Redis集群(cluster)
redis集群(cluster)
简介
【学习目标】
- 掌握集群优势
- 掌握集群搭建
- 集群原理
- 掌握项目服务改造
【理论知识】
1. 集群概念与优缺点
2. 数据分区算法
3. redis-benchmark命令
4. 集群分试算法
【实际操作】
1. 集群搭建与配置
2. 集群环境测试
3. 性能测试
集群介绍
集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源,这些单个的计算机系统就是集群的节点(node)。集群提供了以下关键的特性。
- 可扩展性。集群的性能不限于单一的服务实体,新的服务实体可以动态的加入到集群,从而增强集群的性能。
- 高可用性。集群通过服务实体冗余使客户端免于轻易遭遇到“out of service”警告。当一台节点服务器发生故障的时候,这台服务器上所运行的应用程序将在另一节点服务器上被自动接管。消除单点故障对于增强数据可用性、可达性和可靠性是非常重要的。
- 负载均衡。负载均衡能把任务比较均匀的分布到集群环境下的计算和网络资源,以便提高数据吞吐量。
- 错误恢复。如果集群中的某一台服务器由于故障或者维护需要而无法使用,资源和应用程序将转移到可用的集群节点上。这种由于某个节点中的资源不能工作,另一个可用节点中的资源能够透明的接管并继续完成任务的过程叫做错误恢复。
分布式与集群的联系与区别如下:
- 分布式是指将不同的业务分布在不同的地方。
- 而集群指的是将一台服务器集中在一起,实现同一业务。
- 分布式的每一个节点,都可以做集群,而集群并不一定就是分布式的。而分布式,从狭义上理解,也与集群差不多,但是它的组织比较松散,不像集群,有一定组织性,一台服务器宕了,其他的服务器可以顶上来。分布式的每一个节点,都完成不同的业务,一个节点宕了,这个业务就不可访问了。
集群主要分成三大类:
HA:高可用集群(High Availability Cluster)。
LBC:负载均衡集群/负载均衡系统(Load Balance Cluster)
HPC:科学计算集群(High Performance Computing Cluster)/高性能计算(High Performance Computing)集群。
Redis集群架构
假设上千万、上亿用户同时访问 Redis,QPS 达到 10 万+。这些请求过来,单机 Redis 直接就挂了。系 统的瓶颈就出现在 Redis 单机问题上,此时我们可以通过主从复制解决该问题,实现系统的高并发。
主从模式中,当主节点宕机之后,从节点是可以作为主节点顶上来继续提供服务,但是需要修改应用的方主节点地址,还需要命令所有从节点去复制新的主节点,整个过程需要人工干预。于是,在 Redis 2.8 版 本开始,引入了哨兵(Sentinel)这个概念,在主从复制的基础上,哨兵实现了自动化故障恢复。
哨兵模式中,单个节点的写能力,存储能力受到单机的限制,动态扩容困难复杂。于是,Redis 3.0 版本 正式推出 Redis Cluster 集群模式,有效地解决了 Redis 分布式方面的需求。Redis Cluster 集群模式具有高可用、可扩展性、分布式、容错等特性。
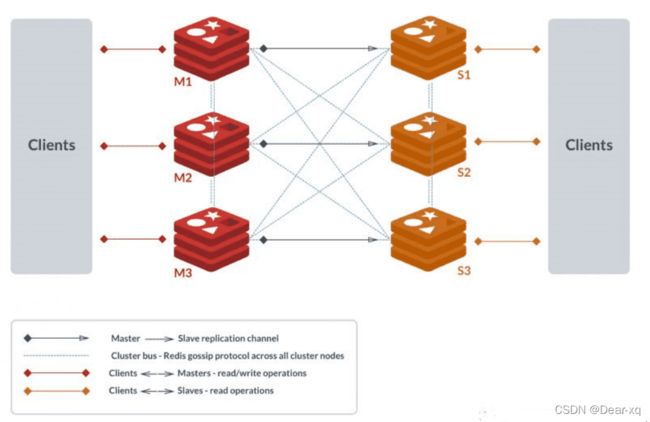
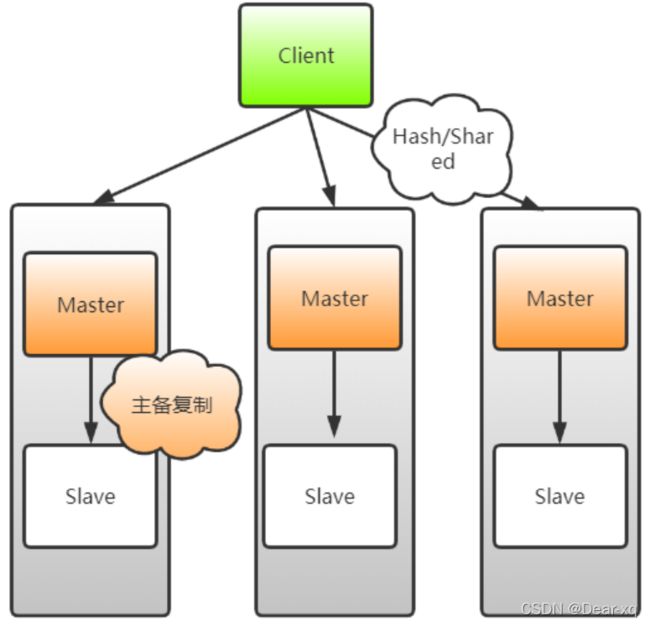
Redis Cluster 采用无中心结构,每个节点都可以保存数据和整个集群状态,每个节点都和其他所有节点 连接。Cluster 一般由多个节点组成,节点数量至少为 6 个才能保证组成完整高可用的集群,其中三个为 主节点,三个为从节点。三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后, 顶替主节点。
配置一个 Redis Cluster 我们需要准备至少 6 台 Redis,为啥至少 6 台呢?我们可以在 Redis 的官方文 档中找到如下一句话:
Note that the minimal cluster that works as expected requires to contain at least three master nodes.
