Leetcode刷题总结(二)
1、序列化二叉树
思路:这里把一颗二叉树转换成一个序列,再将序列转换成树。那这里只有一个序列,不存在先+中确定唯一二叉树的情况,因此这里要借助层序的关系,从上到下将节点保存,并保存空节点。这里比较麻烦的是,对字符串的处理,因为要考虑“,”。可以将得到的字符串,先去掉“,”,那么此时留下的都是节点。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Codec {
public:
// Encodes a tree to a single string.
string serialize(TreeNode* root) {
if(root==NULL)
return "[]";
string data="[";
queue q;
q.push(root);
while(q.size()!=0)
{
TreeNode* node = q.front();
q.pop();
if(node!=NULL)
{
data+=to_string(node->val);
data+=",";
q.push(node->left);
q.push(node->right);
}else{
data+="null,";
}
}
// data.erase(data.length()-1,1); 本来想去掉末尾的“,”,但是有后面的函数,不去也可以
return data+"]";
}
vector split(string& s, string delim) // 去掉“,”
{
vector ret;
int p = s.find(delim);
while (p != -1)
{
ret.push_back(s.substr(0,p));
s.erase(0, p+1);
p = s.find(delim);
}
ret.push_back(s);
return ret;
}
// Decodes your encoded data to tree.
TreeNode* deserialize(string data) {
data.erase(0, 1); // 去掉【
data.erase(data.length()-1, 1); // 去掉 】
if(data.length()==0) // "[]"的情况
return NULL;
vector vec = split(data, ","); // 此时节点都保存在vec中
int i=0;
int value = atoi(vec[i].c_str());
i++;
TreeNode* root = new TreeNode(value);
queue q;
q.push(root);
while(q.size()!=0)
{
TreeNode* node = q.front();
q.pop();
string tmp_left = vec[i];
if(tmp_left=="null")
{
node->left=NULL;
}else{
int value = atoi(tmp_left.c_str());
TreeNode* le = new TreeNode(value);
node->left = le;
q.push(node->left);
}
i++;
string tmp_right = vec[i];
if(tmp_right=="null")
{
node->right=NULL;
}else{
int value = atoi(tmp_right.c_str());
TreeNode* ri = new TreeNode(value);
node->right = ri;
q.push(node->right);
}
i++;
}
return root;
}
};
// Your Codec object will be instantiated and called as such:
// Codec codec;
// codec.deserialize(codec.serialize(root));
2、字符串的排列
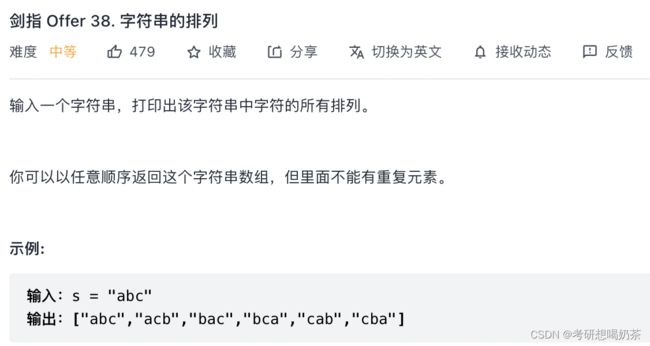
思路:这题考的是全排列,如果直接暴力肯定超时。其实就是设置一个visited数组,用来标志当前字符是否被访问,如果被访问过了那就跳过下一个,逐渐罗列出所有情况。
class Solution {
public:
void dfs(string s, string tmp, vector visited, set& ans)
{
if(tmp.length()==s.length())
{
ans.insert(tmp);
return;
}
for(int i=0;i permutation(string s) {
set ans; // 这里用set是由于有些情况会出现重复,用set去重
vector visited(s.length(), 0);
dfs(s, "", visited, ans);
vector final;
set::iterator iter;
iter = ans.begin();
while(iter!=ans.end())
{
final.push_back(*iter);
iter++;
}
return final;
}
};
还有一种回溯写法,可以不借助set,因为太慢了。
class Solution {
public:
vector rec;
vector vis;
void backtrack(const string& s, int i, int n, string& perm) {
if (i == n) {
rec.push_back(perm);
return;
}
for (int j = 0; j < n; j++) {
if (vis[j] || (j > 0 && !vis[j - 1] && s[j - 1] == s[j])) { // 这里判断的意思是:1)如果被访问过,那就不要;2)如果这个字符不是第一个重复字符,就不要,意思是每次只拿重复字符中第一个,这样就避免重复
continue;
}
vis[j] = true;
perm.push_back(s[j]);
backtrack(s, i + 1, n, perm);
perm.pop_back();
vis[j] = false;
}
}
vector permutation(string s) {
int n = s.size();
vis.resize(n);
sort(s.begin(), s.end()); // 先把字符串排序,让重复的字符放在一起
string perm;
backtrack(s, 0, n, perm);
return rec;
}
};
3、格雷码(不会)
思路:这里就记住格雷码的公式

class Solution {
public:
vector grayCode(int n) {
vector ret(1 << n); // 初始化2^n长度的vector
for (int i = 0; i < ret.size(); i++) {
ret[i] = (i >> 1) ^ i;
}
return ret;
}
};
4、丑数(超时)

思路:根据题目意思,其实可以想到,在已有n个丑数的情况下,要找第n+1个丑数的话:

但不能直接用循环遍历做,会超时。为了保证每个丑数都有乘2,乘3, 乘5,且保持有序,就要记录这个丑数是否乘过。设置3个索引a, b, c,分别记录前几个数已经被乘2, 乘3, 乘5了,比如a表示前(a-1)个数都已经乘过一次2了,下次应该乘2的是第a个数。
对于某个状态下的丑数序列,我们知道此时第a个数还没有乘2(有没有乘3或者乘5不知道), 第b个数还没有乘3(有没有乘2或者乘5不知道),第c个数还没有乘5(有没有乘2或者乘3不知道), 下一个丑数一定是从第a丑数乘2, 第b个数乘3, 第c个数乘5中获得,他们三者最小的那个就是下个丑数。
class Solution {
public:
int nthUglyNumber(int n) {
if(n < 7) return n;
vector res(n);
//初始化
res[0] = 1;
int a = 0,b = 0,c = 0; // 用a,b,c分别作为2、3、5因子倍数的索引
for(int i = 1;i < n;i++)
{
// 取dp[a]*2,dp[b]*3,dp[c]*5的最小值
res[i]=min({res[a]*2,res[b]*3,res[c]*5});
if(res[i] == res[a] * 2) a++; // 如果是2的倍数,那么2对应的索引++
if(res[i] == res[b] * 3) b++;
if(res[i] == res[c] * 5) c++;
}
return res[n - 1];
}
};
5、 n个骰子的点数(不会)

