手搓Lenet的keras实现
本文基于的开发环境介绍:
经典的lenet网络结构:

代码:
import keras
from keras.models import Sequential
from keras.layers import Input,Dense,Activation,Conv2D,MaxPooling2D,Flatten
from keras.datasets import mnist
(x_train,y_train),(x_test,y_test) = mnist.load_data()
x_train = x_train.reshape(-1, 28, 28, 1) #######
x_train = x_train.astype("float32")
print(x_train.shape)
y_train = y_train.astype("float32")
x_test = x_test.reshape(-1,28,28,1)
x_test = x_test.astype("float32")
y_test = y_test.astype("float32")
print(y_train)
x_train /= 255
x_test /= 255
from keras.utils import np_utils
y_train_new = np_utils.to_categorical(num_classes=10,y=y_train)
print(y_train_new)
y_test_new = np_utils.to_categorical(num_classes=10,y=y_test)
def LeNet_5():
model = Sequential()
model.add(Conv2D(filters=6,kernel_size=(5,5),padding="valid",activation="tanh",input_shape=[28, 28, 1]))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=16,kernel_size=(5,5),padding="valid",activation="tanh"))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(120,activation="tanh"))
model.add(Dense(84,activation="tanh"))
model.add(Dense(10,activation="softmax"))
return model
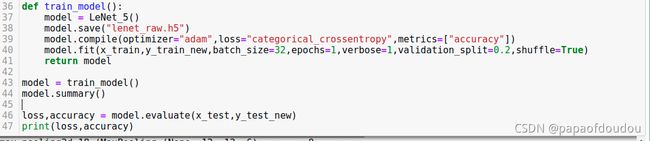
