Flink State状态机制
Flink State状态机制
1.Flink State状态简介
有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。
SparkStreaming在状态管理这块做的不好,很多时候需要借助于外部存储(例如Redis)来手动管理状态。
1-1.Flink状态State是什么
在流式计算中有些操作一次处理一个独立的事件( 比如解析一个事件 ),有些操作却需要记住多个事件的信息( 比如窗口操作 )。那些需要记住多个事件信息的操作就是有状态的。
在流计算场景中数据没有边界,源源不断的流入,每条数据流入都可能会触发计算,例如count或sum是选择每次触发计算将所有流入的历史数据重新计算,还是选择每次都基于上次计算结果进行增量计算。 从综合考虑角度,很多人都会选择增量计算,但上一次的中间计算结果保存在哪里是一个问题。
在flink中提出了state用来存放计算过程的中间结果或元数据等,并提供Exactly-Once语义,而这些state数据在计算过程中会进行持久化。state就变成了与时间相关的是对flink任务内部数据的快照。
由于流计算大多数场景下都是增量计算的,数据逐条被处理,每次当前结果都是基于上一次计算结果之上进行处理,这也势必要将上一次的计算结果进行存储持久化,无论是机器,网络,脏数据等原因导致的程序错误,都能在job进行任务恢复时提供支持。基于这些已被持久化的state,而非将历史的数据重新计算一遍流式计算分为无状态计算和有状态计算两种情况。
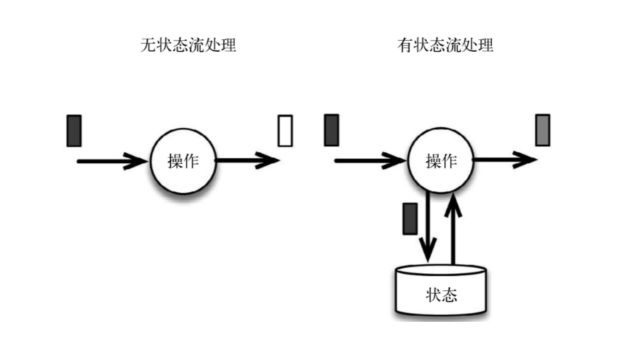
无状态的计算观察每个独立事件,并根据最后一个事件输出结果。例如,流处理应用程序从传感器接收水位数据,并在水位超过指定高度时发出警告。
有状态的计算则会基于多个事件输出结果。
有状态计算例子:
-
计算过去一小时的平均水位,就是有状态的计算。所有用于复杂事件处理的状态机。
-
在一分钟内收到两个相差20cm以上的水位差读数,则发出警告,这是有状态的计算。
流与流之间的所有关联操作,以及流与静态表或动态表之间的关联操作,都是有状态的计算。
1-2.状态管理的用途

- 去重
- 数据流中的数据有重复,我们想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入过的数据来判断去重。
- 检测
- 记录历史数据,检查输入流是否符合某个历史特定的模式,需要将之前流入的元素以状态的形式缓存下来。
- 聚合
- 窗口计算,对一个时间窗口内的数据进行聚合分析
- 更新机器学习模型
- 在线机器学习场景下,需要根据新流入数据不断更新机器学习的模型参数
1-3.Flink中的状态分类
Flink包括两种基本类型的状态
- Managed State 托管状态
- Raw State 原始状态
| Managed State - 托管状态 | Raw State - 原始状态 | |
|---|---|---|
| 状态管理方式 | Flink Runtime托管,自动存储,自动恢复,自动伸缩 | 用户自己管理 |
| 状态数据结构 | Flink提供多种常用数据结构,例如:ListState, MapState等等 | 字节数组: byte[] |
| 使用场景 | 绝大数Flink算子 | 所有算子 |
托管状态是由Flink框架管理的状态,而原始状态,由用户自行管理状态具体的数据结构,框架在做checkpoint的时候,使用byte[]来读写状态内容,对其内部数据结构一无所知。通常在DataStream上的状态推荐使用托管的状态,当实现一个用户自定义的operator时,会使用到原始状态
注意:
从具体使用场景来说,绝大多数的算子都可以通过继承Rich函数类或其他提供好的接口类,在里面使用Managed State Raw State一般是在已有算子和Managed State不够用时,用户自定义算子时使用
1-4.Managed State托管状态分类
Managed State又分2种类型
- Operator State( 算子状态 ) - 记录每个Task对应的状态值数据类型
- Keyed State( 键控状态 ) - 记录每个Key对应的状态值
| Operator State 算子状态 | Keyed State 键控状态 | |
|---|---|---|
| 适用用算子类型 | 可用于所有算子: 常用于source,sink | 只能用于用于KeyedStream上的算子 |
| 状态分配 | 一个算子的子任务对应一个状态 | 一个Key对应一个State: 一个算子会处理多个Key, 则访问相应的多个State |
| 创建和访问方式 | 实现CheckpointedFunction接口 | 重写RichFunction, 通过里面的RuntimeContext访问 |
| 横向扩展 | 并发改变时有多重重写分配方式可选: 均匀分配和合并后每个得到全量 | 并发改变, State随着Key在实例间迁移 |
| 支持的数据结构 | ListState, UnionListStste, BroadCastState |
ValueState, ListState, MapState ReduceState, AggregatingState |
2.Flink State状态算子介绍及示例
2-1.算子状态介绍
Operator State算子状态可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态
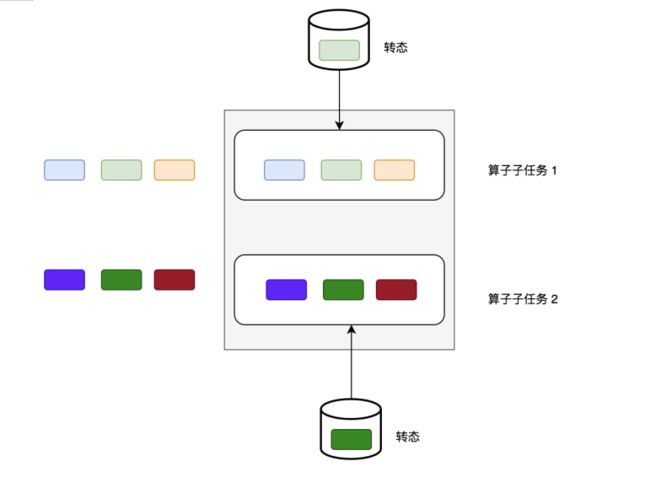
注意: 算子子任务之间的状态不能互相访问
算子状态的作用范围限定为算子任务。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。算子状态不能由相同或不同算子的另一个任务访问
Operator State的实际应用场景不如Keyed State多,它经常被用在Source或Sink等算子上,用来保存流入数据的偏移量或对输出数据做缓存,以保证Flink应用的Exactly-Once语义。
Flink为算子状态提供三种基本数据结构:
-
列表状态( List state )
