Flink快速了解
初识 Flink
- 一.初识 Flink
-
- 1.1初识
- 1.2特性
- 1.3案例
- 1.4流处理和批处理
- 1.5分层API
- 二.Flink 快速上手
-
- 2.1.所需依赖(Maven)
- 2.2.案例
- 三 DataStream API
-
- 3.1初识
- 3.2执行流程
- 3.3从不同的数据源读取数据
- 3.4 转换算子(Transformation)
-
- 1. 映射(map)
- 2. 过滤(filter)
- 3. 扁平映射(flatMap)
- 3.5 聚合算子(Aggregation)
-
- 1. 按键分区(keyBy)
- 2. 简单聚合
- 3. 归约聚合(reduce)
- 3.6富函数
- 3.7输出算子(Sink)
-
- 1.输出到文件
- 2. 输出到 Kafka
- 3.输出到 Redis
- 4.输出到 MySQL(JDBC)
- 四.Table API 和 SQL
-
- 4.1 一个简单示例
- 4.2创建表环境
- 4.3 创建表
-
- 1. **连接器表(Connector Tables)**
- 2. **虚拟表(Virtual Tables)**
- 4.4. **表的查询**
-
- 1. 执行 SQL 进行查询
- 2. 调用 Table API 进行查询
- 3. 两种 API 的结合使用
- 4.5.输出表
- 4.6.表和流的转换
-
- 1. 将表(Table)转换成流(DataStream)
- 2. 将流(DataStream)转换成表(Table)
- 3. 支持的数据类型
一.初识 Flink
1.1初识
Flink 是 Apache 基金会旗下的一个开源大数据处理框架.
Flink 的两个特点:速度快、可扩展性强.
Flink 是一个大数据流处理引擎.
1.2特性
高吞吐和低延迟。每秒处理数百万个事件,毫秒级延迟。
结果的准确性。Flink 提供了事件时间(event-time)和处理时间(processing-time)语义。对于乱序事件流,事件时间语义仍然能提供一致且准确的结果。
精确一次(exactly-once)的状态一致性保证。
可以连接到最常用的存储系统,如 Apache Kafka、Apache Cassandra、Elasticsearch、JDBC、Kinesis 和(分布式)文件系统,如 HDFS 和 S3。
高可用。本身高可用的设置,加上与 K8s,YARN 和 Mesos 的紧密集成,再加上从故障中快速恢复和动态扩展任务的能力,Flink 能做到以极少的停机时间 7×24 全天候运行。
能够更新应用程序代码并将作业(jobs)迁移到不同的 Flink 集群,而不会丢失应用程序的状态
1.3案例
1.网站获得的点击数据可能是连续且不均匀的,还可能在同一时间大量产生,这是典型的数
据流。如果我们希望把它们全部收集起来,再去分析处理,就会面临很多问题:首先,我们需
要很大的空间来存储数据;其次,收集数据的过程耗去了大量时间,统计分析结果的实时性就
大大降低了;另外,分布式处理无法保证数据的顺序,如果我们只以数据进入系统的时间为准,
可能导致最终结果计算错误。
2.用户的交易行为是连续大量发生的,银行面对的是海量的流式数据。
我们需要的是直接处理数据流,而 Flink 就可以做到这一点。
1.4流处理和批处理
流处理:无界 来一条处理一条
批处理: 有界 同时处理一批
有状态的流处理:接到请求先回复收到,但这样没有实际操作数据,可以把需要的额外数据保存成一个“状态”,然后针对这条数据进行处理,并且更新状态。
1.5分层API
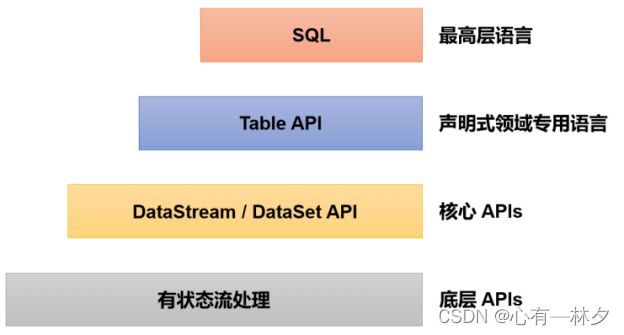
最底层级的抽象仅仅提供了有状态流,它将处理函数(Process Function)嵌入到了DataStream API 中。
Table API 是以表为中心的声明式编程,其中表在表达流数据时会动态变化。Table API 遵循关系模型:表有二维数据结构(schema)(类似于关系数据库中的表),同时 API 提供可比较的操作,例如 select、join、group-by、aggregate 等
可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与DataStream 以及 DataSet 混合使用
SQL 查询可以直接在 Table API 定义的表上执行。
二.Flink 快速上手
2.1.所需依赖(Maven)
<properties>
<flink.version>1.13.0flink.version>
<scala.binary.version>2.12scala.binary.version>
<slf4j.version>1.7.30slf4j.version>
properties>
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-ml-uberartifactId>
<version>2.1.0version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-kafka_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.47version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-table-commonartifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-clients_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-apiartifactId>
<version>${slf4j.version}version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>${slf4j.version}version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-to-slf4jartifactId>
<version>2.14.0version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>3.8.1version>
<scope>testscope>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
<scope>compilescope>
dependency>
dependencies>
<repositories>
<repository>
<id>alimavenid>
<name>Maven Aliyun Mirrorname>
<url>http://maven.aliyun.com/nexus/content/repositories/central/url>
<releases>
