浅析批处理框架Spring Batch
1.Spring Batch简介
Spring Batch 是一个轻量级的、完善的批处理框架,旨在帮助企业建立健壮、高效的批处理应用。Spring Batch是Spring的一个子项目,使用Java语言并基于Spring框架为基础开发,作为一个 Spring 组件,提供了通过使用 Spring 的 依赖注入(dependency injection) 来处理批处理的条件。
Spring Batch 提供了大量可重用的组件,包括了日志、追踪、事务、任务作业统计、任务重启、跳过、重复、资源管理。对于大数据量和高性能的批处理任务,Spring Batch 同样提供了高级功能和特性来支持,比如分区功能、远程功能。总之,通过 Spring Batch 能够支持简单的、复杂的和大数据量的批处理作业。
Spring Batch 是一个批处理应用框架,不是调度框架,但需要和调度框架合作来构建完成的批处理任务。它只关注批处理任务相关的问题,如事务、并发、监控、执行等,并不提供相应的调度功能。
2.Spring Batch架构
Spring Batch 设计时充分考虑了可扩展性和各类终端用户。下图显示了Spring Batch的架构层次示意图,这种架构层次为终端用户开发者提供了很好的扩展性与易用性.

Spring Batch 架构主要分为三类高级组件: 应用层(Application), 核心层(Core) 和基础架构层(Infrastructure)。
应用层(Application)包括开发人员用Spring batch编写的所有批处理作业和自定义代码。
Batch核心(Batch Core) 包含加载和控制批处理作业所必需的核心类。包括 JobLauncher, Job, 和 Step 的实现.
应用层(Application) 与 核心等(Core)都构建在通用基础架构层之上. 基础架构包括通用的 readers(ItemReader) 和 writers( ItemWriter), 以及 services (如重试模块 RetryTemplate), 可以被应用层和核心层所使用。
下面的关系图是一个已使用了数十年的SpringBatch批处理体系结构的简化版本:
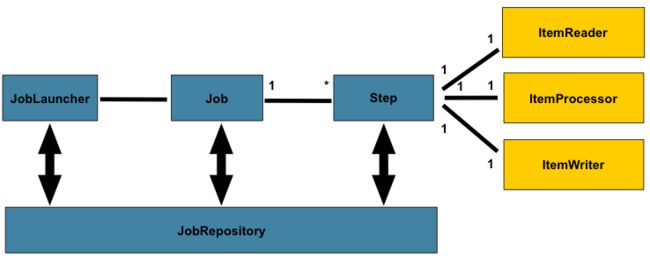
在上面的关系图中,所包含的高亮部分就是组成批处理域语言的关键概念。一个Job有多个Step,一个Step精确对应一个ItemReader、ItemProcessor、ItemWriter。一个Job需要被启动(JobLauncher),当前运行中的流程需要被存储(JobRepository)。
3.Spring Batch核心概念
下面是一些概念是Spring batch框架中的核心概念。
3.1 Job
Job和Step是spring batch执行批处理任务最为核心的两个概念。
其中Job是一个封装整个批处理过程的一个概念。Job在spring batch的体系当中只是一个最顶层的一个抽象概念,体现在代码当中则它只是一个最上层的接口,其代码如下:
/**
* Batch domain object representing a job. Job is an explicit abstraction
* representing the configuration of a job specified by a developer. It should
* be noted that restart policy is applied to the job as a whole and not to a
* step.
