Google论文抢先看:说话人转换检测的字符级损失函数和评价指标
本文介绍谷歌团队发表于ICASSP 2023的一篇最新论文。该论文致力于提升基于Transformer-Transducer(T-T)的说话人转换检测模型,并提出了一种全新的基于字符的(token-based)训练方式,以及一种全新的、更加符合应用场景的评价指标。在不增加模型参数的情况下,这种新型训练方式能大幅提升说话人转换检测的模型性能。
论文链接:https://arxiv.org/pdf/2211.06482.pdf
作者:Guanlong Zhao, Quan Wang, Han Lu, Yiling Huang, Ignacio Lopez Moreno
说话人转换检测
说话人转换检测,英文为Speaker Change Detection (SCD)或者Speaker Turn Detection,所解决的是这样一个问题:在语音信号的特定时刻,其前后的说话人身份是否发生了变化。
该问题与声纹识别(即Speaker Recognition)以及声纹分割聚类问题(即Speaker Diarization)密切相关,但又有所区别。很多早期的说话人转换检测方法,就是简单地提取特定时刻左右两侧的声纹信息,并进行相似度量与阈值判别,从而判断该时刻是否发生了说话人转换。而很多声纹分割聚类的系统,也将说话人转换检测作为其中的一个关键步骤,用于对输入信号进行分割。而完成分割之后,就能对分割得到的语音片段进行声纹特征提取以及聚类。
近些年来,更多说话人转换检测方面的研究从传统方法转向了端到端的方法,即直接利用RNN-T模型或者T-T模型来检测说话人转换事件。这一类方法将说话人转换检测问题作为语音识别问题的一个变种来看待,直接在识别结果中加入特殊字符
例如对于同一段音频,语音识别模型的输出是:“hello how are you I am good”,该输出不包含说话人信息。
而基于RNN-T或者T-T模型的说话人转换检测的输出则是:“hello how are you

图1:谷歌的Turn-to-Diarize声纹分割聚类系统将说话人转换检测作为其中的一个重要组成部分
字符级损失函数
用于语音识别的标准RNN-T或者T-T模型,所使用的损失函数可以表示为- log P (Y | X),这里的X表示输入音频的特征序列,而Y表示目标文本的字符序列。
可以看到,在该损失函数中,我们对于所有的输出字符是一视同仁的。也就是说,在模型的训练过程中,任何一个字符导致的错误,其对于损失函数的影响是等价的。这一点对于标准的语音识别任务来说是没有任何问题的。但是对于说话人转换检测的问题来说,这样的设计则并不理想。
这是因为,绝大部分具备文本标注的语音数据,都并不包含说话人转换事件的信息。只有极少部分训练数据包含特殊字符
为此,论文提出了一种全新的字符级损失函数,该损失函数能够以更大的权重来处理特殊字符
该方法利用了语音识别领域中基于编辑距离的最小贝叶斯风险(Edit-distance based Minimum Bayes Risk,即EMBR)训练方式。EMBR在计算目标文本和输出文本的编辑距离的时候,考虑了字符序列的三种编辑方式,即插入(insert),删除(delete),和替换(substitute)。任何一个字符的任何一种编辑方式,都会使编辑距离加1。
在本论文中,我们对于字符
依据以上编辑距离,我们可以找到目标文本和输出文本之间编辑距离最小的对齐方式,并且计算出在该对齐方式下,字符
一种全新的评价指标
对于说话人转换检测问题,传统的评价指标大部分基于说话人转换检测事件的具体预测时间点。但这一类评价指标的问题在于,它们对于预测时间点都非常的敏感。而人工标注的这些具体的时间点,其精度通常也比较有限,因此很容易因为较小的误差而将正确的预测判定为错误的预测。
参考前面的例子“hello how are you
因此,论文提出了一种基于区间(interval-based)的评价指标。在前面的例子中,整段语音可以被分为三个区间:“hello how are you”所对应的第一区间;两段语音之间的第二区间;以及“I am good”所对应的第三区间。在这种新的评价指标下,任何出现在第一区间或者第三区间的
这种评价指标也能很好地处理重叠的语音。假如“hello how are you”的最后若干单词,与“I am good”的前面几个单词在时间上出现了重叠,那么这部分重叠的内容就构成了说话人转换所对应的区间。任何出现在该区间的
在基于区间的评价体系下,我们便能计算相应的精确度(precision)和召回率(recall),以及相应的F1分数。
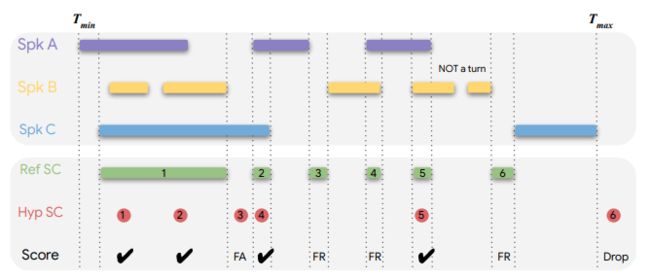
图2:基于区间的说话人转换检测评价指标
实验结果
论文在多个测试数据集上对比了三种说话人转换检测方法的表现,包括:使用标准RNN-T损失函数的Baseline方法;使用基于编辑距离的最小贝叶斯风险的标准EMBR方法;以及本论文所介绍的字符级损失函数SCD Loss方法。测试数据集包含了AMI、CallHome、DIHARD1、Fisher、ICSI等公开数据集,同时也包含了Inbound和Outbound两个内部的电话呼叫中心数据集。这些测试数据集覆盖了会议和电话语音这两个比较常见的多说话人语音应用场景。
在所有的测试数据集上,基于区间的F1分数都表示,SCD Loss方法恒定的要显著优于Baseline和EMBR这两种方法。而传统的、基于具体时间点的F1分数(采用开源软件pyannote.metrics实现),则在不同的测试数据集上,很难区分三种方法的优劣。
这样的结果非常符合我们的预期,并能够得出以下结论:(1)传统的、基于具体时间点的说话人转换检测评价指标,由于其对于具体时间点过于敏感,很难有效地对说话人转换检测算法进行评价;而基于区间的评价指标,则能够对不同方法给出更为一致性的评价。(2)论文所提出的字符级损失函数能够有效地提升说话人转换检测的评价指标。与标准的RNN-T损失函数相比,F1分数提升了5.8%的绝对数值;与标准的EMBR损失函数相比,F1分数提升了2.4%的绝对数值。
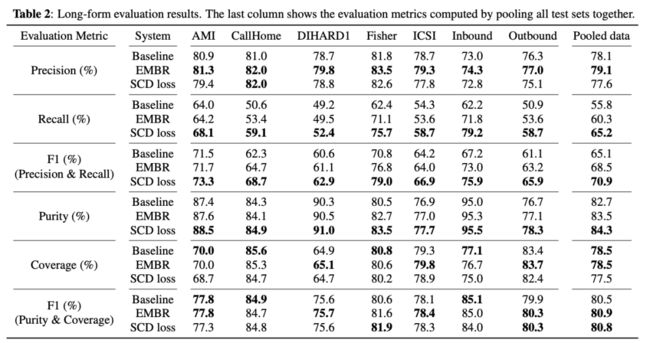
图3:不同损失函数在各个测试数据集上的两类评价指标