<enabled>trueenabled>
releases>
<snapshots>
<enabled>falseenabled>
snapshots>
repository>
repositories>
配置日志管理
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
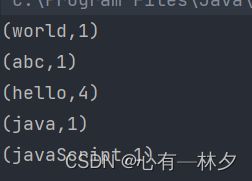
te1.txt
hello abc hello world
hello java
hello javaScript
2.2.案例
接着按照单词分组,统计每组数据的个数
package top.remained;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @description: TODO:批处理单词出现的次数
* @author: lx
* @date: 2023/3/9 14:12
* @param:
* @return:
**/
public class HelloWorld {
public static String fileName = "E:\\jk\\first\\flink\\src\\main\\resources\\te1.txt";
public static void main(String[] args) throws Exception {
// 1. 创建执行环境 // 也快创建远程环境
// LocalEnvironment env1 = new LocalEnvironment();
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件读取数据 按行读取(存储的元素就是每行的文本)
DataSource<String> lineDS = env.readTextFile(fileName);
// 3. 转换数据格式
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS
.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING,Types.LONG));
//当 Lambda 表达式 使用 Java 泛型的时候, 由于泛型擦除的存在, 需要显示的声明类型信息
// 4. 按照 word 进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG =
wordAndOne.groupBy(0);//group by(索引) 第几个字段 进行分组的key
// 5. 分组内聚合统计
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);//field 第几个字段 进行聚合统计的key
// 6. 打印结果
sum.print();
}
}
结果
三 DataStream API
3.1初识
由于新版本已经实现了流批一体,DataSet API 将被弃用,官方推荐统一使用 DataStream API 处理流数据和批数据。DataStream 在用法上有些类似于常规的 Java 集合,但又有所不同。我们在代码中往往并不关心集合中具体的数据,而只是用 API 定义出一连串的操作来处理它们;这就叫作数据流的“转换”(transformations)。
3.2执行流程
⚫ 获取执行环境(execution environment)
⚫ 读取数据源(source)
⚫ 定义基于数据的转换操作(transformations)
⚫ 定义计算结果的输出位置(sink)
⚫ 触发程序执行(execute)
// 获取当前执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 读取文本
DataStreamSource<String> ds = env.socketTextStream("121.41.90.173", 9092);
// 3. 转换数据格式
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = ds
.flatMap((String line, Collector<String> words) -> {
Arrays.stream(line.split(" ")).forEach(words::collect);
})
.returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne
.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS
.sum(1);
// 6. 打印
result.print();
// 7. 执行
env.execute();
3.3从不同的数据源读取数据
public static void main(String[] args) throws Exception {
// 1.执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 2.1从集合中读取数据 原理 把集合数据存储到内存当中 集合常做测试使用
ArrayList<Integer> integers = new ArrayList<>();
integers.add(1);
integers.add(2);
// 简单的集合类型(自定义实体也可以) 可以自动解析
DataStreamSource<Integer> stream1 = env.fromCollection(integers);
// 2.2从环境中去读取数据
// DataStreamSource stream2 = env.readTextFile("C:\\Users\\lx\\IdeaProjects\\flink-study\\flink");
// 2.3 从元素读取数据
// env.fromElements("1", "2", "3", "4", "5", "6");
// 2.4 从socket文本流读取数据
// env.socketTextStream(地址,端口);
// TODO:2.5从kafka中读取数据 不能直接读取 但是Flink 提供了一个通用数据源 的 addSource()方法
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "127.0.0.1:9092");
DataStreamSource<String> kafkaSource = env.addSource(new FlinkKafkaConsumer<String>("first", new SimpleStringSchema(), properties));
kafkaSource.print();
// 3.处理数据
// 4.输出
// stream1.print("stream1");
// stream1> 1
// stream1> 2