*/
public interface Job {
String getName();
boolean isRestartable();
void execute(JobExecution execution);
JobParametersIncrementer getJobParametersIncrementer();
JobParametersValidator getJobParametersValidator();
}
在Job这个接口当中定义了五个方法,它的实现类主要有两种类型的job,一个是simplejob,另一个是flowjob。在spring batch当中,job是最顶层的抽象,除job之外我们还有JobInstance以及JobExecution这两个更加底层的抽象。
一个job是我们运行的基本单位,它内部由step组成。job本质上可以看成step的一个容器。一个job可以按照指定的逻辑顺序组合step,并提供了我们给所有step设置相同属性的方法,例如一些事件监听,跳过策略。
Spring Batch以SimpleJob类的形式提供了Job接口的默认简单实现,它在Job之上创建了一些标准功能。一个使用java config的例子代码如下:
@Bean
public Job userBatchJob(){
return jobBuilderFactory.get("userBatchJob")
.incrementer(new RunIdIncrementer())
.start(userBatchStep())
.end()
.listener(new UserJobListener())
.build();
}这个配置的意思是:首先给这个job起了一个名字叫userBatchJob,RunIdIncrementer会在参数列表中附加一个唯一参数,以便生成的组合将是唯一的,每次使用相同的识别参数组合运行作业时,会产生一个新的JobInstance 。
接着指定了这个job的step,Job也可以配置监听器在Job运行前后执行指定代码。
3.1.1 JobInstance
我们在上文已经提到了JobInstance,他是Job的更加底层的一个抽象,他的定义如下:
public interface JobInstance {
/**
* Get unique id for this JobInstance.
* @return instance id
*/
public long getInstanceId();
/**
* Get job name.
* @return value of 'id' attribute from
*/
public String getJobName();
}
他的方法很简单,一个是返回Job的id,另一个是返回Job的名字。
JobInstance指的是job运行当中,作业执行过程当中的概念。Instance本就是实例的意思。
比如说现在有一个批处理的job,它的功能是在一天结束时执行行一次。我们假定这个批处理job的名字为'EndOfDay'。在这个情况下,那么每天就会有一个逻辑意义上的JobInstance, 而我们必须记录job的每次运行的情况。
3.1.2 JobParameters
在上文当中我们提到了,同一个job每天运行一次的话,那么每天都有一个jobIntsance,但他们的job定义都是一样的,那么我们怎么来区别一个job的不同jobinstance了。不妨先做个猜想,虽然jobinstance的job定义一样,但是他们有的东西就不一样,例如运行时间。
spring batch中提供的用来标识一个jobinstance的东西是:JobParameters。JobParameters对象包含一组用于启动批处理作业的参数,它可以在运行期间用于识别或甚至用作参考数据。我们假设的运行时间,就可以作为一个JobParameters。
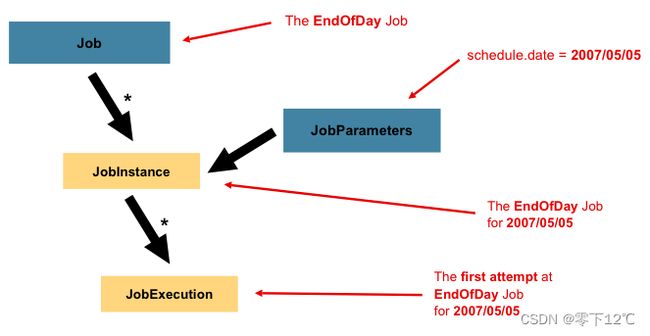
在上面的例子中一个job有两个实例,一个是1月1日以01-01-2022的参数启动运行,一个是1月2日以01-02-2008的参数启动运行。因此可以这样定义:JobInstance = Job + JobParameter。

这让开发者有效地控制JobInstance,因为开发者可以有效控制输入给JobInstance的参数。
3.1.3 JobExecution
JobExecution指的是单次尝试运行一个我们定义好的Job的代码层面的概念。job的一次执行可能以失败也可能成功。只有当执行成功完成时,给定的与执行相对应的JobInstance才也被视为完成。
还是以前面描述的EndOfDay的job作为示例,假设第一次运行01-01-2019的JobInstance结果是失败。那么此时如果使用与第一次运行相同的Jobparameter参数(即01-01-2019)作业参数再次运行,那么就会创建一个对应于之前jobInstance的一个新的JobExecution实例,JobInstance仍然只有一个。
JobExecution的接口定义如下:
public interface JobExecution {
/**
* Get unique id for this JobExecution.
* @return execution id
*/
public long getExecutionId();
/**
* Get job name.
* @return value of 'id' attribute from
*/
public String getJobName();
/**
* Get batch status of this execution.
* @return batch status value.
