BAT 大厂 java 程序员面试必问:JVM+Spring+ 分布式 +tomcat+MyBatis
前言
就目前国内的面试模式来讲,在面试前积极的准备面试,复习整个 Java 知识体系将变得非常重要,可以很负责任的说一句,复习准备的是否充分,将直接影响你入职的成功率。但很多小伙伴却苦于没有合适的资料来回顾整个 Java 知识体系,或者有的小伙伴可能都不知道该从哪里开始复习。
面试:如果不准备充分的面试,完全是浪费时间,更是对自己的不负责。
Java 面试的重点:
数据结构与算法,JVM 内存结构、垃圾回收器、回收算法、GC、并发编程相关(多线程、线程池等)、NIO/BIO、性能优化、设计模式、Spring 框架:分布式相关:Redis 缓存、一致 Hash 算法、分布式存储、负载均衡等,微服务以及 Docker 容器等。
因为头条篇幅原因,不能给大家一个全面的解析,末尾小编会分享一个 Java 基础到架构面试文档,希望能帮助到正在努力的朋友。
JVM 解析
1、垃圾回收的优点和原理。并考虑 2 种回收机制。
Java 语言中-一个显著的特点就是引入了垃圾回收机制,使 C++程序员最头疼的内存管理的问题迎刃而解,它使得 Java 程序员在编写程序的时候不再需要考虑内存管理。由于有个垃圾回收机制,Java 中的对象不再有“作用域”的概念,只有对象的引用才有"作用域”。垃圾回收可以有效的防止内存泄露,有效的使用可以使用的内存。垃圾回收器通常是作为一个单独的低级别的线程运行,不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的对象进行清楚和回收,程序员不能实时的调用垃圾回收器对某个对象或所有对象进行垃圾回收。
2、什么是类加载器,类加载器有哪些?
实现通过类的权限定名获取该类的二进制字节流的代码块叫做类加载器。主要有一下四种类加载器:
-
启动类加载器(BootstrapClassL oader)用来加载 Java 核心类库,无法被 Java 程序直接引用。
-
扩展类加载器(extensions class loader):它用来加载 Java 的扩展库。Java 虚拟机的实现会提供一个扩展库目录。该类加载器在此目录里面查找并加载 Java 类。
-
系统类加载器(system class loader):它根据 Java 应用的类路径
-
(CL ASSPATH)来加载 Java 类。-般来说,Java 应用的类都是由它来完成加载的。可以通过 Classl oader.getSystemClassl _oader()来获取它。
-
用户自定义类加载器,通过继承 java.lang.ClassL oader 类的方式实现。
3、java 内存分配
-
寄存器:我们无法控制。
-
静态域:| static 定义的静态成员。
-
常量池:编译时被确定并保存在. class 文件中的(final) 常量值和-些文本修饰的符号引用(类和接口的全限定名,字段的名称和描述符,方法和名称和描述符)。
-
非 RAM 存储:硬盘等永久存储空间。
-
堆内存: new 创建的对象和数组,由 Java 虚拟机自动垃圾回收器管理,存取速度慢。
-
栈内存:基本类型的变量和对象的引用变量(堆内存空间的访问地址),速度快,可以共享,但是大小与生存期必须确定,缺乏灵活性。1.Java 堆的结构是什么样子的?什么是堆中的永久代(Perm Genspace) ?
JVM 的堆是运行时数据区,所有类的实例和数组都是在堆上分配内存。它在 JVM 启动的时候被创建。对象所占的堆内存是由自动内存管理系统也就是垃圾收集器回收。
堆内存是由存活和死亡的对象组成的。存活的对象是应用可以访问的,不会被垃圾回收。死亡的对象是应用不可访问尚且还没有被垃圾收集器回收掉的对象。-直到垃圾收集器把这些对象回收掉之前,他们会一直 占据堆内存空间。
更多解析

Spring 解析
1、怎样用注解的方式配置 Spring?Spring 在 2.5 版本以后开始支持用注解的方式来配置依赖注入。可以用注解的方式来替代 XML 方式的 bean 描述,可以将 bean 描述转移到组件类的内部,只需要在相关类上、方法上或者字段声明上使用注解即可。注解注入将会被容器在 XML 注入之前被处理,所以后者会覆盖掉前者对于同-个属性的处理结果。注解装配在 Spring 中是默认关闭的。所以需要在 Spring 文件中配置一下才能使用基于注解的装配模式。如果你想要在你的应用程序中使用关于注解的方法的话,请参考如下的配置。
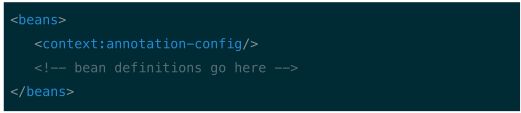
在
-
@Required:该注解应用于设值方法。
-
@Autowired:该注解应用于有值设值方法、非设值方法、构造方法和变量。
-
@Qulfier:该注解和 @Autowired 注解搭配使用,用于消除特定 bean 自动装配的歧义。
-
JSR. 250 Annotations:Spring 支持基于 JSR-250 注解的以下注解,@Resource、@PostConstruct 和 @PreDestroy。
更多解析

