Attention机制和transformer模型
1. 引言
自然语言处理(Natural Language Processing, NLP)是一种重要的人工智能(Artificial Intelligence, AI)技术,可以完成文本分类、序列标注、自动问答、机器翻译和摘要生成等任务,促进了搜索引擎、智能客服和推荐系统等应用的产生和发展,影响着生活的方方面面,值得我们去学习和研究。
最近几年,基于深度学习(Deep Learning, DL)的NLP技术在各项任务中取得了很好的效果,这些基于深度学习模型的NLP任务解决方案通常不使用传统的、特定任务的特征工程而是仅仅使用一个端到端(end-to-end)的神经网络模型就可以获得很好的效果。其中,Transformer是目前最前沿的深度学习模型结构,与之相关的概念有目前很火的attention(注意力)机制和BERT等。
在飞速发展的计算机领域,紧跟技术前沿是非常重要的,因此我们很有必要去学习目前最流行也是最有潜力的transformer模型架构及其相关知识。首先,本文将介绍之前比较流行的NLP处理技术seq2seq模型及其局限性。然后,本文将引出可解决seq2seq模型局限性的attention机制的思想和具体原理。最后,本文将介绍基本能够取代RNN的包括attention机制的transformer模型架构。
2. seq2seq模型
2.1 功能
seq2seq模型是RNN最重要的一个变种,可以处理非等长的输入和输出序列。

例如,在机器翻译中,输入一连串的单词,可以输出一连串其他语言的单词。

2.2 结构
seq2seq 模型是由编码器(Encoder)和解码器(Decoder)组成的。其中,编码器会处理输入序列中的每个元素,把这些信息转换为一个向量(称为上下文(context))。当我们处理完整个输入序列后,编码器把上下文(context)发送给解码器,解码器开始逐项生成输出序列中的元素。