*/
public BatchStatus getBatchStatus();
/**
* Get time execution entered STARTED status.
* @return date (time)
*/
public Date getStartTime();
/**
* Get time execution entered end status: COMPLETED, STOPPED, FAILED
* @return date (time)
*/
public Date getEndTime();
/**
* Get execution exit status.
* @return exit status.
*/
public String getExitStatus();
/**
* Get time execution was created.
* @return date (time)
*/
public Date getCreateTime();
/**
* Get time execution was last updated updated.
* @return date (time)
*/
public Date getLastUpdatedTime();
/**
* Get job parameters for this execution.
* @return job parameters
*/
public Properties getJobParameters();
}
每一个方法的注释已经解释的很清楚,这里不再多做解释。只提一下BatchStatus,JobExecution当中提供了一个方法getBatchStatus用于获取一个job某一次特地执行的一个状态。BatchStatus是一个代表job状态的枚举类,其定义如下:
public enum BatchStatus {STARTING, STARTED, STOPPING,
STOPPED, FAILED, COMPLETED, ABANDONED }
这些属性对于一个job的执行来说是非常关键的信息,并且spring batch会将他们持久到数据库当中. 在使用Spring batch的过程当中spring batch会自动创建一些表用于存储一些job相关的信息,用于存储JobExecution的表为batch_job_execution,下面是一个从数据库当中截图的实例:

3.2 Step
Step是一个独立封装域对象,包含了所有定义和控制实际处理信息批任务的序列。这是一个比较抽象的描述,因为任意一个Step的内容都是开发者自己编写的Job。一个Step的简单或复杂取决于开发者的意愿。一个简单的Step也许是从本地文件读取数据存入数据库,写很少或基本无需写代码。一个复杂的Step也许有复杂的业务规则(取决于所实现的方式),并作为整个个流程的一部分。

Spring Batch最通用的实现方式是使用“面向块”的处理风格。面向块处理是指在一个事务范围内,一次性读取数据,创建被输出的“块”。ItemReader读取一条项目,通过ItemProcessor处理,并整合。当处理完所有项目后,整个块将由ItemWriter输出,然后提交该事务。

与Job一样,Step具有与JobExecution类似的StepExecution,如下图所示:

3.2.1 StepExecution
StepExecution表示一次执行Step, 每次运行一个Step时都会创建一个新的StepExecution,类似于JobExecution。但是,某个步骤可能由于其之前的步骤失败而无法执行。且仅当Step实际启动时才会创建StepExecution。
一次step执行的实例由StepExecution类的对象表示。每个StepExecution都包含对其相应步骤的引用以及JobExecution和事务相关的数据,例如提交和回滚计数以及开始和结束时间。
此外,每个步骤执行都包含一个ExecutionContext,其中包含开发人员需要在批处理运行中保留的任何数据,例如重新启动所需的统计信息或状态信息。下面是一个从数据库当中截图的实例:
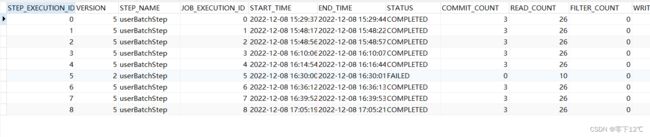
3.2.2 ExecutionContext
ExecutionContext即每一个StepExecution 的执行环境。它包含一系列的键值对。我们可以用如下代码获取ExecutionContext
ExecutionContext ecStep = stepExecution.getExecutionContext();
ExecutionContext ecJob = jobExecution.getExecutionContext();
3.2.3 Item Reader