def train_model():
model = LeNet_5()
model.compile(optimizer="adam",loss="categorical_crossentropy",metrics=["accuracy"])
model.fit(x_train,y_train_new,batch_size=32,epochs=1,verbose=1,validation_split=0.2,shuffle=True)
return model
model = train_model()
model.summary()
loss,accuracy = model.evaluate(x_test,y_test_new)
print(loss,accuracy)这里的padding表示补0策略,有“valid”和“same” 。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同。默认是valid,但是考虑到几层卷积下来,可能卷积连接有问题,一般会用same,这里用的valid.
运行结果:
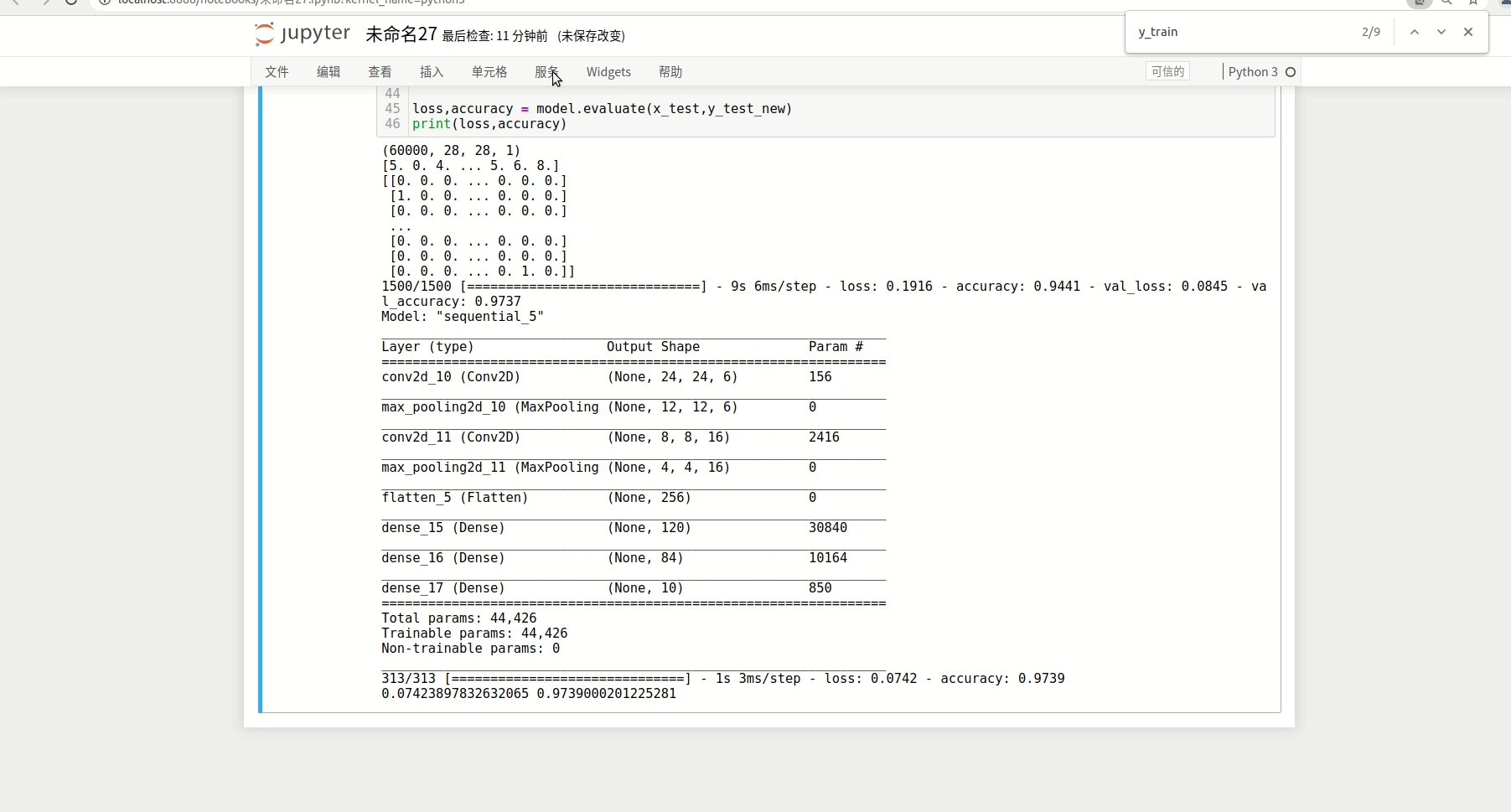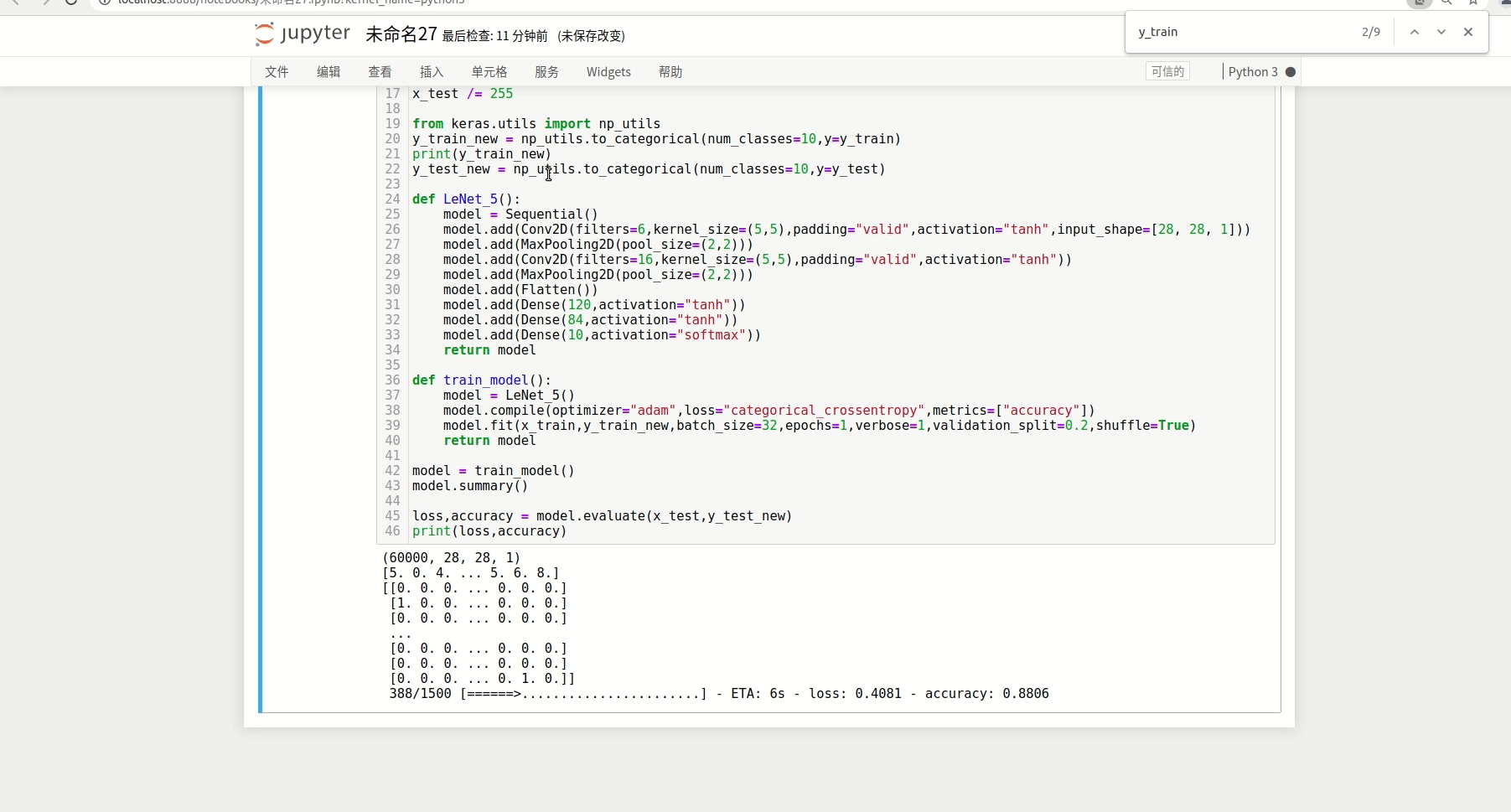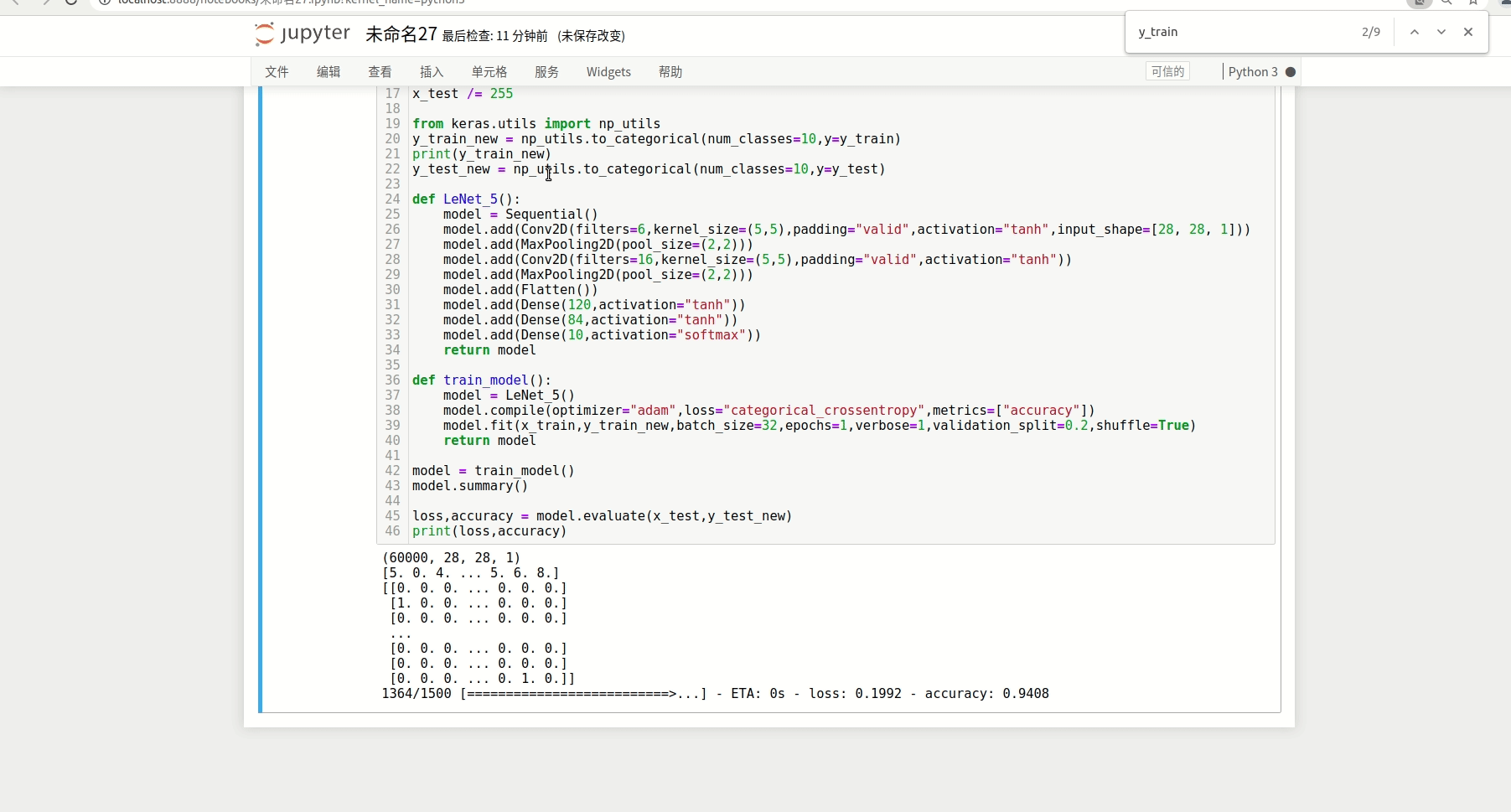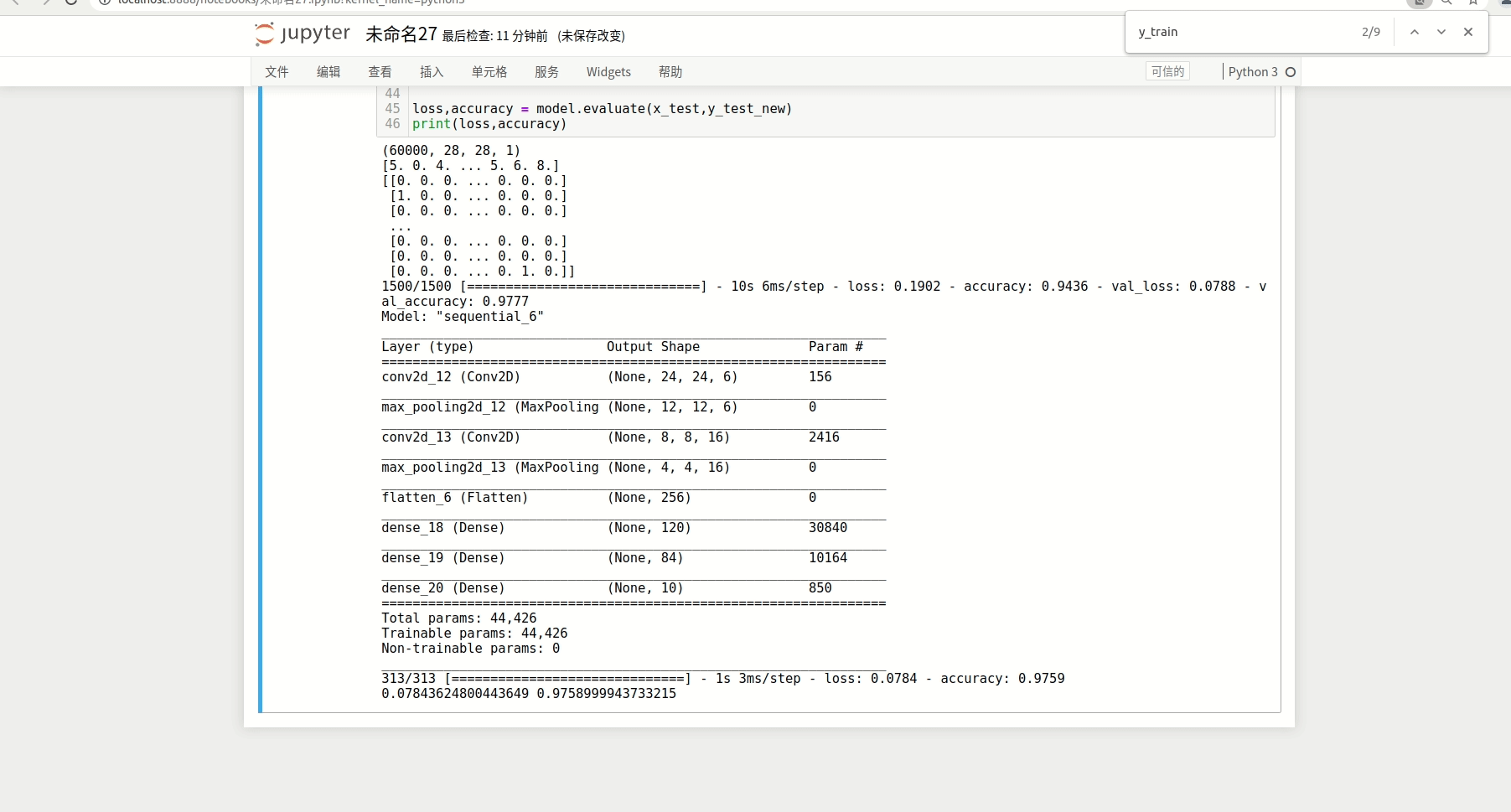