因为最小的 Redis 集群,需要至少 3 个主节点,既然有 3 个主节点,而一个主节点搭配至少一个从节 点,因此至少得 6 台Redis。如上图所示,该集群中包含 6 个 Redis 节点,3 主 3 从,分别为 M1, M2,M3,S1,S2,S3。除了主从 Redis 节点之间进行数据复制外,所有 Redis 节点之间采用 Gossip 协议进行通信,交换维护节点元数据信息。
总结下来就是:读请求分配给 Slave 节点,写请求分配给 Master,数据同步从 Master 到 Slave 节点。
主从模式
Redis Cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点 提供数据存取,从节点复制主节点数据备份,当这个主节点挂掉后,就会通过这个主节点的从节点选取一个来充当主节点,从而保证集群的高可用。
回到刚才的例子中,集群有 A、B、C 三个主节点,如果这 3 个节点都没有对应的从节点,如果 B 挂掉 了,则集群将无法继续,因为我们不再有办法为 5501 ~ 11000 范围内的哈希槽提供服务。
所以我们在创建集群的时候,一定要为每个主节点都添加对应的从节点。比如,集群包含主节点 A、B、 C,以及从节点 A1、B1、C1,那么即使 B 挂掉系统也可以继续正确工作。
因为 B1 节点属于 B 节点的子节点,所以 Redis 集群将会选择 B1 节点作为新的主节点,集群将会继续正 确地提供服务。当 B 重新开启后,它就会变成 B1 的从节点。但是请注意,如果节点 B 和 B1 同时挂掉, Redis Cluster 就无法继续正确地提供服务了。
优点
- 去中心化;
- 可扩展性,数据按照 Slot 存储分布在多个节点,节点间数据共享,节点可动态添加或删除,可动态调 整数据分布;
- 高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本;
- 实现故障自动迁移,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave 到 Master 的 ⻆色提升。
缺点
- 数据通过异步复制,无法保证数据强一致性;
- 集群环境搭建略微复杂。
数据分区方式
随着请求量和数据量的增加,一台机器已经无法满足需求,我们就需要把数据和请求分散到多台机器。这 时候就需要引入分布式存储。分布式存储有以下特性:
- 增强可用性:如果数据库的某个节点出现故障,在其他节点的数据仍然可用;
- 维护方便:如果数据库的某个节点出现故障,需要修复数据,只修复该节点即可;
- 均衡I/O:可以把不同的请求映射到各节点以平衡I/O,改善整个系统性能;
- 改善查询性能:对分区对象的查询可以仅搜索自己关心的节点,提高检索速度。
分布式存储一先要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点 上,每个节点负责整体数据的一个子集
常用分区算法
范围分区
范围分区将数据基于范围映射到每一个分区,这个范围是你在创建分区时指定的分区键决定的。数据库中这种分区方式是最为常用的,并且分区键经常采用日期。
- **优点:**同⼀范围内的范围查询不需要跨节点,提升查询速度
- **应用场景:**MySQL,Oracle
节点取余分区
一般是通过数据的某个特征计算哈希值,并将哈希值与集群中的服务器建立映射关系,从而将不同数据分 布到不同服务器上。 hash(object) % N
- **优点:**实现简单
- **缺点:**当扩容或收缩节点时,需要迁移的数据量大。(翻倍扩容可以相对减少迁移量)
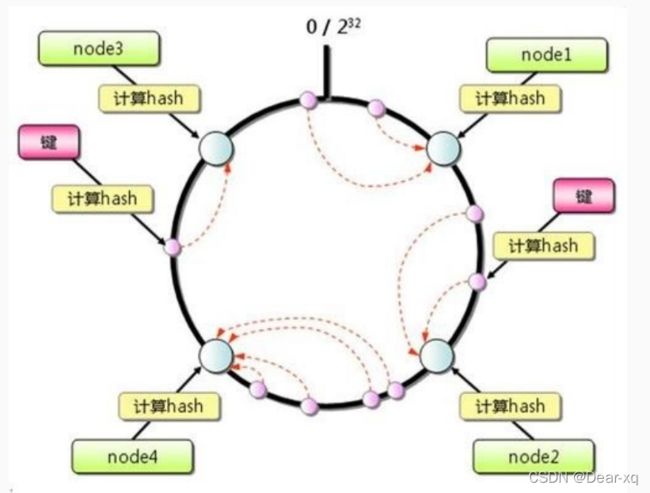
一致性哈希分区
实现思路是为系统中每个节点分配一个token,范围一般在0~2^32,这些token构成一个哈希环。数据读写执行节点查找操作时,先根据key计算hash值,然后顺时针找到第一个大于等于该哈希值的token节点。
- 优点:这种方式相比节点取余最大的好处在于加入和删除节点只影响哈希环中相邻的节点,对其他节点无影响。
- 缺点:当使用少量节点时,节点变化将大范围影响哈希环中数据映射,因此这种方式不适合少量数据节点的分布式方案。
- 应用场景:Memcached
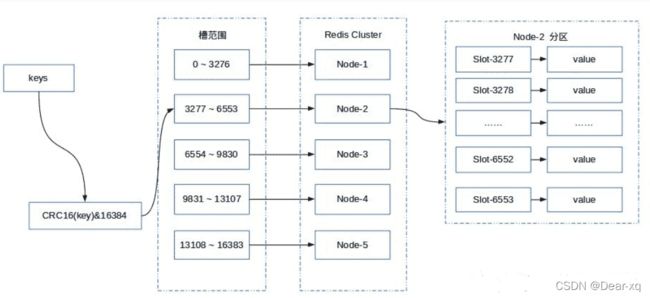
虚拟槽分区
在一致性hash分区的基础上加入了虚拟槽(slot)的概念,通过 virtual slot 将哈希环分割成更小的粒度,小粒度的 slot 块被不同的 node 持有。
- **优点:**每个node均匀的分配了slot,缩小增减节点影响的范围
- **缺点:**需要存储node和slot的对应信息
- **应用场景:**Redis Cluster
集群环境搭建
Redis 集群搭建在5版本以前使用Ruby构建集群,而5版本以后直接使用 redis-cli 命令创建集群了。
节点准备
| IP | Redis节点 |
|---|---|
| 192.168.10.101 | 6371,6372 |
| 192.168.10.102 | 6373,6374 |
| 192.168.10.103 | 6375,6376 |
