跨模态检索的持续学习
Continual learning in cross-modal retrieval跨模态检索的持续学习
概述
多模态表示和持续学习是与人类智能密切相关的两个领域。前者考虑了共享表示空间的学习,其中来自不同模态的信息可以进行比较和集成(我们关注语言和视觉表示之间的跨模态检索)。后者研究如何防止在学习新任务时忘记以前学过的任务。虽然人类在这两个方面表现出色,但深度神经网络仍然相当有限。在本文中,我们提出将这两个问题结合到一个连续的跨模态检索设置中,在其中我们研究了新任务引起的灾难性干扰如何影响嵌入空间及其有效检索所需的跨模态对齐。我们提出了一个通用框架,将训练、索引和查询阶段解耦。我们还确定并研究了可能导致遗忘的不同因素,并提出了缓解遗忘的方法。我们发现索引阶段起着重要的作用,简单地避免用更新的嵌入网络重新索引数据库可以带来显著的收益。我们在两个图像-文本检索数据集中评估了我们的方法,获得了关于微调基线的显著收益。
简介
人类持续学习的能力使我们能够很好地完成很久以前学过的任务。相比之下,神经网络遭受灾难性干扰,这导致在适应新任务时几乎完全忘记以前的任务,这是向能够学习和适应不断变化的环境的高度自主代理前进的关键限制。神经网络中的持续学习(通常也被称为终身学习、顺序学习或增量学习)是一个活跃的研究领域,最近的方法通过新的正则化、架构和(伪)排练机制来解决灾难性遗忘。大多数持续学习方法侧重于分类任务。
本文提出了一个持续的跨模态重新检索框架,可以有效地在已知和未知领域进行检索。 我们确定并研究了导致跨模态数据库和检索中遗忘的不同因素。 针对这些因素,我们研究了检索框架、网络结构和正则化中的修改,以帮助缓解这些因素。
相关工作
持续学习
神经网络中一个众所周知的现象是灾难性遗忘,即学习新任务会干扰对以前任务的记忆。为了使网络能够在需要持续学习的情况下取得成功,人们提出了不同的技术。一种流行的方法是在损失中添加正则化项。权重正则化方法增加了二次项,以惩罚与以前任务的解决方案的巨大差异,通过一些重要性措施进行加权,因此更重要的参数的差异被惩罚得更多。
据我们所知,目前还没有任何工作专门研究在检索环境中持续学习的意义,以及从跨模态嵌入的角度研究灾难性遗忘。
持续的跨模态检索
跨模态深度度量学习
我们的框架是基于一个双分支网络,有特定的图像和特定的文本嵌入分支,将图像和文本投射到一个共同的空间。图像嵌入操作是u = fθ (x),其中u∈RE是输入图像x的图像嵌入,由图像嵌入网络fθ提取,以θ为参数。类似地,通过ω参数化的文本嵌入网络 gω,得到输入文本 y 的文本嵌入 v ∈ RE 为 v = gω (y)。U 和 v 都用 l2范数标准化。图像和文本在嵌入空间中使用欧氏距离进行比较,即d(x,y)=‖u-v‖=‖fθ(x)-gω(y)‖。
图像集X与文本集Y通过配对相似性矩阵S进行对齐。这种跨模态的配对相似性由变量si,j∈S表示,当xi和yj相似时(即正对),其值为1,否则为0(即负对)。我们希望正数对之间的距离要明显低于负数对之间的距离。