最终输出,可以看到lenet 每层的参数情况:
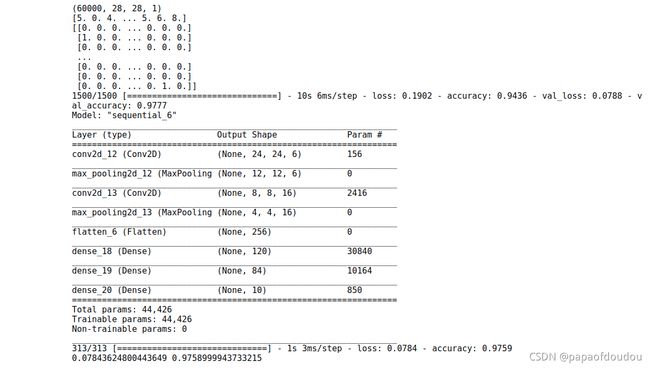
调整EPOCHES再次训练,得到精度更高的模型:

epochs代表要把整个训练样本迭代6次,batch size参数表示一次训练中取32条数据进行训练。
32*1500=48000,表示使用到的训练数据集大小。
训练完成后,我们验证模型的推理能力,代码如下:
import numpy as np
import tensorflow as tf
demo = tf.reshape(x_test[9],(-1,28,28,1))
print(np.argmax(model.predict(demo)))
参数推算:
当输入含有多个通道时,对应的卷积核也应该有相同的通道数。假设输入图片的通道数为CinCin,输入数据的形状是![]()
-
对每个通道分别设计一个2维数组作为卷积核,卷积核数组的形状是
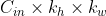 。
。 -
对任一通道
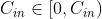 ,分别用大小为
,分别用大小为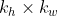 的卷积核在大小为
的卷积核在大小为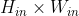 的二维数组上做卷积。
的二维数组上做卷积。 -
将这
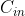 个通道的计算结果相加,得到的是一个形状为
个通道的计算结果相加,得到的是一个形状为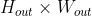 的二维数组。
的二维数组。
根据网络结构计算各层参数:
第一层: 5*5卷积核6个,所以权重数为5*5*6=150个,一个核对应一个通道, 每个通道一个偏置,所以共有6个bias参数,所以,第一个卷积层的参数个数为150+6=156个,pegasus统计没有包括bias,只包括卷积核,所以为150个。計算公式為:
![]()

第二层,池化层没有参数,所以参数个数为0个。
第三层,卷积层,卷积核为16个5*5,但是由于上一层的卷积核个数等于上层输出的feature map通道数,可以得知第二层输入的feature map为6通道,所以实际上的卷积核shape为 16个5*5*6大小,也就是16*5*5*6=2400个参数。再加上16个bias,总共2416个参数。
第四层是池化层,没有参数.