创建目录
三个节点分别创建以下录。
mkdir -p /usr/local/redis/cluster/conf /usr/local/redis/cluster/data /usr/local/redis/cluster/log
编写配置文件
三个节点分别创建 redis-**.conf 并添加以下配置(* 为具体端口为了区分分件)。
注意:修改配置文件中所有 IP 和端口部分内容,可以使用 vi 命令 %s/old/new/g 全局替换。
#(注意配置文件名称起名规则)
vim /usr/local/redis/cluster/conf/redis-6371.conf
# 放行访问IP限制
bind 0.0.0.0
# 端口
port 6371
# 后台启动
daemonize yes
# 日志存储目录及日志文件名
logfile "/usr/local/redis/cluster/log/redis-6371.log"
# rdb数据文件名
dbfilename dump-6371.rdb
# aof模式开启和aof数据文件名
appendonly yes
appendfilename "appendonly-6371.aof"
# rdb数据文件和aof数据文件的存储目录
dir /usr/local/redis/cluster/data
# 设置密码
requirepass 123456
# 从节点访问主节点密码(必须与 requirepass 一致)
masterauth 123456
# 是否开启集群模式,默认 no
cluster-enabled yes
# 集群节点信息文件,会保存在 dir 配置对应目录下
cluster-config-file nodes-6371.conf
# 集群节点连接超时时间
cluster-node-timeout 15000
# 集群节点 IP
cluster-announce-ip 192.168.10.101
# 集群节点映射端口
cluster-announce-port 6371
# 集群节点总线端口
cluster-announce-bus-port 16371
每个 Redis 集群节点都需要打开两个 TCP 连接。一个用于为客户端提供服务的正常 Redis TCP 端口,例如 6379。还有一个基于 6379 端口加 10000 的端口,比如 16379。
第二个端口用于集群总线,这是一个使用二进制协议的节点到节点通信通道。节点使用集群总 线进行故障检测、配置更新、故障转移授权等等。客户端永远不要尝试与集群总线端口通信, 与正常的 Redis 命令端口通信即可,但是请确保防火墙中的这两个端口都已经打开,否则 Redis 集群节点将无法通信。
创建 Redis Cluster 集群
启动 6 个 Redis 节点
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6371.conf
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6372.conf
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6373.conf
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6374.conf
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6375.conf
/usr/local/redis/bin/redis-server /usr/local/redis/cluster/conf/redis-6376.conf
创建集群
随便一个 Redis 节点中使用客户端运行以下命令即可(注意IP和端口):
/usr/local/redis/bin/redis-cli -a 123456 --cluster create \
2 192.168.10.101:6371 192.168.10.101:6372 \
3 192.168.10.102:6373 192.168.10.102:6374 \
4 192.168.10.103:6375 192.168.10.103:6376 \
5 --cluster-replicas 1
- –cluster:构建集群环境的所有 Redis 节点 IP + PORT 信息
- –cluster-replicas 1:主节点数/从节点数的比例,使用一比一的比例,6 个节点最终会产生 3 主 3 从的集群环境

出现选择提示信息,输出 yes,结果如下所示,集群创建成功:
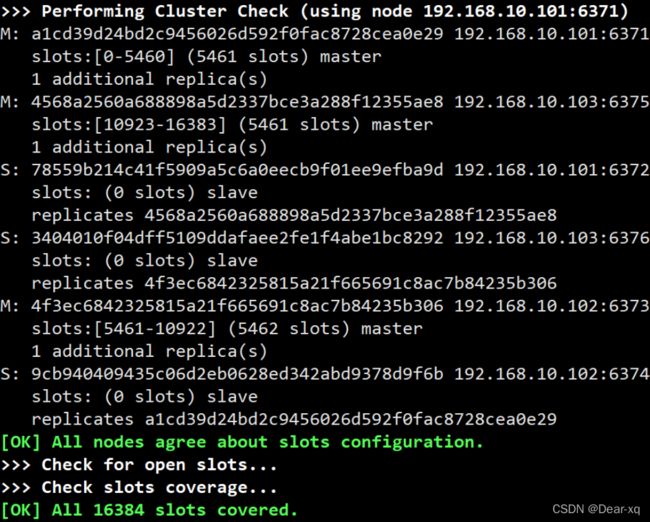
至此一个高可用的 Redis Cluster 集群搭建完成,如下图所示,该集群中包含 6 个 Redis 节点,3 主 3 从。三个主节点会分配槽,处理客户端的命令请求,而从节点可用在主节点故障后,顶替主节点。
检查集群状态
任意一个节点即可,运行以下命令。
/usr/local/redis/bin/redis-cli -a 123456 --cluster check 192.168.10.101:6371