思路:暴力法肯定超时。对于n个骰子,最小值为n,最大是6n,总共可能出现的和的数量是5n+1种。
假设n-1个骰子,所有和出现概率的情况记为f(n-1),现在要求f(n)。f(n-1,x)表示n-1个骰子投出和为x的概率。
这相当于在n-1个骰子已经求完和后,再扔第n个骰子,此时第n个骰子的值只能是1-6,且概率都是1/6,独立于前n-1个骰子。
现在假设要求f(n,x),那么n个骰子和为x的概率是:
f ( n , x ) = ∑ 1 < = i < = 6 f ( n − 1 , x − i ) ∗ 1 6 f(n, x) = {\sum_{1<=i<=6}}f(n-1,x-i)*{\frac{1}{6}} f(n,x)=1<=i<=6∑f(n−1,x−i)∗61
但在遍历1-6的过程中,x可能小于i,导致出现负数,需要增加判断条件。也可以改为正向思路:
f ( n , x + i ) + = f ( n − 1 , x ) ∗ 1 6 f(n, x+i) += f(n-1,x)*{\frac{1}{6}} f(n,x+i)+=f(n−1,x)∗61
当n个骰子和为x+i时,是在n-1个骰子和为x的基础上再乘1/6。
class Solution {
public:
vector dicesProbability(int n) {
vector dp(6, 1.0 / 6.0);
for (int i = 2; i <= n; i++) {
vector tmp(5 * i + 1, 0); // 当i个骰子的时候,总共可能出现的情况数量
for (int j = 0; j < dp.size(); j++) {
for (int k = 0; k < 6; k++) {
tmp[j + k] += dp[j] / 6.0;
}
}
dp = tmp;
}
return dp;
}
};
6、正则表达式匹配(不会)

思路:

class Solution {
public:
bool isMatch(string s, string p) {
int m = s.size() + 1, n = p.size() + 1;
vector> dp(m, vector(n, false));
dp[0][0] = true;
// 初始化首行
for(int j = 2; j < n; j += 2)
dp[0][j] = dp[0][j - 2] && p[j - 1] == '*';
// 状态转移
for(int i = 1; i < m; i++) {
for(int j = 1; j < n; j++) {
if(p[j - 1] == '*') {
if(dp[i][j - 2]) dp[i][j] = true; // 1.
else if(dp[i - 1][j] && s[i - 1] == p[j - 2]) dp[i][j] = true; // 2.
else if(dp[i - 1][j] && p[j - 2] == '.') dp[i][j] = true; // 3.
} else {
if(dp[i - 1][j - 1] && s[i - 1] == p[j - 1]) dp[i][j] = true; // 1. 在前i-1和j-1匹配的基础上,若新添加s[i-1]和p[j-1]两者相等,那么dp[i][j]也匹配
else if(dp[i - 1][j - 1] && p[j - 1] == '.') dp[i][j] = true; // 2. 取‘.’代表任意字母,可以匹配
}
}
}
return dp[m - 1][n - 1];
}
};
7、数组中的逆序对(不会)
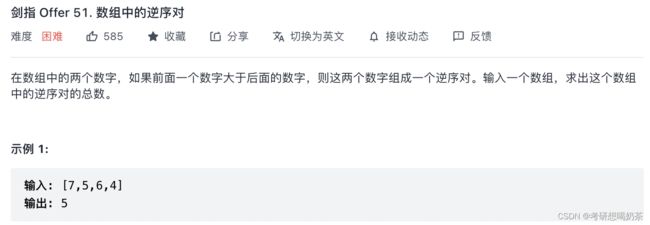
思路:这里是借助了归并排序,在合并的过程中,需要比较前后两个数字大小来判断先放谁,后放谁,这就包含了计算逆序对的过程。
class Solution {
public:
int reversePairs(vector& nums) {
vector tmp(nums.size());
return mergeSort(0, nums.size() - 1, nums, tmp);
}
private:
int mergeSort(int l, int r, vector& nums, vector& tmp) {
// 终止条件
if (l >= r) return 0;
// 递归划分
int m = (l + r) / 2;
int res = mergeSort(l, m, nums, tmp) + mergeSort(m + 1, r, nums, tmp);
// 合并阶段
int i = l, j = m + 1;
for (int k = l; k <= r; k++)
tmp[k] = nums[k];
for (int k = l; k <= r; k++) {
if (i == m + 1)
nums[k] = tmp[j++];
else if (j == r + 1 || tmp[i] <= tmp[j])
nums[k] = tmp[i++];
else {
nums[k] = tmp[j++];
res += m - i + 1; // 统计逆序对
}
}
return res;
}
};
8、1-n整数中1 出现的次数(不会)
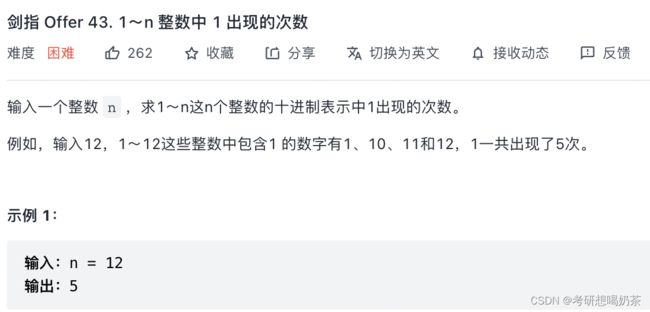
思路:设n是x位数,可表示为 n x n x − 1 . . . n 2 n 1 n_xn_{x-1}...n_2n_1 nxnx−1...n2n1。
- 记 n i n_i ni是当前位,为cur
- n x n x − 1 . . . n i + 1 n_xn_{x-1}...n_{i+1} nxnx−1...ni+1是高位,记为high
- n i − 1 . . . n 1 n_{i-1}...n_{1} ni−1...n1是高位,记为low
- 1 0 i 10^i 10i是位因子,记为digit,表示已经遍历了个位、十位、百位…
根据cur的取值,来分别统计会出现1的次数。
- cur=0:
以2304为例。此时digit=10,是在遍历十位的情况。
high位可以取00-22,共23种情况,此时十位可以取1,个位可以取0-9,共 23 ∗ 10 23*10 23∗10种情况;(也就是 h i g h ∗ d i g i t high*digit high∗digit)
而high位取23时,十位只能取0,不然大于2304,个位可以取0-4,组成2300,2301,2302,2303,2304,但是2301不能算,因为1出现在个位上,是当digit=1的时候会统计过,这里就不在统计。
总共 h i g h ∗ d i g i t high*digit high∗digit - cur=1:
以2314为例,此时digit=10。
high位可以取00-22,十位为1,个位取0-9,共 23 ∗ 10 23*10 23∗10种情况;(high*digit)
当high取23时,十位为1,个位取0-4,共4+1种情况;(low+1)
总共 h i g h t ∗ d i g i t + l o w + 1 hight*digit+low+1 hight∗digit+low+1 - cur=2-9:
以23*4为例,digit=10。
high取00-23,十位取1,个位取0-9,共 24 ∗ 10 24*10 24∗10种情况;( ( h i g h + 1 ) ∗ d i g i t (high+1)*digit (high+1)∗digit)
总共 ( h i g h + 1 ) ∗ d i g i t (high+1)*digit (high+1)∗digit
class Solution {
public:
int countDigitOne(int n) {
long digit=1; // 因为要不断乘10,可能会超出int边界。digit=1就是从个位开始遍历统计
int res = 0;
int high = n/10;
int cur = n%10;
int low = 0;
while(high!=0||cur!=0) // hight=0表示没有高位,cur=0表示没有当前位,也就是遍历完全
{
if(cur==0)
{
res+= high * digit;
}else if(cur==1)
{
res+= high*digit+low+1;
}else{
res+=(high+1)*digit;
}
low += cur * digit;
cur = high % 10;
high /= 10;
digit *= 10;
}
return res;
}
};
9、数字序列中某一位数字
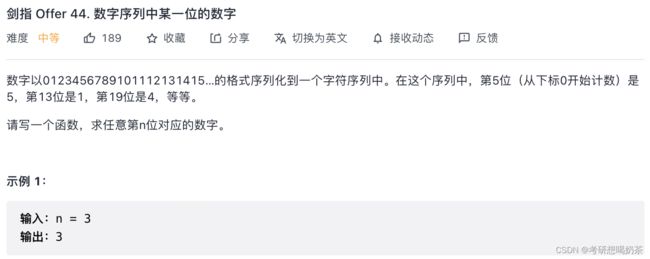
思路:这题受到上一题的启发,自己终于解出来了。大体思路是,按照0-9、10-99、100-999…这样的范围将数字序列分块,要找到第n个数在哪一块中,然后从这一块开始找数字即可。
那么如何计算某一块的数字占了多少位呢?
s u m = ( d i g i t + 1 ) ∗ p o w ( 10 , d i g i t ) ∗ 9 sum=(digit+1)*pow(10, digit)*9 sum=(digit+1)∗pow(10,digit)∗9
拿10-99为例:
这里digit表示位因子,那么作为两位数,每个数会占digit+1位,而10-19有十个数,因此占(digit+1)*pow(10,digit);又10、20、30、…90有9组,因此总共是(digit+1)*pow(10,digit)*9。
class Solution {
public:
int findNthDigit(int n) {
long sum=0; // 避免越界
if(n<10)
{
return n;
}
sum+=10; // 前面0-9就是10个数
int digit=1; // 从十位开始遍历
while(sum10、剪绳子2
思路:这一题和之前的剪绳子基本上思路一样,就是这里需要对大数据越界进行处理。这里学习一种循环求余的做法,每次求结果都取个余,并用long long 类型存储结果,避免越界。
class Solution {
public:
int cuttingRope(int n) {
if(n<=3)
{
return n-1;
}
int duanshu = n/3;
int res = n%3;
long long ans=1;
if(res==1)
{
while(duanshu>1)
{
ans*=3;
ans%=1000000007;
duanshu--;
}
ans*=4;
ans%=1000000007;
}else if(res==2){
while(duanshu>0)
{
ans*=3;
ans%=1000000007;
duanshu--;
}
ans*=2;
ans%=1000000007;
}else if(res==0){
while(duanshu>0)
{
ans*=3;
ans%=1000000007;
duanshu--;
}
ans%=1000000007;
}
return ans;
}
};
11、累加数