将状态表示为一组数据的列表例如Flink中的Kafka Connector,使用了operator state算子状态。它会在每个connector实例中,保存该实例中消费topic的所有( partition, offset )映射
-
联合列表状态( Union list state )
也是将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。
列表状态( List state )是均匀分配,而联合列表状态( Union list state )是将所有 State 合并为全量 State 再分发给每个实例(Union list state) -
广播状态(Broadcast state)
是一种特殊的算子状态,如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
2-2.列表状态示例
列表状态( List state )代码示例:
package com.zenitera.bigdata.state;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 列表状态( List state )
* 将状态表示为一组数据的列表
* getListState
*/
public class Flink01_State_Operator_List {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 2000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(2);
// 开启checkpoint
env.enableCheckpointing(2000);
env
.socketTextStream("localhost", 6666)
.map(new MyMapFunction())
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
private static class MyMapFunction implements MapFunction<String, String>, CheckpointedFunction {
List<String> words = new ArrayList<>();
private ListState<String> wordsState;
@Override
public String map(String line) {
if (line.contains("exit")) {
throw new RuntimeException("异常");
}
String[] data = line.split(" ");
words.addAll(Arrays.asList(data));
return words.toString();
}
@Override
public void snapshotState(FunctionSnapshotContext ctx) throws Exception {
wordsState.update(words);
}
@Override
public void initializeState(FunctionInitializationContext ctx) throws Exception {
wordsState = ctx.getOperatorStateStore().getListState(new ListStateDescriptor<>("wordsState", String.class));
Iterable<String> it = wordsState.get();
for (String word : it) {
words.add(word);
}
}
}
}
/*
D:\BaiduNetdiskDownload\3.安装包\netcat-win32-1.12>nc64.exe -lp 6666
aaa bbb ccc
ddd
fff
ggg
ppp exit
D:\BaiduNetdiskDownload\3.安装包\netcat-win32-1.12>nc64.exe -lp 6666
zzz
exit
D:\BaiduNetdiskDownload\3.安装包\netcat-win32-1.12>nc64.exe -lp 6666
qqq
mmmmmm
--------------------------------------------------------
2> [aaa, bbb, ccc]
1> [ddd]
2> [aaa, bbb, ccc, fff]
1> [ddd, ggg]
2> [aaa, bbb, ccc, fff, zzz]
2> [aaa, bbb, ccc, fff, zzz, qqq]
1> [ddd, ggg, mmmmmm]
*/
联合列表状态( Union list state )代码示例:
package com.zenitera.bigdata.state;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
/**
* 联合列表状态( Union list state )
* 也是将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复
* getUnionListState
*/
public class Flink01_State_Operator_UnionList {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 2000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(2);
// 开启checkpoint
env.enableCheckpointing(2000);
env
.socketTextStream("localhost", 6666)
.map(new MyMapFunction())
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
public static class MyMapFunction implements MapFunction<String, String>, CheckpointedFunction {