# 主节点信息
192.168.10.101:6371 (a1cd39d2...) -> 0 keys | 5461 slots | 1 slaves.
192.168.10.103:6375 (4568a256...) -> 0 keys | 5461 slots | 1 slaves.
192.168.10.102:6373 (4f3ec684...) -> 0 keys | 5462 slots | 1 slaves.
# 主节点有多少 Key
[OK] 0 keys in 3 masters.
# 每个槽的平均分配情况
0.00 keys per slot on average.
# 集群状态检查操作由 192.168.10.101:6371 节点执行
>>> Performing Cluster Check (using node 192.168.10.101:6371)
# 主节点信息以及附加的从节点个数
M: a1cd39d24bd2c9456026d592f0fac8728cea0e29 192.168.10.101:6371
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 4568a2560a688898a5d2337bce3a288f12355ae8 192.168.10.103:6375
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
# 从节点信息以及复制的主节点 ID
S: 78559b214c41f5909a5c6a0eecb9f01ee9efba9d 192.168.10.101:6372
slots: (0 slots) slave
replicates 4568a2560a688898a5d2337bce3a288f12355ae8
S: 3404010f04dff5109ddafaee2fe1f4abe1bc8292 192.168.10.103:6376
slots: (0 slots) slave
replicates 4f3ec6842325815a21f665691c8ac7b84235b306
M: 4f3ec6842325815a21f665691c8ac7b84235b306 192.168.10.102:6373
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 9cb940409435c06d2eb0628ed342abd9378d9f6b 192.168.10.102:6374
slots: (0 slots) slave
replicates a1cd39d24bd2c9456026d592f0fac8728cea0e29
# 所有节点都同意槽的配置情况
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
# 所有 16384 个槽都包括在内
[OK] All 16384 slots covered.
主节点日志
tail -f -n 1000 /usr/local/redis/cluster/log/redis-6371.log
1178:C # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1178:C # Redis version=6.0.9, bits=64, commit=00000000, modified=0, pid=1178,just started
1178:C # Configuration loaded
1178:M * Increased maximum number of open files to 10032 (it wasoriginally set to 1024).
# 未找到集群环境配置,当前节点 ID 为 a1cd39d24bd2c9456026d592f0fac8728cea0e29
1178:M * No cluster configuration found, I'm a1cd39d24bd2c9456026d592f0fac8728cea0e29
# 集群模式启动,端口为 6371
1178:M * Running mode=cluster, port=6371.
# 以下警告是关于 Linux 服务器的内存等相关问题,由于是虚拟机环境导致这可忽略
1178:M # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
# 服务器初始化
1178:M # Server initialized
1178:M # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.
1178:M # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo madvise> /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled (set to 'madvise' or 'never').
