Redis源码解析-基本数据结构
基本的数据结构
SDS
对标的就是 C 中的字符串,能够有如下的优点
**1.O(1) 时间获得长度 **
sds保存
len就好了2.杜绝缓冲区溢出
进行如同
strcat之类的函数时候会判断剩余的空间是否是能够安全的操作如果空间不足会使用独特的内存分配和释放的策略(预分配 & 惰性释放)
3.减少内存重新分配次数
下面的 结构体 介绍了存储结构,在分配内存的时候会预先进行内存的分配
- 如果修改之后
len是 < 1MB的,那么我们再预先分配len大小 的空余空间- 如果修改后的
len是 > 1MB的,那么我们就预先分配 1MB 的空间(分配太多可能浪费)- 惰性释放就是不直接释放,用
free记录下空闲的空间长度就好了4.二进制安全
可能存储 视频类数据 ,内部有
\0, 那么我们就不能够以\0为结果,我们以len为结尾,就能够安全的存储 诸如视频类的数据5.兼容C字符串
末尾加一个
\0就好了,但是我们是以len为结尾的6.禁止内存对齐节省空间
如下,禁止字节对齐,节省空间
struct __attribute__ ((__packed__)) sdshdr8 { // __attribute__ 禁止cpu进行字节对齐,能够很好的节省空间, 但是牺牲了部分时间
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
链表
没啥好说的,就是简单的实现了 双向链表
字典
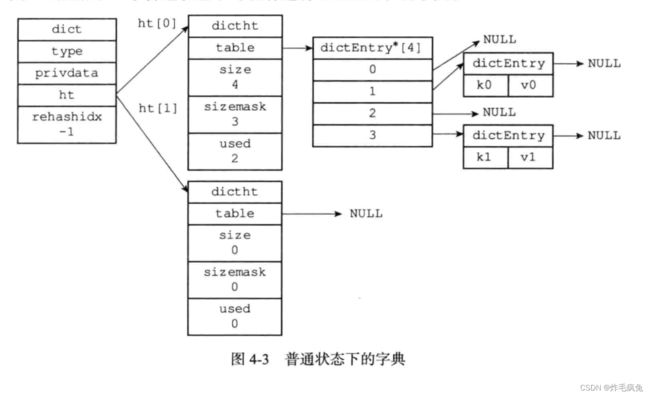
Type 结构里面就有存放 哈希函数 用于计算哈希索引值
存在有两个哈希表 :
dictht用于rehash的操作为了解决
hash collision==> 采用了链地址法,但是新的 entry 放在了链表的最前面
// dict Entry, 使用 Union 节省空间
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 链地址法解决 哈希冲突, 冲突的直接用链表串起来就好了
} dictEntry;
Rehash
随着操作的执行,哈希表的负担会变大, 所以采取的策略是进行 rehash 操作。也就是将一个哈希表中的所有 entry 重新映射到 另一个哈希表中,这也就是为啥有两个
hashtable
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
// 要开始 Rehash 了
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
⚠️: 如果是在 Redis 进行持久化 的时候就不要进行 Rehash 操作了
因为 在持久化时候会开启子进程后台写入,触犯 COW,这时候如果 rehash 会造成大量的拷贝行为,也就是父子不能共享了。 COW原理讲解
渐进式Rehash
因为 Redis 是单线程的, 如果说我们的 Rehash 操作的 entry 过多, 那么就会较长时间的占用主进程的时间,这不是我们希望的。
因此 Rehash 操作不是一次性完成,而是每次完成一点点,多次完成的
IntSet
专门用来存储整数集合的数据结构,内部能够保证他有序且唯一
// 结构体定义
typedef struct intset {
uint32_t encoding; // 表示带符号的【元素类型】,默认是 int_16
uint32_t length; // 按需分配的长度
int8_t contents[]; // 动态数组,其实存储的数据不一定是 int_8类型哦
} intset;
encoding就是表示存储的数据的类型,如int_64、int_32、int_16, 通过宏定义来区分
/* Note that these encodings are ordered, so:
* INTSET_ENC_INT16 < INTSET_ENC_INT32 < INTSET_ENC_INT64. */
#define INTSET_ENC_INT16 (sizeof(int16_t)) // 宏定义 sizeof 来区分不同的数据类型
#define INTSET_ENC_INT32 (sizeof(int32_t))
#define INTSET_ENC_INT64 (sizeof(int64_t))
/* Return the required encoding for the provided value. */
static uint8_t _intsetValueEncoding(int64_t v) {
if (v < INT32_MIN || v > INT32_MAX)
return INTSET_ENC_INT64;
else if (v < INT16_MIN || v > INT16_MAX)
return INTSET_ENC_INT32;
else
return INTSET_ENC_INT16;
}
Intset 的插入和升级
前面可以看到 IntSet 内部存储使用的是 uint8_t的数组存储,其实根本不存储 uint8_t类型的,而是存储 16、32、64的,取决于数组中 类型最大的元素的类型是啥
插入数据 & 更新的流程
为什么这么做,优点是什么?
