
很明显,上面的数据是有重复的,所以会被合并为以下的结构,如下
id |
word |
index |
1 |
周星驰 |
1 |
2 |
是个伟大的 |
1 |
3 |
喜剧 |
1 |
4 |
演员 |
1、2、3 |
5 |
周星星 |
2 |
6 |
是个普通 |
2 |
7 |
刘德华 |
3 |
8 |
也是个很不错的 |
3 |
这样一来就形成了倒排索引表,在查包含演员的数据时,会先在这张表进行查询到1、2、3,然后再根据索引去真正的数据进行查询,效率可是会快很多的
可能有人会疑问,如果倒排索引表也很大,那不是有正排索引的问题吗?其实是没有的,因为词语的个数是有限的,而用词语组成的文章是无限的,就比如演员这个索引可以用来索引很多个句子,而如果用演员来造句成为一个内容,那可以造无限的句子
Elasticsearch出现历史
Shay Banon为Elasticsearch之父,说起来也挺有趣的,Shay Banon当时失业了,而她的妻子是在餐厅工作的,作为好男人的Shay Banon想为妻子开发一个搜索菜谱的工具,刚开始的时候使用当时已经相对成熟的Luence框架进行开发,然而在开发过程中他发现这个框架并不好用,于是乎基于Luence这个框架自己开发了一个Compass框架,后来Compass出来以后大受赞赏,此时Shay Banon也找到了新的工作,他又基于Compass开发出了Elasticsearch
了解这个不一定有用,但是你不觉得很有趣吗,我印象中redis的出现也有类型的情况
Elasticsearch安装
原生Linux安装
首先,你需要下载安装包,这里推荐一个网站进行下载:https://www.elastic.co/cn/downloads/这里的产品比较全,还有后面要安装的Kibana组件,唯一缺点是网站比较卡.....
Elasticsearch 下载:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
我这里下载的是7.1.3版本的:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-17-3
下载完就可以进行安装了,一些核心的步骤这里会说下
首先把下载的Linux包上传到服务器上,我这里是放到了 /opt下面
然后进行解压,命令为
tar -zxvf elasticsearch-7.17.3-linux-x86_64.tar.gz
Elasticsearch是需要依赖jdk的,我们可以直接使用他提供的就行了,位置在你解压后的内容中
这里我们只需要配置一个全局变量,Elasticsearch就可以使用,使用如下步骤配置
vim /etc/profile 打开profile文件,直接拉到最后输入内容,地址自己修改
export ES_JAVA_HOME=/opt/elasticsearch-7.17.3/jdk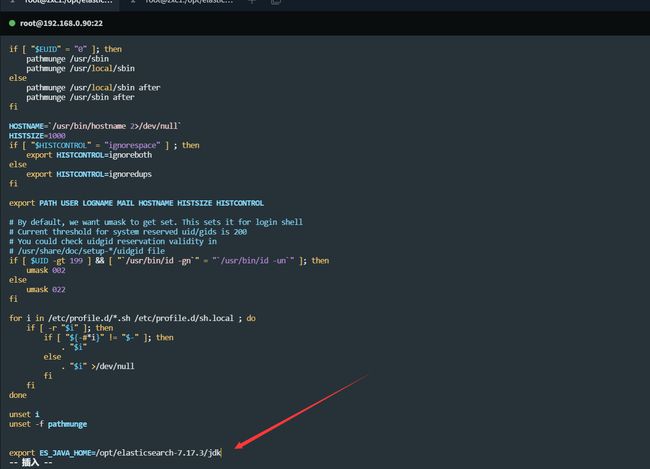
保存后执行如下操作
source /etc/profile #让配置文件生效
echo $ES_JAVA_HOME #看是否配置成功,如果出现下图就是成功了