训练、索引和查询阶段
一般来说,机器学习假定有两个不同的阶段,即训练和验证(或测试),它们按确切的顺序进行(尽管在持续学习中并非如此)。我们专注于用学习过的特征提取器(即我们案例中的嵌入网络)进行检索。在这种情况下,我们确定三个阶段(见图1):
训练(特征提取器(s)):如上节所述,训练阶段从图像和文本数据集X和Y学习嵌入网络,其结果是参数θ和ω。
索引(数据库数据):要索引的数据库数据集ˆX和ˆY使用嵌入网络进行处理,以获得文本和图像嵌入,随后在数据库中进行索引。请注意,训练数据和数据库数据不需要是相同的。
查询(查询数据):这个阶段计算查询样本和索引数据之间的相似度。其结果是一个排名,最相似的样本在最前面。在我们的跨模态案例中,有两个方向:用图像查询,从索引的文本中检索(im2txt);用文本查询,从索引的图像中检索(txt2im)。
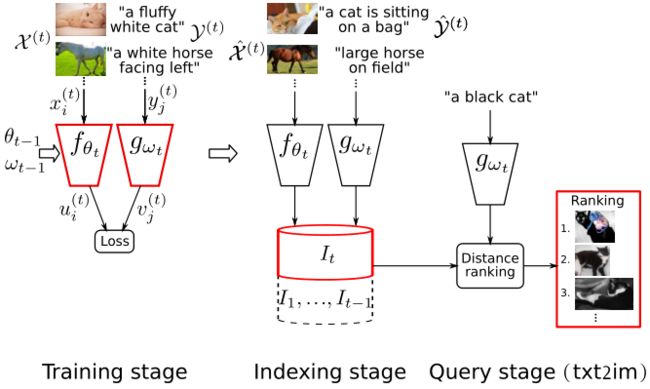
图1:连续跨模态检索的阶段(即训练特征提取器、索引和查询)。每个阶段的输出用红色突出显示(即特征提取器,指数和排名)。
请注意,这三个阶段被认为是以这种特定的顺序进行的,而部署的系统只执行查询阶段。为了简单起见,我们认为数据库数据也被用作训练数据,即ˆX=X,ˆY=Y。
持续检索的框架
现在我们考虑一个持续学习的环境,其中数据以任务序列呈现。每个任务T(t)=(X(t),Y(t),S(t))涉及不同领域的数据(如动物,车辆)。我们假设在对某一任务的数据进行索引之前,用该任务的数据(即训练阶段)对嵌入网络进行更新(即微调)。训练任务t后得到的参数是θt和ωt。
检索系统在查询阶段用每个任务的单独数据进行评估。我们考虑两种评估设置:已知任务和未知任务,取决于该信息在查询时是否可用(见图2a-b)。
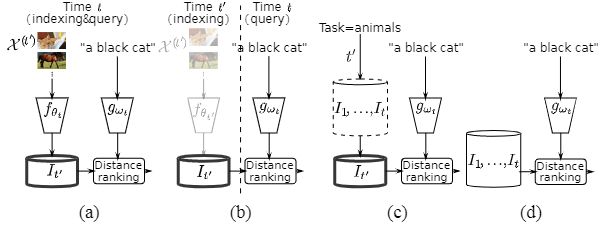
图2. 在时间t>t′(a-b)时被查询和检索(c-d)的前一个任务t′的索引数据的变体: (a) 重新索引,(b) 不重新索引,(c )任务已知,(d) 任务未知。
如前所述,网络是使用跨模态的正负对进行训练的。当所有的数据被联合呈现时,所有的负面对都可用于采样。然而,在连续的设置中,对是在同一任务中形成的,即结合X(t)和Y(t)的样本。因此,我们进一步将负数对(xi, yj)分类为任务内负数对(ITNP),当xi∈X(t)和yj∈Y(t)(sij=0,sij∈S(t)),或者分类为跨任务负数对(CTNP),当xi∈X(t′)和yj∈Y(t),t′≠t。请注意,为了简单起见,我们假设所有的正对都是任务内的。在持续检索中,CNTPs在训练期间是不可用的(见图3)。

图3. 持续跨模态检索中的配对类型:(a)在联合训练中可用,和(b)在持续学习中可用,即没有跨任务负对(CTNP)。CTNP对于避免不同任务的样本之间的重叠至关重要(底部)。
做不做重新索引?
