ceph基础架构详解
1.存储分类:

直连式存储:U盘 硬盘(本地存储:本地存储的本地的文件系统,不能再网络上用.)
区域存储网络:专用存储网络(接交换机形成专用的存储网络) SAN==》对于稳定性要求比较高的:金融/银行
网络附加存储: 对外服务 by网络,任何设备都可以访问
2.分布式存储(是一个集群的概念)
2.1 即是通过网络将数据分散在多台独立的设备上.
分布式存储系统的特性:
1.可扩展性
2.低成本 高性能
3.易用 易管理

2.2 存在第一个节点,调度在第二个节点读取,怎么解决?
两种办法:
1.路由机制(路由表能把用户的请求路由到合适的节点上获取数据)
2.每个节点都存放副本==》没有分布式的意义了(每个节点都保存了完整的数据集)
2.3 传统的架构

一部分存数据 一部分存元数据
客户端访问文件给的是文件名/路径,==》那些编号的块存放了这个文件的数据

如果把一个文件分散到多个节点上存储,传统机制在一个分区上组织元数据
分开存放==》datanode只提供存储空间,找一个固定的地方存元数据(路由服务器节点)
client把请求发送给namenode把要存的文件按我们指定的大小进行切块==》每一块当成独立的文件完成路由和调度
再读数据的时候,要先联系元数据服务器,元数据服务器返回给他信息后,,要通过元数据服务器==》每一个文件被切了多少块,每一块在哪个服务器,快和块之间如何偏移的,不能错乱了组合,并行的从各个节点加载,组合,拼接==》完成划分
3.1传统分布式架构图
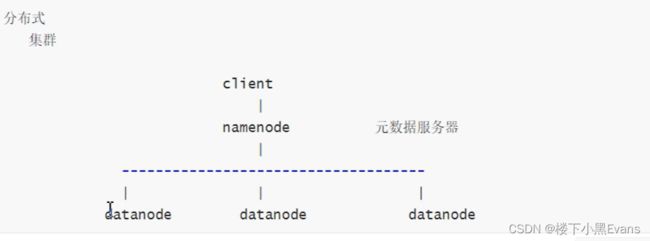
datanode:数据节点,真正存放数据的节点
元数据:用来描述文件的特征,例如:权限、创建时间、数据要存在哪里等。
3.2 两个问题
1. metadata很小但密集(几K)访问任何文件都要访问
2. namenode宕机了:
为了高性能并且访问频次很高,所以放在内存中,消耗内存空间,并且容易丢失元数据
一种机制:同步的持久存储在硬盘上,文件修改==》元数据也要修改,
不知道哪个会被修改,大量的修改操作是随机的,而随机I/O会非常慢,为了高效的能够让这些非常密集的文件修改操作搞笑存储到磁盘上
==》不直接改了, 把改的操作请求记下来,至于改的是什么不真正去修改,如果想还原的话,直接把日志重放一遍就行了==》AOF(顺序写),追加写,恢复很慢
3.3解决逻辑:
为了避免有一个元数据中心服务器成为整个系统的性能瓶颈所在==》 舍去中心节点,对文件做hash运算,映射到对应的存储节点,查也是同样计算,去查==》crush(通过计算方式完成对象路由的一个算法)
就是没中心节点,没元数据服务器,实时计算得到的,hash计算对cpu的消耗很小,计算是无状态的,随便扩展嘛
ceph根本上它的存储服务只是一个api==》librados (没法挂载访问),只能自己写程序,终端用户没法写嘛
3.4传统分布式存储扩展:
1.Hadoop HDFS: 大数据分布式文件系统.
HDFS:分布式文件系统. 是Hadoop系统的重要组成部分. 是Hadoop的一个存储组件.
(到现在都不能随机写,只能读,一些交互的操作场景做不了)