List<String> words = new ArrayList<>();
private ListState<String> wordsState;
@Override
public String map(String line) throws Exception {
if (line.contains("exit")) {
throw new RuntimeException("异常");
}
String[] data = line.split(" ");
words.addAll(Arrays.asList(data));
return words.toString();
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
wordsState.update(words);
}
@Override
public void initializeState(FunctionInitializationContext ctx) throws Exception {
wordsState = ctx.getOperatorStateStore().getUnionListState(new ListStateDescriptor<String>("wordsState", String.class));
Iterable<String> it = wordsState.get();
for (String word : it) {
words.add(word);
}
}
}
}
/*
D:\BaiduNetdiskDownload\3.安装包\netcat-win32-1.12>nc64.exe -lp 6666
aaa bbb ccc
ddd
exit
D:\BaiduNetdiskDownload\3.安装包\netcat-win32-1.12>nc64.exe -lp 6666
ggg
ppp aaaa
exit
D:\BaiduNetdiskDownload\3.安装包\netcat-win32-1.12>nc64.exe -lp 6666
zzz
-------------------------------------------
1> [aaa, bbb, ccc]
2> [ddd]
2> [ddd, aaa, bbb, ccc, ggg]
1> [ddd, aaa, bbb, ccc, ppp, aaaa]
1> [ddd, aaa, bbb, ccc, ggg, ddd, aaa, bbb, ccc, ppp, aaaa, zzz]
*/
2-3.广播状态示例
广播状态( Broadcast state )代码示例:
package com.zenitera.bigdata.state;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.util.Collector;
/**
* 广播状态(Broadcast state)
* getBroadcastState
*/
public class Flink01_State_Operator_BroadCast {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 2000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(2);
env.enableCheckpointing(2000);
DataStreamSource<String> dataStream = env.socketTextStream("localhost", 6666);
DataStreamSource<String> configStream = env.socketTextStream("localhost", 7777);
MapStateDescriptor<String, String> bcStateDesc = new MapStateDescriptor<>("bcState", String.class, String.class);
BroadcastStream<String> bcStream = configStream.broadcast(bcStateDesc);
BroadcastConnectedStream<String, String> connectedStream = dataStream.connect(bcStream);
connectedStream
.process(new BroadcastProcessFunction<String, String, String>() {
@Override
public void processElement(String value,
ReadOnlyContext ctx,
Collector<String> out) throws Exception {
ReadOnlyBroadcastState<String, String> state = ctx.getBroadcastState(bcStateDesc);
String conf = state.get("switch");
if ("start".equals(conf)) {
out.collect(value + " 启动");
} else if ("stop".equals(conf)) {
out.collect(value + " 停止");
} else if ("restart".equals(conf)) {
out.collect(value + " 重启");
} else {
out.collect(value + " 默认info");
}
}
@Override
public void processBroadcastElement(String value,
Context ctx,
Collector<String> out) throws Exception {
BroadcastState<String, String> state = ctx.getBroadcastState(bcStateDesc);
state.put("switch", value);
}
})
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