env.execute();
}
注:连接kafka时
⚫ 第一个参数 topic,定义了从哪些主题中读取数据。可以是一个 topic,也可以是 topic列表,还可以是匹配所有想要读取的 topic 的正则表达式。当从多个 topic 中读取数据时,Kafka 连接器将会处理所有 topic 的分区,将分区的数据放到一条流中去。
⚫ 第二个参数是一个 DeserializationSchema 或者 KeyedDeserializationSchema。Kafka 消息被存储为原始的字节数据,所以需要反序列化成 Java 或者 Scala 对象。上面代码中使用的 SimpleStringSchema,是一个内置的 DeserializationSchema,它只是将字节数组简单地反序列化成字符串。DeserializationSchema 和 KeyedDeserializationSchema 是公共接口,所以我们也可以自定义反序列化逻辑。
⚫ 第三个参数是一个 Properties 对象,设置了 Kafka 客户端的一些属性。
3.3 Flink 支持的数据类型
为了方便地处理数据,Flink 有自己一整套类型系统。Flink 使用“类型信息”(TypeInformation)来统一表示数据类型。TypeInformation 类是 Flink 中所有类型描述符的基类。它涵盖了类型的一些基本属性,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
Flink 对 POJO 类型的要求如下:
⚫ 类是公共的(public)和独立的(standalone,也就是说没有非静态的内部类);
⚫ 类有一个公共的无参构造方法;
⚫ 类中的所有字段是 public 且非 final 的;或者有一个公共的 getter 和 setter 方法,这些方法需要符合 Java bean 的命名规范。
类型提示(Type Hints)
由于 Java 中泛型擦除的存在,在某些特殊情况下(比如 Lambda 表达式中),自动提取的信息是不够精细的。
example
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
如果元组中的一个元素又有泛型,该怎么处理呢?
Flink 专门提供了 TypeHint 类,它可以捕获泛型的类型信息,并且一直记录下来,为运行时提供足够的信息。我们同样可以通过.returns()方法,明确地指定转换之后的 DataStream 里元素的类型。
returns(new TypeHint<Tuple2<Integer, SomeType>>(){})
3.4 转换算子(Transformation)
1. 映射(map)
简单来说,就是一个“一一映射”,消费一个元素就产出一个元素
public class MapTest {
// 并行数量以及环境,
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 读取数据
DataStreamSource<Event> source = env.fromElements(new Event("aa", "a",1000L), new Event("bb", "b",2000L));
// 数据处理
// 1.使用自定义类 ,返回想要的接口,
// SingleOutputStreamOperator map = source.map(new MyMapper());
// 2.使用匿名类实现MapFunction接口
// SingleOutputStreamOperator map = source.map(new MapFunction() {
// @Override
// public String map(Event event) throws Exception {
// return event.user;
// }
// });
// 使用lambda简化
source.map(s -> s.user).print();
// map.print();
env.execute();
}
// 第二个参数是返回值
public static class MyMapper implements MapFunction<Event, String> {
@Override
public String map(Event event) throws Exception {
return event.user;
}
}
}
2. 过滤(filter)
filter 转换操作,顾名思义是对数据流执行一个过滤,通过一个布尔条件表达式设置过滤条件,对于每一个流内元素进行判断,若为 true 则元素正常输出,若为 false 则元素被过滤掉。
public class FilterTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 读取数据
DataStreamSource<Event> source = env.fromElements(new Event("aa", "a",1000L), new Event("bb", "b",2000L));
// 如果是aa则输出
source.filter(s -> s.user.equals("bb")).print("lambda:");
env.execute();
}
}
3. 扁平映射(flatMap)
flatMap 操作又称为扁平映射,主要是将数据流中的整体(一般是集合类型)拆分成一个一个的个体使用。消费一个元素,可以产生 0 到多个元素。flatMap 可以认为是“扁平化”(flatten)和“映射”(map)两步操作的结合,也就是先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理。
flatMap 并没有直接定义返回值类型,而是通过一个“收集器”(Collector)来指定输出。希望输出结果时,只要调用收集器的.collect()方法就可以了;这个方法可以多次调用,也可以不调用。所以 flatMap 方法也可以实现 map 方法和 filter 方法的功能,当返回结果是 0 个的时候,就相当于对数据进行了过滤,当返回结果是 1 个的时候,相当于对数据进行了简单的转换操作。
public class FlatMapTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
// 读取数据
DataStreamSource<Event> source = env.fromElements(new Event("aa", "a",1000L), new Event("bb", "b",2000L));
source.flatMap(new MyFlatMapFunction()).print();
// TODO: 两个流没有顺序执行
source.flatMap((Event e,Collector<String> o) -> {
if (e.user.equals("aa") ) {
