Elasticsearch terms聚合不准确的问题
Elasticsearch terms聚合不准确的问题
默认情况
默认情况下,terms聚合只返回文档数Top10的term统计。如果想返回更多的词项分桶,可以设置"size"参数。
Size参数
{
"aggs" : {
"products" : {
"terms" : {
"field" : "product",
"size" : 5
}
}
}
}
1.如果不指定,size默认10.
2.size参数决定了terms聚合最多有多少个term bucket返回给客户端(由协调节点返回)。
3.默认情况下协调节点向目标分片请求它们的Top size个term bucket. 之后每个分片的term bucket都在协调节点上reduce,最终返回给客户端。
统计误差 & 遗漏
这种协调节点先请求各自分片的top size词项统计列表,之后再在协调节点上合并最终top size的方式存在误差,以下面对product字段聚合为例:
{
"aggs" : {
"products" : {
"terms" : {
"field" : "product",
"size" : 5
}
}
}
}
假设目标索引共三个分片,并且各分片词项分布如下:
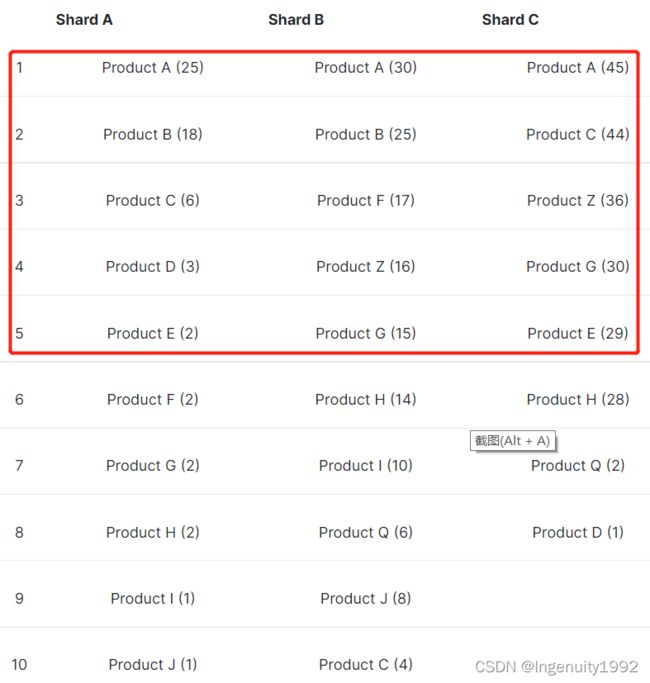
由于size=5,那么协调节点会要求各分片返回各自的top 5词项统计,也就是上图的红框部分。之后在协调节点上,对各分片的top5统计(红框内)进行reduce合并,合并后的结果为:
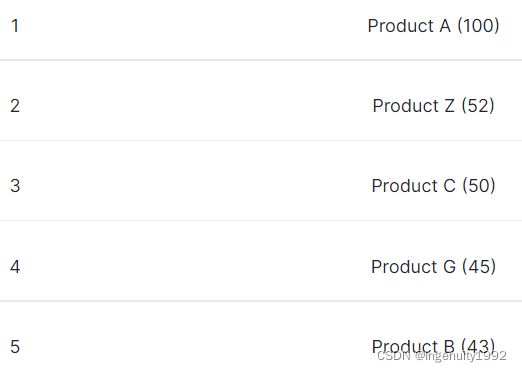
这个返回结果有以下问题需要注意:
- 由于 ProductA(100) 这个结果是由三个分片各自的ProductA统计结果合并得到的(25+30+45),因此排名第一的 ProductA(100) 是准确的,没什么问题。
- ProductC(50) 的统计结果由 ShardA 和 ShardC 的结果合并(6+44),但是这个结果却是有问题的,因为 ShardB 上还有 ProductC(4) 没有被统计到,原因是 ProductC(4) 并没有排进 ShardB 的Top5,导致统计遗漏。
- ProductZ(52) 也是由 ShardB 和 ShardC 的结果合并而来(16+36),但是这个结果却又是准确的,因为 ShardA 确实没有ProductC这个词项,不存在遗漏统计的问题。
- 协调节点在进行最终结果合并的时候,并没有办法区分情况2和情况3,因此不能保证最终terms聚合结果的词项统计是准确的。
- 对于 ProductH 这个词项,它在三个分片上都存在(2+14+28),ProductH(44)理应排进最终结果的第4位,但是最终结果中并没有 ProductH(44),因此 ProductH 被遗漏,原因是它没有排进各自分片的Top5.