传统的检索方案假设训练和索引是一次性进行的。在这种情况下,只有一个静态的嵌入集,在同一时间用同一个网络提取。同样的网络被用来从查询中提取嵌入。在持续检索中,情况可能并非如此,因为每次有新的任务出现时都要进行训练和索引。
重新索引:我们首先考虑跨模态检索的直接扩展,即假设在学习了一个新任务t之后,当前和以前的任务都被重新索引,并使用参数fθt和gωt的嵌入网络版本(见图2a)。我们把这种情况称为重新索引。然而,它的缺点是耗费时间和资源,因为它需要多次对相同的数据进行索引,并且总是需要访问以前任务的图像和文本样本。它的优点是数据库和查询样本都是用同一网络处理的。
无重新索引:我们还提出了无重新索引的变体,即在训练任务t后只对当前任务t的数据进行索引(见图2)。这个变体更有效率,因为数据库样本只处理一次,而且很灵活,因为它不需要访问以前的图像和文本(只需要访问它们的索引嵌入进行检索)。另一方面,没有重新索引会带来不对称性,因为查询嵌入是用fθt(或gωt)提取的,而数据库嵌入是用gωt′(或fθt′,t′≤t)。
跨模态嵌入中的灾难性遗忘
学习一个新的任务意味着网络参数的值会偏离以前的参数。当新任务与之前的任务有很大不同时,这一点尤其重要,因为新任务与之前的任务之间会产生干扰,导致后者的表现下降。为简单起见,我们将这种性能下降称为灾难性遗忘。在下文中,我们将确定在持续的跨模态检索中可能导致遗忘的几种现象。
嵌入网络:。我们首先单独考虑每个嵌入网络的遗忘,不考虑成对的相互作用。当它们的参数远离t - 1的最佳值时(见图4a),嵌入的u和v也会从它们之前的值中漂移。一般来说,新的值fθt和gωt比以前的fθt-1和gωt-1的鉴别力要低,导致性能降低,因为u(t)和v(t)的嵌入空间的鉴别力也低。
嵌入错位:在跨模态网络的特殊情况下,不同模态的嵌入可能有不同的漂移(见图4a)。这种在u和v空间的不平等漂移导致了额外的错位,也导致了比最优情况下更高的距离。请注意,使用连体网络或Triplet网络的单模态检索并不存在这个问题,因为各分支的参数是共享的。
任务重叠:负数对在嵌入空间中把不相似的样本拉走。然而,在持续检索中,CTNPs不能被取样(除非我们包括以前任务的一些样本)。CNTPs是不同任务的样本之间唯一的排斥力。如果没有它们,来自不同任务的样本很可能会在嵌入空间中重叠(见图4a)。在查询时知道任务使这个问题不那么重要,因为在查询时不考虑其他任务的数据。
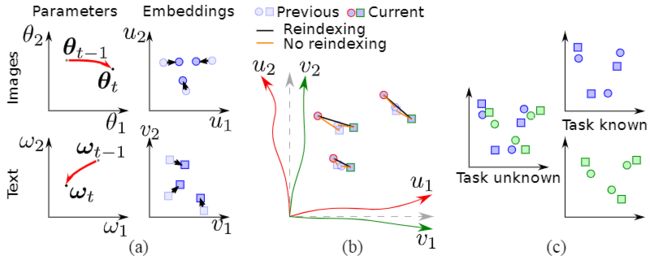
图4. 跨模态嵌入中遗忘的原因:(a)由于参数空间的漂移,嵌入网络变得不那么有辨别力,(b)不平等的漂移增加了跨模态的错位,(c)嵌入空间的任务重叠(当任务未知时)。
防止遗忘
下面我们提出几个工具,通过解决前面的因素来减轻遗忘的影响。
防止嵌入漂移
防止遗忘的一个常见方法是用损失中的二次项对权重进行规范化,以惩罚与以前任务的解决方案的加权欧氏距离(在参数空间)。这可以帮助避免嵌入中的重大漂移,并保持它们对以前任务的辨别力。我们可以把我们案例中的特殊正则化项写成:
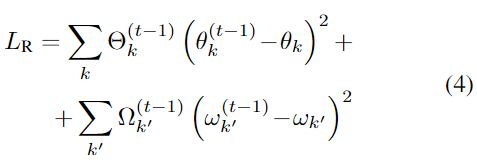
其中Θk和ωk′分别根据θk和ωk的重要性来控制之前任务的正则化强度。在第一个任务的训练期间,没有正则化,即Θ(0) k = 0,ω(0) k′ = 0。