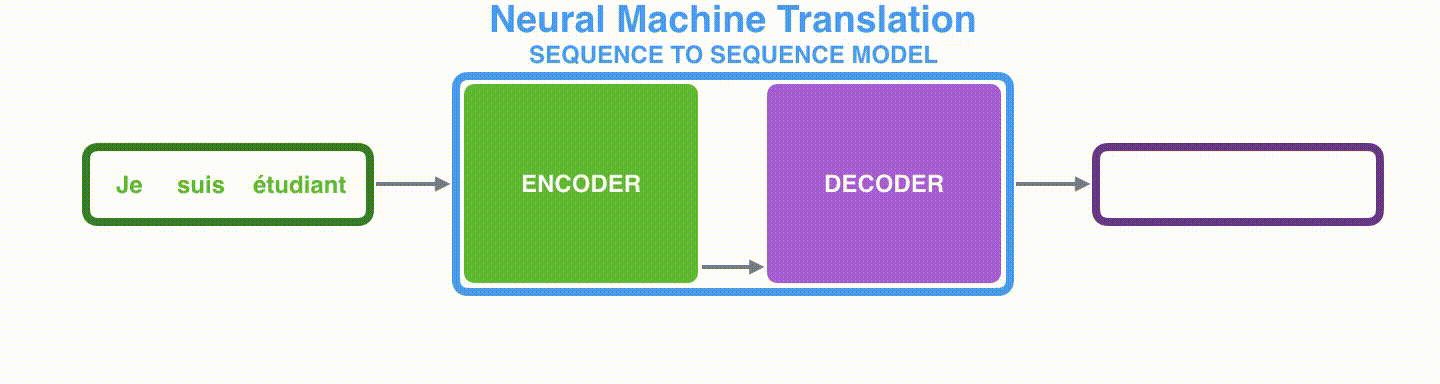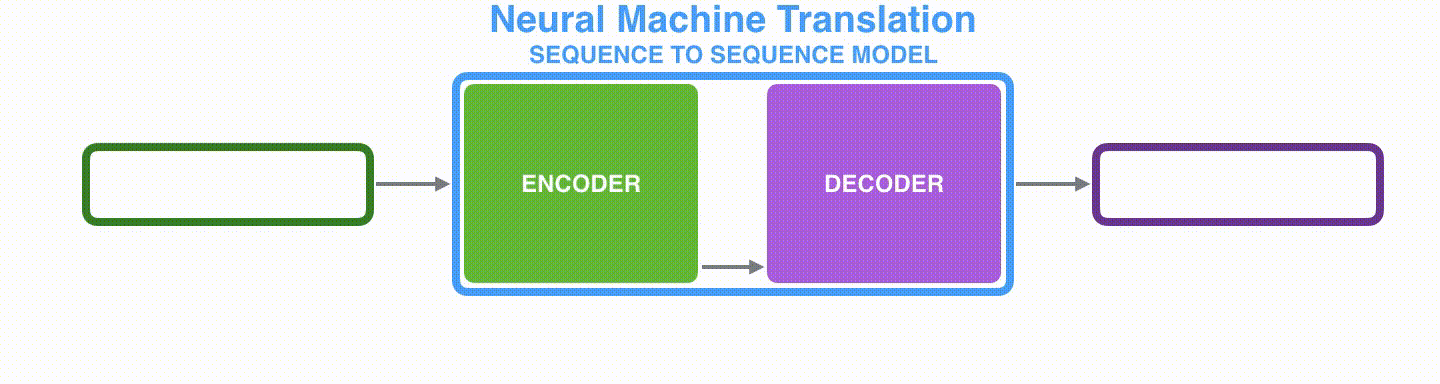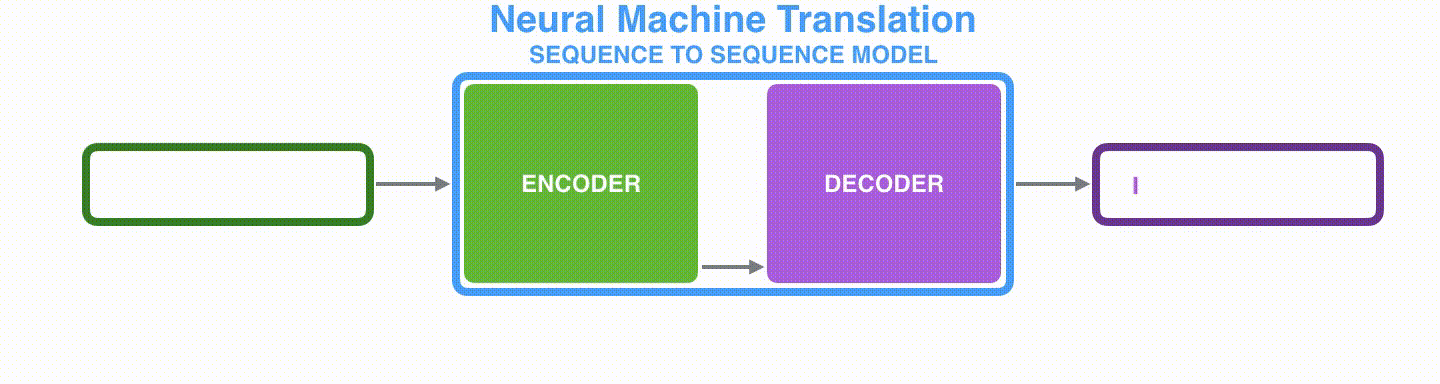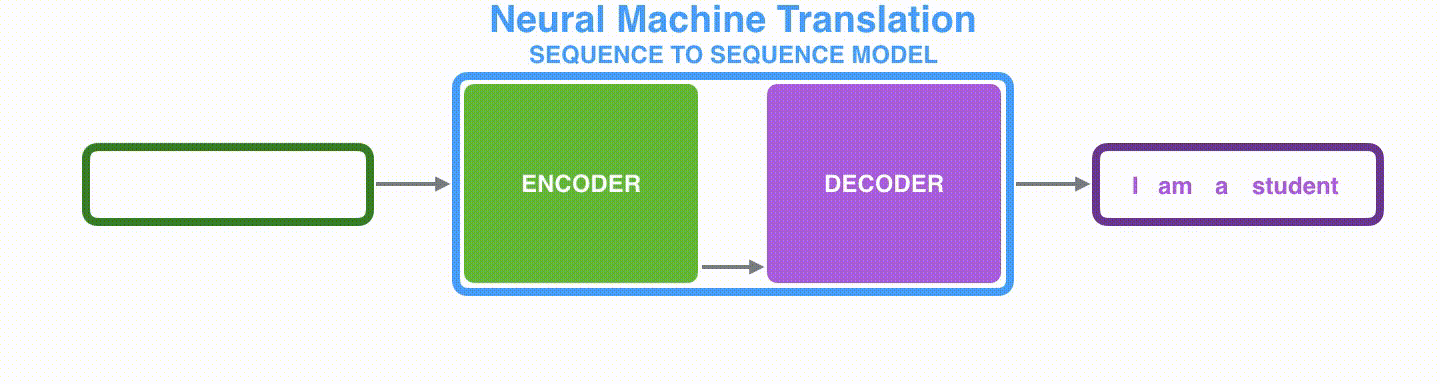
得到 context 有多种方式,最简单的方法就是把 Encoder 的最后一个隐状态赋值给 context,还可以对最后的隐状态做一个变换得到 context,也可以对所有的隐状态做变换。其中,编码器和解码器一般都使用 RNN 结构。
2.3 运行
在机器翻译任务中,上下文(context)是一个向量(基本上是一个数字数组)。

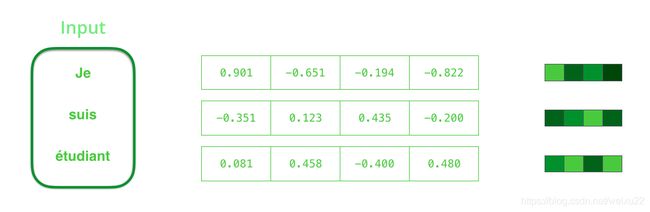
你可以在编写seq2seq模型的时候设置上下文向量的长度。这个长度是基于编码器 RNN 的隐藏层神经元的数量。上图展示了长度为 4 的向量,但在实际应用中,上下文向量的长度可能是 256,512 或者 1024。
我们在处理单词之前,需要把他们转换为向量。这个转换是使用 word embedding 算法来完成的。
模型的主要模块是 RNN,其机制如下图所示:
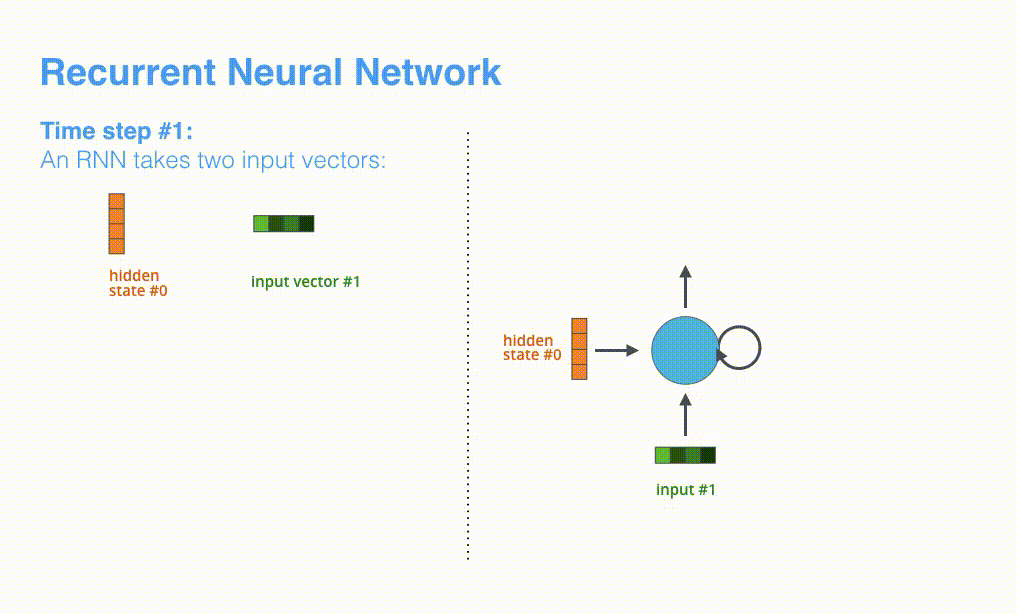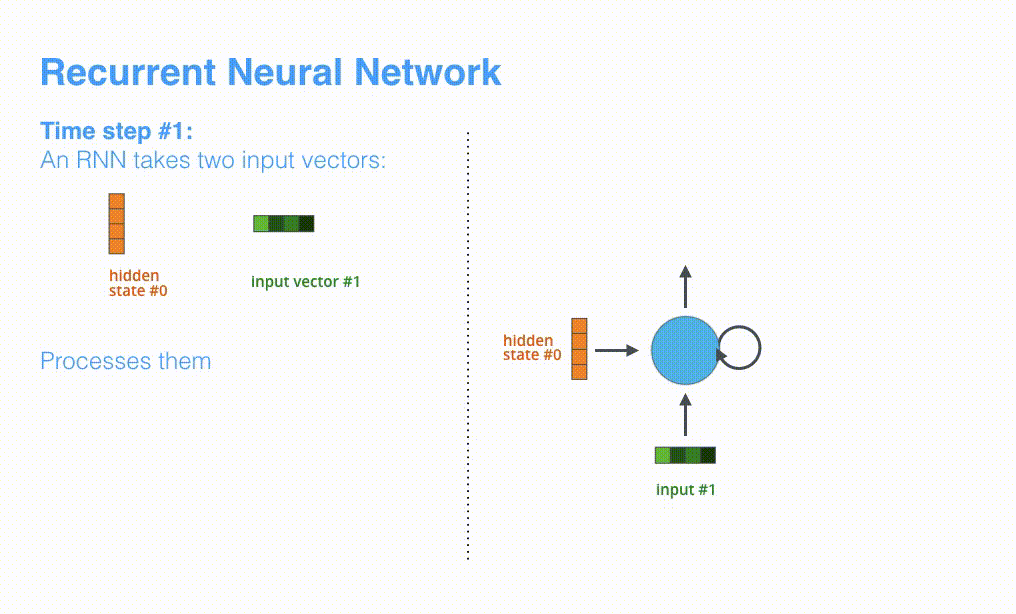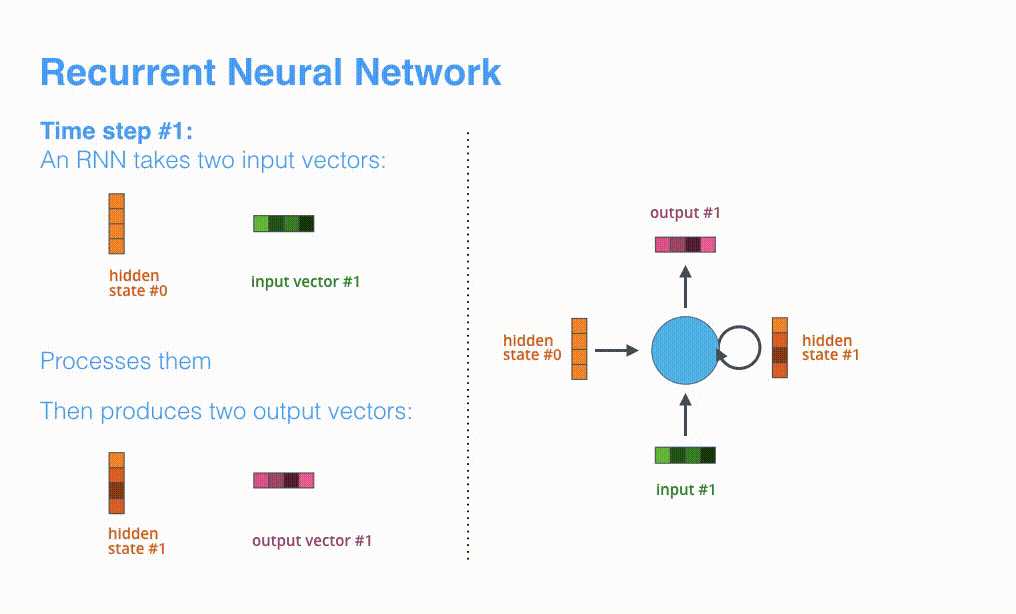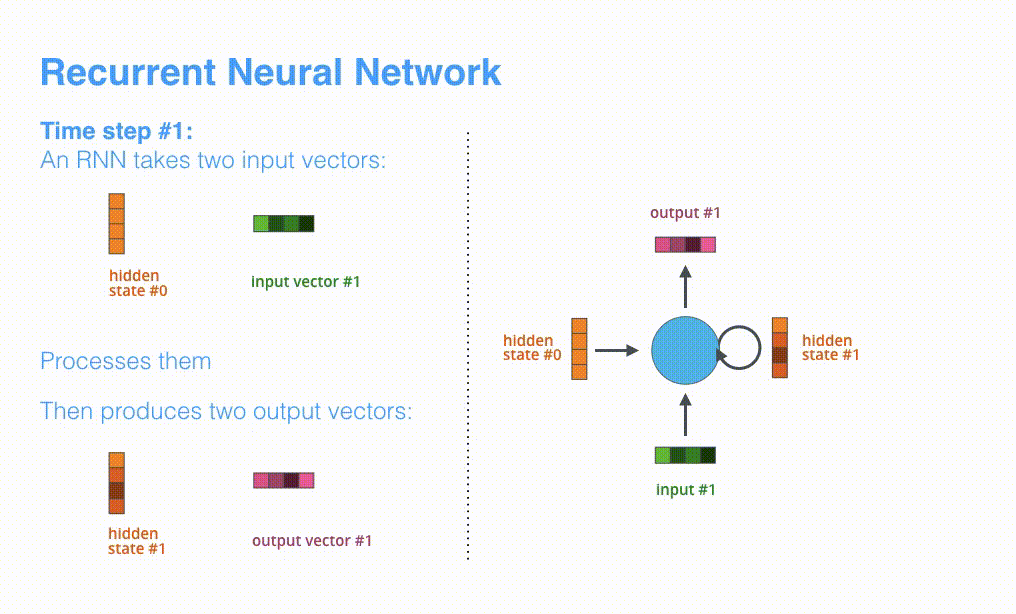
Seq2seq 在机器翻译等应用中,呈现出序列计算的特点,如下所示:
2.4 局限
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征 context 再解码,因此, context 中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个 context 可能存不下那么多信息,就会造成翻译精度的下降。
3. Attention机制
3.1 功能