思路:其实把问题可以拆解为,每次找三个数a,b,c,要让a+b=c;而下一次,b,c就变成了新的a,b,要找新的c。然而每个数究竟多长不确定,因此用循环回溯去判断。这里比较复杂的是处理判断条件,以及和可能超出int边界的问题。
class Solution {
public:
long long to_num(string s)
{
long long ans=0;
while(s.size()!=0)
{
int a = stoi(s.substr(0, 1));
ans=ans*10+a;
s.erase(s.begin());
}
return ans;
}
bool dfs(int firstlen, int secondlen, string num)
{
if(firstlen>num.size()||firstlen+secondlen>num.size()) // 判断越界的情况,如果长度超出了num,那么就无法取出数字
{
return false;
}
long long first = to_num(num.substr(0, firstlen)); // 用long long 类型来存储,避免越界。同时这里自己写了一个to_num函数,而不直接用stoi,因为stoi也会越界。
string tmp_first = to_string(first);
if(tmp_first.size()!=firstlen) // 这里是要排除,数字有前置0的情况,如001
{
return false;
}
long long second = to_num(num.substr(firstlen, secondlen));
string tmp_second = to_string(second);
if(tmp_second.size()!=secondlen)
{
return false;
}
long long sum = first + second;
string tmp = to_string(sum);
int thirdlen = tmp.length();
if(firstlen+secondlen+thirdlen>num.size())
{
return false;
}
long long third = to_num(num.substr(firstlen+secondlen, thirdlen));
if(third!=sum)
{
return false;
}else{
if(num.length()==(firstlen+secondlen+thirdlen)) // 如果刚好a+b=c,返回true
{
return true;
}else{
return dfs(secondlen, thirdlen, num.substr(firstlen));
}
}
}
bool isAdditiveNumber(string num) {
int len = num.length();
if(len<3) // 题目说至少3个数,每个数至少长1位,因此如果num长度小于3肯定不符合
{
return false;
}
bool ans = false;
for(int i=1;i<=len-2;i++) // 记i代表了a的长度,最短是1,最长是len-2,因为b,c的长度最短是1
{
for(int j=1;j<=len-2;j++) // 记j代表了b的长度
{
bool f = dfs(i, j, num); // 进入回溯
if(f)
{
return f;
}
}
}
return ans;
}
};
12、字符串轮转
思路:首先两个字符串长度要想等。要判断s2是否为s1旋转而成,其实可以判断s1+s1中能否找到s2。因为s1+s1相当于一次全字符串的旋转,其中必然可以找到旋转的s2。
class Solution {
public:
bool isFlipedString(string s1, string s2) {
return (s1.length()==s2.length())&&(s1+s1).find(s2)!=-1;
}
};
13、回文链表
思路:正常的做法可以把链表的值都放在vector里面,然后判断是否回文即可。而如果要时间复杂度O(n),空间复杂度O(1),那么就不能借助辅助空间。这里直接将链表的后半部分进行reverse,如果前后两部分遍历值一样,那就是回文的。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* reverse(ListNode* head)
{
if(head==NULL)
{
return head;
}
ListNode* p = head;
ListNode* q = p->next;
p->next = NULL;
while(q!=NULL)
{
ListNode* back = q->next;
q->next = p;
p = q;
q = back;
}
return p;
}
bool isPalindrome(ListNode* head) {
int len = 0;
ListNode* p = head;
while(p!=NULL)
{
len++;
p = p->next;
}
if(len%2!=0) // 如果长度为奇数,那么后半部分链表的头要多走一个节点
{
ListNode* p = head;
ListNode* q = head;
for(int i=0;inext;
}
q = q->next;
ListNode* p2 = reverse(q);
for(int i=0;ival!=p2->val)
{
return false;
}
p = p->next;
p2 = p2->next;
}
return true;
}else{
ListNode* p = head;
ListNode* q = head;
for(int i=0;inext;
}
ListNode* p2 = reverse(q);
for(int i=0;ival!=p2->val)
{
return false;
}
p = p->next;
p2 = p2->next;
}
return true;
}
}
};
14、逃离大迷宫(超时)
思路:其实搜索的思路比较容易写,关键是如何判断跳出,因为网格太大了,有可能全搜完,导致超时。题目中有一个条件,blocked数组大小最大是200,也就是封锁格子的数量最多200个。
而从 s 跑一遍 BFS,然后从 t 跑一遍 BFS,同时设定一个最大访问点数量 MAX,若从两者出发能够访问的点数量都能超过 MAX,说明两点均没有被围住,最终必然会联通。
而MAX最大值如下图,其实是当n个封锁格子为斜边组成方形:
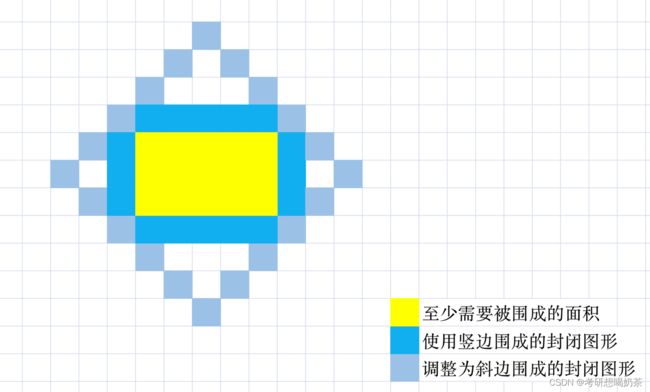
因此, M A X = n ∗ ( n − 1 ) 2 MAX=\frac{n*(n-1)}{2} MAX=2n∗(n−1)
当能遍历的格子数量超过MAX,说明此时遍历不会再被封锁,可以自由前行。同理要对终点也要判断一次,因为有可能终点被困在MAX范围里面。需要两个点都超过MAX。
class Solution {
public:
unordered_set block_set; // 存放封锁格子的索引
int MAX=1e5;
long long BASE = 13331;
int zuobiao[4][2] = {{1,0}, {-1,0},{0,1}, {0, -1}};
bool check(vector& source, vector& target)
{
unordered_set vis; // 访问过的格子
queue > q;
q.push({source[0], source[1]});
vis.insert(source[0]*BASE+source[1]);
while(q.size()<=MAX&&vis.size()<=MAX)
{
auto t = q.front();
q.pop();
int x = t.first;
int y = t.second;
for(int i=0;i<4;i++)
{
int newX = x+zuobiao[i][0];
int newY = y+zuobiao[i][1];
if(newX==target[0]&&newY==target[1]) // 到达终点
{
return true;
}
if(newX<0||newY<0||newX>=1e6||newY>=1e6) // 超过了网格范围
continue;
if(block_set.count(newX*BASE+newY)) // 碰到了封锁格子
continue;
if(vis.count(newX*BASE+newY)) // 已经访问过
continue;
q.push({newX, newY});
vis.insert(newX*BASE+newY);
}
}
return vis.size()>MAX; // 能够访问的格子数量要超过MAX
}
bool isEscapePossible(vector>& blocked, vector& source, vector& target) {
int len = blocked.size();
if(len==0) // 没有封锁的格子,一定可以走到终点
{
return true;
}
MAX = len*(len-1)/2;
for(int i=0;i 15、环路检测
思路:用快慢指针来遍历链表,这样可以节省空间开销。
数学证明如下:
此时,如果让一个指针从头节点开始走,让慢指针从相遇点开始走,那两者最终在环起始点相遇。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
if(head==NULL)
{
return NULL;
}
ListNode* slow = head;
ListNode* fast = head;
while(fast!=NULL&&fast->next!=NULL) // 说明链表不少于2个节点
{
slow = slow->next; // 慢指针走一格
fast = fast->next->next; // 快指针走两格
if(slow==fast) // 当快慢指针相遇,说明已经在环内
{
fast = head; // 此时让快指针从头节点出发
while(slow!=fast) // 让快慢指针同时走,最终相遇的地方就是环起点
{
slow = slow->next;
fast = fast->next;
}
return slow;
}
}
return NULL;
}
};
16、栈的最小值
思路:设两个栈,一个主栈就是正常push,pop;而另一个最小栈,里面元素是主栈每一位元素对应的最小值。
class MinStack {
stack x_stack;
stack min_stack;
public:
MinStack() {
min_stack.push(INT_MAX);
}
void push(int x) {
x_stack.push(x);
min_stack.push(min(min_stack.top(), x)); // 比较新来的元素和之前的最小值。如果之前的最小值更小,说明x对应的最小值还是之前的最小值;如果x更小,那么最小值更新
}
void pop() {
x_stack.pop();
min_stack.pop();
}
int top() {
return x_stack.top();
}
int getMin() {
return min_stack.top();
}
};
17、节点间通路(超时)