# 准备就绪,接受客户端连接
1178:M * Ready to accept connections
# 配置中写入纪元时间
1178:M # configEpoch set to 1 via CLUSTER SET-CONFIG-EPOCH
# 192.168.10.102:6374 从节点发起 SYNC 请求
1178:M * Replica 192.168.10.102:6374 asks for synchronization
# 拒绝部分重同步
1178:M * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'c5c1eab8eeba0ec77023aba4d375c600648bde8c', my replication IDs are '10d98a2bae9316fc6a3c385ba85f1188826e1a84' and 0000000000000000000000000000000000000000')
# 创建 repl_backlog ⽂件及⽣成 master_replid
1178:M * Replication backlog created, my new replication IDs are
'f1eb26435119a6c47c9b9abda86d6067d9110c04' and '0000000000000000000000000000000000000000'
# 通过 BGSAVE 指令将数据写入磁盘(RBD操作)
1178:M * Starting BGSAVE for SYNC with target: disk
# 开启一个子守护进程执行写入
1178:M * Background saving started by pid 1195
# 数据已写入磁盘
1195:C * DB saved on disk
# 有 4MB 数据已写入磁盘
1195:C * RDB: 4 MB of memory used by copy-on-write
# 保存结束
1178:M * Background saving terminated with success
# 从节点同步数据结束
1178:M * Synchronization with replica 192.168.10.102:6374 succeeded
# 集群环境状态 OK
1178:M # Cluster state changed: ok
从节点日志
tail -f -n 1000 /usr/local/redis/cluster/log/redis-6374.log
1187:C # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1187:C # Redis version=6.0.9, bits=64, commit=00000000, modified=0,pid=1187, just started
1187:C # Configuration loaded
1187:M * Increased maximum number of open files to 10032 (it wasge/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled (set to 'madvise' or 'never').
# 准备就绪,接受客户端连接
1187:M * Ready to accept connections
# 配置中写入纪元时间
1187:M # configEpoch set to 4 via CLUSTER SET-CONFIG-EPOCH
# 变为副本前的准备工作
1187:S * Before turning into a replica, using my own master parameters to synthesize a cached master: I may be able to synchronizewith the new master with just a partial transfer.
# 集群环境状态 OK
1187:S # Cluster state changed: ok
# 连接主节点 192.168.10.101:6371
1187:S * Connecting to MASTER 192.168.10.101:6371
# 主从同步开始
1187:S * MASTER <-> REPLICA sync started
# 触发 SYNC 的非阻塞连接事件
1187:S * Non blocking connect for SYNC fired the event.
# 主节点回复:PING,同步可以继续
1187:S * Master replied to PING, replication can continue...
# 尝试部分重同步(主节点日志中可以看到已被拒绝)
1187:S * Trying a partial resynchronization (request c5c1eab8eeba0ec77023aba4d375c600648bde8c:1).
# 全量复制主节点
1187:S * Full resync from master: f1eb26435119a6c47c9b9abda86d6067d9110c04:0
# 抛弃之前缓存的主节点状态
1187:S * Discarding previously cached master state.
# 主从复制:从主节点接收 175 个字节存储到磁盘
1187:S * MASTER <-> REPLICA sync: receiving 175 bytes from master to disk
# 主从复制:刷新旧数据
1187:S * MASTER <-> REPLICA sync: Flushing old data
# 主从复制:将数据加载到内存
1187:S * MASTER <-> REPLICA sync: Loading DB in memory
# 加载 RDB
1187:S * Loading RDB produced by version 6.0.9
1187:S * RDB age 0 seconds
1187:S * RDB memory usage when created 2.52 Mb
# 主从复制:顺利完成
1187:S * MASTER <-> REPLICA sync: Finished with success
# 后台开启进程执行 AOF 写入
1187:S * Background append only file rewriting started by pid 1194
1187:S * AOF rewrite child asks to stop sending diffs.
1194:C * Parent agreed to stop sending diffs. Finalizing AOF...
1194:C * Concatenating 0.00 MB of AOF diff received from parent.
1194:C * SYNC append only file rewrite performed
# 4 MB数据被写入 AOF 文件
1194:C * AOF rewrite: 4 MB of memory used by copy-on-write
# 后台 AOF 进程成功终止
1187:S * Background AOF rewrite terminated with success
1187:S * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
# 后台 AOF 重写顺利完成
1187:S * Background AOF rewrite finished successfully
查看集群信息
随便在哪个机器上运行以下命令。
# 连接至集群某个节点
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376
# 查看集群信息
192.168.10.103:6376> cluster info
# 集群状态
cluster_state:ok
# 集群槽分配总数
cluster_slots_assigned:16384
# 集群槽成功分配总数
cluster_slots_ok:16384
# 集群槽可能失效总数
cluster_slots_pfail:0
# 集群槽已经失效总数
cluster_slots_fail:0
# 集群中 Redis 节点数量
cluster_known_nodes:6
# 集群中设置的分片个数 3 主 3 从
cluster_size:3
# 集群中的currentEpoch总是一致的,currentEpoch越高,代表节点的配置或者操作越新
# 集群中最大的那个 node 的 epoch
cluster_current_epoch:6
