【Android 图像显示系统】整体架构与缓冲区策略
众所周知,Android中View的显示有三个主要方法,即onMeasure()、onLayout()、onDraw()。简单来说,它们分别负责测量——决定View的大小、布局——决定View在ViewGroup中的位置、和绘制——将View绘制到屏幕上。在onDraw()方法中,一般来说,我们实际上是完成了一张画布 canvas 的绘制。那这张画布到底是如何一步一步显示到屏幕上的呢?我们今天就来了解一下。
Android 图像显示系统整体架构
先让我们来看一下 Android 图像显示系统的整体架构。
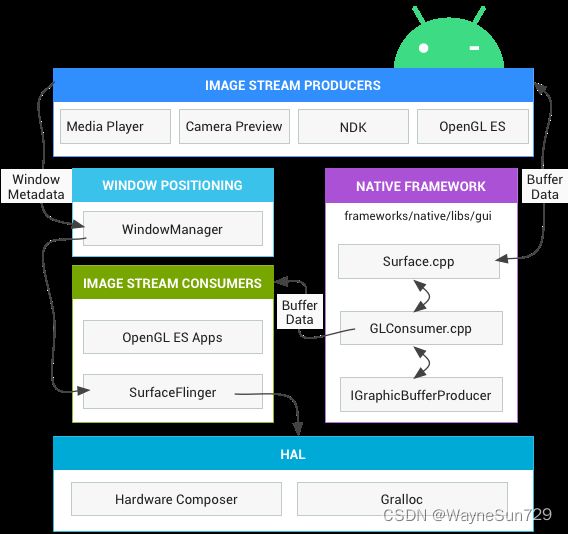
生产者消费者模型
可以看出,这是个典型的生产者消费者模型,生产者产生渲染数据,消费者消耗渲染数据。
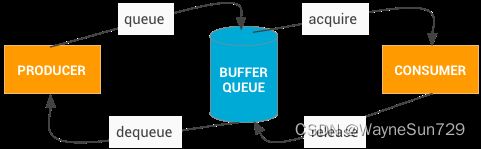
通过上图我们可以大概看到BufferQueue的工作过程:
- 图像生产者通过调用dequeue方法向BufferQueue请求一块图形缓冲区内存,即一块GraphicBuffer;
- 图像生产者将产生的图像数据(比如相机预览的图像或解码器解码出的视频帧)写入图形缓冲区GraphicBuffer,并通过queue方法提交给BufferQueue;
- BufferQueue收到图形缓冲区GraphicBuffer的入队列消息,通知图像消费者调用acquire方法取得已填充数据的buffer进行处理或显示;
- 图像消费者处理完毕,调用release方法把buffer归还给BufferQueue,这个buffer之后可再重复使用;
- 图像生产者、BufferQueue、图像消费者协调工作,图形缓冲区buffer在三者之间协调流转,图像便流畅的显示或处理。
问题:生产者消费者问题的关键如何被解决?
图像流生产者 image stream produceers
图像流生产方,即渲染数据的生产者,它可以是生成图形缓冲区以供消耗的任何内容,包括 OpenGL ES、Canvas 2D 和 mediaserver 视频解码器。
产生数据的过程比如draw方法把绘制指令通过canvas传递给framework层的RenderThread线程。
原生框架层 native framework
以 Buffer Queue 为例,主要协助数据在生产者与消费者之间传输。
图像流消费者 image stream consumers
图像流的最常见消费者是 SurfaceFlinger,该系统服务 System Service 会消耗当前可见的 Surface,并使用窗口管理器 WMS 中提供的信息将它们合成到屏幕。SurfaceFlinger 是可以修改所显示部分内容的唯一服务。SurfaceFlinger 使用 OpenGL 和 Hardware Composer 来合成一组 Surface。
其他 OpenGL ES 应用也可以消耗图像流,例如相机应用会消耗相机预览图像流。非 GL 应用也可以是使用方,例如 ImageReader ,它允许应用程序直接获取渲染到surface的图形数据,并转换为图片。
硬件混合渲染器 HAL
显示子系统的硬件抽象实现,作为硬件抽象层,负责协助消费者把图形数据展示到设备屏幕。
Gralloc
需要使用图形内存分配器 (Gralloc) 来分配图像生产方请求的内存。有关详情,请参阅 Gralloc HAL。
图像生产者
从上面的架构图可知,图像的生产者主要有MediaPlayer,CameraPreview,NDK(即Skia),OpenGl ES。其中MediaPlayer和Camera Preview是通过直接读取图像源来生成图像数据,NDK(Skia),OpenGL ES是通过自身的绘制能力生产的图像数据。
OpenGL、Vulkan、Skia的区别