ItemReader是一个读数据的抽象,它的功能是为每一个Step提供数据输入。当ItemReader以及读完所有数据时,它会返回null来告诉后续操作数据已经读完。Spring Batch为ItemReader提供了非常多的有用的实现类,比如JdbcPagingItemReader,MybatisPagingItemReader等等。
ItemReader支持的读入的数据源也是非常丰富的,包括各种类型的数据库,文件,数据流,等等。几乎涵盖了我们的所有场景。
下面是一个MybatisPagingItemReader的例子代码:
@Bean
public ItemReader reader(){
// 使用FlatFileItemReader去读cvs文件,一行即一条数据
MyBatisPagingItemReader reader = new MyBatisPagingItemReaderBuilder()
.sqlSessionFactory(sqlSessionFactory)
.pageSize(1000)
.queryId("com.sz.toolkit.springbatch.mapper.UserFromMapper.selectAllInfo")
.build();
return reader;
} 3.2.4 Item Writer
既然ItemReader是读数据的一个抽象,那么ItemWriter自然就是一个写数据的抽象,它是为每一个step提供数据写出的功能。写的单位是可以配置的,我们可以一次写一条数据,也可以一次写一个chunk的数据。ItemWriter对于读入的数据是不能做任何操作的。
Spring Batch为ItemWriter也提供了非常多的有用的实现类,当然我们也可以去实现自己的writer功能。
下面是一个MybatisItemWrite的例子代码:
@Bean
public ItemWriter writer(){
MyBatchItemWriter writer = new MyBatchItemWriter();
writer.setSqlSessionFactory(sqlSessionFactory);
writer.setStatementId("***.mapper.UserToMapper.batchInsert");
return writer;
} 3.2.5 Item Processor
ItemProcessor对项目的业务逻辑处理的一个抽象, 当ItemReader读取到一条记录之后,ItemWriter还未写入这条记录之前,I我们可以借助temProcessor提供一个处理业务逻辑的功能,并对数据进行相应操作。如果我们在ItemProcessor发现一条数据不应该被写入,可以通过返回null来表示。ItemProcessor和ItemReader以及ItemWriter可以非常好的结合在一起工作,他们之间的数据传输也非常方便。我们直接使用即可。.
下面是一个Step实例定义的例子代码:
@Bean
public Step userBatchStep(){
System.out.printf("userBatchStep");
return stepBuilderFactory
.get("userBatchStep")
.chunk(10)
.reader(reader()).faultTolerant().retryLimit(3).retry(Exception.class).skip(Exception.class).skipLimit(2)
.listener(new UserReaderListener())
.processor(processor())
.writer(writer()).faultTolerant().skip(Exception.class).skipLimit(2)
.build();
} 在上面这个step里面,chunk size被设为了10,当ItemReader读的数据数量达到10的时候,这一批次的数据就一起被传到itemWriter,同时transaction被提交。
skip策略和失败处理
一个batch的job的step,可能会处理非常大数量的数据,难免会遇到出错的情况,出错的情况虽出现的概率较小,但是我们不得不考虑这些情况,因为我们做数据迁移最重要的是要保证数据的最终一致性。spring batch当然也考虑到了这种情况,并且为我们提供了相关的技术支持。
我们需要留意这三个方法,分别是skipLimit(),skip(),noSkip(),retryLimit(),retry()
skipLimit方法的意思是我们可以设定一个我们允许的这个step可以跳过的异常数量,假如我们设定为10,则当这个step运行时,只要出现的异常数目不超过10,整个step都不会fail。注意,若不设定skipLimit,则其默认值是0.
