基于凸集上投影(POCS)的聚类算法
POCS:Projections onto Convex Sets。在数学中,凸集是指其中任意两点间的线段均在该集合内的集合。而投影则是将某个点映射到另一个空间中的某个子空间上的操作。给定一个凸集合和一个点,可以通过找到该点在该凸集合上的投影来进行操作。该投影是离该点最近的凸集内的点,可以通过最小化该点和凸集内任何其他点之间的距离来计算。既然是投影,那么我们就可以将特征映射到另一个空间中的凸集合上,这样就可以进行聚类或降维等操作。
本文综述了一种基于凸集投影法的聚类算法,即基于POCS的聚类算法。原始论文发布在IWIS2022上。
凸集
凸集定义为一个数据点集合,其中连接集合中任意两点x1和x2的线段完全包含在这个集合中。根据凸集的定义,认为空集∅、单集、线段、超平面、欧氏球都被认为是凸集。数据点也被认为是凸集,因为它是单例集(只有一个元素的集合)。这为 POCS 的概念应用于聚类数据点开辟了一条新路径。
凸集投影(POCS)
POCS方法大致可分为交替式和并行式两种。
1、交替式poc
从数据空间中的任意一点开始,从该点到两个(或多个)相交凸集的交替投影将收敛到集合交点内的一点,例如下图:
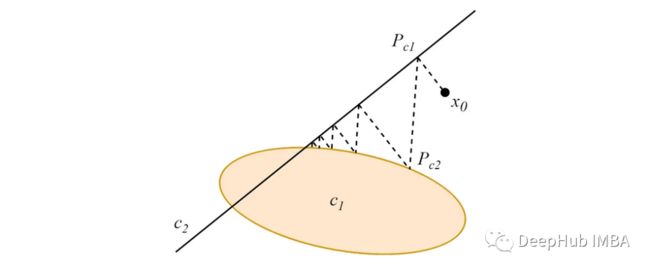
当凸集不相交时,交替投影将收敛到依赖于投影阶数的greedy limit cycles。
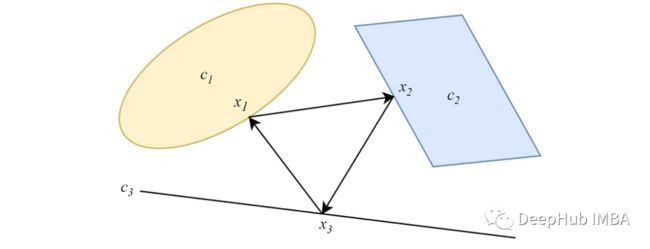
2、并行式 POCS
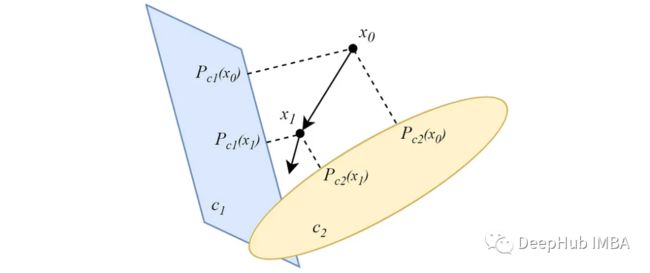
与交替形式不同,并行的POCS 是从数据点到所有凸集同时进行投影,并且每个投影都有一个重要性权重。对于两个非空相交凸集,类似于交替式版本,平行投影会收敛到集相交处的一个点。
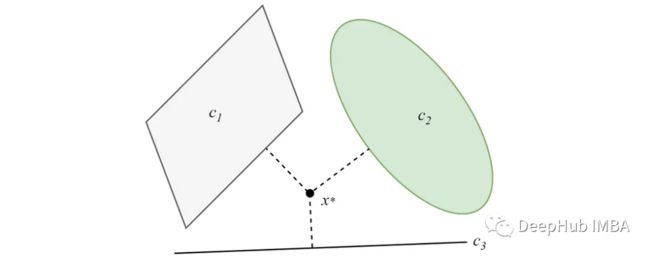
在凸集不相交的情况下,投影将收敛到一个最小解。基于pocs的聚类算法的主要思想来源于这一特性。
有关POCS的更多细节,可以查看原论文
基于pocs的聚类算法
利用并行POCS方法的收敛性,论文作者提出了一种非常简单但在一定程度上有效的聚类算法。该算法的工作原理与经典的K-Means算法类似,但在处理每个数据点的方式上存在差异:K-Means算法对每个数据点的重要性加权相同,但是基于pocs的聚类算法对每个数据点的重要性加权不同,这与数据点到聚类原型的距离成正比。
算法的伪代码如下所示:

实验结果
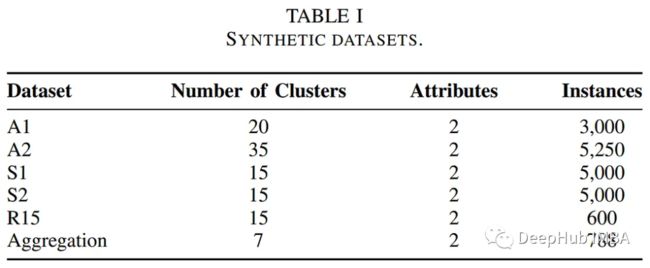