第五层是降维层,二维降1维,没有参数。
第六层是全连接层FC,参数个数为256*120+ 120= 30840
第七层是全连接层FC:参数个数为120*84+84=10164
第八层是全连接层FC: 参数个数是840*10+10=850
DUMP各层信息:
print(model.layers[0].name)
print(model.layers[1].name)
print(model.layers[2].name)
print(model.layers[3].name)
print(model.layers[4].name)
print(model.layers[5].name)
print(model.layers[6].name)
print(model.layers[7].name)
可以看到各层的名称成功获取到了。
之后获取层的参数,以第一层为例:
weights, biases = model.layers[0].get_weights()
print(weights)
print(biases)![]()

然后是BIAS,果然有6个,然后卷积核是训练出来的,并非是设计出来的。

网络的拓扑结构为:
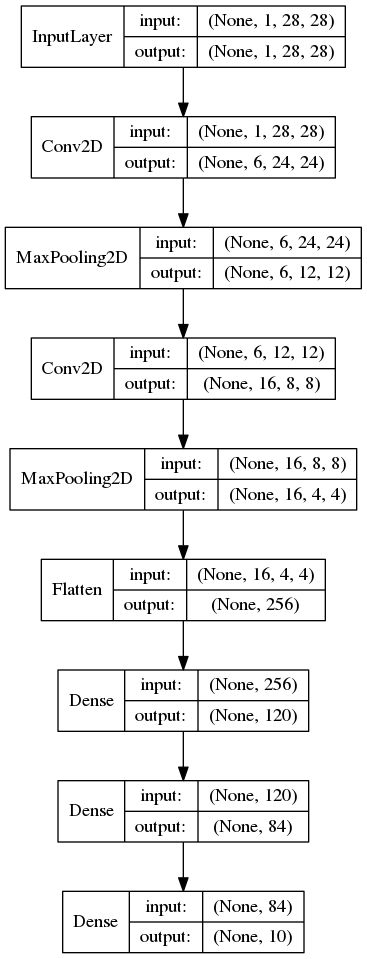
保存模型:
jupter中新添加代码块:
![]()
编辑代码:
model.save("lenet.h5")
model.save_weights("lenet_weight.h5")
运行后,生成两个文件 lenet.h5和lenet_weight.h5
save()保存的模型结果,它既保持了模型的图结构,又保存了模型的参数,而save_weights它只保存了模型的参数,但并没有保存模型的图结构。所以它的size也要比lenet.h5小很多。

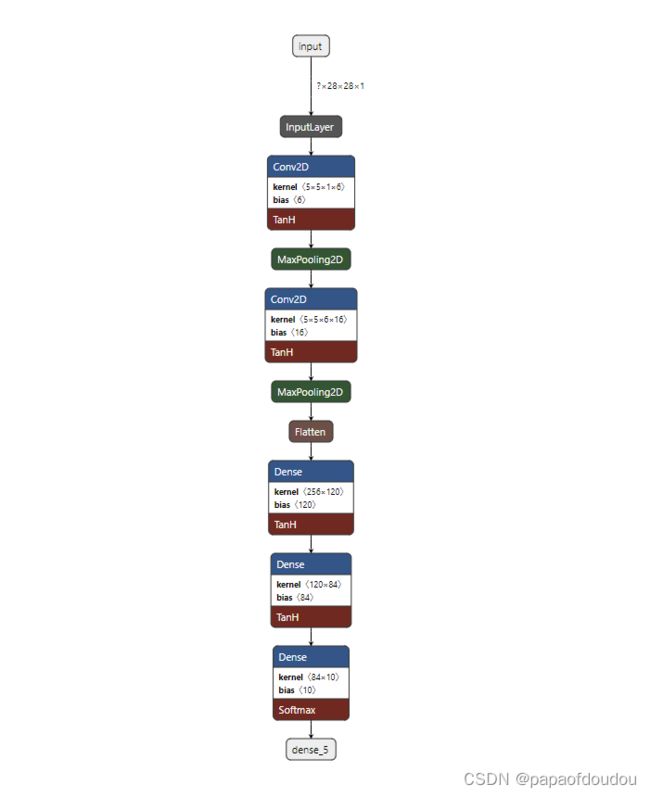
netron查看lenet.h5:
netron原生支持.h5格式的网络模型文件,用netron打开lenet.h5,可以看到网络结构如下:
