22个高级Python知识点总结,干货!
No.1 一切皆对象
众所周知,Java中强调“一切皆对象”,但是Python中的面向对象比Java更加彻底,因为Python中的类(class)也是对象,函数(function)也是对象,而且Python的代码和模块也都是对象。
- Python中函数和类可以赋值给一个变量
- Python中函数和类可以存放到集合对象中
- Python中函数和类可以作为一个函数的参数传递给函数
- Python中函数和类可以作为返回值
Step.1

Step.2

Step.3
 Step.4
Step.4
Step.4

No.2 关键字type、object、class之间的关系
在Python中,object的实例是type,object是顶层类,没有基类;type的实例是type,type的基类是object。Python中的内置类型的基类是object,但是他们都是由type实例化而来,具体的值由内置类型实例化而来。在Python2.x的语法中用户自定义的类没有明确指定基类就默认是没有基类,在Python3.x的语法中,指定基类为object。

No.3 Python的内置类型
在Python中,对象有3个特征属性:
- 在内存中的地址,使用
id()函数进行查看 - 对象的类型
- 对象的默认值
Step.1 None类型
在Python解释器启动时,会创建一个None类型的None对象,并且None对象全局只有一个。
Step.2 数值类型
- ini类型
- float类型
- complex类型
- bool类型
Step.3 迭代类型
在Python中,迭代类型可以使用循环来进行遍历。
Step.4 序列类型
- list
- tuple
- str
- array
- range
- bytes, bytearray, memoryvie(二进制序列)
Step.5 映射类型
- dict
Step.6 集合类型
- set
- frozenset
Step.7 上下文管理类型
- with语句
Step.8 其他类型
- 模块
- class
- 实例
- 函数
- 方法
- 代码
- object对象
- type对象
- ellipsis(省略号)
- notimplemented
NO.4 魔法函数
Python中的魔法函数使用双下划线开始,以双下划线结尾
No.5 鸭子类型与白鹅类型
鸭子类型是程序设计中的推断风格,在鸭子类型中关注对象如何使用而不是类型本身。鸭子类型像多态一样工作但是没有继承。鸭子类型的概念来自于:“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
 白鹅类型是指只要
白鹅类型是指只要 cls 是抽象基类,即 cls 的元类是 abc.ABCMeta ,就可以使用 isinstance(obj, cls) 。
No.6 协议、 抽象基类、abc模块和序列之间的继承关系
- 协议:Python中的非正式接口,是允许Python实现多态的方式,协议是非正式的,不具备强制性,由约定和文档定义。
- 接口:泛指实体把自己提供给外界的一种抽象化物(可以为另一实体),用以由内部操作分离出外部沟通方法,使其能被内部修改而不影响外界其他实体与其交互的方式。
我们可以使用猴子补丁来实现协议,那么什么是猴子补丁呢?
猴子补丁就是在运行时修改模块或类,不去修改源代码,从而实现目标协议接口操作,这就是所谓的打猴子补丁。
Tips:猴子补丁的叫法起源于Zope框架,开发人员在修改Zope的Bug时,经常在程序后面追加更新的部分,这些
杂牌军补丁的英文名字叫做guerilla patch,后来写成gorllia,接着就变成了monkey。
猴子补丁的主要作用是:
- 在运行时替换方法、属性
- 在不修改源代码的情况下对程序本身添加之前没有的功能
- 在运行时对象中添加补丁,而不是在磁盘中的源代码上
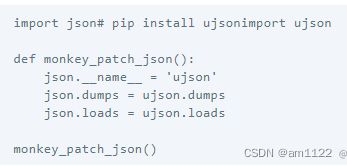
应用案例:假设写了一个很大的项目,处处使用了json模块来解析json文件,但是后来发现ujson比json性能更高,修改源代码是要修改很多处的,所以只需要在程序入口加入:
Python 的抽象基类有一个重要实用优势:可以使用 register 类方法在终端用户的代码中把某个类 “声明” 为一个抽象基类的 “虚拟” 子 类(为此,被注册的类必腨满足抽象其类对方法名称和签名的要求,最重要的是要满足底 层语义契约;但是,开发那个类时不用了解抽象基类,更不用继承抽象基类 。有时,为了让抽象类识别子类,甚至不用注册。要抑制住创建抽象基类的冲动。滥用抽象基类会造成灾难性后果,表明语言太注重表面形式 。
- 抽象基类不能被实例化(不能创建对象),通常是作为基类供子类继承,子类中重写虚函数,实现具体的接口。
- 判定某个对象的类型
- 强制子类必须实现某些方法
抽象基类的定义与使用
值得注意的是:Python 3.0-Python3.3之间,继承抽象基类的语法是class ClassName(metaclass=adc.ABCMeta),其他版本是:class ClassName(abc.ABC)。
- collections.abc模块中各个抽象基类的UML类图

