【目标检测】---- YOLOX 旷视2021
1. YOLOX的改进
YOLOX 以YOLO v3作为baseline主要做了以下改进:
①. 输入端的图像增强(Mosaic、Mixup、RandomHorizontalFlip、ColorJitter、多尺度训练)
②. Backbone(Darknet53 + SPP)
③. Neck (FPN + PAN)
④. Head (Decoupled Head、Anchor free、Multi Positives、IoU-Aware、SimOTA)
⑤, 训练策略(EMA + 余弦学习率策略)

1. 1 Decoupled Head
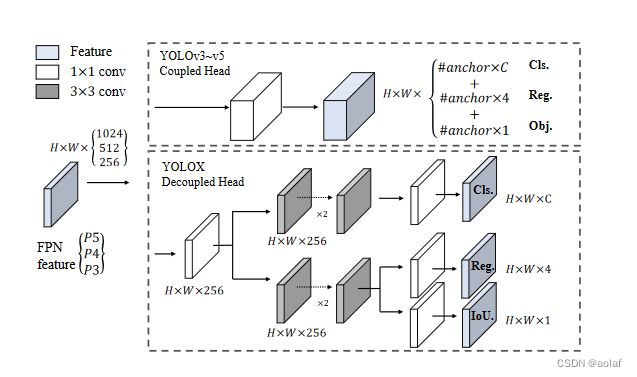
一直以来YOLO系列仅使用一个分支作为检测头同时完成对obj、cls以及reg三部分的预测。而我们所熟知的SSD、RetinaNet则是使用两个并行分支去分别做cls和reg的预测。YOLOX作者认为cls的学习显然和reg不一样,仅使用一个branch来完成两个类型完全不同的目标,确实有点难度。于是,就把原先的Coupled head改成类似于RetinaNet的那种Decoupled head,如下图所示,变成了三个Decoupled Head分支。
改成Decoupled head后不仅检测效果提升,模型的收敛速度也大大提高。

1.2 正负样本匹配
1.2.1 Anchor free
1.2.2 Multi Positives
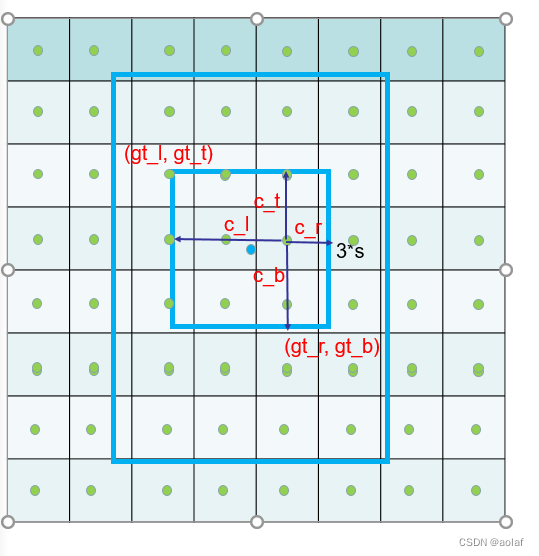
如果只把GT中心点所在的grid_ceil作为正样本,那么每个GT就只有一个正样本,该中心点附近的其余高质量的正样本可能就被忽略了,因此借鉴了focos的做法:中心点所在网格的3X3领域,都作为候选正样本。
注意这一步获得的正样本只是候选正样本,它实际是初步过滤,为了计算cost损失,进而为下一步的simOTA自适应匹配提供条件。