在 Bahdanau等2014发布的Neural Machine Translation by Jointly Learning to Align and Translate 和 Luong等2015年发布的Effective Approaches to Attention-based Neural Machine Translation
两篇论文中,提出并改进了一种叫做注意力 Attention 的技术,它极大地提高了机器翻译的质量。注意力机制可以使模型根据需要,个性化地在每个输出时间步使用不同的 context 来解决单一 context 存储信息受限的问题。

3.2 结构
注意力模型不同于经典的序列到序列(seq2seq)模型,主要体现在 2 个方面:
首先,编码器会把更多的数据传递给解码器。编码器把所有时间步的 hidden state(隐藏层状态)传递给解码器,而不是只传递最后一个 hidden state(隐藏层状态):
第二,注意力模型的解码器在产生输出之前,做了一个额外的处理。为了把注意力集中在与该时间步相关的输入部分。解码器做了如下的处理:
- 查看所有接收到的编码器的 hidden state(隐藏层状态)。其中,编码器中每个 hidden state(隐藏层状态)都对应到输入句子中一个单词。
- 给每个 hidden state(隐藏层状态)一个分数(我们先忽略这个分数的计算过程)。
- 将每个 hidden state(隐藏层状态)乘以经过 softmax 的对应的分数,从而,高分对应的 hidden state(隐藏层状态)会被放大,而低分对应的 hidden state(隐藏层状态)会被缩小。
- 对所有 hidden state进行加权求和,得到个性化的 context 用于解码。
3.3 运行
注意力模型的整个过程:
- 注意力模型的解码器 RNN 的输入包括:一个embedding 向量,和一个初始化好的解码器 hidden state(隐藏层状态)。
- RNN 处理上述的 2 个输入,产生一个输出和一个新的 hidden state(隐藏层状态 h4 向量),其中输出会被忽略。