计算重要性的方式在不同的方法中是不同的。我们考虑两种变体:
全局:这里我们估计关于损失的重要性,将弹性权重合并(EWC)适应于我们特定的三联体损失(LTR代表三联体损失):

这是由1和2中的三联体采样计算的,对Ωk′也是如此。这个损失已经考虑到了三联体和它们的相互作用。
分支:我们不估计取决于联合损失的重要性值,而是考虑独立地规范化每个分支。在这种情况下,我们使用记忆感知突触(MAS)的方法来估计重要性,它可以在无监督的情况下对每个有图像或文本的分支进行计算。图像分支的重要性被估计为:

这是在以前计算的基础上积累的。对于文本分支来说,Ωk′的估计是类似的。在这个方程中,l2 2是函数输出的平方l2准则,它被用来估计MAS方法中参数的重要性。最后的损失结合了(3)和(4),为L = LT + λ3LR。
防止不平等的漂移
为了防止不平等的漂移,我们建议通过在顶部共享层来捆绑网络(底部层必须保持特定的模态)。通过这种方式,不平等的漂移可以得到缓解,因为梯度是并列的,只在较低的层有差异。
在某些情况下,当文本和图像嵌入的漂移方向相反时,不对数据库进行重新索引可以成为缓解漂移的有效工具,因为只有其中一个嵌入受到影响,而另一个则保持固定。图4b说明了在这种情况下,不重新索引如何使匹配对保持较低的距离。
解耦检索方向
到目前为止,我们假设只有一个单一的模型被训练来执行文本到图像和图像到文本的检索。当嵌入物被重新索引时,这是合理的,因为结构和损失是对称的。然而,当数据库数据没有被重新索引而查询被重新索引时,遗忘是不对称的。在这种情况下,我们可以将两个方向解耦,为每个方向训练一个模型,只对查询分支的权重进行规范化处理。 这在某些情况下也是有益的,当图像和文本嵌入漂移到不同的方向时,保持一个固定的位置可以保持较低的距离(见图4b的例子)。
防止跨任务重叠
缺乏CTNP会导致跨任务重叠,因为没有力量将它们分开。 然而,减少漂移,通过权重规则化和共享层保持嵌入的鉴别性,可能间接地有助于保持任务分离(我们在实验中观察到了这一点)。然而,我们做了一些初步的实验,在具有解耦检索方向的模型中使用已经索引的嵌入创建伪CTNPs(ui,xj)(类似于文本到图像检索的其他方向),但我们发现它们在我们的实验中没有帮助,可能是因为不对称的力量,只推动一个分支的嵌入。 在这种情况下,梯度只通过一个分支进行反向传播。 我们把更深入的研究留给未来的工作。
实验
基线和变体:我们在两个涉及图像和文本的任务中评估了我们持续的跨模态框架的不同变体,一个侧重于区域,另一个侧重于场景。我们遵循《Learning two-branch neural networks for image-text match-ing tasks.》中双分支网络的实现,其中4096维的图像特征是从ImageNet上训练的VGG-19模型中提取的,而文本特征是6000维的HGLMM特征(用PCA从最初的18000维减少)。图像分支包括两个额外的全连接层,其大小为2048和64(对于SeViGe,对于SeCOCO为2048和512),在顶部和l2归一化,文本分支也是如此。我们的研究重点是上面的两个全连接层,而初始特征提取器保持固定。与《Learning two-branch neural networks for image-text match-ing tasks.》一样,我们设定λ1=1.0,λ2=1.5,margin m=0.05。所得模型用Adam和0.0001的学习率进行训练,并在ReLu后使用概率为0.5的dropout。我们评估了这个架构的不同变化:
- 联合与持续。我们将拟议框架的变体(持续)与两个共同学习所有任务(联合)的基线进行比较,不同之处在于训练期间是否对CTNP进行采样。
- 检索方向。我们对文本到图像检索(txt2im)和图像到文本检索(im2txt)进行评估。
- 任务知识。我们对任务已知和未知的两种情况进行评估。
- 重新索引。我们认为数据库样本的嵌入是在学习相应任务时提取的(没有重新索引),或者与查询嵌入同时进行(重新索引)。
- 权重正则化。我们考虑在没有正则化的情况下进行微调(ft),在损失上进行联合正则化(EWC),在每个u和v的嵌入上独立进行正则化(MAS)。我们设定λ3=106。
- 解耦方向。对于无重新索引,我们还考虑了一些变体,其中EWC或MAS只在提取查询嵌入的分支中计算(例如MAStxt,当MAS只在文本分支中计算时)。在这种情况下,我们进行两个不同的实验,每个实验都针对一个特定的检索方向。
- 层共享。我们考虑保持两个嵌入网络的独立性(不共享)或共享顶部全连接层(共享)。我们考虑的实验是,每个任务都是通过学习一个新领域来更新嵌入网络。训练完模型后,对相同的训练数据进行索引(即我们提取图像和文本嵌入),然后就可以评估检索性能了。我们报告所有任务学习后的最终结果。我们使用Recall@K作为评价指标(K=10,其他K的结果在补充材料中),相对于同一领域的索引数据(已知)或所有领域的整个索引数据(未知)。我们将每个实验重复五次,并报告平均。
跨模态检索:我们评估了跨模态区域图像-文本检索的不同方法。两个方向的结果都显示在表1中。当任务是已知的时候,我们着重用平均数来评估,当任务是未知的时候(即所有领域的总和),用A+V+C来评估。我们首先观察到,正如预期的那样,联合训练所有的任务比连续设置提供更高的性能。这种优势的很大一部分是由于CTNP,因为联合训练的性能在没有采样的情况下明显下降。这提供了一个更现实和更严格的上界,因为在持续的情况下CTNP是不可用的。在任务已知的情况下,这种下降比较适中(已知1%∼2%,未知3%∼4%),因为任务重叠不是一个问题。这种下降仍然表明,CTNP仍然有助于塑造嵌入空间,使其具有辨别力,而不是简单地避免任务重叠。
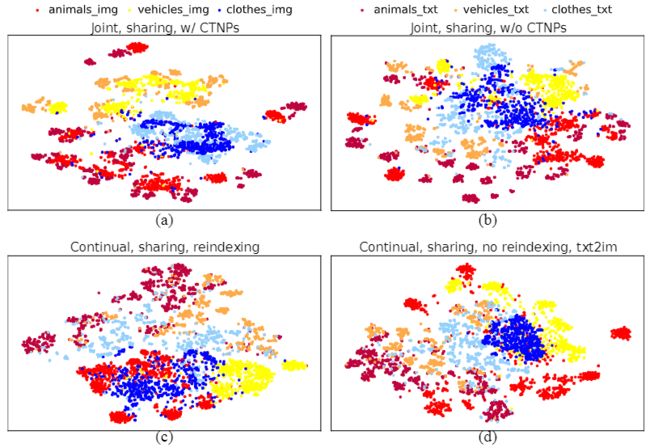
图5. SeViGe的跨模式嵌入空间的t-SNE可视化,共享架构:(a)联合训练(有CTNP),(b)联合训练(无CTNP),(c)持续(重新索引),和(d)持续(无重新索引)。
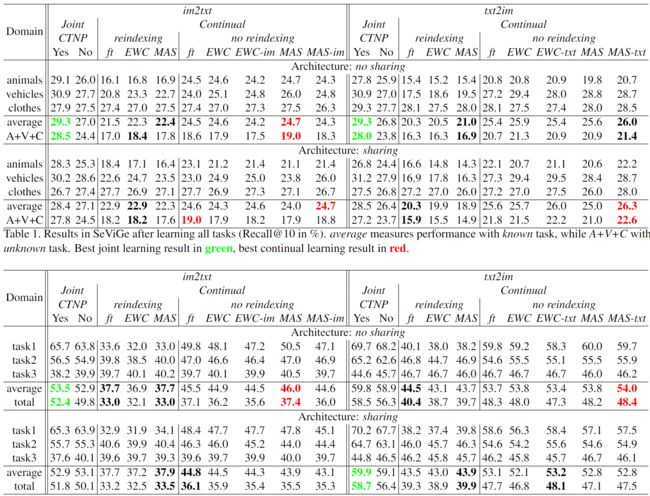
表2. 学习所有任务后的SeCOCO结果(Recall@10,单位:%)。平均衡量已知任务的性能,而未知任务的总性能。最佳联合学习结果为绿色,最佳持续学习结果为红色。
结论
本文首次提出关于遗忘如何影响多模态嵌入空间的研究,重点是跨模态检索。我们提出了一个连续的跨模态检索模型,强调了索引阶段的重要作用。在跨模态任务中,跨模态漂移也是遗忘的关键因素。我们评估了几种缓解遗忘的特定工具。