分布式解析
1、四种类型的 znode
1、| PERSISTENT- 持久化目录节点
客户端与 zookeeper 断开连接后,该节点依旧存在
2、| PERSISTENT SEQUENTIAL-持久化顺序编号目录节点
客户端与 zookeeper 断开连接后,该节点依旧存在,只是 Zookeeper 给该节点名称进行顺序编号
3、1 EPHEMERAL- 临时目录节点
客户端与 zookeeper 断开连接后,该节点被删除
4、EPHEMERAL SEQUENTIAL-临时顺序编号目录节点.
客户端与 zookeeper 断开连接后,该节点被删除,只是 Zookeeper 给该节点名称进行顺序编号
2、获取分布式流程
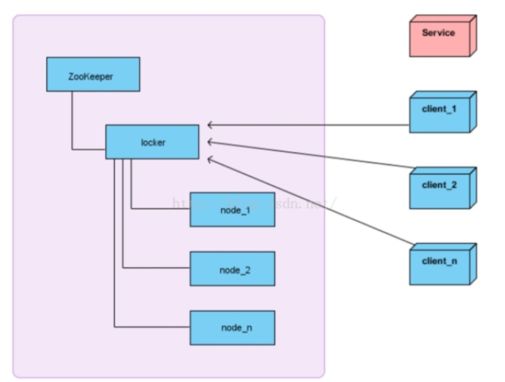
在获取分布式锁的时候在 locker 节点下创建临时顺序节点,释放锁的时候删除该临时节点。客户端调用 createNode 方法在 locker 下创建临时顺序节点,
然后调用 gethildren("locker")来获取 locker 下面的所有子节点,注意此时不用设置任何 Watcher。客户端获取到所有的子节点 path 之后,如果发现自己创建的节点在所有创建的子节点序号最小,那么就认为该客户端获取到了锁。如果发现自己创建的节点并非 locker 所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,然后对其调用 exist()方法,同时对其注册事件监听器。之后,让这个被关注的节点删除,则客户端的 Watcher 会收到相应通知,此时再次判断自己创建的节点是否是 locker 子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一一个节点并注册监听。当前这个过程中还需要许多的逻辑判断。

更多 解析

解析 tomcat
文章资料都整理在一个文档里面了,近 500 道面试题,资料已整理成文档,需要获取的小伙伴可以直接转发+关注后私信(学习)即可获取哦
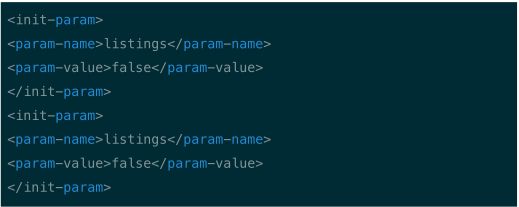
1、tomcat 中如何禁止列目录下的文件在{tomcat_ home}/ conf/web. xml 中,把 listings 参 数设置成 false 即可,
如下:
2、Tomcat 有几种部署方式 tomcat 中四种部署项目方法
第一种方法:在 tomcat 中的 conf 目录中,在 server. xml 中的,
![]()

至于 Context 节点属性,可详细见相关文档。第二种方法:将 web 项目文件件拷贝到 webapps 目录中。
第三种方法:很灵活,在 conf 目录中,新建 Catalina (注意大小写)\| locathost 目录,在该目录中新建一一个 xml 文件, 名字可以随意取,只要和当前文件中的文件名不重复就行了,该 xml 文件的内容为:
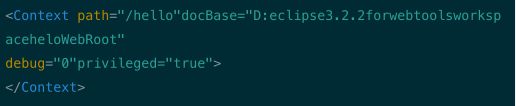
第 3 个方法有个优点,可以定义别名。服务器端运行的项目名称为 path,外部访问的 URL 则使用 XML 的文件名。这个方法很方便的隐藏了项目的名称,对一些项目名称被固定不能更换,但外部访问时又想换个路径,非常有效。
第 2、3 还有优点,可以定义一些个性配置,如数据源的配置等。
第四种办法: 可以用 tomcat 在线后台管理器,-般 tomcat 都打开了,直接上传 war 就可以
更多解析
MyBatis 解析
1、Mybatis 是如何进行分页的?分页插件的原理是什么?
-
Mybatis 使用 RowBounds 对象进行分页,也可以直接编写 sql 现分页,也可以使用 Mybatis 的分页插件。
-
分页插件的原理:实现 Mybatis 提供的接口,实现自定义插件,在插件的拦截方法内拦截待执行的 sql,然后重写 sql。举例:
![]()
拦截 sql 后重写为;
![]()
2、MyBatis 的好处是什么?
-
MyBatis 把 sql 语句从 Java 源程序中独立出来,放在单独的 XML 文件中编写,给程序的维护带来了很大便利。
-
MyBatis 封装了底层 JDBC API 的调用细节,并能自动将结果集转换成 Java Bean 对象,大大简化了 Java 数据库编程的重复工作。
-
因为 MyBatis 需要程序员自己去编写 sql 语句,程序员可以结合数据库自身的特点灵活控制 sql 语句,因此能够实现比 Hibernate 等全自动 orm 框架更高的查询效率,能够完成复杂查询。
更多解析
最后
资料已整理成文档,需要获取的小伙伴可以直接转发+关注后私信(学习)即可获取哦、这个 500 面试题的 PDF 资料哟!
还有更多资料包含 Spring,MyBatis,Netty 源码分析,高并发、高性能、分布式、微服务架构的原理,JVM 性能优化这些成为架构师必备的知识体系。相信对于已经工作和遇到技术瓶颈的码友,在这里会有你需要的内容。