3.Flink键控状态的使用及示例
3-1.键控状态介绍
键控状态是根据输入数据流中定义的键(key)来维护和访问的。
Flink为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。因此,具有相同key的所有数据都会访问相同的状态。
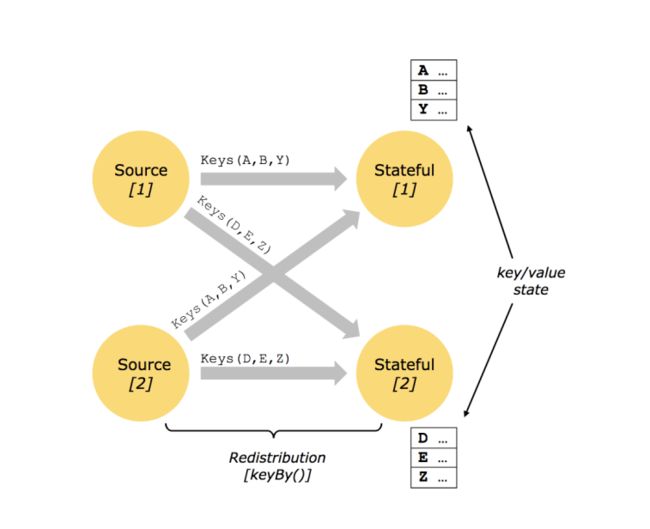
Keyed State很类似于一个分布式的key-value map数据结构,只能用于KeyedStream(keyBy算子处理之后)。

3-2.键控状态支持的数据类型
-
ValueState
-
类型为T的单值状态,保存单个值,每个key有一个状态值,这个状态与对应的key绑定。设置使用 update(T),获取使用 T value()
-
// get操作 ValueState.value() // set操作 ValueState.update(value: T)
-
-
ListState
-
保存元素列表,key上的状态值为一个列表
-
// 附加操作 ListState.add(value: T) ListState.addAll(values: java.util.List[T]) // get操作 ListState.get() // set操作 ListState.update(values: java.util.List[T])
-
-
ReducingState
- 存储单个值,表示把所有元素的聚合结果添加到状态中。与ListState类似,但当使用add(T)的时候ReducingState会使用指定的ReduceFunction进行聚合,最后再合并到一个单一的状态值。
-
AggregatingState
- 存储单个值,与ReducingState类似,都是进行聚合。不同的是, AggregatingState的聚合的结果和元素类型可以不一样
-
MapState
-
存储键值对列表,状态值为一个map。用户通过put或putAll方法添加元素
-
添加键值对: put(UK, UV) or putAll(Map
-
根据key获取值: get(UK)
-
获取所有: entries(), keys() and values()
-
检测是否为空: isEmpty()
-
MapState.get(key: K) MapState.put(key: K, value: V) MapState.contains(key: K) MapState.remove(key: K)
-
注意:
- 所有的类型都有clear(), 清空当前key的状态
- 这些状态对象仅用于用户与状态进行交互
- 从状态获取的值与输入元素的key相关
- 以上所述的State对象,仅仅用于与状态进行交互(更新、删除、清空等),而真正的状态值,有可能是存在内存、磁盘、或者其他分布式存储系统中。相当于我们只是持有了这个状态的句柄(state handle)
3-3.键控状态示例-ValueState
代码示例:
package com.zenitera.bigdata.state;
import com.zenitera.bigdata.bean.WaterSensor;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
/**
* ValueState
*
*/
public class Flink02_State_Key_ValueState {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 2000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
env
.socketTextStream("localhost", 6666)
.map(line -> {
String[] data = line.split(",");
return new WaterSensor(
String.valueOf(data[0]),
Long.valueOf(data[1]),
Integer.valueOf(data[2])
);
})
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
private ValueState<Integer> lastVcState;
@Override
public void open(Configuration parameters) throws Exception {
lastVcState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("lastVcState", Integer.class));
}
@Override
public void processElement(WaterSensor value,
Context ctx,
Collector<String> out) throws Exception {
Integer lastVc = lastVcState.value();
System.out.println(lastVc);
if (lastVc != null) {
System.out.println(lastVc + " " + value.getVc());
if (value.getVc() > 10 && lastVc > 10) {
out.collect(ctx.getCurrentKey() + " to High! ++10 ");
}
}
lastVcState.update(value.getVc());
}
})
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/*
D:\netcat-win32-1.12>nc64.exe -lp 6666
s1,1,3
s1,1,9
s1,1,10
s1,1,12
s1,1,14
s1,1,15
s1,1,2
s1,1,100
s1,1,3
s1,1,100
s1,1,100
-----------------------------------------
null
3
3 9
9
9 10
10
10 12
12
12 14
s1 to High! ++10
14
14 15
s1 to High! ++10