- OpenGL: 是一种跨平台的3D图形绘制规范接口。OpenGL ES 则是专门针对嵌入式设备,如手机做了优化。
- Skia: skia是图像渲染库,2D图形绘制自己就能完成。3D效果(依赖硬件)由OpenGL、Vulkan、Metal支持。它不仅支持2D、3D,同时支持CPU软件绘制和GPU硬件加速。Android、flutter都是使用它来完成绘制。
- Vulkan: Android引入了Vulkan支持。VulKan是用来替换OpenGL的。它不仅支持3D,也支持2D,同时更加轻量级。
缓冲区 Buffer Queue
BufferQueues 是 Android 图形组件之间的粘合剂,可以调解缓冲区从生产方到消耗方的固定周期。一旦生产方移交其缓冲区,SurfaceFlinger 便会负责将所有内容合成到显示部分。
BufferQueue 类是 Android 中所有图形处理操作的核心。它的作用很简单:将生成图形数据缓冲区的一方(生产方)连接到接受数据以进行显示或进一步处理的一方(消耗方)。几乎所有在系统中移动图形数据缓冲区的内容都依赖于 BufferQueue。
即:Android中的图像生产者OpenGL,Skia,Vulkan将绘制的数据存放在图像缓冲区中,Android中的图像消费SurfaceFlinger从图像缓冲区将数据取出,进行加工及合成
BufferQueue的内容比较多,这里暂不展开,而是和大家聊一下与此相关的缓冲区策略。
黄油工程
Google 在 2012 年的 I/O 大会上宣布了 Project Butter 黄油工程,并且在 Android 4.1 中正式开启了这个机制。若要了解该机制,我们先要了解一下VSYNC信号。
VSYNC信号
VSYNC(Vertical Synchronization)是理解 Project Butter 的核心。
双缓存机制
VSYNC信号的起始涉及早期显示器显示原理——显示器会将显存里的数据,按照从左至右,从上到下的顺序同步到屏幕上的每一个像素晶体管,一个像素晶体管就代表了一个像素。
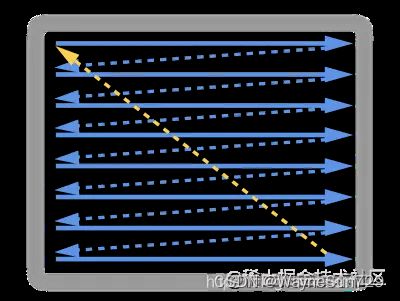
当这个过程完成了,就表示一帧绘制完成了,此时显示器内部绘制图像的扫描点,即绘制“本张画”的“笔”会从右下角挪回左上角,扫描点移回的这个过程称为重置扫描点。
我们已经知道,图像数据都是放在缓冲区中的,当缓冲区只有一个时,那么屏幕在绘制这一帧的时候,图像数据便没法放入帧缓冲中了,只能等待这一帧绘制完成(为什么?),在这种情况下,会有很大的效率、延迟问题(读者写者模型)。
为了解决这一问题,帧缓冲引入两个缓冲区,即双缓冲机制——准备两个缓冲区,其中一个供写者写,一个供读者读,在写者写完之后交换两缓冲区,供读者读新内容、写者写新内容。
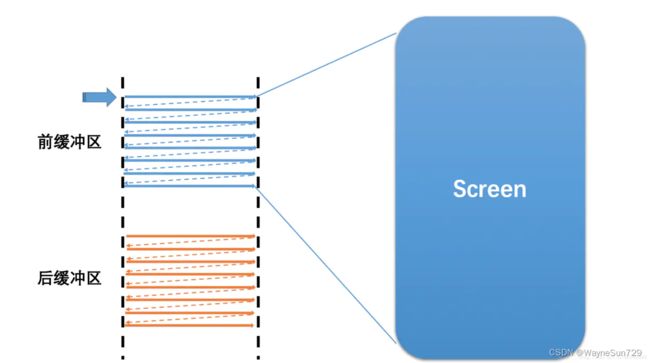
双缓冲虽然能解决效率问题,但会引入一个新的问题。我们知道,平常玩游戏时帧率都是波动的,这是因为忽略发热调度影响,GPU的性能是一定的,而我们的游戏场景是会变的,在低负载场景下,GPU处理的就快,帧率就高,而在高负载场景下GPU处理的就会慢一些,帧率就低。
而当屏幕这一帧还没绘制完成时,即屏幕内容刚显示到一半时,GPU 将新的一帧内容提交到帧缓冲区并把两个缓冲区进行交换后,显卡的像素同步模块就会把新的一帧数据的下半段显示到屏幕上,根据显示原理,显示出来的效果就是垂直方向上线条等的撕裂、断裂。


为了解决这个垂直方向上的撕裂问题,就需要在显示器已经完成绘制的时候才将帧缓冲中的两个缓冲区进行交换,显示器完成绘制发出的这个信号就被称之为垂直同步信号——VSync(名称来源于早年PC领域的垂直同步脉冲)。CPU和GPU都只有收到垂直同步的信号时,才会开始进行图像的绘制操作,以及缓冲区的交换工作。
拓展1 为什么游戏中开了垂直同步后会锁60帧?