提升灵活性
因为
C中存储数据的集合中 数据类型 还是尽量一致比较好,底部能够自动升级来适应新的元素,能将 任意类型整数加入集合 不用担心类型错误节约内存
因为我们支持
int64_t嘛,如果说全部都是 64 位的不太浪费空间了嘛。我们可以当用到了 64 位的时候才升级,如果说用不到的话那就不用占用那么大空间了。
Redis 高级数据结构
1.redis_object
// redis Object 对象的结构体定义
typedef struct redisObject { // redis object, 内部才是使用了之前的基础的一些数据结构
unsigned type:4; // 类型, 可以是字符串、列表、哈希、集合、有序集合
unsigned encoding:4; // 编码
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount; // 引用计数自动内存回收
void *ptr; // 指向底层数据结构的指针
} robj;
// type 类型的话就是宏定义的嘛
/* The actual Redis Object */
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */
// ============================================================
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of ziplists */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
其中
encoding也就是编码类型表明了这个对象底层采用的啥数据结构来进行的一个存储也就是一种特定的数据类型不一定关联固定的编码, 能够很好的提升灵活性和效率。
:如果说列表对象在包含的元素较少时候可以选用压缩列表作为底层实现,因为压缩列表更加的节省内存,在数据量比较少时候性能好。当然随着数据量上来了就讲底层存储的类型进行转换 。
实例:
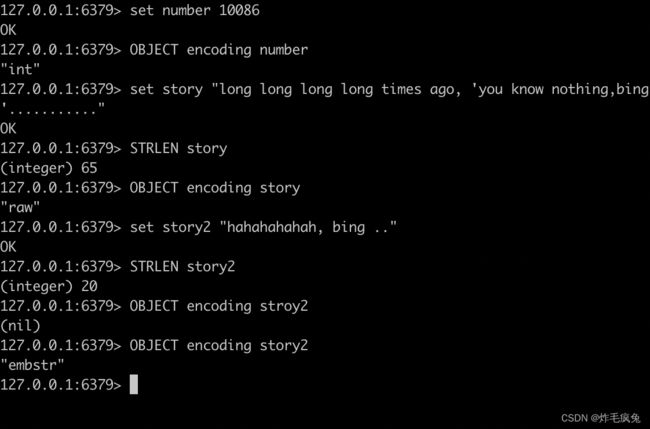
字符串类型在
len< 32 字节的时候采用的是embstr, 大于32字节的时候采用的是raw看源码好像是44字节可能我看的书比较老吧 haha
创建object 代码
// 创建 embstr 类型的String对象
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR; // 设定好编码类型为 EMB_STR
o->ptr = sh+1;
o->refcount = 1;
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
// 创建 redis_object
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution), or
* alternatively the LFU counter. */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return o;
}