AI 作画第二弹
上次一次尝试 AI 作画,还是在 6 月份,详情可见 《AI 作画初体验》。那个时候使用的是 Google 开发的 DD (Disco Diffusion) 系统,使用的版本为 V5.0。DD 作画的确令人惊艳,但没想到,不到两个月的时间,SD (Stable Diffusion) 斜里杀出,一下子抢了 DD 的风头。之前研究 DD 作画入魔的和菜头,也转头倒向了 SD。下面是他的作品:

人物肖像画

风景画
经过长时间的尝试,关于 SD 可以得出如下结论:
针对人物造型做了优化,不再像 DD 那样会画出奇怪(甚至恐怖)的人物。
在资源消耗上做了很大优化,对 GPU 显存的要求降低到 4GB,老至 GTX 1080 显卡就能胜任,相当亲民。
在作画速度上也有了长足的进步,生成画作可以达到秒级。比如在我使用的 RTX 2080 Ti 显卡上,生成一幅 512 x 512 尺寸的图画,只需要几十秒钟。
SD 是由 CompVis、Stability AI 和 LAION 共同开发的一个文本转图像模型,目前正式开源了代码、模型和权重参数库。如果部署到自己本地的 GPU上,就不用 Stability.ai 提供的服务,可以免费无限量的使用 SD 作画。
更好的消息是,SD 的部署相当简单,可以部署在 Windows、Linux 和 Mac OS 上。硬件要求如下:
4GB 及以上显存的 NVIDIA 显卡,或者 M1 芯片的苹果电脑。
至少 12 GB 内存。
至少 6 GB 的可用磁盘存储空间。
下面就介绍 SD 在 Ubuntu 系统上的部署。
安装 Anaconda
Anaconda 是专门为了方便使用 Python 进行数据科学研究而建立的一组软件包,涵盖了数据科学领域常见的 Python 库,并且自带了专门用来解决软件环境依赖问题的 conda 包管理系统。主要是提供了包管理与环境管理的功能,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题。
安装 Anaconda 非常简单,从他们的网站下载 Anaconda 安装程序脚本即可。网站地址为:
https://www.anaconda.com/products/distribution#linux
Anaconda 的版本也在不断更新,所以下载 URL 可能会随时间变化,如果这样,替换以下脚本的 URL:
# 下载最新版本 Anaconda 3
$ wget https://repo.anaconda.com/archive/Anaconda3-2022.05-Linux-x86_64.sh
# 修改文件为可执行
$ chmod a+x Anaconda3-2022.05-Linux-x86_64.sh
# 安装 Anaconda 3
$ ./Anaconda3-2022.05-Linux-x86_64.sh接下来会有提示,第一个提示输入 yes 接受条款,后面一个提示输入 Anaconda 的安装位置,默认位于 $HOME/anaconda3 下,你也可以自行指定一个位置。
Do you accept the license terms? [yes|no]
[no] >>> yes
Anaconda3 will now be installed into this location:
/home/alex/anaconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/home/alex/anaconda3] >>>安装完毕后,接下来会提示是否进行初始化。这会在 $HOME/.bashrc 文件中增加 Anaconda 的查找路径,方便使用 Anaconda,通常选择 yes 即可。
done
installation finished.
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
[no] >>> yes
no change /data/ai/anaconda3/condabin/conda
no change /data/ai/anaconda3/bin/conda
no change /data/ai/anaconda3/bin/conda-env
no change /data/ai/anaconda3/bin/activate
no change /data/ai/anaconda3/bin/deactivate
no change /data/ai/anaconda3/etc/profile.d/conda.sh
no change /data/ai/anaconda3/etc/fish/conf.d/conda.fish
no change /data/ai/anaconda3/shell/condabin/Conda.psm1
no change /data/ai/anaconda3/shell/condabin/conda-hook.ps1
no change /data/ai/anaconda3/lib/python3.9/site-packages/xontrib/conda.xsh
no change /data/ai/anaconda3/etc/profile.d/conda.csh
no change /home/alex/.bashrc
No action taken.
If you'd prefer that conda's base environment not be activated on startup,
set the auto_activate_base parameter to false:
conda config --set auto_activate_base false
Thank you for installing Anaconda3!通常情况下,我们并不希望 Anaconda 一上来就激活 base 这个 python 运行环境,使用如下命令关掉:
$ conda config --set auto_activate_base false下载模型文件
Stable Diffusion 所需的模型文件托管在 Hugging Face (https://huggingface.co/CompVis/) 上。先按照网站的提示使用电子邮件进行注册。注册后,前往最新的模型存储库,目前最新的模型库是 stable-diffusion-v-1-4-original。
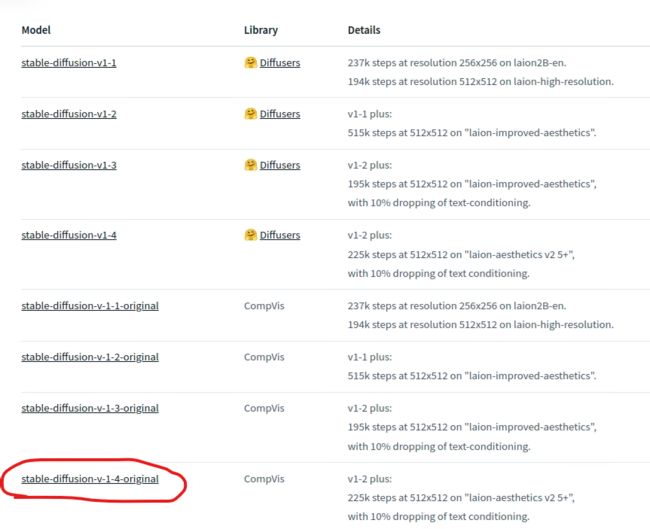
然后下载检查点文件 sd-v1-4.ckpt。

