InternImage 论文笔记
一个基于CNN、参数超10亿、训练图像超4亿的大模型。
【65.4 mAP on COCO test-dev and 62.9 mIoU on ADE20K】
Related Work
近年基于transformer的架构,以ViT为例因全局感受野和动态空间聚集取得了巨大成功。但由于其计算昂贵和内存复杂,限制了它在下游任务中的应用。为了解决这个问题,PVT和Linformer对downsampled key和value maps进行全局注意力,DAT使用可变形注意力从value maps中稀疏地采样信息,而HaloNet和Swin transformer开发了局部注意力机制,并使用haloing和shift操作在相邻的局部区域之间传递信息。
一、作者总结的差异结论:
1.CNNs与ViTs:
(1).ViTs1的多头自注意,具有long-range dependence(远距离像素相关性)和自适应空间聚集性
(2).ViTs2还包含一系列标准CNN中不包括的高级组件,如Layer Normalization3、前馈网络(FFN)4、GELU5等。即使通过使用大核(e.g., 31×31)的密集卷积将long-range dependence引入CNNs6,如下图(c)所示。在性能和模型规模方面,与最先进的大规模Vit7仍有相当大的差距。
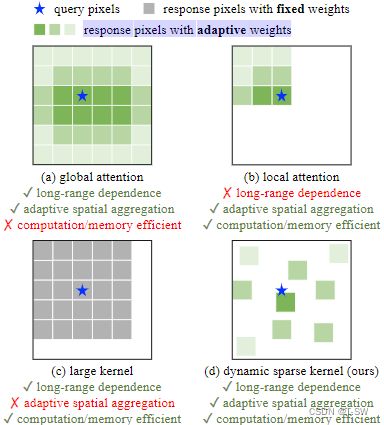
2.Conv与MHSA:
(1).long-range dependence,即具有大的有效感受野的模型通常在任务中表现更好。但即使是深度3×3常规卷积网络,实际有效感受野也无法与ViT相比。
(2).自适应空间聚合。与参考输入动态训练权重的MHSA相比,常规卷积是一种具有静态权重和强归纳偏差的算子,如二维局部性、邻域结构、翻译等价性等。它具有高归纳特性,故可能比ViT更快地收敛且需要的训练数据更少,但也限制了其通用性。
二、模型及其设计思路
InternImage,使用可变形卷积(DCN)8,通过将其与一系列类似于Transformer的层级和结构级设计而成,核心算子是size为3x3的动态稀疏卷积。实现了与大规模ViTs9相当甚至更好的性能。
其优势为:1).灵活的sampling offsets,可以动态学习适当的感受野(长距离/短距离);
2). 自适应调整sampling offsets和modulation scalars,像ViTs一样自适应空间聚合,
减少over-inductive bias of regular convolutions(常规卷积的过归纳偏差);
3).使用3×3卷积核,避免了大核稠密卷积所引起的的优化问题和昂贵的成本10。
由公式推导出DCNv2与MHSA具有相似特性。但DCNv2通常被用作常规卷积的扩展,加载预训练权重并进行微调以获得更好的性能,这并不完全适合需要从头开始训练的大规模模型。故对其扩展为DCNv3:
1).与常规卷积不同,原DCNv2中的不同卷积神经元具有独立的线性映射权重,因此其参数和记忆复杂度与采样点总数呈线性提升,这显著限制了模型的效率,尤其大型模型。为解决这个问题,借鉴了可分离卷积的思想,其中逐通道部分负责原始location-aware modulation scalar(位置感知调节标量),逐点部分负责共享采样点之间的映射权重。
2).引入多组机制。它被广泛应用于MHSA与自适应空间聚合一起工作,以有效地从不同位置的不同表示子空间中学习更丰富的信息。受此启发,将空间聚合过程拆分为G组,因此单个卷积层上的不同组可能具有不同的空间聚合模式,从而为下游任务带来更大的特征。
3).原DCNv2通过sigmoid进行归一化,在使用大规模参数和数据训练时,DCNv2层中的梯度不稳定。改为softmax后,和被约束为1,不同尺度下的模型的训练过程更加稳定。
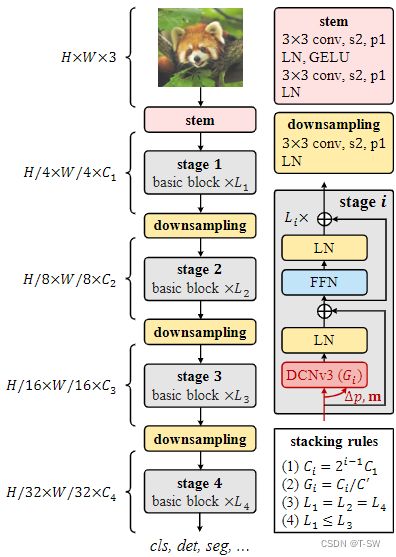
上图为InternImage的总体结构,其中核心算子是DCNv3,基本模块是由layer normal-ization(LN)和FFN组成的transformers,主干层和下采样层遵循传统的CNN设计,其中“s2”和“p1”分别表示stride 2 和padding 1。模型只有4个超参数(C1, C′, L1, L3)。
Basic block,其中核心算子DCNv3及the sampling offsets和modulation scalesare是将输入特征通过可分离卷积(3×3深度卷积+线性映射)来预测的。对于其他组件,我们默认使用标准化设置11,采用与普通transformer12相同的设计。
Stem & downsampling layers,为获得分层特征图,卷积stem和downsampling层调节特征图尺寸。如图上图所示,将stem层放在stage 1前,输入分辨率降为1/4,第一个卷积的输出通道为第二个卷积的一半。而下采样层位于两个stage之间,用于将输入特征图大小降至1/2。
Stacking rules。
超参数解析:1).Ci:stage i的通道数;
2).Gi:stage i有几组DCNv3;
3).Li:stage i中基本块的数量。
模型有4个stage,故其变体由12个超参数决定,这些超参数的搜索空间太大,无法充分枚举并找到最佳变体。为了减少搜索空间,我们将现有技术的设计经验总结13为4条规则:
1).最后三个stage的通道数由第一个stage的通道数C1决定,
2).使group的数量与stage的通道数相对应。
3&4).对于不同阶段的堆叠block的数量设计模式简化为“AABA”,即stage1、stage2和stage4的block数量相同,并且不大于阶段3的block数量。
由上述规则,InternalImage的变体只能通过使用4个超参数(C1,C′,L1,L3)来定义。将一个参数为3000万的模型作为原型,将C1、L1、C′分别离散到{48,64,80}、{1,2,3,4,5}、{16,32}。这样,原始巨大的搜索空间减少到30个,在ImageNet中对30个变体进行训练和评估,找到最佳模型超参数设置(64,16,4,18),由此来定义基础模型并将其缩放到不同的比例。
Scaling rules
不同尺度模型的超参数:

三、实验数据
在仅用ImageNet-1K训练的情况下,InternImage-B上top-1精度达到84.9%。 在10亿参数、4.27亿训练数据下,InternImage-H上top-1精度增长至89.6%。在COCO上以21.8亿参数量达65.4% box mAP,较SwinV2-G14高2.3%且参数量减少27%。 如下图所示。

1.Image Classification
Settings:ImageNet上评估分类性能,遵循惯例15,InternetImage-T/S/B在ImageNet-1K(约130万)上训练了300个epochs;InternetImage-L/XL首先在ImageNet-22K(约1420万)上训练90个epochs,然后在ImageNet-1K上训练了20个epochs。为了进一步探索模型能力,并匹配先前方法16中使用的大规模个人数据,我们采用M3I Pre-training17,在由publicLaion-400M18、YFCC-15M19和CC12M20组成的4.27亿联合数据集上对InternImage-H进行预训练,共30个epochs,然后在ImageNet-1K上微调模型20个epochs。

注:“type”,其中“T”和“C”分别是transformer和CNN。“scale”是输入尺寸。“acc”是 top-1 accuracy.。“‡”表示模型在ImageNet-22K上进行了预训练。“#”表示在超大规模个人数据集(如JFT-300M21、FLD-900M22)或联合公共数据集进行预训练。
2.Object Detection
Settings:Mask R-CNN[70]和Cascade Mask R-CNN[71]。遵循惯例[2,11],使用预先训练的分类权重初始化骨干,并且训练模型默认使用1×(12 epochs)或3×(36 epochs)schedule。