- 注意力的步骤:我们使用编码器的 hidden state(隐藏层状态)和 h4 向量来计算这个时间步的上下文向量(C4)。
- 我们把 h4 和 C4 拼接起来,得到一个向量。
- 我们把这个向量输入一个前馈神经网络(这个网络是和整个模型一起训练的)。
- 前馈神经网络的输出表示这个时间步输出的单词。
- 在下一个时间步重复这个步骤。
请注意,注意力模型不是无意识地把输出的第一个单词对应到输入的第一个单词。实际上,它从训练阶段学习到了如何在两种语言中对应单词的关系(在我们的例子中,是法语和英语)。
3.4 注意力分数的计算
为了便于说明,我们以 RNN 作为具体模型的 Encoder-Decoder 框架为例。
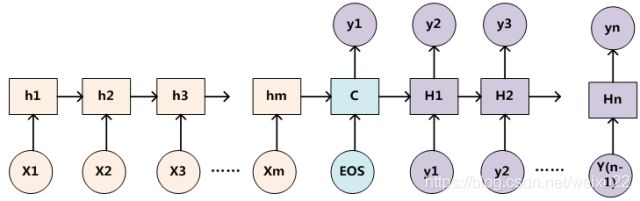
其中,EOS 表示 End Of Sentence,在这里作为一句话的开始,也即上一句话的结束。
下图可以较为便捷地说明注意力分配概率分布值的通用计算过程。

对于采用 R N N RNN RNN 的 D e c o d e r Decoder Decoder 来说,在时刻 i i i,如果要生成 y i y_i yi 单词,我们是可以知道 T a r g e t Target Target 在生成 y i y_i yi 之前的时刻,隐层节点的输出值 H i − 1 H_{i-1} Hi−1 的,而我们的目的是要计算生成 y i y_i yi 时输入句子中的单词对 y i y_i yi 来说的注意力分配概率分布。我们通过函数 F ( h j , H i − 1 ) F(h_j,H_{i-1}) F(hj,Hi−1) 来获得目标单词 y i y_i yi 和每个输入单词对应的对齐可能性,这个函数在不同论文里可能会采取不同的方法,然后函数的输出经过 S o f t m a x Softmax Softmax 进行归一化就得到了注意力分配概率分布数值。
绝大多数Attention模型都是采取上述的计算框架来计算注意力分配概率分布信息。
4. Transformer模型
在 RNN 中,每一个 time step 的计算都依赖于上一个 time step 的输出,这就使得所有的 time step 必须串行化,无法并行计算,如下图所示。
