代码拿走即用!Python推送内容到公众号实现自动化
Python推送内容到公众号自动化,代码拿走即用!
序言
作为一名普通的公众号运营者,撰写文章、排版、发表等过程都是比较耗时间的。
其实很多人不知道的是,微信公众号平台为创作者开通了很多的接口,这些接口如果加以利用,可大大减少创作者上传素材、发表等时间。
甚至如果打通“某些接口”的话,直接可实现一键转载别人的文章、自动添加素材等骚操作。
这个时候对于转载文章,你可能就只需要检查、更改下排版等,就可以直接发表。今天,我们就实现一个添加素材到公众后后台的自动化案例。
如果你是python爱好者,这个案例可用来练手;如果你是公司或个人新媒体运营人员,这样做能减少你很多工作;再一个,如果是互联网从业者,复制粘贴(c/v)才是真谛,哈哈都懂吧。
源码已整理到好,需要可在我的公号“Python和数据分析”后台回复【微信】或添加作者获取。
自动化添加素材到公众号
1.介绍及效果
功能介绍:使用Python获取天行数据(一个网站)特定接口的素材,自动化将文案素材上传到自己的公众号中。
效果如下:
实现思路:
准备所要上传到草稿箱的文本(我是在天行数据上拉去的段子素材)–> 获取access_token(其作用参考微信开放文档 (qq.com)) -->先用测试工具上传一张图片到公号素材库(必须一张图用于文章封面)–> 调用公众号上传草稿的接口用post请求方式上传草稿
2.代码实现
2.1天行数据拉取段子素材
这里可以换成你想拉去的其他接口数据,或者你自己写的文字用于测试都行。
import requests
# 此模块用于在天行数据上拉取在段子
# 创建一个爬虫类
# 首先,实例为蜘蛛,,属性有名字,每一只蜘蛛会建立连接,解析数据,保存数据
class Spider(object):
def __init__(self, name, url):
self.name = name
self.url = url
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
# 配置请求,返回json数据
def request(self):
resp = requests.get(
url=self.url,
headers=self.headers,
params={
'key': '注册天行数据,获取一个key到这里'
}
)
resp.encoding = 'utf-8'
# 拿到标题
# content_json = resp.json()['newslist'][0]['title']
# 拿到内容
# content_json = resp.json()['newslist'][0]['content']
content_json = resp.json()
return content_json
# 保存数据
def savetext(self, content, filename):
f = open('data/' + filename, 'w')
f.write(content + '\n')
f.close()
return 1
def main():
url = 'http://api.tianapi.com/joke/index'
spider = Spider('笑话', url)
# 每天抓十条数据
contents = ''
# 输出文案
datajson = spider.request()
for i in range(10):
try:
# 标题
title = datajson['newslist'][i]['title']
print(title)
# 内容
content = datajson['newslist'][i]['content']
# 合并
merge = ''
merge = title + '\n' + content
contents += '\n'
contents += merge
except Exception as e:
print(e)
# 保存到文件,成功返回1
print(spider.savetext(contents, 'joke.txt'))
if __name__ == '__main__':
main()
2.2获取access_token
不知道access_token,请自行百度或参考微信开放文档 (qq.com),有不明白可关注公众号“Python和数据分析”,后台就可找到我哦!
