Hive---常见问题
1、left join 和 left semi join 的区别与联系
当主表与关联表的关联列都存在重复数据时,由于产生笛卡尔积,使用left join是低效的。此时使用left semi join或者in时,往往能快速的查询出结果。但是当需要查询右表的列时就只能使用left join了。
联系:他们都是 hive join 方式的一种,join on 属于 common join(shuffle join/reduce join),而 left semi join 则属于 map join(broadcast join)的一种变体,从名字可以看出他们的实现原理有差异。
区别:
(1)LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现。比如下面两条语句执行结果是一样的:
select*from wedw_dw.t_user t1left semi join wedw_dw.t_order t2on t1.user_id = t2.user_id;
select*from wedw_dw.t_user t1where t1.user_id in (select user_id from wedw_dw.t_order) ;
(2)LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方都不行。
(3)因为 left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,而 join 则会一直遍历。这就导致右表有重复值得情况下 left semi join 只产生一条,join 会产生多条,也会导致 left semi join 的性能更高。
(4)left semi join 是只传递表的 join key 给 map 阶段,因此left semi join 中最后 select 的结果只许出现左表。因为右表只有 join key 参与关联计算了,而left join on 默认是整个关系模型都参与计算了
2、hive为什么没有索引
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键。但是索引占空间而且要不断update,不如分区、分桶来得合算。
3、hive中count(*)、count(1)、count(某字段)的区别
count(*):所有行进行统计,包括NULL行;
count(1):所有行进行统计,包括NULL行;
count(column):对column中非Null进行统计;
区别:count(*)和count(1)基本没什么差别,count(1)和count(column)的区别:count(1):所有行进行统计,包括NULL行;count(column)只对column中非Null进行统计。
4、HQL 转换为 MR 任务流程说明
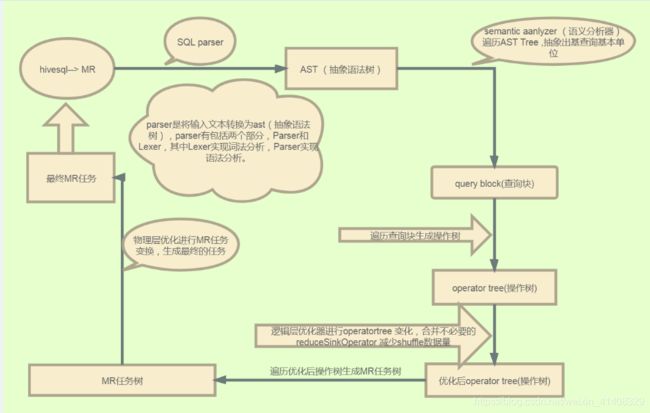
1).进入程序,利用Antlr框架定义HQL的语法规则,对HQL完成词法语法解析,将HQL转换为为AST(抽象语法树);
2).遍历AST,抽象出查询的基本组成单元QueryBlock(查询块),可以理解为最小的查询执行单元;
3).遍历QueryBlock,将其转换为OperatorTree(操作树,也就是逻辑执行计划),可以理解为不可拆分的一个逻辑执行单元;
4).使用逻辑优化器对OperatorTree(操作树)进行逻辑优化。例如合并不必要的ReduceSinkOperator,减少Shuffle数据量;
5).遍历OperatorTree,转换为TaskTree。也就是翻译为MR任务的流程,将逻辑执行计划转换为物理执行计划;
6).使用物理优化器对TaskTree进行物理优化;
7).生成最终的执行计划,提交任务到Hadoop集群运行。
5.内部表和外部表的区别
元数据:本质上只是用来存储hive中有哪些数据库,哪些表,表的模式,目录,分区,索引以及命名空间。为数据库创建的目录一般在hive数据仓库目录下。
区别:
主要体现在load与drop(是否同时删除元数据与数据)的操作上:
(1) Hive创建内部表时,会将数据移动到数据仓库指向的路径,也就是hive所在的hdfs路径,hive管理数据的生命周期;
创建外部表时,仅记录数据所在的路径,不对数据的位置做任何改变。
(2)在删除表时,内部表的元数据和数据会一起被删除。外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。创建外部表时,甚至不需要知道外部数据是否存在,可以把创建数据推迟到创建表之后才进行。
6.内部表和外部表的应用场景
-
每天采集的ng日志和埋点日志,在存储的时候建议使用外部表,因为日志数据是采集程序实时采集进来的,一旦被误删,恢复起来非常麻烦。而且外部表方便数据的共享。
-
抽取过来的业务数据,其实用外部表或者内部表问题都不大,就算被误删,恢复起来也是很快的,如果需要对数据内容和元数据进行紧凑的管理, 那还是建议使用内部表
-
在做统计分析时候用到的中间表,结果表可以使用内部表,因为这些数据不需要共享,使用内部表更为合适。并且很多时候结果分区表我们只需要保留最近3天的数据,用外部表的时候删除分区时无法删除数据。
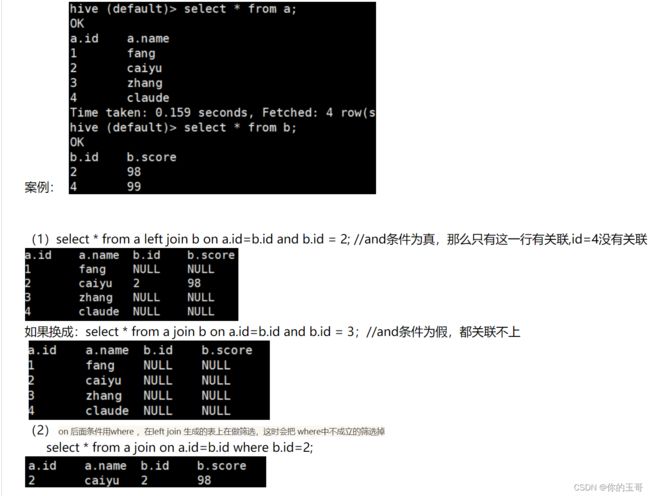
7、a left jion b后面 跟where和and的区别
left join 后加where 约束整个查询结果;
left join 后加and,and条件不能限制左表,仅能限制右表。
8、一条hive语句在mr中的执行过程,在MR中怎么实现Join的
以 select a.id, b.id from a join b on a.id = b.id为例:
处理逻辑:
1.map阶段,把所有输入拆分为k,v形式。其中k是我们要关联的字段。
Map输出的 value 为 join 之后所关心的(select或者where中需要
用到的)列;同时在value中还会包含表的 Tag 信息,用于标明此val
ue对应哪个表。如果输入是a相关的文件,那么map阶段的value加上标识符"a",
表示是a的输出。对于b文件,加上标识符"b"。
2.shuffle阶段,根据key的值进行hash,并将key/value按照hash值推
送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中。
3.reduce阶段,将每个k下的value列表拆分为分别来自a和b的两部分,
然后双层循环做笛卡尔积即可
4.注意的是,因为是left join,所以在reduce阶段,如果employee对
应的company_id有,而salary没有,注意要输出此部分数据。