思路:可以用深搜或广搜。超时的原因是没有用一个vis来标记已经访问过的节点,导致存在环的话,一直在里面循环,出不来。
class Solution {
private:
vector visited;
unordered_map> map; // 邻接表
public:
bool findWhetherExistsPath(int n, vector>& graph, int start, int target) {
if(start==target) return true;
for(vector& vec:graph){
map[vec[0]].push_back(vec[1]); // 根据边的关系,存入邻接表中
}
visited=vector(n,false); // 设置访问数组
return dfs(start,target);
}
bool dfs(int start,int target){
if(start==target) return true;
if(visited[start]) return false;
visited[start]=true; // 设置当前节点已经访问过,说明之前走过这条路,之后再递归就不需要再走这个节点。有的情况是需要在递归回来后,将访问标记去除。
for(int point:map[start]){
if(dfs(point,target)) return true;
}
return false;
}
};
18、递增的三元子序列(不会)
思路:直接暴力最后一个用例超时。用贪心算法:定义a来存储当前元素之前最小的值,定义b存储第二大的值,形成了长度为2的递增序列。
class Solution {
public:
bool increasingTriplet(vector& nums) {
int len = nums.size();
if(len<3)
{
return false;
}
int a = INT_MAX;
int b = INT_MAX;
for(int i=0;i=nums[i]) // 说明b肯定比a大
{
b = nums[i];
}else{ // 又找到比b更大的数
return true;
}
}
return false;
}
};
第二种解法:双向遍历。
这种解法没有想到,不应该。第一次遍历,用数组存储当前元素之前的最小值;第二次遍历,用另一个数组存储当前元素之后的最大值。(因为递增序列有索引大小的关系)。最后一次遍历,只要在去头去尾的中间元素找到一个值介于最小值、最大值中间即可。
class Solution {
public:
bool increasingTriplet(vector& nums) {
int n = nums.size();
if (n < 3) {
return false;
}
vector leftMin(n);
leftMin[0] = nums[0];
for (int i = 1; i < n; i++) {
leftMin[i] = min(leftMin[i - 1], nums[i]);
}
vector rightMax(n);
rightMax[n - 1] = nums[n - 1];
for (int i = n - 2; i >= 0; i--) {
rightMax[i] = max(rightMax[i + 1], nums[i]);
}
for (int i = 1; i < n - 1; i++) {
if (nums[i] > leftMin[i - 1] && nums[i] < rightMax[i + 1]) {
return true;
}
}
return false;
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/increasing-triplet-subsequence/solution/di-zeng-de-san-yuan-zi-xu-lie-by-leetcod-dp2r/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
19、最小高度树

思路:由于题目给的是升序的数组,因此就已经给了二叉搜索树的潜在条件。为了构建高度最小的二叉搜索树,就是让左右子树尽量平衡,那就从数组的中点作为根节点,然后分数组为左数组、右数组,再递归构建左子树、右子树,此时左右子树的数量应该是差不多的。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* sortedArrayToBST(vector& nums) {
if(nums.size()==0)
{
return NULL;
}
int mid = nums.size()/2; // 求终点,不用管奇偶
TreeNode* root = new TreeNode(nums[mid]);
vector left;
for(int i=0;i right;
for(int i=mid+1;ileft = sortedArrayToBST(left);
root->right = sortedArrayToBST(right);
return root;
}
};
20、特定深度节点链表
思路:用BFS按层遍历,这里要统计每层有多少节点,其实可以直接用当前队列有多少元素,就是这层的节点数。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
vector listOfDepth(TreeNode* tree) {
vector ans;
if(tree==NULL)
{
return ans;
}
queue q;
q.push(tree);
while(q.size()!=0)
{
ListNode* head = NULL;
ListNode* pre = NULL;
int curSize = q.size(); // 当前队列的元素个数,即为这一层的节点数
for(int i=0;ival);
q.pop();
if(node!=NULL)
{
if(head==NULL)
{
head = listnode;
}else{
pre->next = listnode;
}
pre = listnode;
if(node->left!=NULL)
q.push(node->left);
if(node->right!=NULL)
q.push(node->right);
}
}
ans.push_back(head);
}
return ans;
}
};
21、检查平衡性
思路:这里考察两点,1)求树高;2)递归左右子树进行判断
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int height(TreeNode* root)
{
if(root!=NULL)
{
return max(height(root->left), height(root->right))+1; // 左右子树更高者+1
}else{
return 0;
}
}
bool isBalanced(TreeNode* root) {
if(root==NULL)
{
return true;
}
if(abs(height(root->left)-height(root->right))>1) // 判断左右子树的高度差
{
return false;
}
return isBalanced(root->left)&&isBalanced(root->right);
}
};
22、后继者