作者在一些公共基准数据集上测试了基于pocs的聚类算法的性能。下表总结了这些数据集的描述。
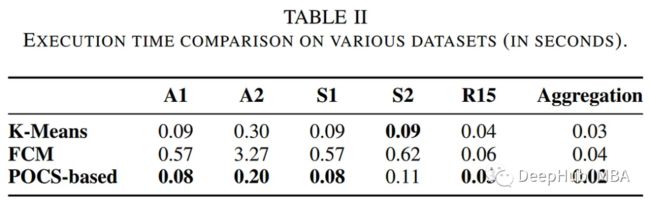
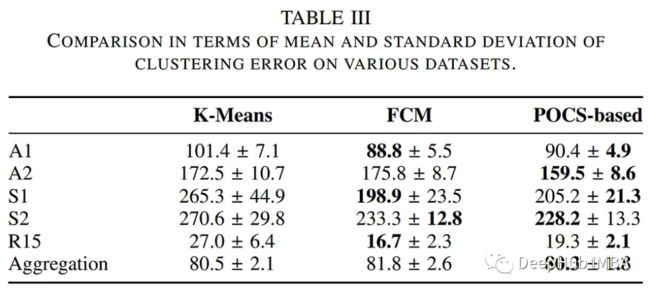
作者比较了基于pocs的聚类算法与其他传统聚类方法的性能,包括k均值和模糊c均值算法。下表总结了执行时间和聚类错误方面的评估。
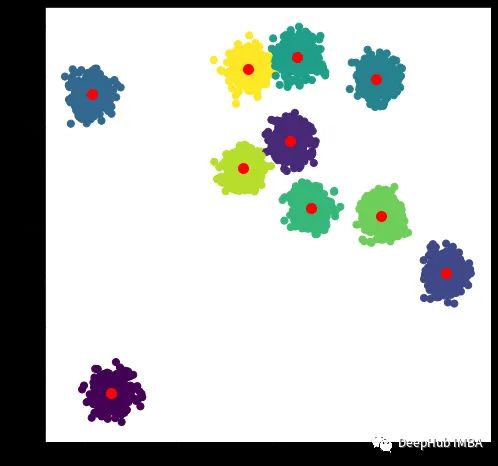
聚类结果如下图所示:
示例代码
我们在一个非常简单的数据集上使用这个算法。作者已经发布了直接使用的包,对于应用我们可以直接使用:
pip install pocs-based-clustering
创建一个以10个簇为中心的5000个数据点的简单数据集:
# Import packages
importtime
importmatplotlib.pyplotasplt
fromsklearn.datasetsimportmake_blobs
frompocs_based_clustering.toolsimportclustering
# Generate a simple dataset
num_clusters=10
X, y=make_blobs(n_samples=5000, centers=num_clusters, \
cluster_std=0.5, random_state=0)
plt.figure(figsize=(8,8))
plt.scatter(X[:, 0], X[:, 1], s=50)
plt.show()

执行聚类并显示结果:
# POSC-based Clustering Algorithm
centroids, labels=clustering(X, num_clusters, 100)
# Display results
plt.figure(figsize=(8,8))
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
plt.scatter(centroids[:, 0], centroids[:, 1], s=100, c='red')
plt.show()
总结
我们简要回顾了一种简单而有效的基于投影到凸集(POCS)方法的聚类技术,称为基于POCS的聚类算法。该算法利用POCS的收敛特性应用于聚类任务,并在一定程度上实现了可行的改进。在一些基准数据集上验证了该算法的有效性。
https://avoid.overfit.cn/post/bd811302f89c47fa8777c9f5bac8c59e
作者:LA Tran