HDFS优点: 1.高容错性.:数据自动保存多个副本,副本丢失后会自动恢复.
2.数据访问机制好: 一次写入、多次读取,保证数据的一致性.
3.扩展能力强,适合大数据文件的存储.
HDFS缺点: 1.低延迟数据访问:难以应付毫秒以下的应用.
2.海量小文件存取:会占用NameNode大量内存. ?
3.一个文件只能有一个写入者.
4.1 ↓ ceph与传统分布式架构不同的是:
==》新时代SDS代表性产品
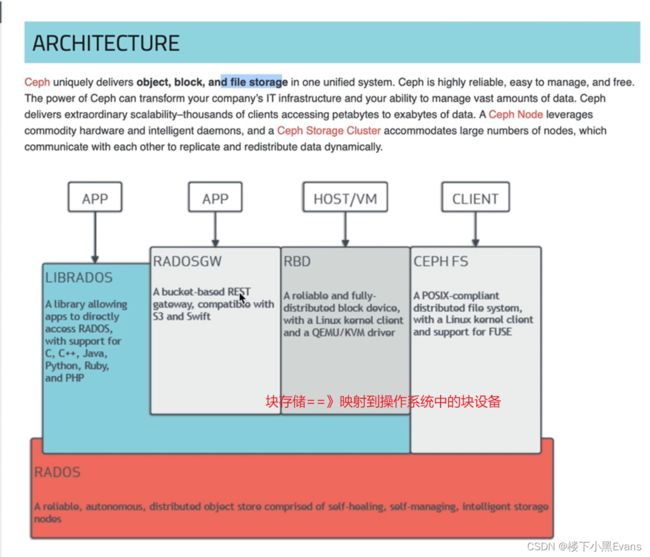
每一个小分块不再叫分片了,而是叫对象(很大 64M/128M)==》每一个对象自带元数据
rados存储集群是一个底层服务
所以 我们如果想在ceph上存数据,我们就需要调librados的API or 自己写代码调API,它能帮你切割成固定大小的对象并分散的存储到rados集群上
librados:基础库. 是对rados进行抽象和封装,并向上层提供API , 以便直接基于RADOS(而不是整个ceph)进行应用开发. rados是一个对象存储系统,因此,librados实现的API也只是针对对像存储功能的。
==》在librados基础上也提供了几个接口:(他们的作用是在librados库的基础上提供抽象层次更高、更便于应用或客户端使用的上层接口.)
cephfs:就可以挂载了,跟NFS很像,需要用到一个MDSs(metadataServer)
RBD:ceph目前用的最广泛最稳定的接口(块设备接口,在client映射到内核,识别成dev下的某个设备访问)==》挂载直接使用
radosGW:更抽象的跨域的对象存储?(云存储接口,对象网关接口)提供http/s的接口
这三个都是ceph的客户端,避免用户写软件,便可直接跟librados进行交互,
相当于只是把rados存储后端的服务进一步抽象了而已
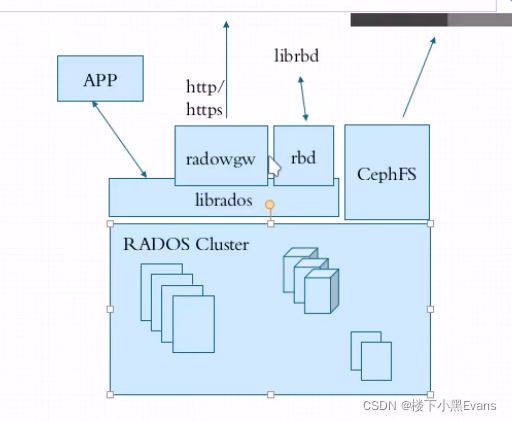
4.2 rados集群运行图:

rados内部:存储集群在主机本地以什么形式提供存储空间的呢==》存文件系统呗(先通过某一类客户端接入==》(借助api接口,文件先切成对象)
所有数据都在同一个平面上,因为他不是文件系统没有目录,所以所有文件均不可同名
每一个分区叫做存储池,大小取决于底层的存储空间,
OSD:对象存储设备,真正存储数据的地方,osd会定期把自己的状态上报给monitors
如果由异常的话,整个集群就会进行数据的分配
PG:就是归置组(每个对象一定属于某一个pool的PG)
POOL:存储池
4.3 运行在主机之上的两个守护进程:
Monitor:主要是负责监控整个集群的一个状态情况(客户端可以很直观的看到目前集群的情况)
它是集群元数据,而非文件元数据服务器,为了维护整个集群正常运行而设置的,离开了这个节点,集群内部就没法协调了,所以要做高可用 !并且:(monitor是集群运行状态图的持有者),一般是奇数个(至少三个)==》负责监控整个集群中有多少个pool,每个pool有多少个PG,每个PG有哪些OSD,都由它来维护 (ps: 认证中心,任何认证都需要多个monitor,通过cephx协议进行认证)
mgr:mngr 实现一些监控类的组件 ==>无状态的
Done!