o.collect(e.url);
}else if (e.user .equals("bb")){
o.collect(e.timestamp.toString());
}
}).returns(new TypeHint<String>() {}).print();
env.execute();
}
public static class MyFlatMapFunction implements FlatMapFunction<Event, String> {
@Override
public void flatMap(Event value, Collector<String> out) throws Exception {
out.collect(value.user);
out.collect(value.url);
}
}
}
3.5 聚合算子(Aggregation)
计算的结果不仅依赖当前数据,还跟之前的数据有关。
1. 按键分区(keyBy)
对海量数据做聚合肯定要进行分区并行处理,这样才能提高效率。所以在 Flink 中,要做聚合,需要先进行分区;
聚合前必须要用到的一个算子。
keyBy 通过指定键(key)(计算 key 的哈希值),可以将一条流从逻辑上划分成不同的分区(partitions)(一个字符串写死就是一个分区)。这里所说的分区,其实就是并行处理的子任务,也就对应着任务槽(task slot)。
keyBy 得到的结果将不再是 DataStream,而是会将 DataStream 转换为KeyedStream。只有基于它才可以做后续的聚合操
作(比如 sum,reduce);
2. 简单聚合
⚫ sum():在输入流上,对指定的字段做叠加求和的操作。
⚫ min():在输入流上,对指定的字段求最小值。
⚫ max():在输入流上,对指定的字段求最大值。
⚫ minBy():与 min()类似,在输入流上针对指定字段求最小值。不同的是,min()只计
算指定字段的最小值,其他字段会保留最初第一个数据的值;而 minBy()则会返回包
含字段最小值的整条数据。
⚫ maxBy():与 max()类似,在输入流上针对指定字段求最大值。两者区别与min()/minBy()完全一致
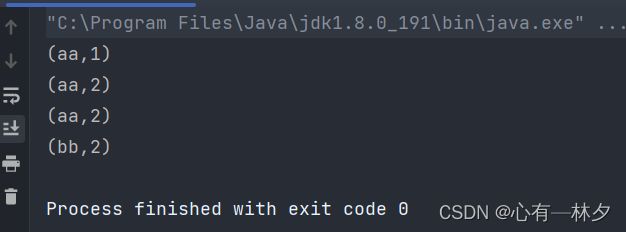
public class SimpleAggTest {
// 简单聚合
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
DataStreamSource<Event> stream = env.fromElements( new Event("aa", "b",100L),
new Event("aa", "a",1000L),
new Event("bb", "b",2000L),
new Event("bb", "b",1000L));
// 按照分键之后进行聚合 TODO 处理的是接收之前的
// getKey 进行分区 max 只把截取的字段输出其余的字段还是原来的 maxBy的话是全部字段都用最大值的字段
stream.keyBy(event -> event.user).max("timestamp").print();
env.execute();
}
public static class MyKeySelector implements KeySelector<Event, String> {
@Override
public String getKey(Event event) throws Exception {
return null;
}
}
}
3. 归约聚合(reduce)
它可以对已有的数据进行归约处理,把每一个新输入的数据和当前已经归约出来的值,再做一个聚合计算。
这个方法接收两个输入事件,经过转换处理之后输出一个相同类型的事件;所以,对于一组数据,我们可以先取两个进行合并,然后再将合并的结果看作一个数据、再跟后面的数据合并,最终会将它“简化”成唯一的一个数据,内部会维护一个初始值为空的累加器。
public class ReduceAggTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1);
DataStreamSource<Event> stream = env.fromElements( new Event("aa", "b",100L),
new Event("aa", "a",1000L),
new Event("bb", "b",2000L),
new Event("bb", "b",1000L));
// 统计网站访问量
SingleOutputStreamOperator<Tuple2<String, Long>> reduce = stream.map(new MapFunction<Event, Tuple2<String, Long>>() {
//Tuple2 二元数组
@Override
public Tuple2<String, Long> map(Event event) throws Exception {
return Tuple2.of(event.user, 1l);
}
}).keyBy(data -> data.f0).reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> t1) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + t1.f1);
}
});
// 固定一个字符串 分配到统一分区
reduce.keyBy(data -> "key").reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return value1.f1>value2.f1 ? value1 : value2;
}
}).print();
env.execute();
}
}
3.6富函数
富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
“富函数类”也是 DataStream API 提供的一个函数类的接口,所有的 Flink 函数类都有其Rich 版本。富函数类一般是以抽象类的形式出现的。
public class MyFlatMap extends RichFlatMapFunction<IN, OUT>> {
@Override
public void open(Configuration configuration) {
// 做一些初始化工作
// 例如建立一个和 MySQL 的连接
}
@Override
public void flatMap(IN in, Collector<OUT out) {
// 对数据库进行读写
}
@Override
public void close() {
// 清理工作,关闭和 MySQL 数据库的连接。
}
}
3.7输出算子(Sink)
