Scikit-learn中的Pipeline:让机器学习流程更加简单、高效、可靠
文章目录
- 1 什么是Pipeline
- 2 Pipeline的基本用法
-
- 2.1 数据准备工作
- 2.2 定义Pipeline对象
- 2.3 训练Pipeline对象
- 2.4 使用Pipeline对象进行预测和评估
- 3 Pipeline的高级用法
-
- 3.1 GridSearchCV与Pipeline
- 3.2 make_union与Pipeline
- 3.3 FeatureUnion与Pipeline
Scikit-learn是一个非常流行的机器学习库,提供了各种各样的算法、工具和API,让用户可以轻松地构建和调整机器学习模型。其中一个非常有用的工具是Pipeline,它可以将多个数据预处理步骤和机器学习模型组合在一起,构建起整个机器学习流程。
在这篇博客中,我们将介绍Scikit-learn中的Pipeline,包括Pipeline的基本概念、使用方法和实际案例。这篇博客将将解如何使用Pipeline来构建高效且可靠的机器学习流程,使你的机器学习任务更加简单、高效和可靠。
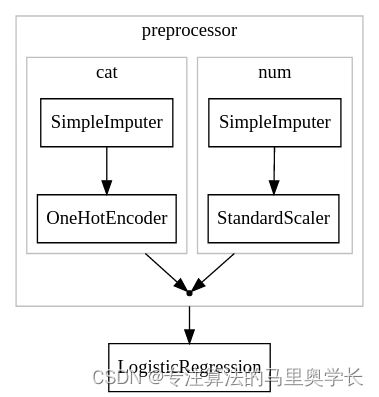
1 什么是Pipeline
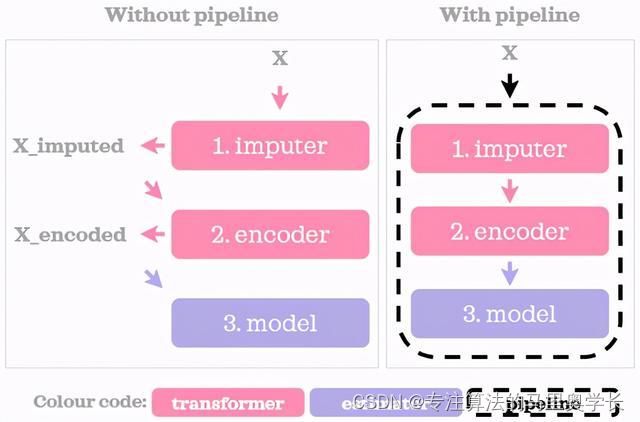
Pipeline是Scikit-learn中的一个类,它允许用户将多个数据预处理步骤和机器学习模型组合成一个整体。具体而言,Pipeline将多个估算器对象串联在一起,其中估算器可以是数据预处理步骤(如缺失值填充、特征缩放、特征选择等)或机器学习模型(如线性回归、决策树、支持向量机等)。Pipeline对象可以像普通的估算器一样进行训练、预测和评估,并且可以与GridSearchCV等工具一起使用,对估算器参数进行调优。
使用Pipeline的好处是显而易见的:它使机器学习流程更加简单、高效和可靠。通过将多个步骤串联在一起,Pipeline可以避免许多常见的错误,例如将测试集数据泄露到训练集中,或者忘记对所有特征进行相同的预处理。Pipeline还可以减少代码量,并使代码更易于维护和修改。此外,使用Pipeline可以使参数搜索空间更小,从而加快模型调整的速度。
2 Pipeline的基本用法
2.1 数据准备工作
在使用Pipeline之前,你需要准备好数据集。将数据集分成训练集和测试集,并将它们分别用于训练和评估Pipeline对象。
例如,假设你正在处理一个二元分类问题,数据集包含100个样本,每个样本有10个特征和一个二元标签。可以使用Scikit-learn的train_test_split函数将数据集分成训练集和测试集:
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(n_samples=100, n_features=10, n_classes=2, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2.2 定义Pipeline对象
接下来,需要定义Pipeline对象。定义Pipeline对象的方法是创建一个元组列表,其中每个元组表示一个步骤,格式为(步骤名称, 估算器对象)。可以使用make_pipeline函数来创建一个Pipeline对象,它会自动为每个步骤分配一个唯一的名称。
例如,假设想要将数据进行特征缩放,并使用支持向量机模型进行分类。可以定义一个Pipeline对象,其中包含两个步骤:
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
pipe = make_pipeline(
StandardScaler(),
SVC()
)
在上面的代码中,第一个步骤是使用StandardScaler进行特征缩放,第二个步骤是使用SVC进行分类。
2.3 训练Pipeline对象
一旦定义了Pipeline对象,就可以将其视为一个普通的估算器对象,对其进行训练和调整。训练Pipeline对象非常简单,只需要调用它的fit方法并将训练数据集作为参数传入即可。
pipe.fit(X_train, y_train)
在训练过程中,Pipeline对象将按照定义的顺序依次执行每个步骤。例如,在上面的示例中,Pipeline对象将首先使用StandardScaler对特征进行缩放,然后使用SVC进行分类。
2.4 使用Pipeline对象进行预测和评估
训练完成后,可以使用Pipeline对象进行预测和评估。预测过程非常简单,只需要调用Pipeline对象的predict方法并将测试数据集作为参数传入即可。
y_pred = pipe.predict(X_test)
评估过程也非常简单,只需要调用Pipeline对象的score方法并将测试数据集和相应的标签作为参数传入即可。
score = pipe.score(X_test, y_test)
3 Pipeline的高级用法
除了上面介绍的基本用法之外,Pipeline还具有许多高级用法,可以帮助我们更好地控制机器学习流水线的行为。
3.1 GridSearchCV与Pipeline
GridSearchCV是一个可以自动搜索最佳参数组合的工具,可以与Pipeline结合使用。GridSearchCV会尝试所有可能的参数组合,并返回最佳参数组合及其对应的评分。
例如,假设我们正在处理一个分类问题,数据集包含100个样本,每个样本有10个特征和一个二元标签。可以使用Pipeline对象将数据进行特征缩放,并使用支持向量机模型进行分类,然后使用GridSearchCV搜索最佳参数组合。