模型文件大约有 4GB 大小,请耐心等待。
下载 SD
这里下载的其实并非官方的 SD,而是网上的一位大神在官方源码的基础上添加了一系列实用脚本的改进版本,支持命令行、 WebUI,并增强了交互性。
$ git clone https://github.com/invoke-ai/InvokeAI.git
$ cd InvokeAI/接下来,建立一个软链接,链接到之前下载的模型文件,这样做的好处是。以后模型如果有更新,修改这个软链接的指向即可。
$ mkdir -p models/ldm/stable-diffusion-v1/
$ ln -s /data/ai/gan/sd/sd-v1-4.ckpt models/ldm/stable-diffusion-v1/model.ckpt创建 conda 环境
依然在 InvokeAI 代码目录下,通过环境文件创建 SD 运行的环境。
conda env create -f environment.yaml这个过程会下载比较多的 python 包,需要一点时间。
运行 SD
上面的步骤完成后,接下来激活 conda 环境,预加载模型。
$ conda activate ldm
(ldm) alex@alex-MS-7C22:/data/ai/gan/sd/InvokeAI$ python scripts/preload_models.py预加载模型也会涉及到一些模型的下载:
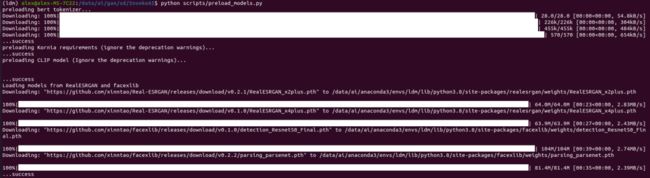
接着运行 dream 脚本:
python scripts/dream.py界面会出现一个提示,在这里输入一些文本,指示 AI 进行作画。也可以输入 -h 寻求帮助,看看支持哪些选项。
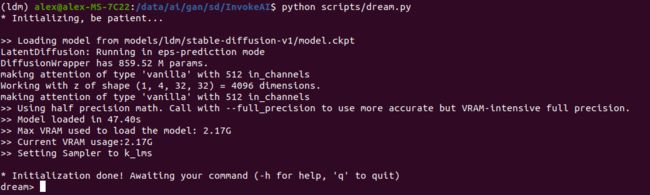
比如,输入如下的提示:
dream> photograph of highly detailed closeup of victoria sponge cake等待个几十秒钟(取决于显卡的性能),在 output/img-sample 文件夹中就可以找到生成的图像。

每次生成图像的同时,还附带一个 dream_log.txt 文件,里面记录了图像生成所使用的 prompt(提示),每个提示后面还有一个种子参数,例如, -S2420237860。有了 prompt 和种子参数,你以后就可以重新生成完全相同的图像。
dream> photograph of highly detailed closeup of victoria sponge cake -S2420237860生成大尺寸图像
默认情况下,SD 的输出为 512x512 像素,不建议采用更大的尺寸,除非你有非常强劲的显卡。在如今普遍 1080P 的时代, 512x512 分辨率确实有点寒碜。不过有一个补救措施,那就是借助 AI 进行放大,实验下来,效果也相当不错。
这里介绍一个名为 Real-ESRGAN 的放大模块,安装非常简单,在 conda ldm 环境下运行:
(ldm) alex@alex-MS-7C22:/data/ai/gan/sd/InvokeAI$ pip install realesrgan安装完毕后,再次运行 dream 脚本,在 dream 提示符下,输入 prompt,在 prompt 末尾加上 -U 参数,表明放大倍数,目前仅支持 2 或者 4。
dream> photograph of highly detailed closeup of victoria sponge cake -U 4这次生成的图像就是 2048x2048 像素,算得上高清图像。
结束语
SD 可以调节的参数还有很多,比如可以根据图片来作画,使用 -n5 等标志来生成多个图像,使用 -s 来指定生成步数,等等。
当然最核心的还是 prompt,高质量的 prompt 可以让 AI 更好的理解你的作画意图。
如果你对绘画知之甚少,也搞不清楚绘画流派、风格,可以去 Lexica.art 网站寻找灵感。那里汇聚了众多玩家摸索出来的 prompt。你可以找到感兴趣的画作,然后复制 prompt,尝试作一些修改,生成属于你自己的作品。
现在,AI 作画甚至催生出一种新的职业,就是帮客户设计出 prompt,然后交给 AI 作画。这一点上,可能艺术生会更具有优势。
关于 AI 作画,你还可以看看我之前的三篇文章:
AI 作画初体验
让AI 作画更快一点
根据中国古诗词作画,AI 可以做到吗?
还可以看一篇西乔撰写的一篇 SD 全面介绍:
当下最强的 AI art 生成模型 Stable Diffusion 最全面介绍
此外,和菜头的微信公众号已经写了很多篇文章探讨 AI 作画,当然是站在用户的角度,有兴趣也可以去围观。