实现步骤:
①. 找GT中心点周围3 * 3的邻域(这里的3指的是一个单位,实际相对于原图做要 * 下采样步长S)
②. 计算每个网格中心点到该3 * 3领域四条边的距离c_l, c_t, c_r, c_b
③. 若到四条边的距离全大于0,那么说明该网格中心点在3*3邻域内部,这部分为候选正样本
def get_geometry_constraint(
self, gt_bboxes_per_image, expanded_strides, x_shifts, y_shifts,
):
"""
Calculate whether the center of an object is located in a fixed range of
an anchor. This is used to avert inappropriate matching. It can also reduce
the number of candidate anchors so that the GPU memory is saved.
"""
# 特征图下采样的步长
expanded_strides_per_image = expanded_strides[0]
# 每个grid_ceil在原图上的中心点坐标
x_centers_per_image = ((x_shifts[0] + 0.5) * expanded_strides_per_image).unsqueeze(0)
y_centers_per_image = ((y_shifts[0] + 0.5) * expanded_strides_per_image).unsqueeze(0)
center_radius = 1.5
# 1. 找GT中心点周围3*3的邻域
center_dist = expanded_strides_per_image.unsqueeze(0) * center_radius
gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0:1]) - center_dist
gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0:1]) + center_dist
gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1:2]) - center_dist
gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1:2]) + center_dist
# 2.计算每个网格中心点到该3*3领域四条边的距离
c_l = x_centers_per_image - gt_bboxes_per_image_l
c_r = gt_bboxes_per_image_r - x_centers_per_image
c_t = y_centers_per_image - gt_bboxes_per_image_t
c_b = gt_bboxes_per_image_b - y_centers_per_image
center_deltas = torch.stack([c_l, c_t, c_r, c_b], 2)
# 3.若到四条边的距离全大于0,那么说明该网格中心点在3*3邻域内部,这部分为候选正样本
is_in_centers = center_deltas.min(dim=-1).values > 0.0
anchor_filter = is_in_centers.sum(dim=0) > 0
geometry_relation = is_in_centers[:, anchor_filter]
return anchor_filter, geometry_relation
1.2.3 cost成本计算
上述通过GT中心点领域的方法获得了初步的正样本,利用这些正样本和网络输出的预测结果我们可以得到loss损失
- 计算预测框与GT框的iou损失
- 计算类别损失(BCE):sqrt(sigmoid(cls_preds) * sigmoid(obj_preds))
注意这里开方是为了缓解两个小于1的值相乘更小问题。 - 计算cost代价:cost = (cls_loss + 3.0 * ious_loss + 1e6 * (~geometry_relation)
其中3是回归系数,1e6 * (~geometry_relation)是为了尽可能约束正样本从3 * 3的领域内获得。
pair_wise_ious = bboxes_iou(gt_bboxes_per_image, bboxes_preds_per_image, False)
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8)
cls_preds_ = (cls_preds_.float().sigmoid_() * obj_preds_.float().sigmoid_()).sqrt()
pair_wise_cls_loss = F.binary_cross_entropy(
cls_preds_.unsqueeze(0).repeat(num_gt, 1, 1),
gt_cls_per_image.unsqueeze(1).repeat(1, num_in_boxes_anchor, 1),
reduction="none"
).sum(-1)
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_ious_loss
+ float(1e6) * (~geometry_relation)
)
1.2.4 SimOTA
通过cost代价函数,我们可以衡量一个预测框对于一个GT框来说是否足够好,显然,GT匹配上那些代价更小的预测框更为合适。那么具体给每个GT匹配多少个预测框呢?SimOTA采用了一种动态估计策略。
步骤一:确定每个GT需要分配的预测框数量
①. 对于每个GT框,找出与其iou最大的十个预测框,以及前十大iou的值
②. 对每个GT框,与其所有预测框的前10名的iou之和取整,最小为1, 这个值作为每个GT框需分配的预测框数量。(iou接近于1,说明预测框和GT越匹配,刚开始训练时候,由于预测基本不准,导致dynamic_k基本上都是1)
步骤二:根据GT框需要的预测框数量m,找cost损失最小的m个预测框给该GT
步骤三:解决某个预测框匹配多个GT的情况
取消该预测框所匹配的全部GT,找和该框cost损失最小的GT去匹配。
注意步骤三存在的问题:
假设某个预测框A同时和GT1、GT2匹配,其中A和GT2的cost最小,根据步骤三,A会匹配给GT2,若GT1没有预测框与之匹配,那么此时GT1就没有正样本。
解决思路:
判断一下,只有GT1匹配的预测框数量大于1时才这么做
def simota_matching(self, cost, pair_wise_ious, gt_classes, num_gt, fg_mask):
# 一. 确定每个GT需分配的预测框数量
# 1. 创建与cost维度一致的全0矩阵,[gt_nums, pos_anchor_nums]
matching_matrix = torch.zeros_like(cost, dtype=torch.uint8)
# 2. 取10与pos_anchor_nums中的较小值作为每个目标的最大候选框数量
n_candidate_k = min(10, pair_wise_ious.size(1))
# 3. 找出每个GT框与其预测框的前十大iou的预测框, [gt_nums, min(10, pos_anchor_nums)]
topk_ious, _ = torch.topk(pair_wise_ious, n_candidate_k, dim=1)
# 4. 对每个GT框与所有预测框的前10名的iou之和取整,最小为1, 这个值作为每个GT框需分配的候选框数量。(iou接近于1,说明预测框和GT越匹配,刚开始训练时候,由于预测基本不准,导致dynamic_k基本上都是1)
dynamic_ks = torch.clamp(topk_ious.sum(1).int(), min=1)
# 二. 根据每个gt需要的候选框数量结合cost确定相应的候选框索引
# 5. 遍历每个Gt求其前TOPK对应的cost索引,这个索引即为每个GT匹配上的候选框的索引
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(cost[gt_idx], k=dynamic_ks[gt_idx], largest=False)
# 将全0匹配矩阵对应的位置置1
matching_matrix[gt_idx][pos_idx] = 1
del topk_ious, dynamic_ks, pos_idx
# 三. 解决某个候选框同时匹配多个GT的情况,计算该候选框与所有GT的cost,将最小的cost对应的GT分配给该候选框
# 1. 每个候选框匹配的GT数量
anchor_matching_gt = matching_matrix.sum(0)
# 2. 若存在候选框匹配的GT数>1
if anchor_matching_gt.max() > 1:
# 找出匹配多个GT的候选框的索引
multiple_match_mask = anchor_matching_gt > 1
# 求匹配多个GT的候选框的最小cost对应的GT索引
_, cost_argmin = torch.min(cost[:, multiple_match_mask], dim=0)
# 将匹配多个GT的候选框的索引置0
matching_matrix[:, multiple_match_mask] *= 0
# 将匹配多个GT的候选框对应最小cost的候选框置1
matching_matrix[cost_argmin, multiple_match_mask] = 1
# 提取所有匹配了Gt的anchor
fg_mask_inboxes = anchor_matching_gt > 0
num_fg = fg_mask_inboxes.sum().item()
#
fg_mask[fg_mask.clone()] = fg_mask_inboxes
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
gt_matched_classes = gt_classes[matched_gt_inds]
pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[fg_mask_inboxes]
return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds
1.3 损失函数
1.4 训练策略
- Mosaic和Mix-up在提升了模型的鲁棒性和泛化性的同时也破坏了数据的真实分布,因此在训练的最后15 epoch,马赛克增强和混合增强会被关闭。
- Random crop与Mosaic有一定的重叠,去掉了Random crop。