from sklearn.model_selection import GridSearchCV
pipe = make_pipeline(
StandardScaler(),
SVC()
)
param_grid = {
'svc__C': [0.1, 1, 10],
'svc__gamma': [0.1, 1, 10],
}
grid = GridSearchCV(pipe, param_grid=param_grid, cv=5)
grid.fit(X_train, y_train)
print("Best parameters: ", grid.best_params_)
print("Best cross-validation score: {:.2f}".format(grid.best_score_))
print("Test set score: {:.2f}".format(grid.score(X_test, y_test)))
在上面的代码中,可以看到param_grid字典指定了要搜索的参数,其中’svc__C’和’svc__gamma’指定了SVC的两个超参数。在GridSearchCV中,这些参数名称必须以步骤名称和双下划线分隔符的形式指定,例如’svc__C’指定了SVC的C超参数。
3.2 make_union与Pipeline
有时候,我们可能希望将多个预处理步骤应用于同一数据集,然后将它们组合在一起,再将组合的结果送到估算器中进行训练。在这种情况下,可以使用make_union函数将多个预处理步骤组合在一起。
例如,假设正在处理一个分类问题,数据集包含100个样本,每个样本有10个特征和一个二元标签。我们想要将数据集分成两个子集,对每个子集进行不同的预处理,然后将预处理的结果合并在一起,并使用支持向量机模型进行分类。则可以使用make_union函数来实现这一目标。
from sklearn.pipeline import make_union
from sklearn.decomposition import PCA
union = make_union(
StandardScaler(),
PCA(n_components=3)
)
pipe = make_pipeline(
union,
SVC()
)
pipe.fit(X_train, y_train)
score = pipe.score(X_test, y_test)
在上面的代码中,可以看到make_union函数将两个预处理步骤组合在一起,其中一个步骤是使用StandardScaler进行特征缩放,另一个步骤是使用PCA进行降维。然后,Pipeline对象将使用这个组合预处理步骤的结果,并将其作为输入传递给支持向量机模型进行分类。
3.3 FeatureUnion与Pipeline
除了make_union函数之外,scikit-learn还提供了FeatureUnion类,用于将多个预处理步骤组合在一起。与make_union不同的是,FeatureUnion可以处理非数字特征(例如文本或图像)。
FeatureUnion的工作原理类似于Pipeline,它按顺序应用每个预处理步骤,然后将结果合并在一起。可以将FeatureUnion与其他转换器和估计器结合使用,例如CountVectorizer或TfidfVectorizer。
例如,假设我们正在处理一个分类问题,数据集包含100个样本,其中有一些文本特征和一些数字特征,我们想要将它们组合起来进行分类。可以使用FeatureUnion将两个预处理步骤组合在一起。
from sklearn.pipeline import FeatureUnion
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.preprocessing import StandardScaler
text_union = make_pipeline(
CountVectorizer(),
TfidfTransformer()
)
numeric_union = make_pipeline(
StandardScaler(),
PCA(n_components=3)
)
combined_features = FeatureUnion([
('text_features', text_union),
('numeric_features', numeric_union)
])
pipe = make_pipeline(
combined_features,
SVC()
)
pipe.fit(X_train, y_train)
score = pipe.score(X_test, y_test)
在上面的代码中,可以看到将两个预处理步骤组合在一起,其中一个步骤是处理文本特征,另一个步骤是处理数字特征。FeatureUnion按照指定的顺序依次处理每个预处理步骤,并将它们的结果组合在一起。最后,Pipeline对象将使用这些组合的特征并将其作为输入传递给支持向量机模型进行分类。
在这篇文章中,我们介绍了scikit-learn中的Pipeline类,并讨论了它如何帮助您在机器学习流程中自动化预处理步骤。Pipeline类能够将多个预处理步骤组合在一起,并按照指定的顺序应用它们。
此外,我们还介绍了Pipeline的高级用法,包括结合GridSearch进行网格搜索,以及使用make_union进行预处理的组合等。希望大家能够使用Pipeline和其他scikit-learn中提供的工具更加轻松地构建机器学习模型。