No.7 isinstence和type的区别

python有我 元气满满 干货满满
No.8 类变量和实例变量
- 实例变量只能通过类的实例进行调用
- 修改模板对象创建的对象的属性,模板对象的属性不会改变
- 修改模板对象的属性,由模板对象创建的对象的属性会改变

No.9 类和实例属性以及方法的查找顺序
- 在Python 2.2之前只有经典类,到Python2.7还会兼容经典类,Python3.x以后只使用新式类,Python之前版本也会兼容新式类
- Python 2.2 及其之前类没有基类,Python新式类需要显式继承自
object,即使不显式继承也会默认继承自object - 经典类在类多重继承的时候是采用从左到右深度优先原则匹配方法的.而新式类是采用C3算法
- 经典类没有MRO和instance.mro()调用的
假定存在以下继承关系:

采用DFS(深度优先搜索算法)当调用了A的say_hello()方法的时候,系统会去B中查找如果B中也没有找到,那么去D中查找,很显然D中存在这个方法,但是DFS对于以下继承关系就会有缺陷:

在A的实例对象中调用say_hello方法时,系统会先去B中查找,由于B类中没有该方法的定义,所以会去D中查找,D类中也没有,系统就会认为该方法没有定义,其实该方法在C中定义了。所以考虑使用BFS(广度优先搜索算法),那么问题回到第一个继承关系,假定C和D具备重名方法,在调用A的实例的方法时,应该先在B中查找,理应调用D中的方法,但是使用BFS的时候,C类中的方法会覆盖D类中的方法。在Python 2.3以后的版本中,使用C3算法:
使用C3算法后的第二种继承顺序:

使用C3算法后的第一种继承顺序:
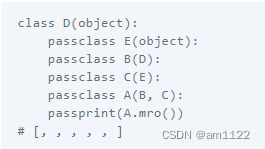
在这里仅介绍了算法的作用和演变历史
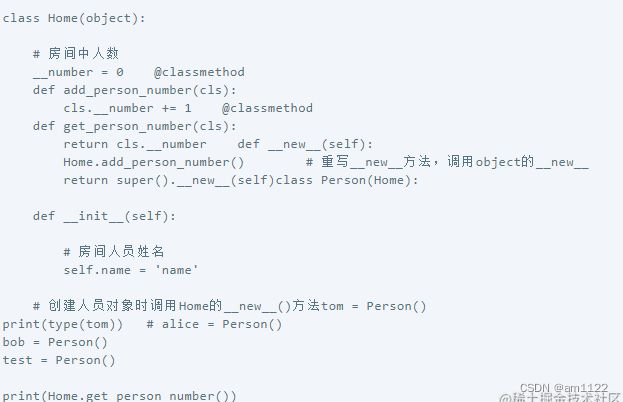
No.10 类方法、实例方法和静态方法

实例方法只能通过类的实例来调用;静态方法是一个独立的、无状态的函数,紧紧依托于所在类的命名空间上;类方法在为了获取类中维护的数据,比如:
No.11 数据封装和私有属性
Python中使用双下划线+属性名称实现类似于静态语言中的private修饰来实现数据封装。