思路:就是中序遍历,当找到p后,先标记,再进入一次中序遍历后得到的根节点就是后继者。我是直接将中序遍历节点存下来,然后遍历数组找后继者。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
TreeNode node;
public TreeNode inorderSuccessor(TreeNode root, TreeNode p) {
dfs(root, p);
// 当node == p的时候,p是最后一个元素,所以没有后继节点
return node == p ? null : node;
}
private void dfs(TreeNode root, TreeNode p) {
if (root == null) return;
dfs(root.left, p);
// 如果已经找到p节点,将node赋值为p的后继节点
if (node == p) {
node = root;
return;
}
// 找到p节点
if (root == p) node = root;
dfs(root.right, p);
}
}
作者:huyii
链接:https://leetcode-cn.com/problems/successor-lcci/solution/mian-shi-ti-0406-hou-ji-zhe-by-huyii-a1qs/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
23、配对交换(不会位运算)

class Solution {
public int exchangeBits(int num) {
//奇数
int odd = num & 0x55555555;
//偶数
int even = num & 0xaaaaaaaa;
odd = odd << 1;
even = even >>> 1;
return odd | even;
}
}
作者:releng-xing
链接:https://leetcode-cn.com/problems/exchange-lcci/solution/wei-yun-suan-jie-jue-by-releng-xing/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
24、删除中间节点

思路:这里只传入了要删除的节点,但是没给头节点,因此不能遍历删除。因此只知道要删除的节点,及其后面的节点,可以考虑将后一个节点的值赋给当前节点,并将指针也赋给当前节点,此时用后一个节点覆盖了当前节点,就变相删除了当前节点。
class Solution {
public:
void deleteNode(ListNode* node) {
node->val = node->next->val;
node->next = node->next->next;
}
};
25、绘制直线(不会)
思路:主要这里有可能出现多行,不一定在同一水平线。

class Solution {
public:
vector drawLine(int length, int w, int x1, int x2, int y) {
vector res;
int cols=w/32; // 说明一行有几个int数
int rows=length/cols; // 总共length个int,一行有cols个int,因此rows代表有几行
for(int row=0;row num; // 用bitset来存储二进制
for(int k=0;k<32;k++){//遍历每个组(32个像素)
if(x1<=col*32+k&&col*32+k<=x2){
num[31-k]=1; // 直线经过的标1
}
}
res.push_back((int)num.to_ulong()); // 将二进制转化为int,这个不知道,学习一下
}
else res.push_back(0);
}
}
return res;
}
};
作者:xuheding
链接:https://leetcode-cn.com/problems/draw-line-lcci/solution/mian-shi-ti-0508-hui-zhi-zhi-xian-cshi-y-nmp1/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
26、统计元音字母序列的数目

思路:有点像跳台阶问题,每个元音都有相对应的情况,相当于每次跳台阶有多种选择。
class Solution {
public:
int M = 1000000007;
int countVowelPermutation(int n) {
if(n==1)
{
return 5;
}
long long dp[n+1][5]; // 表示记录在当前长度下,以第i个元音字母结尾的序列数量
dp[1][0] = dp[1][1] = dp[1][2] = dp[1][3] = dp[1][4] = 1;
for(int i=2;i<=n;i++)
{
dp[i][0] = dp[i-1][1] + dp[i-1][2] + dp[i-1][4]; // 以a结尾的序列数量,可以由这三种情况组成
dp[i][1] = dp[i-1][0] + dp[i-1][2];
dp[i][2] = dp[i-1][1] + dp[i-1][3];
dp[i][3] = dp[i-1][2];
dp[i][4] = dp[i-1][2] + dp[i-1][3];
for(int j=0;j<5;j++)
{
dp[i][j] %= M; // 为防止越界,这里每次都要取余
}
}
int ans=0;
for(int j=0;j<5;j++)
{
ans+=dp[n][j]; // 最后把5种字母结尾的序列数量全加起来
ans%=M;
}
return ans;
}
};
27、幂集
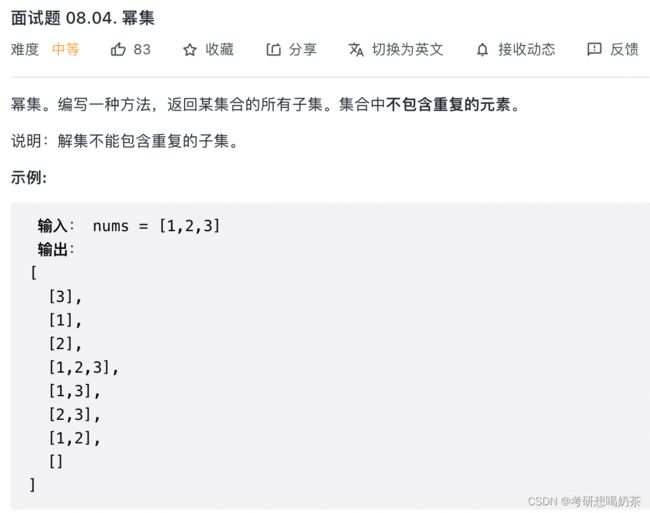
思路:这里用回溯的思想。
进入回溯:
for循环条件:
加入集合;
进入下一步回溯;
退出集合;(避免影响下一次回溯)
class Solution {
public:
void tongji(vector tmp, vector& nums, int index, vector >& ans)
{
ans.push_back(tmp);
for(int i=index;i> subsets(vector& nums) {
vector > ans;
vector tmp;
tongji(tmp, nums, 0, ans);
return ans;
}
};
28、二进制数转字符串

