网络爬虫系列4:BeautifulSoup
一、爬虫中文乱码繁体字乱码问题解决
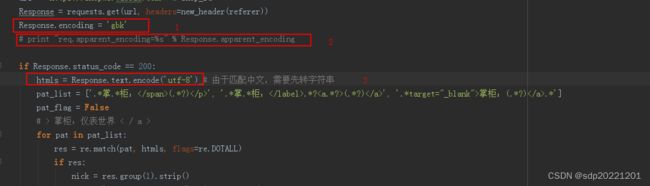
1.中文乱码,开始直接就 Response.encoding = 'utf-8',结果中文都是乱码。查资料可以用 Response.apparent_encoding 看出返回网页的编码格式 GB2312
2.繁体字乱码 简单中文没问题,但是繁体字又是乱码,而且Response.apparent_encoding=‘GB2312’,再查资料,直接在浏览器看网页源码,找到 ,改成gbk问题解决
3.汉字无法正则匹配,因Response.text是unicode格式,需转成python支持的utf-8
二、BeautifulSoup 中 ‘lxml’ 和 ‘html.parser’有区别
使用BeautifulSoup进行文档解析时需要解析器的配合,‘lxml’ 和 ‘html.parser’就是两种解析器。html.parser是python标准库中的解析器,我们可以直接使用。当然,Python也支持第三方解析器,例如 lxml 等,只是需要单独进行安装。
BeautifulSoup 支持的常见解析器有四种: html.parser,lxml,lxml-xml,html5lib。
这四种解析器各有优劣,下面是他们特点对比图:
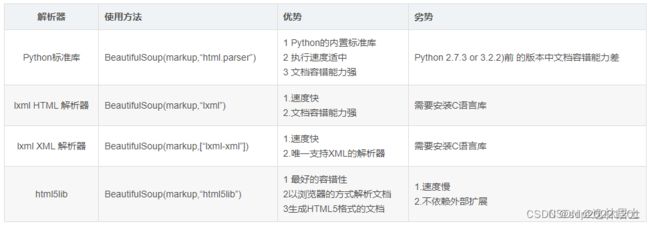
由于lxml更高的效率,因此推荐使用lxml作为解析器。
一般我们安装BeautifulSoup包的时候会自带这几种解析器,但如果你的包里没有lxml或html5lib,可以单独在terminal(我用的pycharm)中安装,或者再python环境中安装也可以。
关于BeautifulSoup使用部分这里就不多叙述了。最后提示一点,一般解析本地文件使用html.parser解析器更好用一些,如上我用的就是html.parser;如果要是解析网页文件,比如从网页上抓取下来得信息,就需要用 lxml 解析器,效率会更高一些。当然,lxml 也可以解析本地文件。综上,推荐使用 lxml 解析器!
三、requests 模块的 requests.session() 功能
之前使用 requests 模块的时候,是直接 requests.get() 或者 requests.post() 发送GET请求或POST请求;当然也是可以带上 cookies 和 headers 的,但这都是一次性请求,你这次带着cookies信息,后面的请求还得带。这时候 requests.session() 就派上用场了,它可以自动处理cookies,做状态保持。
(26条消息) requests 模块的 requests.session() 功能_python编程的博客-CSDN博客_requests.session()