No.12 Python的自省机制
自省(introspection)是一种自我检查行为。在计算机编程中,自省是指这种能力:检查某些事物以确定它是什么、它知道什么以及它能做什么。自省向程序员提供了极大的灵活性和控制力。
- dir([obj]):返回传递给它的任何对象的属性名称经过排序的列表(会有一些特殊的属性不包含在内)
- getattr(obj, attr):返回任意对象的任何属性 ,调用这个方法将返回obj中名为attr值的属性的值
- ... ...
No.13 super函数
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(type[, object-or-type]).xxx 。
super()函数用来调用MRO(类方法解析顺序表)的下一个类的方法。
No.14 Mixin继承
在设计上将Mixin类作为功能混入继承自Mixin的类。使用Mixin类实现多重继承应该注意:
- Mixin类必须表示某种功能
- 职责单一,如果要有多个功能,就要设计多个Mixin类
- 不依赖子类实现,Mixin类的存在仅仅是增加了子类的功能特性
- 即使子类没有继承这个Mixin类也可以工作

python有我 元气满满 干货满满
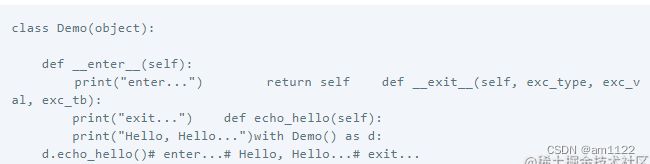
No.15 上下文管理器with语句与contextlib简化
普通的异常捕获机制:
![]() with简化了异常捕获写法:
with简化了异常捕获写法:

No.16 序列类型的分类
- 容器序列:list tuple deque
- 扁平序列:str bytes bytearray array.array
- 可变序列:list deque bytearray array
- 不可变序列:str tuple bytes
No.17 +、+=、extend()之间的区别于应用场景
首先看测试用例:
 由源代码片段可知:
由源代码片段可知:

No.18 使用bisect维护一个已排序的序列
 No.19 deque类详解
No.19 deque类详解
deque是Python中一个双端队列,能在队列两端以O(1)O(1)O(1)的效率插入数据,位于collections模块中。
![]()
deque类的源码:





deque
list存储数据的时候,内部实现是数组,数组的查找速度是很快的,但是插入和删除数据的速度堪忧。deque双端列表内部实现是双端队列。deuque适用队列和栈,并且是线程安全的。
deque提供append()和pop()函数实现在deque尾部添加和弹出数据,提供appendleft()和popleft()函数实现在deque头部添加和弹出元素。这4个函数的时间复杂度都是O(1)O(1)O(1)的,但是list的时间复杂度高达O(n)O(n)O(n)。
创建deque队列

源码






ChainMap
用来合并多个字典。
应用案例

源码



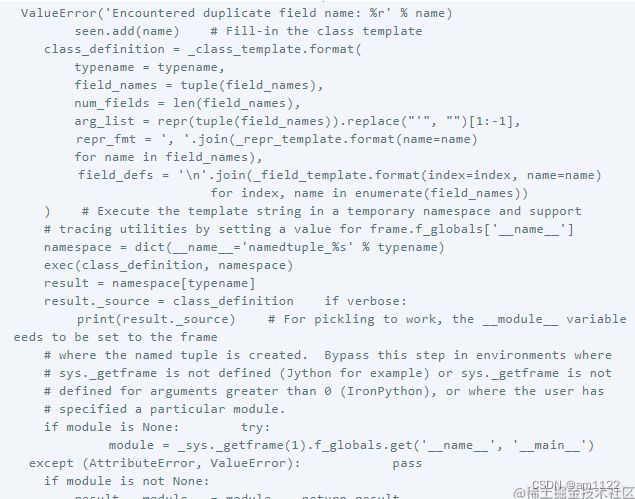
UserDict
UserDict是MutableMapping和Mapping的子类,它继承了MutableMapping.update和Mapping.get两个重要的方法 。
应用案例