打开/opt/elasticsearch-7.17.3/config/elasticsearch.yml文件,配置意思如下,挑你需要的进行修改
network.host: 0.0.0.0 #所有机器都可以访问
http.port: 9200 #对外暴漏的http端口,默认不改就是9200
path.data: /path/to/data #数据位置
path.logs: /path/to/logs #日志位置
discovery.seed_hosts: ["192.168.0.90"] #写你的ip就行了 cluster.initial_master_nodes: ["node-1"]
node.name: node-1 #跟上面的一致
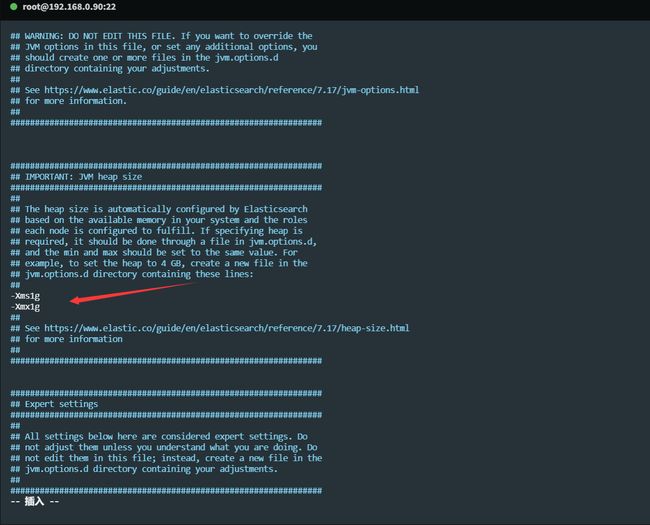
接着第一个问题就是jvm内存问题,默认情况下Elasticsearch会使用4g内存启动,但是我们有时可能只是自己要试一下,内存太少,这个时候可以修改文件,/opt/elasticsearch-7.17.3/config/jvm.options 加入以下配置:我这里改为了1g
-Xms1g
-Xmx1g
到这里配置就完了,就可以运行了,启动命令为:/opt/elasticsearch-7.17.3/bin/elasticsearch ,但是如果你是root用户是启动不了的,这是es做的一个控制,解设你在root用户直接去启动,会报如下的错

所以我们一般需要创建一个单独的用户来管理Elasticsearch,如下是创建命令
adduser es #创建用户名es,名字你随意
passwd es #为es用户设置密码
chown -R es:es . #到你的es目录下设置当前目录的权限给es用户
创建好后切换到es用户进行启动 如果你是在root账号下可以使用 su es 切换到es用进行启动,但是你仍然可能会启动以下几个问题
启动可能会有的问题
问题一
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错
#切换到root用户
vim /etc/security/limits.conf
末尾添加如下配置: 前面的*表示启动es的用户,比如我这里应该是es
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096注意,修改完以后需要重启,如果重启还是不行建议参考一下这篇文章
https://blog.csdn.net/qq_41378597/article/details/103706237
我也是边写博客边安装的,,,,有问题就顺便总结在这里了,,,,
问题二
max number of threads [1024] for user [es] is too low, increase to at least [4096]
无法创建本地线程问题,用户最大可创建线程数太小
vim /etc/security/limits.d/20-nproc.conf
改为如下配置:
* soft nproc 4096问题三
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
最大虚拟内存太小,调大系统的虚拟内存
vim /etc/sysctl.conf
追加以下内容:
vm.max_map_count=262144
保存退出之后执行如下命令:
sysctl -p问题四
the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
缺少默认配置,至少需要配置discovery.seed_hosts/discovery.seed_providers/cluster.initial_master_nodes中的一个参数.
discovery.seed_hosts: 集群主机列表
discovery.seed_providers: 基于配置文件配置集群主机列表
cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填
vim config/elasticsearch.yml
#添加配置
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node-1"]
#或者 单节点(集群单节点)
discovery.type: single-node以上可能是你会遇到的问题,处理完以后在执行启动命令看到如下的数据就是成功了
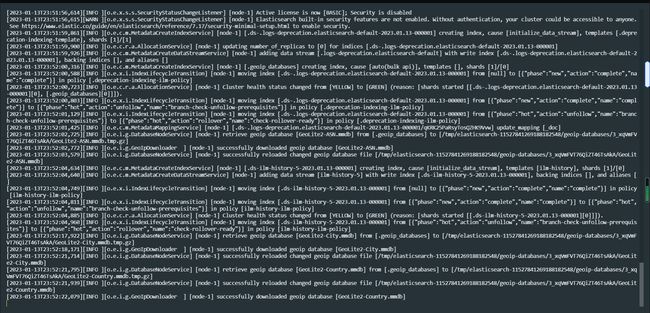
然后访问你ip的地址,看到如下就是成功了: http://192.168.0.90:9200/

