Elasticsearch实战(十六)---TOP N 实现统计组内排名最高的N条数据及histogram区间统计
Elasticsearch实战-实现统计组内排名最高的N条数据及Histogram区间统计
文章目录
-
-
- Elasticsearch实战-实现统计组内排名最高的N条数据及Histogram区间统计
-
- 1.准备数据
- 2. ES 分组内TopN逻辑实现
-
- 2.1 top_hits获取分组内固定N条数据
- 3.Histogram 区间统计
-
- 3.1 以10为区间,统计年龄10-20/20-30/30-40等的数据统计
- 4.date_histogram 时间区间统计
-
- 4.1 准备时间/销售额数据
- 4.2 date_histogram 时间区间统计参数详解
- 4.3 date_histrogram 时间区间统计,然后聚合操作
-
场景:
- ES搜索, 获取不同部门中 年龄最大的前三个人,或者 获取获取不同部门,工资最高的前三个人,其实就是对分组内的数据进行topN处理 这种场景应该如何满足? 这种就是 TOP N的场景,使用 top_hits实现
- ES搜索,如果想搜 10-20年龄多少人,20-30年龄多少人,30-40年龄多少人,40-50年龄多少人,其实就是10年一个区间去做区间统计,这种应该如何满足?这种就是histogram区间统计
1.准备数据
POST /testcopy/_bulk
{"index":{"_id": 1}}
{"empId" : "111","name" : "员工1","age" : 20,"sex" : "男","mobile" : "19000001111","salary":1333,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"光谷大道","address":"湖北省武汉市洪山区光谷大厦","content" : "i like to write best elasticsearch article"}
{"index":{"_id": 2}}
{"empId" : "222","name" : "员工2","age" : 25,"sex" : "男","mobile" : "19000002222","salary":15963,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i think java is the best programming language"}
{"index":{"_id": 3}}
{ "empId" : "333","name" : "员工3","age" : 30,"sex" : "男","mobile" : "19000003333","salary":20000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"经济技术开发区","address" : "湖北省武汉市经济开发区","content" : "i am only an elasticsearch beginner"}
{"index":{"_id": 4}}
{"empId" : "444","name" : "员工4","age" : 20,"sex" : "女","mobile" : "19000004444","salary":5600,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"沌口开发区","address" : "湖北省武汉市沌口开发区","content" : "elasticsearch and hadoop are all very good solution, i am a beginner"}
{"index":{"_id": 5}}
{ "empId" : "555","name" : "员工5","age" : 20,"sex" : "男","mobile" : "19000005555","salary":9665,"deptName" : "测试部","provice" : "湖北省","city":"高新开发区","area":"武汉","address" : "湖北省武汉市东湖隧道","content" : "spark is best big data solution based on scala ,an programming language similar to java"}
{"index":{"_id": 6}}
{"empId" : "666","name" : "员工6","age" : 30,"sex" : "女","mobile" : "19000006666","salary":30000,"deptName" : "技术部","provice" : "武汉市","city":"湖北省","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i like java developer"}
{"index":{"_id": 7}}
{"empId" : "777","name" : "员工7","age" : 60,"sex" : "女","mobile" : "19000007777","salary":52130,"deptName" : "测试部","provice" : "湖北省","city":"黄冈市","area":"边城区","address" : "湖北省黄冈市边城区","content" : "i like elasticsearch developer"}
{"index":{"_id": 8}}
{"empId" : "888","name" : "员工8","age" : 19,"sex" : "女","mobile" : "19000008888","salary":60000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"汉阳区","address" : "湖北省武汉市江汉大学","content" : "i like spark language"}
{"index":{"_id": 9}}
{"empId" : "999","name" : "员工9","age" : 40,"sex" : "男","mobile" : "19000009999","salary":23000,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市郑州大学","content" : "i like java developer"}
{"index":{"_id": 10}}
{"empId" : "101010","name" : "张湖北","age" : 35,"sex" : "男","mobile" : "19000001010","salary":18000,"deptName" : "测试部","provice" : "湖北省","city":"武汉","area":"高新开发区","address" : "湖北省武汉市东湖高新","content" : "i like java developer i also like elasticsearch"}
{"index":{"_id": 11}}
{"empId" : "111111","name" : "王河南","age" : 61,"sex" : "男","mobile" : "19000001011","salary":10000,"deptName" : "销售部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am not like java "}
{"index":{"_id": 12}}
{"empId" : "121212","name" : "张大学","age" : 26,"sex" : "女","mobile" : "19000001012","salary":1321,"deptName" : "测试部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am java developer thing java is good"}
{"index":{"_id": 13}}
{"empId" : "131313","name" : "李江汉","age" : 36,"sex" : "男","mobile" : "19000001013","salary":1125,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市二七区","content" : "i like java and java is very best i like it do you like java "}
{"index":{"_id": 14}}
{"empId" : "141414","name" : "王技术","age" : 45,"sex" : "女","mobile" : "19000001014","salary":6222,"deptName" : "测试部",,"provice" : "河南省","city":"郑州市","area":"金水区","address" : "河南省郑州市金水区","content" : "i like c++"}
{"index":{"_id": 15}}
{"empId" : "151515","name" : "张测试","age" : 18,"sex" : "男","mobile" : "19000001015","salary":20000,"deptName" : "技术部",,"provice" : "河南省","city":"郑州市","area":"高新开发区","address" : "河南省郑州高新开发区","content" : "i think spark is good"}
2. ES 分组内TopN逻辑实现
2.1 top_hits获取分组内固定N条数据
aggs分组中有一些属性来控制条数及排序规则,参数如下:
- top_hits来返回获取组内多少条数据,默认10条
- sort数组结构,组内是字段,order属性,表示组内数据用什么字段,什么规则排序
- _source数组结构,组内是 includes/excludes结果中包含或者排除 documnet中哪些字段
#top_hits获取分组内 topN 前2条数据
get /testcopy/_search
{
"size":0,
"aggs":{
"group_by_dept":{
"terms": {
"field": "deptName.keyword"
},
//terms 同级进行 aggs聚合搜索
"aggs": {
"top_two_age": {
"top_hits": {
// top_hits中的size 就是取每个分组多少条
"size": 2,
//按照什么排序
"sort": [
{
"age": {
"order": "desc"
}
}
],
//取哪些字段
"_source": {
"includes": ["name","age","deptName"]
}
}
}
}
}
}
}
查询结果 所有的分组都是 取前2个, 比如 技术部有四个员工,只取 top2,前2个