还可以保存未训练前的网络,比如在下面加入的保存lenet_raw.h5的语句:

lenet_raw.h5它保存了模型的图结构,但应该没有保存模型的初始化参数,所以也要比lenet.h5小一些。
查看模型内容:
模型为 Hierarchical Data Format (version 5) data个格式,可以通过工具查看内容。
ubuntu下安装hdfview可以查看保存模型的内容,ubuntu安装方式直接 sudo apt install hdfview即可. 经测试,UBUNTU版本的hdfview打不开对应的文件,不得已切换为windows10系统,下载下图对应版本的工具


可以看到,工具下,模型结构一目了然。
转ONNX
首先执行sudo pip3 install keras2onnx, sudo pip3 install onnxmltools安装转换包

另一种方式:
上面使用CNN网络实现了mnist数据集的分类网络,其实除了CNN,RNN循环神经网络也可以实现同样算法,LSTM是RNN的一种算法, 在序列分类中比较有用。常用于语音识别,文字处理(NLP)等领域。 等同于VGG等CNN模型在在图像识别领域的位置。
LSTM模型网络结构相对更加复杂,下面是一个lstm_mnist网络的例子,用netron分析结构如下,是不是比上面CNN的复杂好多?
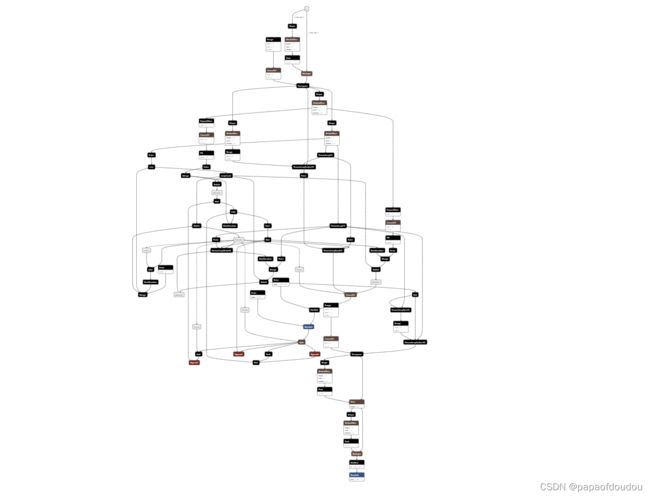
具体参考下篇文章:
用LSTM分类 MNIST - hylas - 博客园
FAQS:
if you encunter issues below, may be you have a wrong protobuf version.

as follows protobuf:
![]()
you can try down grade protbuf versions as below:
pip install protobuf~=3.19.0
pip install six~=1.15.0
pip installtyping-extensions~=3.7.4this would be fine!