为了避免这样的问题,Flink 的 DataStream API 专门提供了向外部写入数据的方法:
addSink。与 addSource 类似,addSink 方法对应着一个“Sink”算子,主要就是用来实现与外
部系统连接、并将数据提交写入的;Flink 程序中所有对外的输出操作,一般都是利用 Sink 算
子完成的。
1.输出到文件
Flink 为此专门提供了一个流式文件系统的连接器:StreamingFileSink,它继承自抽象类
RichSinkFunction,而且集成了 Flink 的检查点(checkpoint)机制,用来保证精确一次(exactly
once)的一致性语义。
public class SinkToFileTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(4);
DataStreamSource<Event> stream = env.fromElements( new Event("aa", "b",100L),
new Event("aa", "a",1000L),
new Event("bb", "b",2000L),
new Event("bb", "b",1000L));
StreamingFileSink<String> fileSink = StreamingFileSink
.<String>forRowFormat(new Path("./output"),
new SimpleStringEncoder<>("UTF-8"))
.withRollingPolicy( //滚动策略
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(15) // 15分钟
)
.withInactivityInterval(TimeUnit.MINUTES.toMillis(5 //隔多长时间没数据进行滚动
))
.withMaxPartSize (1024 * 1024 * 1024)
.build())
.build();
// 将 Event 转换成 String 写入文件
stream.map(Event::toString).addSink(fileSink);
env.execute();
}
}
2. 输出到 Kafka
Flink 官方为 Kafka 提供了 Source和 Sink 的连接器,我们可以用它方便地从 Kafka 读写数据。如果仅仅是支持读写,那还说明
不了 Kafka 和 Flink 关系的亲密;真正让它们密不可分的是,Flink 与 Kafka 的连接器提供了端到端的精确一次(exactly once)语义保证,这在实际项目中是最高级别的一致性保证。
public class SinkToKafka {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(4);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "121.41.90.173:9092");
DataStreamSource<String> streamSource = env.addSource(new FlinkKafkaConsumer<String>("first", new SimpleStringSchema(), properties));
// 对kafka数据进行切分 且 包装成event
streamSource.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] split = value.split(",");
return new Event(split[0].trim(),split[1].trim(),Long.parseLong(split[2].trim().replace("timestamp=1000}","1000"))).toString();
}
}).addSink(new FlinkKafkaProducer<String>("first", new SimpleStringSchema(), properties));
env.execute();
}
}
3.输出到 Redis
Flink 没有直接提供官方的 Redis 连接器,不过 Bahir 项目还是担任了合格的辅助角色,为我们提供了 Flink-Redis 的连接工具。但版本升级略显滞后,目前连接器版本为 1.0,支持的Scala 版本最新到 2.11。由于我们的测试不涉及到 Scala 的相关版本变化,所以并不影响使用。在实际项目应用中,应该以匹配的组件版本运行。
<dependency>
<groupId>org.apache.bahirgroupId>
<artifactId>flink-connector-redis_2.11artifactId>
<version>1.0version>
dependency>
4.输出到 MySQL(JDBC)
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.47version>
dependency>
package top.remained.sink;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import top.remained.Event;
/**
* @Author: lx
* @CreateTime: 2023-03-16 13:39
* @Description: TODO
*/
public class SinkToMysql {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Event> stream = env.fromElements(
new Event("Mary", "./home", 1000L),
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 3600L),
new Event("Bob", "./home", 3000L),
new Event("Bob", "./prod?id=1", 2300L),
new Event("Bob", "./prod?id=3", 3300L));
stream.addSink(
JdbcSink.sink(
"INSERT INTO student (name, id) VALUES (?, ?)",
(statement, r) -> {
statement.setString(1, r.user);
statement.setString(2, r.url);
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
new
JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://localhost:3308/test")