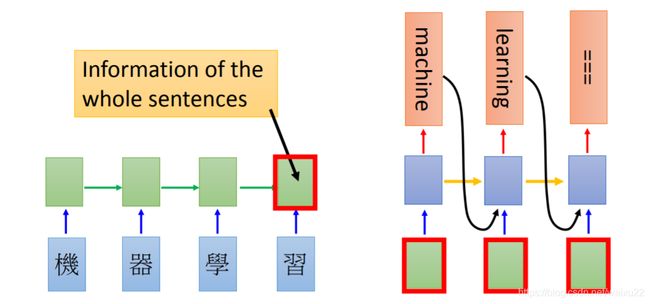
在 Transformer 中,所有 time step 的数据都是经过 Self Attention 计算,使得整个运算过程可以并行化。
4.1 功能
Transformer模型与seq2seq各类模型的功能是一致的,不同点在于其内部结构考虑了自注意力机制。

4.2 Encoder(编码器)
4.2.1 输入和输出
和通常的 NLP 任务一样,我们首先会使用词嵌入算法(embedding algorithm),将每个词转换为一个词向量。实际中向量一般是 256 或者 512 维。为了简化起见,这里将每个词的转换为一个 4 维的词向量。
那么整个输入的句子是一个向量列表,其中有 3 个词向量。在实际中,每个句子的长度不一样,我们会取一个适当的值,作为向量列表的长度。如果一个句子达不到这个长度,那么就填充全为 0 的词向量;如果句子超出这个长度,则做截断。句子长度是一个超参数,通常是训练集中的句子的最大长度,你可以尝试不同长度的效果。
编码器(Encoder)接收的输入都是一个向量列表,输出也是大小同样的向量列表,然后接着输入下一个编码器。

每个单词转换成一个向量之后,进入self-attention层,每个位置的单词得到新向量,然后再输入 FFN 神经网络。
4.2.2 Self-Attention
当模型处理句子中的每个词时,Self Attention 机制使得模型不仅能够关注这个位置的词,而且能够关注句子中其他位置的词,作为辅助线索,进而可以更好地编码当前位置的词。

如上图可视化图所示,当我们在第五层编码器中(编码部分中的最后一层编码器)编码“it”时,有一部分注意力集中在“The animal”上,并且把这两个词的信息融合到了"it"这个单词中。
计算 Self Attention 的第 1 步是:对输入编码器的每个词向量,都创建 3 个向量,分别是:Query 向量,Key 向量,Value 向量。这 3 个向量是词向量分别和 3 个矩阵相乘得到的,而这个矩阵是我们要学习的参数。