思路:题目理解,0.625可以化为分数 5 8 \frac{5}{8} 85,5对应二进制101,8对应3位二进制,因此得到二进制小数形式是0.625。
class Solution {
public:
int max_yueshu(int a,int b) // 求最大公约数
{
int i;
while(b!=0)
{
i=a%b;
a=b;
b=i;
}
return a;
}
pair fenshu(string s_num)
{
string tmp = s_num.substr(2);
int len = tmp.size();
int fenzi = stoi(tmp);
int fenmu = pow(10, len);
int d = max_yueshu(fenzi, fenmu); // 求出分子、分母的最大公约数,来化简分式
fenzi /= d;
fenmu /= d;
int tmp_fenbu=fenmu;
while(tmp_fenbu%2==0) // 判断分母是不是2的幂次,只有2的幂次才能化成二进制
{
tmp_fenbu/=2;
}
if(tmp_fenbu!=1)
{
return make_pair(-1, -1);
}else{
return make_pair(fenzi, fenmu);
}
}
string get_binary(int x)
{
string ans = "";
while(x!=0)
{
int a = x%2;
x/=2;
ans+=to_string(a);
}
reverse(ans.begin(), ans.end());
return ans;
}
string printBin(double num) {
string s_num = to_string(num);
string ans = "0.";
pair get_fenshu = fenshu(s_num);
if(get_fenshu.first==-1)
{
return "ERROR";
}else{
string binary = get_binary(get_fenshu.first); // 将分子变成二进制形式
int fenmu = get_fenshu.second;
int len = 0;
while(fenmu!=0)
{
fenmu/=2;
len++;
}
len--; // 求出分母需要几位二进制
if(binary.size()==len) // 如果分子的二进制长度和分母相同,那么直接ans加上
{
ans+=binary;
}else{
for(int i=0;i 29、括号
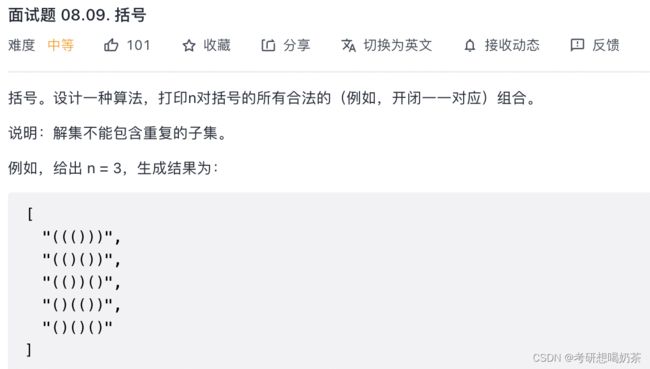
思路:回溯,left表示左括号数’(’,right表示右括号数’)’,
class Solution {
public:
void backtrack(vector& ans, int n, string tmp, int left, int right)
{
if(left>n || left generateParenthesis(int n) {
vector ans;
backtrack(ans, n, "",0 ,0);
return ans;
}
};
30、堆箱子

思路:最长上升子序列的变种。每次的值,可能是当前值,或者是前一个+当前值,两个中的较大值。这样如果前面累加过来值更大,那就不用更换累加起点。
class Solution {
public:
int pileBox(vector>& box) {
if(box.size()==0)
{
return 0;
}
sort(box.begin(), box.end()); // 排序是为了判断w,d,h更有序,从小到大排
vector dp(box.size(), 0);
dp[0] = box[0][2];
for(int i=1;i 31、
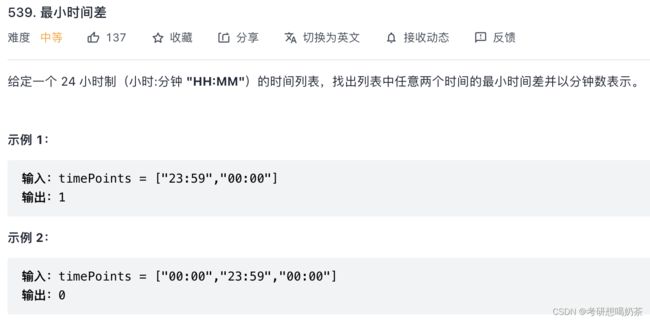
思路:对于一个列表的时间,可以用 小时*60+分钟 来得到一个唯一确定的数;另外考虑到23:59和00:00这样的关系,可以用0+2460再与2360+59比较,这样给较小值多加一天的时间。
class Solution {
public:
int findMinDifference(vector& timePoints) {
int ans=INT_MAX;
vector vec;
for(int i=0;i 32、翻转数位
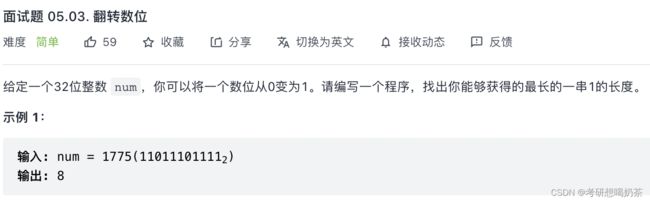
思路:模拟,先把数转换成32位2进制,注意这里可能是负数,因此用bitset<32> bst(num) 实现转换。然后统计32位中,连续1的数量,遇到0则计数停止并加入数组中,然后只要让记录长度的相邻两个元素相加,再加1(表示0变成1),就是连续的一串1,从而得出最长的一串1。
class Solution {
public:
int reverseBits(int num) {
bitset<32> bst(num);
int len=0;
vector vec;
for(int i=0;i 33、硬币
思路:这里是完全背包问题,用dp[k]表示当金额为k的时候,有几种组合情况。事实上,动态规划的转移方程可以是
d p [ i ] = d p [ i ] + d p [ i − c o i n ] dp[i] = dp[i] + dp[i-coin] dp[i]=dp[i]+dp[i−coin]
当前金额,可以有当前金额自己(不取硬币),以及取coin硬币之前的情况,所组合而成。而这里要注意的是,需要先遍历硬币,再进行遍历n种情况,不然会出现重复的现象。
class Solution {
public:
const int M = 1000000007;
int coins[4] = {1, 5, 10, 25};
int waysToChange(int n) {
vector dp(n+1, 0);
dp[0]=1;
for(int i=0;i<4;i++)
{
int coin = coins[i];
for(int j=coin;j<=n;j++)
{
dp[j] = (dp[j]+dp[j-coin]) % M;
}
}
return dp[n];
}
};
34、存在重复元素
思路:如果直接暴力会超时,这里用滑动窗口的做法只遍历一次。先维护一个大小为 k+1 的窗口,判断这个初始窗口里面有没有不同索引的重复元素;然后每次往后遍历一格,将窗口的末尾元素淘汰,将新元素添加进来,每次只要判断新元素是否和窗口内元素有重复即可。
class Solution {
public:
bool containsNearbyDuplicate(vector& nums, int k) {
if(k==0)
{
return false;
}
unordered_map mp; // 这里维护窗口内元素的哈希表
for(int i=0;i<=k;i++) // 初始窗口
{
if(i::iterator iter = mp.find(nums[i-k-1]); // 淘汰窗口的末尾元素
if(iter!=mp.end())
{
mp.erase(iter);
}
if(mp.count(nums[i])==0) // 判断新元素,是否在窗口内有重复的
{
mp[nums[i]]=1;
}else{
return true;
}
}
return false;
}
};
35、无重复字符串的排列组合
思路:这是回溯的模版题,体现回溯的做法。由于这里已经说明是无重复的字符串,不需要考虑存在重复字符的问题。
class Solution {
public:
void backtrack(vector& ans, string tmp, string S, vector vis)
{
if(tmp.size()==S.size()) // 满足长度要求,就是一种排列组合
{
ans.push_back(tmp);
return ;
}
for(int i=0;i permutation(string S) {
vector ans;
vector vis(S.size(), 0);
backtrack(ans, "", S, vis);
return ans;
}
};
36、搜索旋转数组(二分不太会)
思路:这类题目用二分的方法来找,比较合适。因为是有序数组再进行多次旋转,说明一些成段的序列是递增的。
class Solution {
public:
int search(vector& arr, int target) {
int left = 0;
int right = arr.size()-1;
while(left<=right)
{
int mid = (left + right) / 2;
if(arr[left]==target) // 当左边界l对应元素为target时直接返回l,因为题目要求返回最小索引
{
return left;
}else if(arr[left]==arr[mid]) // 说明此时,left-mid中间有两段递增序列,最小值在其中
{
left++;
}else if(arr[left]arr[mid]) // 在右区间
{
left=mid;
}else{
left = left + 1;
right = mid;
}
}else if(arr[left]>arr[mid])
{
if(targetarr[mid]) // 说明在右区间
{
left=mid;
}else{
left = left + 1;
right = mid;
}
}
}
return -1;
}
};
37、八皇后