// 对于 MySQL 5.7,用"com.mysql.jdbc.Driver"
.withDriverName("com.mysql.jdbc.Driver")
.withUsername("root")
.withPassword("123456")
.build()
)
);
env.execute();
}
}
四.Table API 和 SQL
Flink 同样提供了对于“表”处理的支持,这就是更高层级的应用 API,在 Flink 中被称为Table API 和 SQL。Table API 顾名思义,就是基于“表”(Table)的一套 API,它是内嵌在 Java、Scala 等语言中的一种声明式领域特定语言(DSL),也就是专门为处理表而设计的;在此基础上,Flink 还基于 Apache Calcite 实现了对 SQL 的支持。
4.1 一个简单示例
package top.remained.table;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.junit.Test;
import top.remained.Event;
/**
* @Author: lx
* @CreateTime: 2023-03-16 14:42
* @Description: TODO
*/
public class SimpleTableExample {
public static void main(String[] args) throws Exception {
// 获取流执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=7", 105 * 1000L)
);
// 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表
Table eventTable = tableEnv.fromDataStream(eventStream);
// 用执行 SQL 的方式提取数据
Table visitTable = tableEnv.sqlQuery("select url, user from " + eventTable);
// 将表转换成数据流,打印输出
tableEnv.toDataStream(visitTable).print();
// 执行程序
env.execute();
}
// 程序基本架构如下:
@Test
public void test() throws Exception {
// 创建表环境
TableEnvironment tableEnv = StreamTableEnvironment.create(StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(4));
// 创建输入表,连接外部系统读取数据
tableEnv.executeSql("CREATE TEMPORARY TABLE inputTable ... WITH ( 'connector' = ... )");
// 注册一个表,连接到外部系统,用于输出
tableEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH ( 'connector' = ... )");
// 执行 SQL 对表进行查询转换,得到一个新的表
Table table1 = tableEnv.sqlQuery("SELECT ... FROM inputTable... ");
// 使用 Table API 对表进行查询转换,得到一个新的表
Table table2 = tableEnv.from("inputTable").select("...");
// 将得到的结果写入输出表
TableResult tableResult = table1.executeInsert("outputTable");
}
}
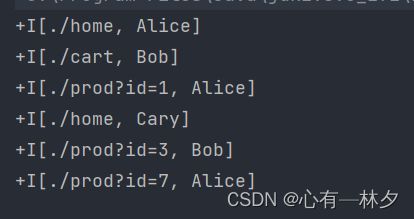
对于输出表的定义是完全一样的。可以发现,在创建表的过程中,其实并不区分“输入”还是“输出”,只需要将这个表“注册”进来、连接到外部系统就可以了;这里的 inputTable、outputTable 只是注册的表名,并不代表处理逻辑,可以随意更换。
4.2创建表环境
每个表和 SQL 的执行,都必须绑定在一个表环境(TableEnvironment)中。TableEnvironment是 Table API 中提供的基本接口类,可以通过调用静态的 create()方法来创建一个表环境实例。方法需要传入一个环境的配置参数 EnvironmentSettings,它可以指定当前表环境的执行模式和计划器(planner)。执行模式有批处理和流处理两种选择,默认是流处理模式;计划器默认使用 blink planner。
第一种
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
308
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 使用流处理模式
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
第二种
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
4.3 创建表
Flink 中的表概念也并不特殊,是由多个“行”数据构成的,每个行(Row)又可以有定义好的多个列(Column)字段;整体来看,表就是固定类型的数据组成的二维矩阵。
1. 连接器表(Connector Tables)
通过连接器(connector)连接到一个外部系统,然后定义出对应的表结构。
例如我们可以连接到 Kafka 或者文件系统,将存储在这些外部系统的数据以“表”的形式定义出来,这样对表的读写就可以通过连接器转换成对外部系统的读写了。当我们在表环境中读取这张表,连接器就会从外部系统读取数据并进行转换;而当我们向这张表写入数据,连接器就会将数据输出(Sink)到外部系统中。
在代码中,我们可以调用表环境的 executeSql()方法,可以传入一个 DDL 作为参数执行
SQL 操作。这里我们传入一个 CREATE 语句进行表的创建,并通过 WITH 关键字指定连接到外部系统的连接器:
tableEnv.executeSql("CREATE [TEMPORARY] TABLE MyTable ... WITH ( 'connector'
= ... )");
这里没有定义 Catalog(相当于目录文件) 和 Database , 所 以 都 是 默 认 的 , 表 的 完 整 ID 就 是default_catalog.default_database.MyTable。如果希望使用自定义的目录名和库名,可以在环境中进行设置:
tEnv.useCatalog("custom_catalog");
tEnv.useDatabase("custom_database");