注意,这 3 个新得到的向量一般比原来的词向量的长度更小。假设这 3 个向量的长度是 d k e y d_{key} dkey,而原始的词向量或者最终输出的向量的长度是 512(这 3 个向量的长度,和最终输出的向量长度,是有倍数关系的)。为了简化,假设只有一个 head 的 Self-Attention。

第 2 步,是计算 Attention Score(注意力分数)。假设我们现在计算第一个词 Thinking 的 Attention Score(注意力分数),需要根据 Thinking 这个词,对句子中的其他每个词都计算一个分数。这些分数决定了我们在编码Thinking这个词时,需要对句子中其他位置的每个词放置多少的注意力。
这些分数,是通过计算 “Thinking” 对应的 Query 向量和其他位置的每个词的 Key 向量的点积,而得到的。如果我们计算句子中第一个位置单词的 Attention Score(注意力分数),那么第一个分数就是 q1 和 k1 的内积,第二个分数就是 q1 和 k2 的点积。
第 3 步就是把每个分数除以 ( d k e y ) \sqrt(d_{key}) (dkey) ( d k e y d_{key} dkey是 Key 向量的长度)。你也可以除以其他数,除以一个数是为了在反向传播时,求取梯度更加稳定。
第 4 步,接着把这些分数经过一个 Softmax 层,Softmax可以将分数归一化,这样使得分数都是正数并且加起来等于 1。
第 5 步,得到每个位置的分数后,将每个分数分别与每个 Value 向量相乘。这种做法背后的直觉理解就是:对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能是相关性不大的,这样我们就忽略了这些位置的词。
第 6 步是把上一步得到的向量相加,就得到了 Self Attention 层在这个位置(这里的例子是第一个位置)的输出。