# 当前节点的 config epoch,每个主节点都不同,一直递增, 其表示某节点最后一次变成主节点或获取新 slot 所有权的逻辑时间
cluster_my_epoch:3
cluster_stats_messages_ping_sent:71
cluster_stats_messages_pong_sent:76
cluster_stats_messages_meet_sent:1
cluster_stats_messages_sent:150
cluster_stats_messages_ping_received:76
cluster_stats_messages_pong_received:72
cluster_stats_messages_received:150
查看节点信息
随便在哪个机器上运⾏以下命令。
1 # 连接至集群某个节点
2 /usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376
# 查看集群结点信息,该信息也保存在 nodes-*.conf 配置⽂件中
192.168.10.103:6376> cluster nodes
# 节点ID | IP:PORT | 节点的⻆色(master,slave,myself)以及状态(pfail,fail),如果节点是一个从节点的话,那么跟在其之后的将是主节点的ID | 集群最近一次向节点发送 PING 命令之后,过了多长时间还没接到回复 | 节点最近一次返回 PONG 回复的时间 | 节点的配置纪元(config epoch) | 本节点的⽹络连接情况 | 主节点目前包含的槽
4f3ec6842325815a21f665691c8ac7b84235b306 192.168.10.102:6373@16373 master - 0 1606821938050 3 connected 5461-10922
3404010f04dff5109ddafaee2fe1f4abe1bc8292 192.168.10.103:6376@16376 myself,slave 4f3ec6842325815a21f665691c8ac7b84235b306 0 1606821935000 3 connected
9cb940409435c06d2eb0628ed342abd9378d9f6b 192.168.10.102:6374@16374 slave a1cd39d24bd2c9456026d592f0fac8728cea0e29 0 1606821935000 1 connected
78559b214c41f5909a5c6a0eecb9f01ee9efba9d 192.168.10.101:6372@16372 slave 4568a2560a688898a5d2337bce3a288f12355ae8 0 1606821936033 5 connected
4568a2560a688898a5d2337bce3a288f12355ae8 192.168.10.103:6375@16375 master - 0 1606821936000 5 connected 10923-16383
a1cd39d24bd2c9456026d592f0fac8728cea0e29 192.168.10.101:6371@16371 master - 0 1606821937042 1 connected 0-5460
集群环境测试
SET/GET
在 6376 节点中执行写入和读取,命令如下:
/usr/local/redis/bin/redis-cli -c -a 123456 -h 192.168.10.103 -p 6376
192.168.10.101:6371> set username zhangsan
-> Redirected to slot [14315] located at 192.168.10.103:6375
OK
192.168.10.103:6375> set age 18
-> Redirected to slot [741] located at 192.168.10.101:6371
OK
192.168.10.101:6371> set address sh
OK
192.168.10.101:6371> get username
-> Redirected to slot [14315] located at 192.168.10.103:6375
"zhangsan"
192.168.10.103:6375> get address
-> Redirected to slot [3680] located at 192.168.10.101:6371
"sh"
192.168.10.101:6371> get age
"18"
通过以上操作我们得知 username 键的存储被分配到了 6375 节点,如果直接连接 6375 节点并获取该值 会怎么样?没错,不需要重定向节点,因为数据就在该节点,所以直接读取返回。
从节点只读模式
通过上面的例子我们发现 Slave 从节点无论是读还是写命令都会转发到主节点上去执行,这样的话从节点 相当于只起到一个备份容灾的作用,读写的压力都在主节点上。
如果希望从节点执行读命令直接返回不需要转发至主节点,在从节点中执行 READONLY 即可。
注意:如果获取的Key不在从节点复制的主节点中那么则无法直接返回还是会进行转发
比如:set abc 111 被写入 192.168.10.102:6373 对应的从节点是 192.168.10.103:6376,在从节点中执行 READONLY 以后 get abc 不会转发直接返回。但是如果执行 get username 还是会进行转发,因为 username 这个 key 在 192.168.10.103:6375 中,而它的从节点是 192.168.10.101:6372。
客户端连接
随便哪个节点,看看可否通过外部访问 Redis Cluster 集群。

性能测试
redis-benchmark 命令
语法
redis-benchmark 是一个测试 Redis 性能的工具,Redis 性能测试是通过同时执行多个命令实现的。
redis-benchmark 【option 】【option value】
参数

单机测试
# 随机 set/get 1000000 条命令,在 1000 并发下执⾏
bin/redis-benchmark -a 123456 -h 192.168.10.101 -p 6379 -t set,get -r 1000000 -n 1000000 -c 1000
结果分析
====== SET ======
# 1000000 次 SET 请求在 16.27 秒内完成
1000000 requests completed in 16.27 seconds
# 1000 并发
1000 parallel clients
# 每个操作数据量是 3 个字节
3 bytes payload
# 连接方式 keep alive 长连接
keep alive: 1
# Redis 是否开启了 RBD 和 AOF
host configuration "save":
host configuration "appendonly": yes
multi-thread: no
0.00% <= 4 milliseconds
0.00% <= 5 milliseconds
0.01% <= 6 milliseconds # 0.01% 的命令执⾏时间⼩于 6 毫秒
1.04% <= 7 milliseconds
.
.
.
100.00% <= 351 milliseconds
100.00% <= 373 milliseconds
100.00% <= 395 milliseconds
100.00% <= 395 milliseconds
61474.15 requests per second # Redis 每秒可以处理 61474.15 次 SET请求
====== GET ======
# 1000000 次 GET 请求在 14.91 秒内完成
1000000 requests completed in 14.43 seconds
# 1000 并发
1000 parallel clients
# 每个操作数据量是 3 个字节
3 bytes payload
# 连接方式 keep alive 长连接
keep alive: 1
# Redis 是否开启了 RBD 和 AOF
host configuration "save":
host configuration "appendonly": yes
multi-thread: no
0.00% <= 5 milliseconds
0.16% <= 6 milliseconds # 0.16% 的命令执时时间大于 6 毫秒
7.73% <= 7 milliseconds
19.99% <= 8 milliseconds
.