2. 虚拟表(Virtual Tables)
在环境中注册之后,我们就可以在 SQL 中直接使用这张表进行查询转换了。
Table newTable = tableEnv.sqlQuery("SELECT ... FROM MyTable... ");
由于 newTable 是一个 Table 对象,并没有在表环境中注册;所以我们还需要将这
个中间结果表注册到环境中,才能在 SQL 中使用。
tableEnv.createTemporaryView("NewTable", newTable);
上方就是虚拟标的创建过程。
虚拟表也可以让我们在 Table API 和 SQL 之间进行自由切换。一个 Java 中的 Table对象可以直接调用 Table API 中定义好的查询转换方法,得到一个中间结果表;这跟对注册好的表直接执行 SQL 结果是一样的。
4.4. 表的查询
对一个表的查询(Query)操作,就对应着流数据的转换(Transform)处理。
1. 执行 SQL 进行查询
Flink 基于 Apache Calcite 来提供对SQL 的支持,Calcite 是一个为不同的计算平台提供标准 SQL 查询的底层工具,很多大数据框架比如 Apache Hive、Apache Kylin 中的 SQL 支持都是通过集成 Calcite 来实现的。
执行得到的结果,是一个 Table 对象。
// 创建表环境
TableEnvironment tableEnv = ...;
// 创建表
tableEnv.executeSql("CREATE TABLE EventTable ... WITH ( 'connector' = ... )");
// 查询用户 Alice 的点击事件,并提取表中前两个字段
Table aliceVisitTable = tableEnv.sqlQuery(
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
上面的例子得到的是一个新的 Table 对象,我们可以再次将它注册为虚拟表继续在 SQL
中调用。另外,我们也可以直接将查询的结果写入到已经注册的表中,这需要调用表环境的
executeSql()方法来执行 DDL,传入的是一个 INSERT 语句:
// 注册表
tableEnv.executeSql("CREATE TABLE EventTable ... WITH ( 'connector' = ... )");
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// 将查询结果输出到 OutputTable 中
tableEnv.executeSql (
"INSERT INTO OutputTable " +
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
2. 调用 Table API 进行查询
这是嵌入在 Java 和 Scala 语言内的查询 API,核心就是 Table 接口类,通过一步步链式调用 Table 的方法,就可以定义出所有的查询转换操作。每一步方法调用的返回结果,都是一个 Table。
由于Table API是基于Table的Java实例进行调用的,因此我们首先要得到表的Java对象。基于环境中已注册的表,可以通过表环境的 from()方法非常容易地得到一个 Table 对象:
Table eventTable = tableEnv.from("EventTable");
调用 API 进行各种转换操作了,得到的是一个新的 Table 对象
Table maryClickTable = eventTable
.where($("user").isEqual("Alice"))
.select($("url"), $("user"));
注:“$”符号用来指定表中的一个字段
Table API 是嵌入编程语言中的 DSL,SQL 中的很多特性和功能必须要有对应的实现才可以使用,因此跟直接写 SQL 比起来肯定就要麻烦一些。目前 Table API 支持的功能相对更少。
3. 两种 API 的结合使用
(1)无论是那种方式得到的 Table 对象,都可以继续调用 Table API 进行查询转换;
(2)如果想要对一个表执行 SQL 操作(用 FROM 关键字引用),必须先在环境中对它进行注册。所以我们可以通过创建虚拟表的方式实现两者的转换:
tableEnv.createTemporaryView("MyTable", myTable);
简写
Table clickTable = tableEnvironment.sqlQuery("select url, user from " + eventTable);
将 Table 对象名 eventTable 直接以字符串拼接的形式添加到 SQL 语句中,在解析时会自动注册一个同名的虚拟表到环境中,这样就省略了创建虚拟视图的步骤。
大部分还是不用Table API的,功能较少。
4.5.输出表
在代码上,输出一张表最直接的方法,就是调用 Table 的方法 executeInsert()方法将一个Table 写入到注册过的表中,方法传入的参数就是注册的表名。
// 注册表,用于输出数据到外部系统
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// 经过查询转换,得到结果表
Table result = ...
// 将结果表写入已注册的输出表中
result.executeInsert("OutputTable");
在底层,表的输出是通过将数据写入到 TableSink 来实现的。TableSink 是 Table API 中提供的一个向外部系统写入数据的通用接口,可以支持不同的文件格式(比如 CSV、Parquet)、存储数据库(比如 JDBC、HBase、Elasticsearch)和消息队列(比如 Kafka)。它有些类似于DataStream API 中调用 addSink()方法时传入的 SinkFunction,有不同的连接器对它进行了实现。
4.6.表和流的转换
Table 没有提供 print()方法。
1. 将表(Table)转换成流(DataStream)
// 将表转换成数据流
tableEnv.toDataStream(aliceVisitTable).print();
调用 toChangelogStream()方法
(更新时)防止结果被打印多次
// 将表转换成更新日志流
tableEnv.toDataStream(urlCountTable).print();
2. 将流(DataStream)转换成表(Table)
调用 fromDataStream()方法
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取数据源
SingleOutputStreamOperator<Event> eventStream = env.addSource(...)