注:COCOval2017上的目标检测和实例分割性能。FLOP是以1280×800为输入计算的。 APb和 APm表示box AP and mask AP。“MS”表示多尺度训练。
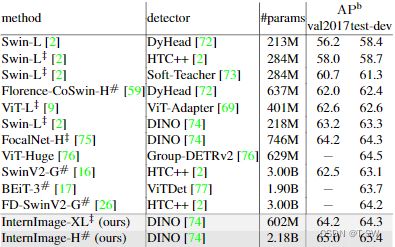
注:在COCOval2017和test-dev上与state-of-the-art 检测器的比较。
3.Semantic Segmentation
Settings:用预先训练的分类权重初始化主干,并在ADE20K23上用UperNet24训练模型进行160k iterations。为了进一步达到最佳性能,给InternImage-H装备更先进的Mask2Former25,并使用[17,69]中相同的训练设置。
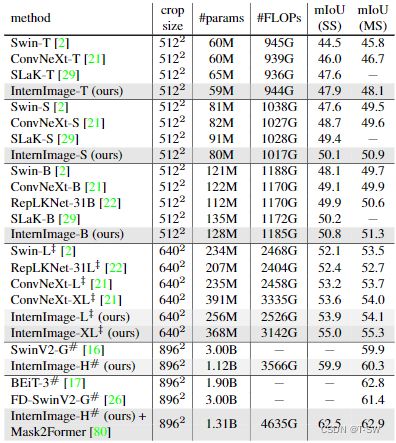
注:ADE20K验证集上的语义分割性能。FLOP根据剪裁尺寸以512×2048、640×2560或896×896为输入进行测量。“SS”和“MS”分别表示单尺度和多尺度测试。
四、Ablation Study(消融研究)
卷积神经元之间的权重共享很重要。由于硬件限制,大型模型对核心算子的参数和内存成本很敏感。DCNv3的卷积神经元之间共享权重。下图,比较了基于DCNv3的具有共享或非共享权重的模型的参数和内存成本。
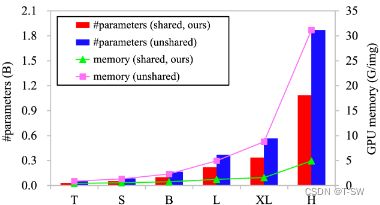
注:右纵轴表示batch size为32且输入图像分辨率为224×224时每个图像的GPU内存使用量。
多组空间聚合带来了更强的特征,使模型能够从不同的表示子空间中学习信息[9]。如图下所示,对于相同的查询像素,来自不同组的偏移集中在不同的区域,从而产生分层的语义特征。下表比较了有多个组和没有多个组的模型的性能,在ImageNet上显著下降1.2%,在COCO val2017上显著下降3.4%。此外,在前两个阶段,学习的有效感受野(ERF)相对较小,随着模型的深入(即第3和第4阶段),ERF增加到全局性。这种现象不同于ViTs[9,10,83],后者的ERF通常是全局的。
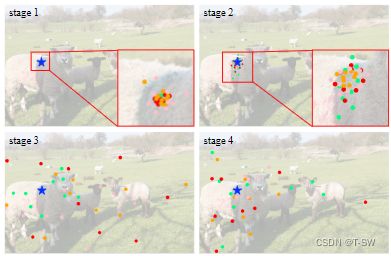
注:在不同阶段对不同组采样位置的可视化。

注:对DCNv3的三种改动的消融比较。实验基于分类的InternImage-T和检测的Mask R-CNN 1×schedule。
局限:高延迟,不适于下游任务。
论文链接:
InternImage: Exploring Large-Scale Vision Foundation Models withDeformable Convolutions
ps:下为论文内文献索引,供拓展使用。更多实验数据请见论文附录。
paper[9,21,22] ↩︎
paperpaper[9,22,23] ↩︎
paper[24] ↩︎
paper[1] ↩︎
paper[25] ↩︎
paper[21,22] ↩︎
paper[16,18-20,26] ↩︎
paper[27,28] ↩︎
paper[2,11,30] ↩︎
paper[22,29] ↩︎
paper[57] ↩︎
paper[1,9] ↩︎
paper[2,21,36] ↩︎
paper[16] ↩︎
paper[2,10,21,58] ↩︎
paper[16,20,59] ↩︎
paper[60] ↩︎
paper[61] ↩︎
paper[62] ↩︎
paper[63] ↩︎
paper[68] ↩︎
paper[59] ↩︎
paper[82] ↩︎
paper[81] ↩︎
paper[80] ↩︎