15
15 2
2
2 100
100
100 3
3
3 100
100
100 100
s1 to High! ++10
*/
3-4.键控状态示例-ListState
代码示例:
package com.zenitera.bigdata.state;
import com.zenitera.bigdata.bean.WaterSensor;
import com.zenitera.bigdata.util.BigdataUtil;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.util.Comparator;
import java.util.List;
/**
* ListState
*
*/
public class Flink02_State_Key_ListState {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 2000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
env
.socketTextStream("localhost", 6666)
.map(line -> {
String[] data = line.split(",");
return new WaterSensor(
String.valueOf(data[0]),
Long.valueOf(data[1]),
Integer.valueOf(data[2])
);
})
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
private ListState<Integer> top3VcState;
@Override
public void open(Configuration parameters) throws Exception {
top3VcState = getRuntimeContext().getListState(new ListStateDescriptor<Integer>("top3", Integer.class));
}
@Override
public void processElement(WaterSensor value,
Context ctx,
Collector<String> out) throws Exception {
top3VcState.add(value.getVc());
Iterable<Integer> it = top3VcState.get();
List<Integer> list = BigdataUtil.toList(it);
list.sort(Comparator.reverseOrder());
if (list.size() == 4) {
list.remove(list.size() - 1);
}
top3VcState.update(list);
out.collect(list.toString());
}
})
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/*
D:\netcat-win32-1.12>nc64.exe -lp 6666
s1,1,10
s1,1,8
s1,1,12
s1,1,6
s1,1,66
s1,1,666
s1,1,6666
s1,1,88
--------------------
[10]
[10, 8]
[12, 10, 8]
[12, 10, 8]
[66, 12, 10]
[666, 66, 12]
[6666, 666, 66]
[6666, 666, 88]
*/
3-5.键控状态示例-ReducingState
代码示例:
package com.zenitera.bigdata.state;
import com.zenitera.bigdata.bean.WaterSensor;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
/**
* ReducingState
*/
public class Flink02_State_Key_ReduceState {
public static void main(String[] args) {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 2000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
env
.socketTextStream("localhost", 6666)
.map(line -> {
String[] data = line.split(",");
return new WaterSensor(
String.valueOf(data[0]),
Long.valueOf(data[1]),
Integer.valueOf(data[2])
);
})
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
private ReducingState<WaterSensor> vcSumState;
@Override
public void open(Configuration parameters) {
vcSumState = getRuntimeContext().getReducingState(
new ReducingStateDescriptor<>(
"vcSumState",
(ReduceFunction<WaterSensor>) (value1, value2) -> {
value1.setVc(value1.getVc() + value2.getVc());
System.out.println(value1.getVc());
return value1;
},
WaterSensor.class
));
}
@Override
public void processElement(WaterSensor value,
Context ctx,
Collector<String> out) throws Exception {
vcSumState.add(value);