上面这张图,包含了 Self Attention 的全过程,最终得到的当前位置(这里的例子是第一个位置)的向量会输入到前馈神经网络。但这样每次只能计算一个位置的输出向量,在实际的代码实现中,Self Attention 的计算过程是使用矩阵来实现的,这样可以加速计算,一次就得到所有位置的输出向量。
4.2.3 多头注意力机制
Transformer 的论文通过增加多头注意力机制(一组注意力称为一个 attention head),进一步完善了 Self Attention 层。这种机制从如下两个方面增强了 attention 层的能力:
- 它扩展了模型关注不同位置的能力。在上面的例子中,第一个位置的输出 z1 包含了句子中其他每个位置的很小一部分信息,但 z1 可能主要是由第一个位置的信息决定的。当我们翻译句子:
The animal didn’t cross the street because it was too tired时,我们想让机器知道其中的it指代的是什么。这时,多头注意力机制会有帮助。 - 多头注意力机制赋予 attention 层多个“子表示空间”。下面我们会看到,多头注意力机制会有多组 W Q , W K W V W^Q, W^K W^V WQ,WKWV 的权重矩阵(在 Transformer 的论文中,使用了 8 组注意力(attention heads)。因此,接下来我也是用 8 组注意力头 (attention heads))。每一组注意力的 的权重矩阵都是随机初始化的。经过训练之后,每一组注意力 W Q , W K W V W^Q, W^K W^V WQ,WKWV 可以看作是把输入的向量映射到一个”子表示空间“。
4.3 Decoder(解码器)
在完成了编码(encoding)阶段之后,我们开始解码(decoding)阶段。解码(decoding )阶段的每一个时间步都输出一个翻译后的单词(这里的例子是英语翻译)。
接下来会重复这个过程,直到输出一个结束符(END 或 EOS),Transformer 就完成了所有的输出。每一步的输出都会在下一个时间步输入到下面的第一个解码器。Decoder 就像 Encoder 那样,从下往上一层一层地输出结果。正对如编码器的输入所做的处理,我们把解码器的输入向量,也加上位置编码向量,来指示每个词的位置。