Shard Size参数
为了解决以上问题,最容易想到的就是加大Size参数,size越大,最终结果越准。
但是过大的size会增加协调节点合并的压力,并且对于业务上来说,我明明只想要查询TOP5,可我却必须返回TOP100,这会导致不必要的网络传输和数据处理。
更合理的方案是显示设置"shard_size"参数,它可以控制协调节点要求各分片返回TOP shard_size。之后协调节点再从各"TOP shard_size"结果中合并出 “TOP size”。
"shard_size"不能设置得比"size"小,这没有意义,如果shard_size < size,ES后台会强制改写成shard_size = size。
两个反应误差的参数
{
...
"aggregations" : {
"products" : {
"doc_count_error_upper_bound" : 46,
"buckets" : [
{
"key" : "Product A",
"doc_count" : 100
},
{
"key" : "Product Z",
"doc_count" : 52
}
...
]
}
}
}
总的doc_count_error_upper_bound
可以看到返回的结果中有一个参数:“doc_count_error_upper_bound”。
这个参数表示了 遗漏词项(不在最终结果中的词项)的最大可能文档数。它的值是各分片返回的最后一个词项的文档数的和,就是红框中的第五行(2+15+29)=46。
在上面的例子中,这意味着,在最坏情况下,一个被遗漏的词项,至多可能出现在最终TOP5 的第4位,比如ProductH(44),实际应该是在第5。
各词项的doc_count_error_upper_bound
通过设置"show_term_doc_count_error":true来开启:
GET /_search
{
"aggs" : {
"products" : {
"terms" : {
"field" : "product",
"size" : 5,
"show_term_doc_count_error": true
}
}
}
}
{
...
"aggregations" : {
"products" : {
"doc_count_error_upper_bound" : 46,
"buckets" : [
{
"key" : "Product A",
"doc_count" : 100,
"doc_count_error_upper_bound" : 0
},
{
"key" : "Product Z",
"doc_count" : 52,
"doc_count_error_upper_bound" : 2
}
...
]
}
}
}
各词项的"doc_count_error_upper_bound"表示当前词项的最大误差。
它的值计算方式为:
- 从各分片返回结果中,筛选出没有出现当前词项的结果。
- 计算上述结果中最后一个词项的和。
比如ProductZ,只有ShardA的返回结果中没有,ShardA返回的最后一个词项的和是ProductE(2)。表示ProductZ的文档统计数最大可能有2的误差。
同理,有ProductC,只有ShardB没有,ShardB返回的最后一个词项的和是ProductG(15),表示ProductC的文档数最大可能有15的误差。
计算doc_count_error_upper_bound的条件
只有在聚合结果按照 文档数降序(默认就是这样) 排序的时候,才会统计这些误差。
以下情况返回"doc_count_error_upper_bound":“-1” :
- 按照词项值本身排序(无论升序还是降序),因为这种情况没有误差,因为此时如果分片的TOP N中没有该词项,那一定是这个词项就在该分片中不存在。
- 按照当前文档数升序,或者按照子聚合结果排序,也无法统计误差。
关于排序
默认按照文档数降序。
按文档数排序
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"order" : { "_count" : "asc" }
}
}
}
}
不鼓励按照子聚合排序或者文档数升序,否则误差没有上限,除非:
- 目标索引只有当个分片。
- 正在聚合的字段被用作文档索引路由的key。
- 按自聚合排序且子聚合为max或者min。

按词项本身排序
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"order" : { "_key/_term" : "asc" }
}
}
}
}

按照子聚合排序
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"order" : { "max_play_count" : "desc" }
},
"aggs" : {
"max_play_count" : { "max" : { "field" : "play_count" } }
}
}
}
}
// 如果内部聚合是多值的:
GET /_search
{
"aggs" : {
"genres" : {
"terms" : {
"field" : "genre",
"order" : { "playback_stats.max" : "desc" }
},
"aggs" : {
"playback_stats" : { "stats" : { "field" : "play_count" } }
}
}
}
}