思路:还是回溯的思想,只是原来简单的vis数组判断是否遍历过,这里要用一个比较复杂的函数,来判断当前位置是否能放皇后。
class Solution {
public:
bool valid(vector& tmp, int row, int col, int n) // 因为当前只放到row行,因此只要判断row前面部分棋盘上Q出现的情况,而不用管row行之后的
{
for(int i=0;i=0&&j>=0;i--,j--) // 判断左上角的对角线有没有Q
{
if(tmp[i][j]=='Q')
{
return false;
}
}
for(int i=row-1, j=col+1;i>=0&&j >& ans, int n, int row, vector& tmp)
{
if(row==n) // 说明已经到最后一行都放完了
{
ans.push_back(tmp);
return ;
}
for(int col=0;col> solveNQueens(int n) {
vector > ans;
string row(n, '.');
vector tmp(n, row); // 先初始化棋盘全是‘.‘
backtrack(ans, n, 0, tmp);
return ans;
}
};
38、稀疏数组搜索

思路:有序数组的搜索,就想到用二分。但是这里其中有空字符串,遇到空字符串,就退化为线性遍历,直到没遇到空串,再恢复二分即可。
class Solution {
public:
int findString(vector& words, string s) {
int left = 0;
int right = words.size()-1;
while(left<=right)
{
int mid = left + (right - left) / 2;
while((mid>left) && (words[mid]=="")) // 移除空字符串
{
mid--;
}
if(words[mid]==s)
{
return mid;
}
if(words[mid]>s)
{
right = mid-1;
}else{
left = mid+1;
}
}
return -1;
}
};
39、石子游戏(看不懂)
思路:博弈论的题目,重点在于将石头价值模3,并且要认识到价值为0不会改变石头总价值的状态。
设x为已移除石头的状态,s为石头价值。

class Solution {
public:
bool stoneGameIX(vector& stones) {
int num[3] = {0, 0, 0};
for(auto val: stones)
{
num[val%3]++; // 价值模3
}
if(num[0]%2==0) // 价值为0的石子数量是2的倍数,那就说明不会改变局面(因为两个人都有机会选)
{
if(num[1]==0) // 当价值为1的石头数量为0,那么A只能选s=2的石头。这样B再选s=2,那么x变为1,此时不管怎么样A都要选s=2(或者没石头可以选),导致输掉。
{
return false;
}else if(num[2]==0) // 同理,因为A先手,因此B再选s=1,会导致x变为2,让A不得不选s=1(或者没石头),导致输掉
{
return false;
}else{ // 如果s=1,s=2数量都不为0,那么A只要选择数量较少的一类石头,就能迫使B选择同类的石头。最终A把数量少的石头取完,留给B的是只能取另一类石头导致总和能整除3。
return true;
}
}else{ // 如果s=0 的数量是奇数,那么双方有一个人能够有换手的机会。
if(abs(num[1] - num[2])<=2) // s=1和s=2的数量差不超过2。A如果此时拿s=0,那么B有机会拿s=1或s=2,然后迫使A始终拿同类石子,因此A不能拿s=0。而A只能拿s=1或s=2,那么B有机会拿s=0,让A继续拿自己一开始的同类石子,最终是A凑成了3的倍数。
{
return false;
}else{ // s=1和s=2的数量差大于2,此时A只要选数量多的一类石子,那么就能迫使B只能选同类石子,然后A继续拿这一类石子去抵消(因为差值大于2,总有抵消的机会),最终要么没石头了,要么只能取另一类
return true;
}
}
}
};
40、跳跃游戏

思路:一开始直接用dfs做,导致超时。参考题解,用bfs,并用完后删除实现剪枝。
class Solution {
public:
unordered_map > idxSameValue;
int minJumps(vector& arr) {
if(arr.size()==0)
{
return 0;
}
for(int i=0;i > q;
vector vis(arr.size(), 0); // 访问数组
q.push(make_pair(0,0));
vis[0]=1;
while(q.size()!=0)
{
auto [idx, num] = q.front();
q.pop();
if(idx==arr.size()-1)
{
return num;
}
num++;
int v = arr[idx];
if(idxSameValue.count(v)!=0)
{
for(auto &i : idxSameValue[v]) // 这里将和v相同值的索引,全部放入队列中,这样一次都访问完,然后就可以删除掉;避免后面再访问
{
vis[i]=1;
q.push(make_pair(i, num));
}
idxSameValue.erase(v); // 最关键的一步,要删除用过的值。
}
if(idx+1=0&&vis[idx-1]==0)
{
vis[idx-1]=1;
q.push(make_pair(idx-1, num));
}
}
return -1;
}
};
41、删除回文子序列

思路:注意题目的两个要点,1)回文子序列,也就是说可以不连续;2)字符串只有a,b。那其实就两种可能性,如果这个字符串本身就是回文的,那直接一次性删除,返回1;如果不是回文的,那就所有a一起删除,留下的只有b,再删一次,总共2次。
class Solution {
public:
int removePalindromeSub(string s) {
for(int i=0, j=s.size()-1;i42、有重复字符串的排列组合
思路:因为有重复字符,因此全排列组合可能出现重复的排列情况。这里先对字符串排序,这样重复字符必定相邻,然后在回溯的过程中判断一下重复字符有没有被使用,如果使用过了就不再加入。这样避免使用set。
class Solution {
public:
void backtrack(vector& ans, string S, string tmp, vector vis)
{
if(tmp.size()==S.size())
{
ans.push_back(tmp);
return ;
}
for(int i=0;i0&&S[i]==S[i-1]&&vis[i-1]!=0)
{
continue;
}
vis[i]=1;
tmp+=S[i];
backtrack(ans, S, tmp, vis);
tmp.erase(tmp.size()-1, 1);
vis[i]=0;
}
}
}
vector permutation(string S) {
vector ans;
vector vis(S.size(), 0);
sort(S.begin(), S.end());
backtrack(ans, S, "", vis);
return ans;
}
};
43、到达目的地的第二短时间(超时)

思路:由于这里每条边的用时都是一样的,视为无权,所以可以计算达到终点经过几条边,最后再计算时间。又因为题目要求第二短时间,因此在求完最短路径后,再求第二短路径。用dfs会超时。
class Solution {
public:
int secondMinimum(int n, vector>& edges, int time, int change) {
vector> graph(n + 1); // 先转化为邻接表
for (auto &e : edges) {
graph[e[0]].push_back(e[1]);
graph[e[1]].push_back(e[0]);
}
// path[i][0] 表示从 1 到 i 的最短路长度,path[i][1] 表示从 1 到 i 的严格次短路长度
vector> path(n + 1, vector(2, INT_MAX));
path[1][0] = 0;
queue> q;
q.push({1, 0});
while (path[n][1] == INT_MAX) { // 这里不要用q.size()!=0,因为只要找到第二短路径即可,不然会超时。因为图是双向的,可以重复访问。
auto [cur, len] = q.front();
q.pop();
for (auto next : graph[cur]) {
if (len + 1 < path[next][0]) {
path[next][0] = len + 1; // 更新最短路径长度
q.push({next, len + 1});
} else if (len + 1 > path[next][0] && len + 1 < path[next][1]) { // 写入第二短路径长度
path[next][1] = len + 1;
q.push({next, len + 1});
}
}
}
int ret = 0;
for (int i = 0; i < path[n][1]; i++) {
//经过 (2 * change) 灯由绿灯变成绿灯,并且维持 change 秒
//如果 ret 不在该范围到达,就无法到达后立即出发,需要等红灯
//等待时间为,一个 (2 * change) 周期,减去 到达时间
if (ret % (2 * change) >= change) {
ret = ret + (2 * change - ret % (2 * change));
}
ret = ret + time;
}
return ret;
}
};
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/second-minimum-time-to-reach-destination/solution/dao-da-mu-de-di-de-di-er-duan-shi-jian-b-05i0/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
44、最长快乐字符串
思路:贪心(不要想着两个字母一起加,是一个一个加)
1)每次使用当前数量最多的字母,先把这个字母用完;
2)如果当前字母数量连续到达3个,那么就跳过,选用另一个字母;
3)尝试所有的字母都无法添加时跳出循环。
class Solution {
public:
string longestDiverseString(int a, int b, int c) {
string res;
vector> arr = {{a, 'a'}, {b, 'b'}, {c, 'c'}};
while (true) {
sort(arr.begin(), arr.end(), [](const pair & p1, const pair & p2) {
return p1.first > p2.first; // 按照字母数量多少进行排序
});
bool hasNext = false;
for (auto & [freq, ch] : arr) {
int m = res.size();
if (freq <= 0) {
break;
}
if (m >= 2 && res[m - 2] == ch && res[m - 1] == ch) { // 连续两个字母和当前字母一样,则跳过,到下一个字母
continue;
}
hasNext = true; // 表示有下个字母可以添加
res.push_back(ch);
freq--;
break;
}
if (!hasNext) { // 没有字母添加则跳出循环
break;
}
}
return res;
}
};
45、峰与谷