注意,如果不成功的话请看下防火墙关闭或者端口通不通
centos7关闭防火墙命令:systemctl stop firewalld.service
到此为止我们就安装玩了
使用Docker安装
如果不懂Docker可以参考我之前的文章
https://blog.csdn.net/zxc_user/article/details/128517677?spm=1001.2014.3001.5501
至于Docker的安装就非常简单了,就几条命令,如下
docker network create elastic
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.13.4
docker run --name es01-test --net elastic -p 127.0.0.1:9200:9200 -p 127.0.0.1:9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.13.4
详情请参考官网文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.13/getting-started.html
以上就是Elasticsearch的安装的两种方式了
Elasticsearch操作
那么我们如何操作Elasticsearch呢?Elasticsearch提供了rest风格的yapi,我们可以同过postman工具来进行操作,如下是添加一个索引

如上就操作成功了,但是很明显这种操作很麻烦,接口一多我们需要记录好多,所以Elasticsearch又提供了一个界面工具,叫Kibana
Kibana
用于操作Elasticsearch的界面工具,使用非常方便
安装
首先要进行安装,到官网:https://www.elastic.co/cn/downloads/past-releases#kibana
下载完以后上传到linux中,如下,版本最好跟Elasticsearch一致

首先进行解压
tar -zxvf kibana-7.17.3-linux-x86_64.tar.gz
修改文件,如下
server.port: 5601 #对外暴露的端口
server.host: "192.168.0.90" #服务器ip,Kibana的访问地址
elasticsearch.hosts: ["http://localhost:9200"] #elasticsearch的访问地址
i18n.locale: "zh-CN" #Kibana汉化运行Kibana
注意:kibana也需要非root用户启动
这里为了简单,就直接用es账号启动了,你也可以创建个专门的账号进行启动,记得要先把目录改为对应用户可以使用的
使用命令 ./bin/kibana 启动,看到如下界面就是成功了

使用
http://192.168.0.90:5601/ 访问你本地的进入下面的界面
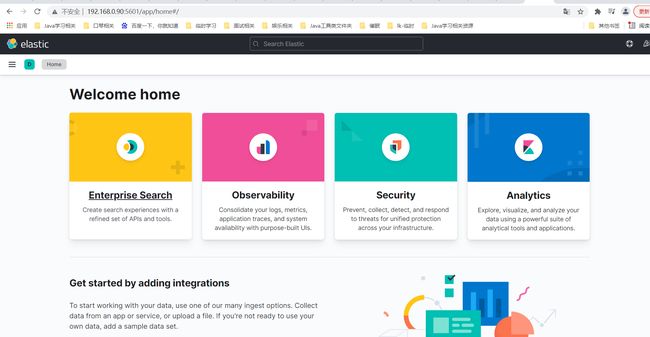
再选择DevTools工具

创建索引zxc1.如下
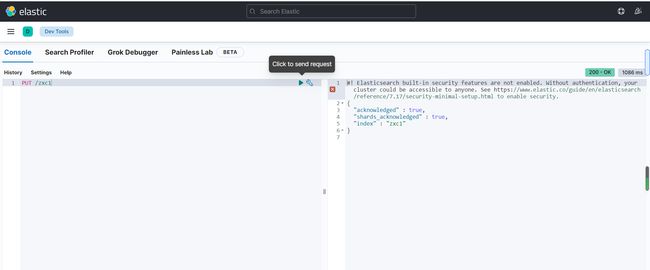
程序后台启动
上面的Elasticsearch和Kibana都是在前台启动的,一旦服务器关闭就会掉线了,可以使用命令进行后台启动
Elasticsearch后台启动
./elasticsearch-7.17.3/bin/elasticsearch -d
Kibana后台启动,注:Kibana启动可能比较久,请耐心等待,可以通过tail -f nohup.out查看日志
nohup ./bin/kibana &
总结
我是边安装,边写博客,边解决问题,从9点半弄到现在,用了好几个小时,不过我强烈建议你自己操作下,虽然并不难,但是你操作过就会有个印象,就像我之前玩docker一样,大家加油