3.Histogram 区间统计
3.1 以10为区间,统计年龄10-20/20-30/30-40等的数据统计
以10 为区间,统计每个年龄段多少人,或者统计每个年龄段的平均工资 salary,我们就以histogram来实现
hisgogram 参数 interval就是控制区间步长, 比如 10, 那么它划分的 区间就是 10-20/20-30/30-40/40-50/50-60/60-70 , 然后没有70岁以上的人 那就结束,直到最后一个区间
# 以10为区间,统计 每个年龄段的 平均工资
get /testcopy/_search
{
"size":0,
"aggs":{
"histogram_by_10_age":{
"histogram": {
"field": "age",
"interval": 10
},
//histogram 平级,然后进行 aggs 求每个区间的 平均工资
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
}
}
}
查询过滤 结果 可以看到 每个年龄段 都统计了人数及 平均工资,
最低年龄19,落在区间10-20区间内,所以第一个期间就是 key:10, 区间10-20 ,
没有人 超过70岁,所以就不显示 70及以后的区间
| 年龄区间 | 人数 | 平均工资 |
|---|---|---|
| 10-20区间 | 1人 | 60000 |
| 20-30区间 | 4人 | 8140.25 |
| 30-40区间 | 4人 | 17281.25 |
| 40-50区间 | 1人 | 23000.0 |
| 50-60区间 | 0人 | null |
| 60-70区间 | 1人 | 52130.0 |