import json
from urllib import parse, request
import time
## 此函数用于获取access_token,不知道有啥作用,参考微信公众号开发文档:https://developers.weixin.qq.com/doc/offiaccount/Basic_Information/Get_access_token.html
# // 获取token
def get_wxCode_token():
try:
appid = "你自己的appid"
secret = "你自己的secret"
textmod = {"grant_type": "client_credential",
"appid": appid,
"secret": secret
}
textmod = parse.urlencode(textmod)
header_dict = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'}
url = 'https://api.weixin.qq.com/cgi-bin/token'
req = request.Request(url='%s%s%s' % (url, '?', textmod), headers=header_dict)
res = request.urlopen(req)
res = res.read().decode(encoding='utf-8')
res = json.loads(res)
access_token = res["access_token"]
print('access_token:',(access_token,time.time()))
return (access_token,time.time())
except Exception as e:
print(e)
return False
if __name__ == '__main__':
# 注意,获取不到access_token,很可能你没有在公众号上添加 你的ip地址 为白名单
get_wxCode_token()
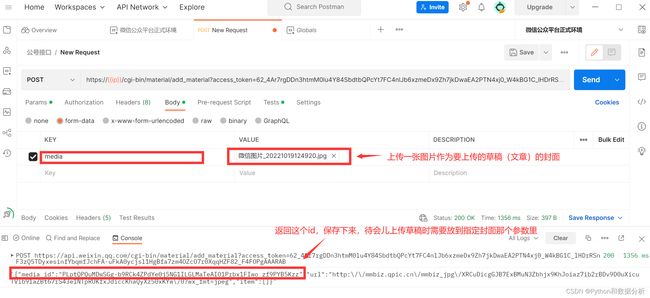
2.3调用公众号接口上传素材
先用测试工具(这个工具是啥应该不需要我介绍了吧,好吧,需要的后台回复【测试工具】,获取安装包)使用post请求方式上传一张图片到公众号,得到media_id。
具体操作方式参考:微信开放文档 (qq.com)
2.4使用主函数调用所有函数
import requests
import datetime
import time
import json
import chardet
from getToken import get_wxCode_token
from joke import Spider
# 此模块作用:将文本内容上传到公众号草稿箱,可参考https://developers.weixin.qq.com/doc/offiaccount/Draft_Box/Add_draft.html
# 全流程:
# 步骤:1.获取access_token
# 2.从天行数据拉去想要的文本数据并解析整理
# 3.调用上传草稿的接口使用post方式上传文本数据
# 步骤:
# 1.拿到token,用一个变量来记录获取token时的时间戳,每次执行时先检查时间达到2个小时的才去获取token
token = ''
getTokenTime = 0
class Caogao(object):
def __init__(self,name,data,access_token,getTokenTime):
self.name = name
self.data = data
self.access_token = access_token
self.getTokenTime = getTokenTime
# 先判断是否有token,如果没有,获取token,同时记录时间,获取后开始干活儿,
# 如果有,判断是否失效,失效则重新获取,
# 判断token是否过期
def which_token_abate(self):
# 获取token时间戳
# global getTokenTime
# 获取当前时间戳
nowtime_stamp = time.time()
# 用当前时间戳减去getTokenTime,大于两个小时就判定失效
hour2 = 2 * 60 * 60 * 1000
if nowtime_stamp - self.getTokenTime > hour2:
return True
return False
# 判断是否有token
def have_token(self):
if self.access_token != '':
return True
return False
# 发送数据,data为要发的内容
def send_requests(self):
# 2.导入requests包,发送post
try:
header_dict = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'Content-Type': 'application/json; charset=utf-8'
}
response_psot = requests.post(
url='https://api.weixin.qq.com/cgi-bin/draft/add?',
params={
'access_token': self.access_token},
headers=header_dict,
data=bytes(json.dumps(self.data, ensure_ascii=False).encode('utf-8'))
# data=self.data,
)
print(response_psot)
except Exception as e:
print(e)
def main():
# 1.抓取笑话数据
url = 'http://api.tianapi.com/joke/index'
spider = Spider('笑话', url)
# 每天抓十条数据
contents = ''
# 建立请求
datajson = spider.request()
# 解析数据
for i in range(11):
try:
# 标题
title = datajson['newslist'][i]['title']
print(title)
# 内容
content = datajson['newslist'][i]['content']
# 合并
merge = ''
merge = title + '\n' + content
contents += '\n'
contents += merge
except Exception as e:
print(e)
# 保存到文件,成功返回1
# print(spider.savetext(contents, 'joke.txt'))
# 2.推送到公众号
# 要传的草稿
data = {
"articles": [
{
"title": "关注【Python和数据分析】公众号",
"author": "翔宇",
"content": contents,
"thumb_media_id": "这里需要用接口工具上传一张图片到公众号素材里,返回的mediaid放到这里,不懂请关注公众号“Python和数据分析“问作者"
}
]
}
token_and_time = get_wxCode_token()
access_token = token_and_time[0]
getTokenTime = token_and_time[1]
# 创建草稿实例
caogao = Caogao('caogao',data,access_token,getTokenTime)
caogao.send_requests()
if __name__ == '__main__':
for _ in range(10):
main()
3.总结
总的来说,这个自动化工具还是很不错的,至少省掉了我很多复制粘贴的工作。
直接从天行数据拉去段子后,我稍微排版一下就可以发表文章了。下面这种文章的素材就是自动推送到公众号的。大家可以点进去帮我看看效果或提意见。
另外,对于这个程序,如果你知道post、get请求方式,会使用Python拉取数据和post推送数据,实现这样一个自动工具还是很简单的,为了不让大家重复造轮子,使用我的代码进行改动一下就可以了。
好了,今天就分享到这里,关注下方公众号后台回复【微信】即可获取源代码哦!或者有问题可以后台联系作者哦。