skip方法我们可以指定我们可以跳过的异常,因为有些异常的出现,我们是可以忽略的。
noSkip方法的意思则是指出现这个异常我们不想跳过,也就是从skip的所以exception当中排除这个exception,从上面的例子来说,也就是跳过所有除FileNotFoundException的exception。
retryLimit(3).retry(Exception.class) 这个就是设置重试,当出现异常的时候,重试多少次。我们设置为3,也就是说当一条数据操作失败,那我们会对这条数据进行重试3次,还是失败就是 当做失败了, 那么我们如果有配置skip(推荐配置使用),那么这个数据失败记录就会留到给 skip 来处理。
那么对于这个step来说,FileNotFoundException就是一个fatal的exception,抛出这个exception的时候step就会直接fail
3.3 JobRepository
JobRepository是一个用于将上述job,step等概念进行持久化的一个类。它同时给Job和Step以及下文会提到的JobLauncher实现提供CRUD操作。
首次启动Job时,将从repository中获取JobExecution,并且在执行批处理的过程中,StepExecution和JobExecution将被存储到repository当中。
@EnableBatchProcessing注解可以为JobRepository提供自动配置。
3.4 JobLauncher
JobLauncher这个接口的功能非常简单,它是用于启动指定了JobParameters的Job,为什么这里要强调指定了JobParameter,原因其实我们在前面已经提到了,jobparameter和job一起才能组成一次job的执行。下面是代码实例:
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException, JobParametersInvalidException;
}
上面run方法实现的功能是根据传入的job以及jobparamaters从JobRepository获取一个JobExecution并执行Job。
下面是一个jobLauncher执行job代码例子
@Test
public void testJob() throws JobInstanceAlreadyCompleteException, JobExecutionAlreadyRunningException, JobParametersInvalidException, JobRestartException {
// 后置参数:使用JobParameters中绑定参数 addLong addString 等方法
JobParameters jobParameters = new JobParametersBuilder().addLong("time",System.currentTimeMillis()).toJobParameters();
jobLauncher.run(userBatchJob, jobParameters);
}4 批处理操作指南
本部分是一些使用spring batch时的值得注意的点
4.1 批处理的指导原则
下面是一些关键的指导原则,在构建批处理解决方案可以参考:
- 批处理架构通常会影响在线服务的架构,反之亦然。设计架构和环境时请尽可能使用公共的模块。
- 尽可能的简化,避免在单个批处理应用中构建复杂的逻辑结构。
- 尽可能在数据存放的地方处理这些数据,反之亦然(即,各自负责处理自己的数据)。
- 尽可能少的使用系统资源,尤其是I/O。尽可能多地在内存中执行大部分操作。
- 审查应用程序I/O(分析SQL语句)以避免不必要的物理I/O。特别是以下四个常见的缺陷(flaws)需要避免:
- 在每个事务中都将(所有并不需要的)数据读取,并缓存起来;
- 多次读取/查询同一事务中已经读取过的数据;
- 引起不必要的表或索引扫描;
- 在SQL语句的WHERE子句中不指定过滤条件。
- 在同一个批处理不要做两次一样的事。例如,如果你需要报表的数据汇总,请在处理每一条记录时使用增量来存储,尽可能不要再去遍历一次同样的数据。
- 在批处理程序开始时就分配足够的内存,以避免运行过程中再执行耗时的内存分配。
- 总是将数据完整性假定为最坏情况。插入适当的检查和数据校验以保持数据完整性(integrity)。
- 如有可能,请为内部校验实现checksum。例如,平面文件应该有一条结尾记录,说明文件中的总记录数和关键字段的集合(aggregate)。
- 尽可能早地在模拟生产环境下使用真实的数据量,进行计划和执行压力测试。
- 在大型批处理系统中,备份会是一个很大的挑战,特别是 7x24小时不间断的在线服务系统。数据库备份通常在设计时就考虑好了,但是文件备份也应该提升到同养的重要程度。如果系统依赖于文本文件,文件备份程序不仅要正确设置和形成文档,还要定期进行测试。
4.2 批处理使用场景
- 定期提交批处理任务
- 并发批处理:并行执行任务
- 分阶段,企业消息驱动处理
- 高并发批处理任务
- 失败后手动或定时重启
- 按顺序处理任务依赖(使用工作流驱动的批处理插件)
- 局部处理:跳过记录(例如在回滚时)
- 完整的批处理事务:因为可能有小数据量的批处理或存在存储过程/脚本
5 如何默认不启动job
在使用java config使用spring batch的job时,如果不做任何配置,项目在启动时就会默认去跑我们定义好的批处理job。那么如何让项目在启动时不自动去跑job呢?
spring batch的job会在项目启动时自动run,如果我们不想让他在启动时run的话,可以在application.yml中添加如下属性:
spring
batch:
job:
enabled: false # 手动执行任务
jdbc:
initialize-schema: always # 服务启动时自动初始化 batch 相关数据库
6 参考文档
批处理框架 Spring Batch - licj的博客 - 博客园
Spring Batch参考文档中文版 - 《Spring Batch参考文档中文版》 - 书栈网 · BookStack