.
.
99.98% <= 17 milliseconds
99.99% <= 18 milliseconds
100.00% <= 18 milliseconds
69319.29 requests per second # Redis 每秒可以处理 69319.29 次 GET请求
集群测试
# 随机 set/get 1000000 条命令,在 1000 并发下执⾏
bin/redis-benchmark -a 123456 -h 192.168.10.101 -p 6371 -t set,get -r 1000000 -n 1000000 -c 1000
结果分析
====== SET ======
# 1000000 次 SET 请求在 16.61 秒内完成
1000000 requests completed in 16.61 seconds
# 1000 并发
1000 parallel clients
# 每个操作数据量是 3 个字节
3 bytes payload
# 连接方式 keep alive 长连接
keep alive: 1
# Redis 是否开启了 RBD 和 AOF
host configuration "save":
host configuration "appendonly": yes
multi-thread: no
0.00% <= 5 milliseconds
0.01% <= 6 milliseconds # 0.01% 的命令执行时间大于 6 毫秒
.
.
.
99.99% <= 52 milliseconds
100.00% <= 53 milliseconds
100.00% <= 53 milliseconds
60204.70 requests per second # Redis 每秒可以处理 60204.70 次 SET请求
====== GET ======
# 1000000 次 GET 请求在 14.91 秒内完成
1000000 requests completed in 14.91 seconds
# 1000 并发
1000 parallel clients
# 每个操作数据量是 3 个字节
3 bytes payload
# 连接⽅式 keep alive ⻓连接
keep alive: 1
# Redis 是否开启了 RBD 和 AOF
host configuration "save":
host configuration "appendonly": yes
multi-thread: no
0.00% <= 4 milliseconds
0.00% <= 5 milliseconds
0.03% <= 6 milliseconds # 0.03% 的命令执⾏时间⼩于 6 毫秒
.
.
.
99.99% <= 33 milliseconds
100.00% <= 33 milliseconds
67055.59 requests per second # Redis 每秒可以处理 67055.59 次 GET请求
集群原理
单机、主从、哨兵的模式数据都是存储在一个节点上,其他节点进行数据的复制。而单个节点存储是存在上限的,集群模式就是把数据进行分片存储,当一个分片数据达到上限的时候,还可以分成多个分片。
哈希槽
Redis集群(Cluster)并没有选择一致性哈希,而是采用了哈希槽(SLOT)的这种概念。主要的原因是一致性哈希算法对于数据分布、节点位置的控制并不是很友好。
首先哈希槽其实是两个概念:
- 哈希算法。Redis Cluster的hash算法不是简单的hash(),而是crc16算法,一种校验算法。
- 槽位的概念,空间分配的规则。其实哈希槽的本质和一致性哈希算法非常相似,不同点就是对于哈希空间的定义。一致性哈希的空间是一个圆环,节点分布是基于圆环的,无法很好的控制数据分布。而 Redis Cluster的槽位空间是自定义分配的,类似于Windows盘分区的概念。这种分区是可以自定义大小,自定义位置的。
Redis Cluster包含了16384个哈希槽,每个Key通过计算后都会落在具体一个槽位上,而这个槽位是属于 哪个存储节点的,则由用户自己定义分配。例如机器硬盘小的,可以分配少一点槽位,硬盘大的可以分配 多一点。如果节点硬盘都差不多则可以平均分配。所以哈希槽这种概念很好地解决了一致性哈希的弊端。
另外在容错性和扩展性上,表象与一致性哈希一样,都是对受影响的数据进行转移。一哈希槽本质上是对槽位的转移,把故障节点负责的槽位转移到其他正常的节点上。扩展节点也是一样,把其他节点上的槽位 转移到新的节点上。
但一定要注意的是,对于槽位的转移和分派,Redis集群是不会自动进行的,而是需要人工配置的。所以 Redis集群的高可用是依赖于节点的主从复制与主从间的自动故障转移。
16384个slots(槽位)
Redis Cluster没有单机的那种16个数据库(0-15)的概念,而是分成了16384个slots(槽位),每个节点 负责其中一部分槽位,槽位的信息存储于每个节点中;