打开垂直同步之后,缓冲区的交换只在显示器绘制完成之后进行,如果显示器刷新率是60hz的话,自然就会锁在60帧了。
拓展2 目前手机、显示器市场的卖点——“高刷”有什么用?


根据前面的叙述,我们知道如果设备性能足够,显示器刷新率如果从60hz提升到120hz,那自然卡顿就会更小一点,帧与帧之间的延迟也会更低,观感上就是感觉高刷的画面更流畅。
In Android
黄油工程之前
具体到Android中,在Android4.1之前,屏幕刷新也遵循上面介绍的双缓存机制。
如下图:
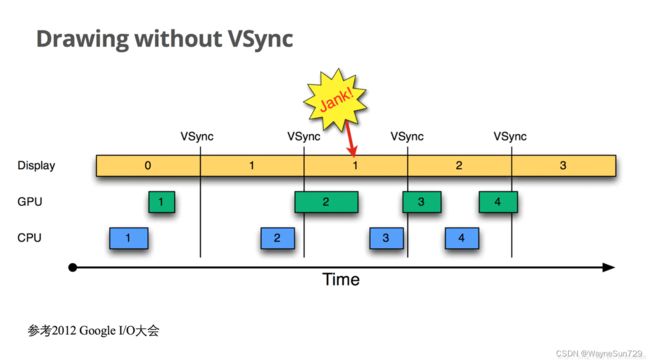
以时间的顺序来看下将会发生的过程:
- Display显示第0帧数据,此时CPU和GPU渲染第1帧画面,且在Display显示下一帧前完成
- 因为渲染及时,Display在第0帧显示完成后,也就是第1个VSync后,缓存进行交换,然后正常显示第1帧
- 接着第2帧开始处理,是直到第2个VSync快来前才开始处理的。
- 第2个VSync来时,由于第2帧数据还没有准备就绪,缓存没有交换,显示的还是第1帧。这种情况被Android开发组命名为“Jank”,即发生了丢帧。
- 当第2帧数据准备完成后,它并不会马上被显示,而是要等待下一个VSync 进行缓存交换再显示。
所以总的来说,就是屏幕平白无故地多显示了一次第1帧。
呼之欲出的黄油工程
为了解决这个问题,Google在Android 4.1系统中对Android Display系统进行了重构,实现了Project Butter(黄油工程):系统在收到VSync pulse后,将马上开始下一帧的渲染。即系统在收到VSync信号后,将马上开始下一帧的渲染。即一旦收到VSync通知(16ms触发一次),CPU和GPU 才立刻开始计算然后把数据写入buffer。如下图:

CPU/GPU根据VSYNC信号同步处理数据,可以让CPU/GPU有完整的16ms时间来处理数据,减少了jank。
一句话总结,VSync同步使得CPU/GPU充分利用了16.6ms时间,减少jank。
三缓存机制
在Android 4.0之前,Android采用双缓冲机制,让绘制和显示器拥有各自的buffer:GPU 始终将完成的一帧图像数据写入到 Back Buffer,而显示器使用 Front Buffer。
双缓存机制的问题
引入了垂直同步的双缓冲机制的理想前提是GPU性能足够,显示器只要绘制完毕就可以拿到下一帧的新数据,但现实往往与理想不同。如果界面比较复杂,或者设备硬件性能本身较低,CPU/GPU的处理时间较长,超过了16.6ms呢?双缓存机制会带来什么问题?如下图:
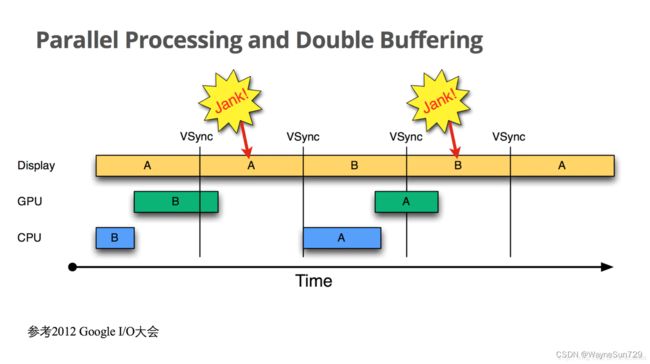
- 在第二个时间段内,却因 GPU 还在处理 B 帧,缓存没能交换,导致 A 帧被重复显示。
- 而B完成后,又因为缺乏VSync信号,它只能等待下一个VSYNC的来临。于是在这一过程中,有一大段时间是被浪费的。
- 当下一个VSync出现时,CPU/GPU马上执行操作(A帧),且缓存交换,相应的显示屏对应的就是B。这时看起来就是正常的。只不过由于执行时间仍然超过16ms,导致下一次应该执行的缓冲区交换又被推迟了——如此循环反复,便出现了越来越多的“Jank”。
为什么 CPU 不能在第二个 16ms 处理绘制工作呢?