解码器中的 Self Attention 层,和编码器中的 Self Attention 层不太一样:在解码器里,Self Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self Attention 分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置。
Encoder-Decoder Attention层的原理和多头注意力(multiheaded Self Attention)机制类似,不同之处是:Encoder-Decoder Attention层是使用前一层的输出来构造 Query 矩阵,而 Key 矩阵和 Value 矩阵来自于解码器最终的输出。
4.4 最后的线性层和 Softmax 层
线性层就是一个普通的全连接神经网络,可以把解码器输出的向量,映射到一个更长的向量,这个向量称为 logits 向量。
现在假设我们的模型有 10000 个英语单词(模型的输出词汇表),这些单词是从训练集中学到的。因此 logits 向量有 10000 个数字,每个数表示一个单词的分数。我们就是这样去理解线性层的输出。
然后,Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。然后选择最高概率的那个数字对应的词,就是这个时间步的输出单词。
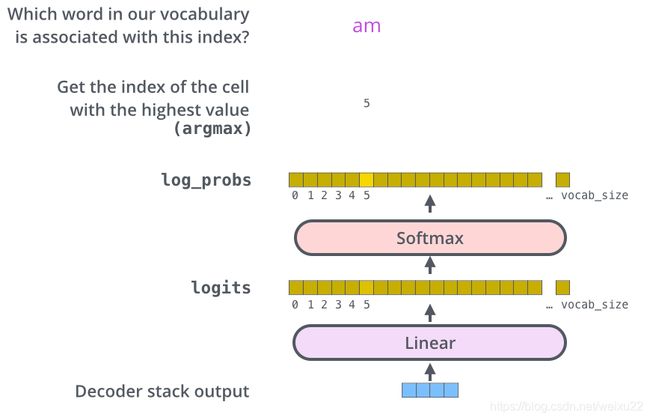
在上图中,最下面的向量,就是编码器的输出,这个向量输入到线性层和 Softmax 层,最终得到输出的词。
参考资料
- 何之源. 完全图解RNN、RNN变体、Seq2Seq、Attention机制
- 张俊林. 深度学习中的注意力模型(2017版)
- 张俊林. 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
- Datawhale 开源教程