yolov5训练自己的数据集,xml转txt以及划分数据集
文章目录
-
- 1.XML格式转yolo_txt格式
- 2 划分数据集
1.XML格式转yolo_txt格式
需要注意XML内的xywh为图片尺寸的相应的比例,而txt需要归一化之后的比例。
此外cls类别需要使用阿拉伯数字1-N来表示,不能使用英文
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from pathlib import Path
class_name = ['bud', 'half', 'impurity', 'moldy', 'normal', 'peeling', 'smallpeeling']
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(xml_file, save_txt_file):
in_file = open(xml_file, encoding='UTF-8')
out_file = open(save_txt_file, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in class_name:
continue
cls_id = class_name.index(cls)
xml_box = obj.find('bndbox')
b = (float(xml_box.find('xmin').text), float(xml_box.find('xmax').text), float(xml_box.find('ymin').text),
float(xml_box.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == '__main__':
xml_path = "D:/HN/dataset/xml/" # "D:/HN/train/xml/" D:/HN/val/xml/
save_txt_path = "D:/HN/dataset/labels/" # "D:/HN/train/label/" D:/HN/val/labels/
if not os.path.exists(save_txt_path):
os.makedirs(save_txt_path)
xml_lists = os.listdir(xml_path)
for xml in xml_lists:
print("Do XML File:" + xml)
name = Path(xml).stem
xml_file = xml_path + xml
txt_path = save_txt_path + name + ".txt"
convert_annotation(xml_file, txt_path)
print("XML File End:" + xml_path)
print("Txt File Save On:" + save_txt_path)
2 划分数据集
yolov5对数据集的读取有两种不同的方式:
1.将训练数据集和验证数据集分别放在两个单独的文件夹中。
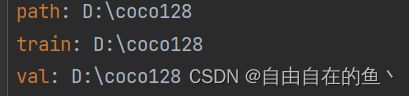
2.将训练数据和验证数据分别存储在两个txt文件中,从txt文件中读取数据集的位置。

在下列代码中move_xml_img函数使用将数据集划分到文件中进行读取,split_in_txt函数将数据集的路径存储在txt文件中。
# coding:utf-8
import os
import random
import argparse
from pathlib import Path
import shutil
def move_xml_img(lists, save_path, xml_path, img_path):
save_img_path = save_path + '/' + "images"
save_xml_path = save_path + '/' + "xml"
if not os.path.exists(save_img_path):
os.makedirs(save_img_path)
if not os.path.exists(save_xml_path):
os.makedirs(save_xml_path)
for list in lists:
name = Path(list).stem
save_img_path = save_path + '/' + "images" + '/'
save_xml_path = save_path + '/' + "xml" + '/'
img = img_path + name + ".jpg"
xml = xml_path + name + ".xml"
# print(img)
shutil.copy(img, save_img_path)
shutil.copy(xml, save_xml_path)
def split_in_txt(txt_path):
train_percent = 0.8 # 训练集和验证集所占比例。
val_percent = 0.2 # 训练集所占比例,可自己进行调整
img_path = txt_path + '/images/'
file_train_txt = open(txt_path + '/train.txt', 'w')
file_val_txt = open(txt_path + '/val.txt', 'w')
total_img = os.listdir(img_path)
t_p = int(num * train_percent)
v_p = int(num * val_percent)
train_lists = random.sample(total_img, t_p)
val_lists = random.sample(total_img, v_p)
for train_list in train_lists:
path = img_path + train_list + '\n'
file_train_txt.write(path)
for val_list in val_lists:
path = img_path + val_list + '\n'
file_val_txt.write(path)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--xml_path', default='D:/HN/xml1/', type=str, help='input xml label path')
parser.add_argument('--img_path', default='D:/HN/image1/', type=str, help='output txt label path')
parser.add_argument('--save_path', default='D:/HN', type=str, help='output txt label path')
parser.add_argument('--txt_path', default='D:/HN/dataset', type=str, help='output txt label path')
opt = parser.parse_args()
train_percent = 0.8 # 训练集和验证集所占比例。
val_percent = 0.2 # 训练集所占比例,可自己进行调整
xml_path = opt.xml_path
img_path = opt.img_path
save_path = opt.save_path
txt_path = opt.txt_path
txt_or_not = False # False
total_xml = os.listdir(xml_path)
num = len(total_xml)
t_p = int(num * train_percent)
v_p = int(num * val_percent)
train_lists = random.sample(total_xml, t_p)
val_lists = random.sample(total_xml, v_p)
# 按顺序划分数据集
# train_csv = data_path_pd.iloc[:train_slice_point,:]
if txt_or_not:
train_path = save_path + '/' + "train"
val_path = save_path + '/' + "val"
print("Train datasets start")
move_xml_img(train_lists, train_path, xml_path, img_path)
print("Train datasets end")
print("Val datasets start")
move_xml_img(val_lists, val_path, xml_path, img_path)
print("Val datasets end")
print("End split train and val datasets")
else:
print("****split_in_txt start****")
split_in_txt(txt_path)
print("****split_in_txt end****")