源码

No.20 Python中的变量与垃圾回收机制
Python与Java的变量本质上不一样,Python的变量本事是个指针。当Python解释器执行number=1的时候,实际上先在内存中创建一个int对象,然后将number指向这个int对象的内存地址,也就是将number“贴”在int对象上,测试用例如下:

==和is的区别就是前者判断的值是否相等,后者判断的是对象id值是否相等。

Python有一个优化机制叫intern,像这种经常使用的小整数、小字符串,在运行时就会创建,并且全局唯一。
Python中的del语句并不等同于C++中的delete,Python中的del是将这个对象的指向删除,当这个对象没有任何指向的时候,Python虚拟机才会删除这个对象。
No.21 Python元类编程
property动态属性
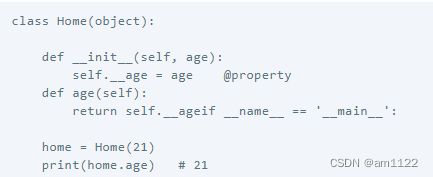
在Python中,为函数添加@property装饰器可以使得函数像变量一样访问。
__getattr__和__getattribute__函数的使用
__getattr__在查找属性的时候,找不到该属性就会调用这个函数。
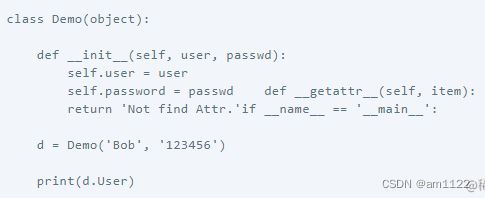 __getattribute__在调用属性之前会调用该方法。
__getattribute__在调用属性之前会调用该方法。

属性描述符
在一个类中实现__get__()、__set__()和__delete__()都是属性描述符。
数据属性描述符

非数据属性描述符 在Python的新式类中,对象属性的访问都会调用
__getattribute__()方法,它允许我们在访问对象时自定义访问行为,值得注意的是小心无限递归的发生。__getattriubte__()是所有方法和属性查找的入口,当调用该方法之后会根据一定规则在__dict__中查找相应的属性值或者是对象,如果没有找到就会调用__getattr__()方法,与之对应的__setattr__()和__delattr__()方法分别用来自定义某个属性的赋值行为和用于处理删除属性的行为。描述符的概念在Python 2.2中引进,__get__()、__set__()、__delete__()分别定义取出、设置、删除描述符的值的行为。
- 值得注意的是,只要实现这三种方法中的任何一个都是描述符。
- 仅实现
__get__()方法的叫做非数据描述符,只有在初始化之后才能被读取。 - 同时实现
__get__()和__set__()方法的叫做数据描述符,属性是可读写的。
属性访问的优先规则
对象的属性一般是在__dict__中存储,在Python中,__getattribute__()实现了属性访问的相关规则。
假定存在实例obj,属性number在obj中的查找过程是这样的:
- 搜索基类列表
type(b).__mro__,直到找到该属性,并赋值给descr。 - 判断
descr的类型,如果是数据描述符则调用descr.__get__(b, type(b)),并将结果返回。 - 如果是其他的(非数据描述符、普通属性、没找到的类型)则查找实例
obj的实例属性,也就是obj.__dict__。 - 如果在
obj.__dict__没有找到相关属性,就会重新回到descr的判断上。 - 如果再次判断
descr类型为非数据描述符,就会调用descr.__get__(b, type(b)),并将结果返回,结束执行。 - 如果
descr是普通属性,直接就返回结果。 - 如果第二次没有找到,为空,就会触发
AttributeError异常,并且结束查找。
用流程图表示:
__new__()和__init__()的区别
__new__()函数用来控制对象的生成过程,在对象上生成之前调用。__init__()函数用来对对象进行完善,在对象生成之后调用。- 如果
__new__()函数不返回对象,就不会调用__init__()函数。
自定义元类
在Python中一切皆对象,类用来描述如何生成对象,在Python中类也是对象,原因是它具备创建对象的能力。当Python解释器执行到class语句的时候,就会创建这个所谓类的对象。既然类是个对象,那么就可以动态的创建类。这里我们用到type()函数,下面是此函数的构造函数源码:
 由此可知,
由此可知,type()接收一个类的额描述返回一个类。
元类用来创建类,因为累也是对象。type()之所以可以创建类是由于tyep()就是个元类,Python中所有的类都由它创建。在Python中,我们可以通过一个对象的__class__属性来确定这个对象由哪个类产生,当Python创建一个类的对象的时候,Python将在这个类中查找其__metaclass__属性。如果找到了,就用它创建对象,如果没有找到,就去父类中查找,如果还是没有,就去模块中查找,一路下来还没有找到的话,就用type()创建。创建元类可以使用下面的写法:

使用元类创建API
元类的主要用途就是创建API,比如Python中的ORM框架。
Python领袖 Tim Peters :
“元类就是深度的魔法,99%的用户应该根本不必为此操心。如果你想搞清楚究竟是否需要用到元类,那么你就不需要它。那些实际用到元类的人都非常清楚地知道他们需要做什么,而且根本不需要解释为什么要用元类。”
No.22 迭代器和生成器
当容器中的元素很多的时候,不可能全部读取到内存,那么就需要一种算法来推算下一个元素,这样就不必创建很大的容器,生成器就是这个作用。
Python中的生成器使用yield返回值,每次调用yield会暂停,因此生成器不会一下子全部执行完成,是当需要结果时才进行计算,当函数执行到yield的时候,会返回值并且保存当前的执行状态,也就是函数被挂起了。我们可以使用next()函数和send()函数恢复生成器,将列表推导式的[]换成()就会变成一个生成器:

值得注意的是,我们一般不会使用next()方法来获取元素,而是使用for循环。当使用while循环时,需要捕获StopIteration异常的产生。
Python虚拟机中有一个栈帧的调用栈,栈帧保存了指定的代码的信息和上下文,每一个栈帧都有自己的数据栈和块栈,由于这些栈帧保存在堆内存中,使得解释器有中断和恢复栈帧的能力:
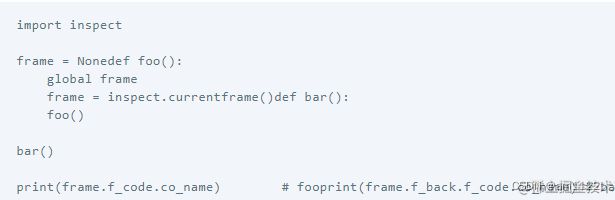 这也是生成器存在的基础。只要我们在任何地方获取生成器对象,都可以开始或暂停生成器,因为栈帧是独立于调用者而存在的,这也是协程的理论基础。
这也是生成器存在的基础。只要我们在任何地方获取生成器对象,都可以开始或暂停生成器,因为栈帧是独立于调用者而存在的,这也是协程的理论基础。
迭代器是一种不同于for循环的访问集合内元素的一种方式,一般用来遍历数据,迭代器提供了一种惰性访问数据的方式。
可以使用for循环的有以下几种类型:
- 集合数据类型
- 生成器,包括生成器和带有
yield的生成器函数
这些可以直接被for循环调用的对象叫做可迭代对象,可以使用isinstance()判断一个对象是否为可Iterable对象。集合数据类型如list、dict、str等是Iterable但不是Iterator,可以通过iter()函数获得一个Iterator对象。send()和next()的区别就在于send()可传递参数给yield()表达式,这时候传递的参数就会作为yield表达式的值,而yield的参数是返回给调用者的值,也就是说send可以强行修改上一个yield表达式值。