out.collect(vcSumState.get().toString());
}
})
.print();
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/*
D:\netcat-win32-1.12>nc64.exe -lp 6666
s1,1,1
s1,1,3
s1,1,5
s1,1,10
--------------------------
com.zenitera.bigdata.bean.WaterSensor@80c7dff
4
com.zenitera.bigdata.bean.WaterSensor@80c7dff
9
com.zenitera.bigdata.bean.WaterSensor@80c7dff
19
com.zenitera.bigdata.bean.WaterSensor@80c7dff
*/
3-6.键控状态示例-AggregatingState
代码示例:
package com.zenitera.bigdata.state;
import com.zenitera.bigdata.bean.WaterSensor;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.state.AggregatingState;
import org.apache.flink.api.common.state.AggregatingStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
/**
* AggregateState
*/
public class Flink02_State_Key_AggregateState {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 2000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
env
.socketTextStream("localhost", 6666)
.map(line -> {
String[] data = line.split(",");
return new WaterSensor(
data[0],
Long.valueOf(data[1]),
Integer.valueOf(data[2])
);
})
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
private AggregatingState<WaterSensor, Double> vcAvgState;
@Override
public void open(Configuration parameters) throws Exception {
vcAvgState = getRuntimeContext().getAggregatingState(
new AggregatingStateDescriptor<WaterSensor, Avg, Double>(
"vcAvgState",
new AggregateFunction<WaterSensor, Avg, Double>() {
@Override
public Avg createAccumulator() {
return new Avg();
}
@Override
public Avg add(WaterSensor value, Avg acc) {
acc.sum += value.getVc();
acc.count++;
return acc;
}
@Override
public Double getResult(Avg acc) {
return acc.avg();
}
@Override
public Avg merge(Avg a, Avg b) {
return null;
}
},
Avg.class
)
);
}
@Override
public void processElement(WaterSensor value,
Context ctx,
Collector<String> out) throws Exception {
vcAvgState.add(value);
out.collect(ctx.getCurrentKey() + " avg: " + vcAvgState.get());
}
})
.print();
env.execute();
}
public static class Avg {
public Integer sum = 0;
public Long count = 0L;
public Double avg() {
return sum * 1.0 / count;
}
}
}
/*
D:\netcat-win32-1.12>nc64.exe -lp 6666
s1,1,2
s1,1,4
s1,1,12
s1,1,40
--------------------------
s1 avg: 2.0
s1 avg: 3.0
s1 avg: 6.0
s1 avg: 14.5
*/
3-7.键控状态示例-MapState
代码示例:
package com.zenitera.bigdata.state;
import com.zenitera.bigdata.bean.WaterSensor;
import com.zenitera.bigdata.util.BigdataUtil;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
/**
* MapState
*/
public class Flink02_State_Key_MapState {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 2000);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);
env.setParallelism(1);
env
.socketTextStream("localhost", 6666)
.map(line -> {
String[] data = line.split(",");
return new WaterSensor(