思路1:简单的想法就是先将数组排序,然后一次取最大值,一次取最小值,构成了峰、谷、峰、谷。。。这样的序列。(这需要借助额外的空间)
思路2:采用局部峰、谷的思想,每次都维护局部峰、谷的顺序成立,当新加入的数字只需和前一个数字进行判断即可。
例如:[3,5,2,1,6,4],现在维护一个谷、峰、谷、峰这样的数组。
1)先看3,则当前是[3],满足条件;
2)再看5,现在的位置应该是峰,并且5>3,符合条件,因此加入[5,3];
3)遍历到2,现在的位置应该是谷,2<3,符合条件,因此[5,3,2];
4)遍历到1,现在的位置是峰,但是1<2,不符合条件,同时又由于前面的数组是满足局部谷峰关系的,必然nums[i-2]>nums[i-1],也必然nums[i-2]>nums[i-1]>num[i],因此只要交换nums[i-1]和nums[i]的位置,就能满足条件,得到[5,3,1,2];
5)后面也是如此比较。
class Solution {
public:
void wiggleSort(vector& nums) {
if(nums.size()<=2)
{
return ;
}
for(int i=1;inums[i-1])
{
swap(nums[i], nums[i-1]);
}
}
}
}
};
46、阶乘尾数(不会)
思路:要想最后尾数为0,数字尾随零等于数字可以被10整除,而2 * 5=10,2的个数肯定多于5的个数,因此只需统计5的个数。
class Solution {
public int trailingZeroes(int n) {
/*
0 是由 *10 得到的,而 10 是由 2 * 5 得到的
因此我们求 n! 过程中存在多少个 2 * 5
因为 2 的个数必定比 5 的个数多,因此我们只求 5 的个数
如果直接一个一个遍历,即
for(int i = 5; i <= n; i++){
int temp = i;
while(temp % 5 == 0){
count++;
temp /= 5;
}
}
那么 n 过大时,从 1 遍历到 n, 那么会超时,因此我们修改下规律
n! = 1 * 2 * 3 * 4 * (1 * 5) * ... * (2 * 5) * ... * (3 * 5) ...
我们发现,
每隔 5 个数就会出现 一个 5,因此我们只需要通过 n / 5 来计算存在存在多少个 5 个数,那么就对应的存在多少个 5
但是,我们也会发现
每隔 25 个数会出现 一个 25, 而 25 存在 两个 5,我们上面只计算了 25 的一个 5,因此我们需要 n / 25 来计算存在多少个 25,加上它遗漏的 5
同时,我们还会发现
每隔 125 个数会出现一个 125,而 125 存在 三个 5,我们上面只计算了 125 的两个 5,因此我们需要 n / 125 来计算存在多少个 125,加上它遗漏的 5
...
因此我们 count = n / 5 + n / 25 + n / 125 + ...
最终分母可能过大溢出,上面的式子可以进行转换
count = n / 5 + n / 5 / 5 + n / 5 / 5 / 5 + ...
因此,我们这样进行循环
n /= 5;
count += n;
这样,第一次加上的就是 每隔 5 个数的 5 的个数,第二次加上的就是 每隔 25 个数的 5 的个数 ...
*/
int count = 0;
while(n >= 5){
n /= 5;
count += n; // 说明此时有n个5
}
return count;
}
}
47、BiNode

思路:已知原树是二叉搜索树,因此中序遍历必然是有序序列,即可根据中序遍历来构造成单向列表。又因为题目要求在原地修改,因此在遍历中修改左、右子树。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* head = new TreeNode(-1);
TreeNode* prev = NULL; // 记录前一个节点
void midorder(TreeNode* root)
{
if(root!=NULL)
{
midorder(root->left);
if(prev==NULL) // 此时还没有前节点
{
prev = root; // 将根节点作为前节点
head->right = root; // 头节点的右节点变为根
}else{
prev->right = root; // 对于当前根节点来说,要成为前一个节点的右孩子
prev = root; // 自己变成了前节点
}
root->left = NULL;
midorder(root->right);
}
}
TreeNode* convertBiNode(TreeNode* root) {
midorder(root);
return head->right;
}
};
48、恢复空格(超时)

思路:使用动态规划。
dp[i]表示前 i 个字符中无法识别的字符个数。
从前往后遍历sentence的每个位置 i ,然后从后往前数dic_len个字符,看看是否出现在字典中,如果出现,那么dp[i]=dp[i-dic_len];
如果没有出现在字典中,那么dp[i]=dp[i-1]+1。
class Solution {
public:
int respace(vector& dictionary, string sentence) {
int len = sentence.size();
vector dp(len+1, 0); //dp[i]表示sentence前i个字符里面未识别的字符数
dp[0]=0;
for(int i=1;i<=len;i++)
{
dp[i]=dp[i-1]+1;
for(int j=0;j 49、模式匹配
思路:根据pattern和value的不同情况,进行分类讨论。
class Solution {
public:
int cnt[2]={0,0};
bool helper(string value, int k)
{
int m = value.size();
if(m%k!=0)
return false;
int len = m / k;
for (int i = len; i < m; i += len)
if (value.substr(i, len) != value.substr(0, len)) return false;
return true;
}
bool check(string pattern, string value, int len_a, int len_b)
{
string ps[2]={"",""}; // 分别记录a,b所表示的字符串
int j=0; // 记录当前遍历value的位置
for(int i=0;i50、最小k个数

思路1:直接排序后取k个数
思路2:构建堆,维护k个最小数的堆,再遍历数组,每次和堆顶数比较。
class Solution {
public:
vector smallestK(vector& arr, int k) {
vector vec(k, 0);
if (k == 0) { // 排除 0 的情况
return vec;
}
priority_queue Q;
for (int i = 0; i < k; ++i) {
Q.push(arr[i]);
}
for (int i = k; i < (int)arr.size(); ++i) {
if (Q.top() > arr[i]) {
Q.pop();
Q.push(arr[i]);
}
}
for (int i = 0; i < k; ++i) {
vec[i] = Q.top();
Q.pop();
}
return vec;
}
};