4.date_histogram 时间区间统计
上面我们介绍了 使用histogram来统计区间内数据,我们的数据都是按照日期进行更新插入的,如果现在要统计每月销售额如何实现?
原理就是 用 date_histogram来做时间月份的区间统计,然后sum销售额即可
4.1 准备时间/销售额数据
先设计mapping,创建时间格式 mapping,否则插入的时间戳 要么是long数字,要么是text文本形式
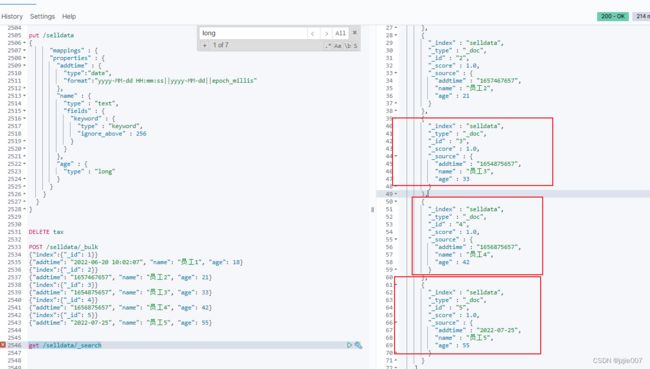
put /selldata
{
"mappings" : {
"properties" : {
"addtime" : {
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"age" : {
"type" : "long"
}
}
}
}
}
插入数据
我们准备了几种 date格式, yyyy-mm-dd HH:mm:ss 及 时间戳long,及UTC时间 2021-01-30T10:02:07Z 都 试一试,看看能否插入成功
# 错误数据 ,因为 员工3和员工4 是UTC时间,是无法插入的
POST /selldata/_bulk
{"index":{"_id": 1}}
{"addtime": "2022-06-20 10:02:07", "name": "员工1", "age": 18}
{"index":{"_id": 2}}
{"addtime": "1657467657000", "name": "员工2", "age": 21}
{"index":{"_id": 3}}
{"addtime": "2022-05-1T12:20:00Z", "name": "员工3", "age": 33}
{"index":{"_id": 4}}
{"addtime": "2022-06-30T10:02:07Z", "name": "员工4", "age": 42}
{"index":{"_id": 5}}
{"addtime": "2022-07-25", "name": "员工5", "age": 55}
执行报错 UTC时间无法匹配时间格式
failed to parse date field [2022-05-1T12:20:00Z] with format [yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis]",
所以修改下员工3和员工4的错误数据,再次插入
#正确数据, 插入成功
POST /selldata/_bulk
{"index":{"_id": 1}}
{"addtime": "2022-04-20 10:02:07", "name": "员工1", "age": 18}
{"index":{"_id": 2}}
{"addtime": "1657467657000", "name": "员工2", "age": 21}
{"index":{"_id": 3}}
{"addtime": "1654875657000", "name": "员工3", "age": 33}
{"index":{"_id": 4}}
{"addtime": "1656875657000", "name": "员工4", "age": 42}
{"index":{"_id": 5}}
{"addtime": "2022-07-25", "name": "员工5", "age": 55}
查询下 是否成功插入, 全都正确
get /selldata/_search
4.2 date_histogram 时间区间统计参数详解
date_histogram 有以下参数
- field 区间聚合分组字段
- interval 区间范围变化 year,quarter,month,week,day,hour,minute,second 分别对应 年/季度/月/周/天/时/分/秒
- format 指定时间显示格式
- min_doc_count 区间最少doc,默认为0,表示 区间内没有doc也会展示 0
- extend_bounds 不是过滤,不是过滤,不是过滤 ,重要事情说三遍,他只是结果 展示的开始时间及结束时间,如果没指定,就是默认字段中最小范围与最大范围的起止时间, 如果指定了 就按照这个区间去展示
实现时间区间统计,统计 按照month区间
get /selldata/_search
{
"size":0,
"aggs":{
"histogram_by_sell_date":{
"date_histogram": {
"field": "addtime",
//月份区间
"interval": "month",
//展示格式
"format": "yyyy-MM-dd",
"min_doc_count": 0
}
}
}
}
查询结果 key_as_string 展示格式就是 yyyy-MM-dd 2022-04-01, 以month月度为统计区间
min_doc_count就是最小的文档数 为0 表示即使时0也要展示出来

我们修改下 min_doc_count = 2
试一下, 看看 文档doc数量为0/1的是否展示
get /selldata/_search
{
"size":0,
"aggs":{
"histogram_by_sell_date":{
"date_histogram": {
"field": "addtime",
//月份区间
"interval": "month",
//展示格式
"format": "yyyy-MM-dd",
//最小数目大于 等于 2的才展示
"min_doc_count": 2
}
}
}
}
查询结果

我们加一个参数 extend_bounds
经过刚才的查找, 我们看到 最早时间是 2022-04-01, 最晚时间在 2022-07-01 ,我们现在限制控制下 查询的开始时间及结束时间
不设置 extend_bounds 开 始时间时 2022-04-01 ~ 2022-07-01 就是数据存在的第一个月,及数据结束的最后一个月
现在设置 “extended_bounds”: { “min”: “2022-02-01”, “max”: “2022-09-30” } 意思就是 从 2022-02-01 开始 到 2022-09-01 结束,验证一下结果
# extended_bounds 控制数据展示的 开始及结束时间
get /selldata/_search
{
"size":0,
"aggs":{
"histogram_by_sell_date":{
"date_histogram": {
"field": "addtime",
//月份区间
"interval": "month",
//展示格式
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "2022-02-01",
"max": "2022-09-30"
}
}
}
}
}
查询结果 ,可以看到的确是 从我们指定的 min,max日期开始进行统计展示

4.3 date_histrogram 时间区间统计,然后聚合操作
回到最初的问题,实现时间区间统计,统计 按照month区间,来统计 每个区间的年龄 平均值
get /selldata/_search
{
"size":0,
"aggs":{
"histogram_by_sell_date":{
"date_histogram": {
"field": "addtime",
//月份区间
"interval": "month",
//展示格式
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "2022-02-01",
"max": "2022-09-30"
}
},
//分组内 date_histogram 同级 进行aggs 平均年龄统计
"aggs":{
"avg_age":{
"avg": {
"field": "age"
}
}
}
}
}
}
查询结果,符合预期

至此 我们已经学习了 TOP N分组内获取前N条数据的实现逻辑, 及如何使用区间统计histogram来对每一个区间内的数据进行统计分析, 及 如何使用date_histrogram 来进行时间区间统计