当客户端来连接集群时,它先得到一份集群的槽位 配置信息并将其缓存在客户端本地。这样当客户端要查找某个key时,可以直接定位到目标节点。同时因为 槽位的信息可能会存在客户端与服务器不一致的情况,还需要纠正机制来实现槽位信息的校验调整。
槽位定位算法
Redis Cluster默认会对key值使用CRC16算法进行hash得到一个整数值,然后用这个整数值对16384进行取模来得到具体槽位。每一个节点负责维护一部分槽以及槽所映射的键值数据。
槽位计算公式:HASH_SLOT = CRC16(key) mod 16384

键空间被分割为 16384 槽(slot),所有的主节点都负责 16384 个哈希槽中的一部分。当集群处于稳定 状态时,集群中没有在执行重配置(reconfiguration)操作,每个哈希槽都只由一个节点进行处理(不过主节点可以有一个或多个从节点,可以在网络断线或节点失效时替换掉主节点)。
Redis Cluster 提供了灵活的节点扩容和缩容方案。在不影响集群对外服务的情况下,可以为集群添加节 点进行扩容也可以下线部分节点进行缩容。可以说,槽是 Redis Cluster 管理数据的基本单位,集群伸缩 就是槽和数据在节点之间的移动。
简单的理解就是:扩容或缩容以后,槽需要重新分配,数据也需要重新迁移,但是服务不需要下线
假如,这⾥有 3 个节点的集群环境如下:
- 节点 A 哈希槽范围为 0 ~ 5500;
- 节点 B 哈希槽范围为 5501 ~ 11000;
- 节点 C 哈希槽范围为 11001 ~ 16383 ;
此时,我们如果要存储数据,按照 Redis Cluster 哈希槽的算法,假设结果是: CRC16(key) % 16384 = 6782。 那么就会把这个 key 的存储分配到 B 节点。此时连接 A、B、C 任何一个节点获取 key,都会 这样计算,最终通过 B 节点获取数据。
假如这时我们新增一个节点 D,Redis Cluster 会从各个节点中拿取一部分 Slot 到 D 上,比如会变成这 样:
- 节点 A 哈希槽范围为 1266 ~ 5500;
- 节点 B 哈希槽范围为 6827 ~ 11000;
- 节点 C 哈希槽范围为 12288 ~ 16383;
- 节点 D 哈希槽范围为 0 ~ 1265,5501 ~ 6826,11001 ~ 12287
这种特性允许在集群中轻松地添加和删除节点。同样的如果我想删除节点 D,只需要将节点 D 的哈希槽移 动到其他节点,当节点是空时,便可完全将它从集群中移除。
为什么是 16384 个槽
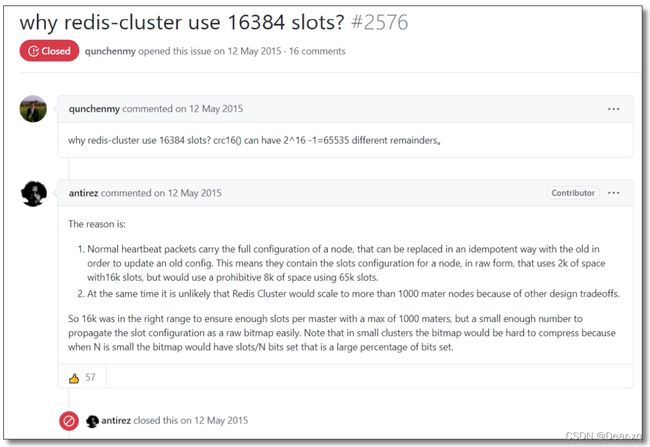
CRC16算法产生的 hash 值有 16bit,该算法可以产生 2^16 = 65536 个值。换句话说,值是分布在 0~65535 之间。那作者在做mod运算的时候,为什么不mod65536,而选择mod 16384?
对 于 这 个 问 题 , 作 者 给 出 了 解 答 。 原版回答如下图所示 , 对 应 的 链 接 地 址 为 :
https://github.com/redis/redis/issues/2576
如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
两个 Redis 节点之间进行通信的时候,会定期发送 PING/PONG 消息,交换数据信息。交换的数据信 息,由消息体和消息头组成。消息头包含了发送消息的节点的具体信息,每一个消息必须拥有完整的消息 头;消息体无外乎是一些节点标识啊,IP啊,端口号啊,发送时间啊。完整的消息格式定义 clusterMsg
在消息头中,最占空间的是 myslots[CLUSTER_SLOTS/8]。当槽位为 65536 时,这块的大小是: 65536 ÷ 8 = 8kb 因为每秒钟,Redis 节点需要发送一定数量的 PING 消息作为心跳包,如果槽位为 65536,这个 PING 消息的消息头太大了,浪费带宽。
Redis的集群主节点数量基本不可能超过1000个。
如上所述,集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。 因此 Redis 作者,不建议 Redis Cluster 节点数量超过 1000 个。那么,对于节点数在 1000 以内的 Redis Cluster 集群,16384 个槽位够用了。没有必要拓展到 65536个。
槽位越小,节点少的情况下,压缩率高。
Redis 主节点的配置信息中,它所负责的哈希槽是通过一张 bitmap 的形式来保存的,在传输过程中,会 对 bitmap 进行压缩,但是如果 bitmap 的填充率 slots / N 很大的话(N表示节点数),bitmap 的压缩率 就很低。如果节点数很少,而哈希槽数量很多的话,bitmap 的压缩率也会很低。而 16384 ÷ 8 = 2kb。 (文件压缩率指的是,文件压缩前后的大小比。)
综上所述,作者决定取 16384 个槽,不多不少,刚刚好!