python爬虫之爬取“唯美“壁纸,让你心花怒放


个人名片:
作者简介:一名大二在校生,热爱生活,爱好敲码!
\ 个人主页 :holy-wangle
➡系列内容: ️ tkinter前端窗口界面创建与优化
️ Java实现ATP小系统
✨个性签名: 不积跬步,无以至千里;不积小流,无以成江海
想要拥有大量的好看的壁纸和头像?跟我这一篇文章学习,如果一键爬取吧!!!!!
今天我补充上一篇文章无法爬取多页壁纸的内容,这是上一篇:python爬虫之爬取“唯美“主流图片
爬取url:https://pic.netbian.com/4kdongman/
到网页看看!!
我们选择一张图片查看照片的二进制文件在哪!

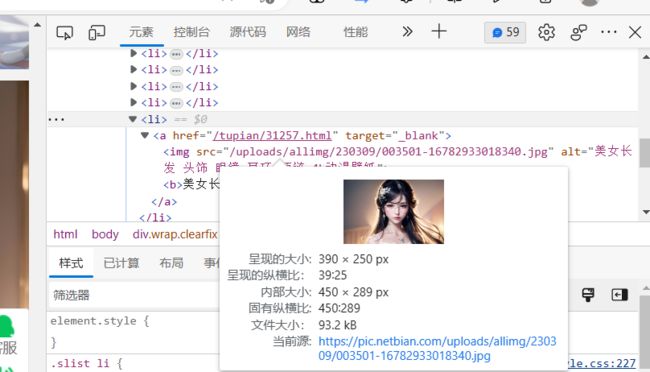
可以看见,这个当前源就是照片的真正存放位置,我们把它爬取下载即可!
先上代码!
# 导入需要用的模块
import requests
from lxml import etree
import os
# 创建一个:壁纸爬取类
class WallpaperCrawling(object):
# 初始化
def __init__(self):
self.url = 'https://pic.netbian.com/4kdongman/'
self.header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.49 '
}
# 用来拼接url
self.number = 2
# 爬取该url的网源代码并且转换为一般的形式然后返回这个值
@staticmethod
def crawling_page(url, header):
response = requests.get(url, headers=header)
page_text = response.text
return page_text
# 进行解析代码,提取图片,并且存储
def solve_page(self, page, header):
# 这是一种解析方式不懂的可以上网查找
tree = etree.HTML(page)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
# 判断是否有当前目录下有没有这个文件夹:picLipbs, 没有的话创建一个
if not os.path.exists('./picLibs'):
os.mkdir('./picLibs')
for li in li_list:
img_src = 'https://pic.netbian.com' + li.xpath('./a/img/@src')[0]
img_name = li.xpath('./a/img/@alt')[0] + '.jpg'
# 通用处理中文乱码解决方案
img_name = img_name.encode('iso-8859-1').decode('gbk')
img_name = img_name.replace('?', '').replace('*', '').replace('<', '').replace('> ', '')
# print(img_name,img_src)
# 请求图片,进行持久化存储
img_data = requests.get(url=img_src, headers=header).content
img_path = r"picLibs/" + img_name
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(img_name, '下载成功!!')
# 这里是实现翻页的关键,我这里首先拼接好下一页的url,然后再次调用run_spider(),就是用迭代的思想去实现
if self.number == 2:
self.url += ("index_%d.html" % self.number)
print(self.url)
self.number += 1
spider.run_spider()
else:
self.number += 1
print(self.number)
self.url = ('https://pic.netbian.com/4kdongman/index_%d.html' % self.number)
spider.run_spider()
def run_spider(self):
# 获取page
home_page = self.crawling_page(self.url, self.header)
# 解析数据并且存储图片
self.solve_page(home_page, self.header)
if __name__ == '__main__':
spider = WallpaperCrawling()
spider.run_spider()
我这里是写一个爬虫类实现爬取壁纸的!
# 初始化
def __init__(self):
self.url = 'https://pic.netbian.com/4kdongman/'
self.header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.49 '
}
# 用来拼接url
self.number = 2首先先初始化,设置要爬取的URL的网址,然后设置一个请求头,模拟浏览器发送请求,self.number=2,这里是等会要拿来拼接我们的翻页url的,等会再具体将讲!
def crawling_page(url, header):
response = requests.get(url, headers=header)
page_text = response.text
return page_text然后呢发送请求,获取网源代码!
# 进行解析代码,提取图片,并且存储
def solve_page(self, page, header):
# 这是一种解析方式不懂的可以上网查找
tree = etree.HTML(page)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
# 判断是否有当前目录下有没有这个文件夹:picLipbs, 没有的话创建一个
if not os.path.exists('./picLibs'):
os.mkdir('./picLibs')
for li in li_list:
img_src = 'https://pic.netbian.com' + li.xpath('./a/img/@src')[0]
img_name = li.xpath('./a/img/@alt')[0] + '.jpg'
# 通用处理中文乱码解决方案
img_name = img_name.encode('iso-8859-1').decode('gbk')
img_name = img_name.replace('?', '').replace('*', '').replace('<', '').replace('> ', '')
# print(img_name,img_src)
# 请求图片,进行持久化存储
img_data = requests.get(url=img_src, headers=header).content
img_path = r"picLibs/" + img_name
with open(img_path, 'wb') as fp:
fp.write(img_data)
print(img_name, '下载成功!!')这里进行解析、爬取、存储!
我这里是用xpath进行解析。解析就是什么?就是找到照片存储的位置呢,上面说的当前源的地址哦!
这个黑框可以帮助我们更好的找到存放位置!如果没找对位置,右边是不会出现文字的!
不懂可以去,百度一下,这里就不讲了!
img_name = img_name.replace('?', '').replace('*', '').replace('<', '').replace('> ', '')这里防止图片名字出现这些window命名不允许出现的符号!
# 这里是实现翻页的关键,我这里首先拼接好下一页的url,然后再次调用run_spider(),就是用迭代的思想去实现
if self.number == 2:
self.url += ("index_%d.html" % self.number)
print(self.url)
self.number += 1
spider.run_spider()
else:
self.number += 1
print(self.number)
self.url = ('https://pic.netbian.com/4kdongman/index_%d.html' % self.number)
spider.run_spider()d.实现翻页!

这里可以看见这是首页的url:https://pic.netbian.com/4kdongman/index.html
然后这是第二页的url:https://pic.netbian.com/4kdongman/index_2.html
然后第三页的url是:https://pic.netbian.com/4kdongman/index_3.html
依次类推而已!
发现这个好办事了!!!!!
我们第一页爬取完成后,判断self.number是不是等于2.如果是的话就可以就爬取当前页,然后+1后面就迭代爬取每一页了!
if self.number == 2:
self.url += ("index_%d.html" % self.number)
print(self.url)
self.number += 1
spider.run_spider()
else:
self.number += 1
print(self.number)
self.url = ('https://pic.netbian.com/4kdongman/index_%d.html' % self.number)
spider.run_spider()我们看看爬取的效果是怎么样的!!!!



这是正文!!
这里会一直爬取到没有的爬!

感谢各位的观看,创作不易,能不能给哥们来一个点赞呢!!!
好了,今天的分享就这么多了,有什么不清楚或者我写错的地方,请多多指教!
私信,评论我呗!!!!!!
关注我下一篇不迷路哦!