data[0],
Long.valueOf(data[1]),
Integer.valueOf(data[2])
);
})
.keyBy(WaterSensor::getId)
.process(new KeyedProcessFunction<String, WaterSensor, String>() {
private MapState<Integer, Object> vcMapState;
@Override
public void open(Configuration parameters) throws Exception {
vcMapState = getRuntimeContext().getMapState(
new MapStateDescriptor<Integer, Object>(
"vcMapState",
TypeInformation.of(new TypeHint<Integer>() {}),
TypeInformation.of(new TypeHint<Object>() {})
)
);
}
@Override
public void processElement(WaterSensor value,
Context ctx,
Collector<String> out) throws Exception {
vcMapState.put(value.getVc(), new Object());
Iterable<Integer> vcs = vcMapState.keys();
out.collect(ctx.getCurrentKey() + " VC: " + BigdataUtil.toList(vcs));
}
})
.print();
env.execute();
}
}
/*
D:\netcat-win32-1.12>nc64.exe -lp 6666
s1,1,2
s1,1,4
s1,1,6
s1,1,8
s1,1,10
s1,1,12
s1,1,16
s1,1,18
s1,1,20
s1,1,22
--------------------------
s1 VC: [2]
s1 VC: [2, 4]
s1 VC: [2, 4, 6]
s1 VC: [2, 4, 6, 8]
s1 VC: [2, 4, 6, 8, 10]
s1 VC: [2, 4, 6, 8, 10, 12]
s1 VC: [16, 2, 4, 6, 8, 10, 12]
s1 VC: [16, 2, 18, 4, 6, 8, 10, 12]
s1 VC: [16, 2, 18, 4, 20, 6, 8, 10, 12]
s1 VC: [16, 2, 18, 4, 20, 6, 22, 8, 10, 12]
*/
4.Flink状态后端(state backend)
每传入一条数据,有状态的算子任务都会读取和更新状态。由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务(子任务)都会在本地维护其状态,以确保快速的状态访问
状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就叫做状态后端(state backend)
4-1.状态后端的功能
状态后端组合要负责两个功能
- 本地( taskmanager )的状态管理
- 将检查点( checkpoint )状态写入远程存储
4-2.状态后端的分类
状态后端作为一个可插入的组件, 没有固定的配置, 我们可以根据需要选择一个合适的状态后端
可使用于生产环境的状态后端主要分为
- FsStateBackend
- 存储方式:本地状态在TaskManager内存, Checkpoint时, 存储在文件系统(hdfs)中
- 特点:拥有内存级别的本地访问速度, 和更好的容错保证
- 使用场景:
- 常规使用状态的作业, 例如分钟级别窗口聚合, join等
- 需要开启HA的作业
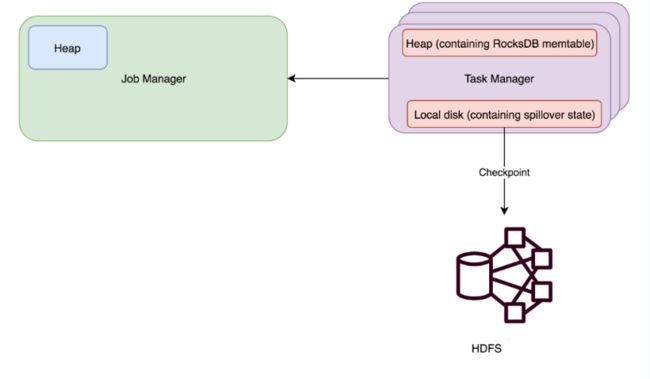
- RocksDBStateBackend
- 存储方式:本地状态存储在TaskManager的RocksDB数据库中(实际是内存+磁盘),Checkpoint在外部文件系统(hdfs)中
- 使用场景:
- 超大状态的作业, 例如天级的窗口聚合
- 需要开启HA的作业
- 对读写状态性能要求不高的作业
- MemoryStateBackend
原理:运行时所需的 State 数据全部保存在 TaskManager JVM 堆上内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到 JobManager 进程 的内存中。执行 Savepoint 时,可以把 State 存储到文件系统中。
基于内存的 StateBackend 在生产环境下不建议使用,因为 State 大小超过 JobManager 内存就 OOM 了,此种状态后端适合在本地开发调试测试,生产环境基本不用
4-3.配置状态后端
- 全局配置状态后端
在flink-conf.yaml文件中设置默认的全局后端
state.backend: 类型选择
state.checkpoints.dir: 检查点位置
state.savepoints.dir: 存储点位置
- 代码功能中配置状态后端
可以在代码中单独为这个Job设置状态后端
// 示例
env.setStateBackend(new MemoryStateBackend());
env.setStateBackend(new FsStateBackend("hdfs://hdt-dmcp-ops01:8020/flink/checkpoints/fs"));
env.setStateBackend(new RocksDBStateBackend("hdfs://hdt-dmcp-ops01:8020/flink/checkpoints/rocksdb"));
注意:如果要使用RocksDBBackend, 需要先引入依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-statebackend-rocksdb_${scala.binary.version}artifactId>
<version>${flink.version}version>
dependency>