// 将数据流转换成表
Table eventTable = tableEnv.fromDataStream(eventStream);
由于流中的数据本身就是定义好的 POJO 类型 Event,所以我们将流转换成表之后,每一行数据就对应着一个 Event,而表中的列名就对应着 Event 中的属性。另外,我们还可以在 fromDataStream()方法中增加参数,用来指定提取哪些属性作为表中的字段名,并可以任意指定位置:
// 提取 Event 中的 timestamp 和 url 作为表中的列
Table eventTable2 = tableEnv.fromDataStream(eventStream, $("timestamp"),
$("url"));
可以通过表达式的 as()方法对字段进行重命名:
// 将 timestamp 字段重命名为 ts
Table eventTable2 = tableEnv.fromDataStream(eventStream, $("timestamp").as("ts"), $("url"));
调用 createTemporaryView()方法
以直接调用 createTemporaryView()方法创建虚拟表,传入的两个参数,第一个依然是注册的表名,而第二个可以直接就是
DataStream。之后仍旧可以传入多个参数,用来指定表中的字段.即转换的同时创建此表为视图。
tableEnv.createTemporaryView("EventTable", eventStream,
$("timestamp").as("ts"),$("url"));
调用 fromChangelogStream ()方法
表环境还提供了一个方法 fromChangelogStream(),可以将一个更新日志流转换成表。这个方法要求流中的数据类型只能是 Row,而且每一个数据都需要指定当前行的更新类型(RowKind);所以一般是由连接器帮我们实现的,直接应用比较少见,
3. 支持的数据类型
DataStream 中支持的数据类型,Table 中也是都支持的,只不过在进行转换时需要注意一些细节。
(1)原子类型
在 Flink 中,基础数据类型(Integer、Double、String)和通用数据类型(也就是不可再拆
分的数据类型)统一称作“原子类型”。原子类型的 DataStream,转换之后就成了只有一列的
Table,列字段(field)的数据类型可以由原子类型推断出。另外,还可以在 fromDataStream()
方法里增加参数,用来重新命名列字段。
StreamTableEnvironment tableEnv = ...;
DataStream<Long> stream = ...;
// 将数据流转换成动态表,动态表只有一个字段,重命名为 myLong
Table table = tableEnv.fromDataStream(stream, $("myLong"));
(2)Tuple 类型
Table 支持 Flink 中定义的元组类型 Tuple,对应在表中字段名默认就是元组中元素的属性名 f0、f1、f2…。所有字段都可以被重新排序,也可以提取其中的一部分字段。字段还可以通过调用表达式的 as()方法来进行重命名。
StreamTableEnvironment tableEnv = ...;
DataStream<Tuple2<Long, Integer>> stream = ...;
// 将数据流转换成只包含 f1 字段的表
Table table = tableEnv.fromDataStream(stream, $("f1"));
// 将数据流转换成包含 f0 和 f1 字段的表,在表中 f0 和 f1 位置交换
Table table = tableEnv.fromDataStream(stream, $("f1"), $("f0"));
// 将 f1 字段命名为 myInt,f0 命名为 myLong
Table table = tableEnv.fromDataStream(stream, $("f1").as("myInt"),
$("f0").as("myLong"));
(3)POJO 类型
POJO 类型的 DataStream 转换成 Table,如果不指定字段名称,就会直接使用原始 POJO 类型中的字段名称。POJO 中的字段同样可以被重新排序、提却和重命名。
StreamTableEnvironment tableEnv = ...;
DataStream<Event> stream = ...;
Table table = tableEnv.fromDataStream(stream);
Table table = tableEnv.fromDataStream(stream, $("user"));
Table table = tableEnv.fromDataStream(stream, $("user").as("myUser"),
$("url").as("myUrl"));
(4)Row 类型
它是 Table 中数据的基本组织形式。
是一种复合类型且它的长度固定。
Row 类型还附加了一个属性 RowKind,用来表示当前行在更新操作中的类型,Row 就可以用来表示更新日志流(changelog stream)中的数据,从而架起了 Flink 中流和表的转换桥梁。
DataStream<Row> dataStream =
env.fromElements(
Row.ofKind(RowKind.INSERT, "Alice", 12),
Row.ofKind(RowKind.INSERT, "Bob", 5),
Row.ofKind(RowKind.UPDATE_BEFORE, "Alice", 12),
Row.ofKind(RowKind.UPDATE_AFTER, "Alice", 100));
// 将更新日志流转换为表
Table table = tableEnv.fromChangelogStream(dataStream);