原因是只有两个 buffer,缓存区backBuffer用于CPU/GPU图形处理,缓存区frameBuffer用于显示器显示。而此时Back buffer正在被GPU用来处理B帧的数据, Frame buffer的内容用于Display的显示,这样两个buffer都被占用,CPU 则无法准备下一帧的数据。 那么,如果再提供一个buffer,CPU、GPU 和显示设备都能使用各自的buffer工作,互不影响。
三缓冲机制
三缓冲就是在双缓冲机制基础上增加了一个缓冲区TripleBuffer,这样可以最大限度的利用空闲时间,带来的坏处是多使用的一个Graphic Buffer所占用的内存。
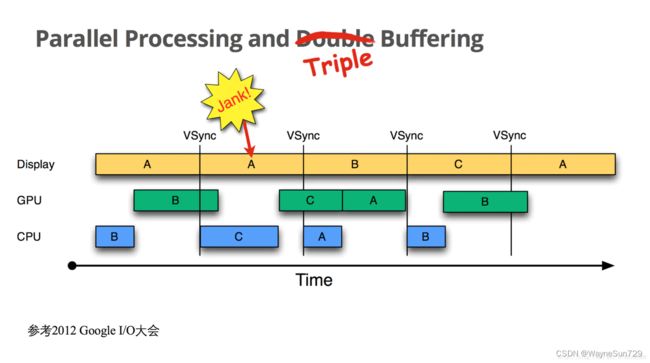
第一个Jank,是不可避免的。但是在第二个 16ms 时间段,CPU/GPU 使用 第三个 Buffer 完成C帧的计算,虽然还是会多显示一次 A 帧,但后续显示就比较顺畅了,有效避免 Jank 的进一步加剧。总的来说,三缓冲机制有效利用了等待vysnc的时间,可以帮助我们减少了jank 。
其实,掉帧的根本原因是因为在一帧时间内(一般为16.6ms),CPU/GPU无法把下一帧的数据准备好。
而即使目前系统引用了三缓存和垂直同步,但是掉帧的情况该发生还是会发生,我们作为App软件开发者,能做的就是尽可能优化布局,减少嵌套,减少CPU/GPU计算画面数据的时间,让每一帧时间内正常准备好下一帧图像数据。
RenderThread
经过 Android 4.1 的 Project Butter 黄油计划之后,Android 的渲染性能有了很大的改善。不过,虽然利用了 GPU 的图形高性能运算,但是从计算 DisplayList,到通过 GPU 绘制到 Frame Buffer,整个计算和绘制都在 UI 主线程中完成。
UI 线程任务过于繁重。如果整个渲染过程比较耗时,可能造成无法响应用户的操作,进而出现卡顿的情况。GPU 对图形的绘制渲染能力更胜一筹,如果使用 GPU 并在不同线程绘制渲染图形,那么整个流程则会更加顺畅。
正因如此,在 Android 5.0 引入两个比较大的改变。一个是引入了 RenderNode 的概念,它对 DisplayList 及一些 View 显示属性都做了进一步封装。另一个是引入了 RenderThread,所有的 GL 命令执行都放到这个线程上,渲染线程在 RenderNode 中存有渲染帧的所有信息,可以做一些属性动画,这样即便主线程有耗时操作的时候也可以保证动画流畅。
硬件加速
关于硬件加速,相信大家也经常听到,尤其是有些API不支持硬件加速,因此需要我们手动关闭,那么硬件加速到底是什么呢?
CPU 与 GPU 的区别
除了屏幕,UI 渲染还要依赖另外两个核心的硬件:CPU 和 GPU。
- CPU(Central Processing Unit,中央处理器),是计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元;
- GPU(Graphics Processin Unit,图形处理器),是一种专门用于图像运算的处理器,在计算机系统中通常被称为 "显卡"的核心部件就是 GPU。
UI 组件在绘制到屏幕之前,都需要经过 Rasterization(栅格化)操作,而栅格化又是一个非常耗时的操作。

Rasterization 栅格化是绘制那些 Button、Shape、Path、String、Bitmap 等显示组件最基础的操作。栅格化将这些 UI 组件拆分到显示器的不同像素上进行显示。这是一个非常耗时的操作,GPU 的引入就是为了加快栅格化。
拓展3 挖矿为什么用显卡不用CPU?
先来介绍一下挖矿是什么。
什么是挖矿?
所谓的矿就是一个个数据包,这些数据包需要解密。矿的数据包中含有少量的网络虚拟货币——比特币。比特币的本质其实就是一堆复杂算法所生成的特解,即方程组所能得到有限个解中的一组。以钞票来比喻的话,比特币就是钞票的冠字号码,你知道了某张钞票上的冠字号码,你就拥有了这张钞票。
为什么用显卡挖矿?
既然是计算工作,为什么现在矿老板们都是使用显卡挖矿,不使用CPU呢?
其实,挖矿并不是说不能用cpu,最开始大家都是用CPU在挖矿。但是随着对挖矿算法的深入研究,矿工们发现原来挖矿主要都是在进行重复的工作,因为这些数据包的计算量很大,但计算方式其实并不困难,而CPU作为通用性计算单元,里面设计了很多诸如分支预测单元、寄存单元等等模块,这些对于提升纯算力是根本没有任何帮助的,受限于架构设计,CPU也并不擅长于进行并行运算,一般最多就执行十几个任务,这个和拥有数以千计流处理器的显卡差远了,因此大家慢慢针对显卡开发出对应的挖矿算法进行挖矿。
目前消费级CPU最多是64核心128线程。而GPU呢?都是上千核心上千线程,但都只能进行简单的计算。
顶级CPU、GPU架构表
i9 12900KS 核心数:16核心24线程
RTX 3090Ti:84个SM单元,每个SM单元拥有的CUDA核心数现在为128个,一共拥有10752个流处理器
麒麟9000 Soc:CPU 8核 GPU 24核
硬件绘制与软件绘制
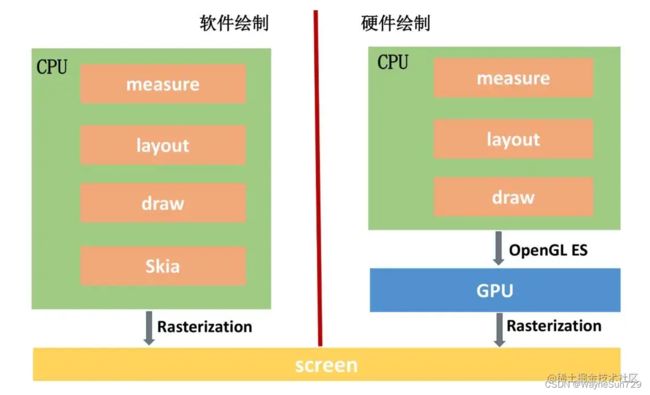
硬件绘制的思想就是通过底层软件代码,将 CPU 不擅长的图形计算转换成 GPU 专用指令,由 GPU 完成绘制任务。所以说硬件加速的本质就是使用GPU代替CPU完成Graphic Buffer绘制工作,以实现更好的性能。
需要注意的是,软件绘制使用的Skia库,但这不代表Skia不支持硬件加速,从Android 8开始,我们可以选择使用Skia进行硬件加速,Android 9开始就默认使用Skia来进行硬件加速。Skia的硬件加速主要是通过 copybit 模块调用OpenGL或者SKia来实现。
图像消费者
当生产者把绘制好的GraphicBuffer数据放入BufferQueue后,接下来的工作就是以SurfaceFlinger为代表的消费者来完成了。
SurfaceFlinger是Android系统中最重要的一个图像消费者,Activity绘制的界面图像,都会传递到SurfaceFlinger来,SurfaceFlinger的作用主要是接收GraphicBuffer,然后与HWComposer或者OpenGL协助进行合成工作,合成完成后,SurfaceFlinger会把最终的数据提交给FrameBuffer。
在应用程序请求创建surface的时候,SurfaceFlinger会创建一个Layer。Layer是SurfaceFlinger操作合成的基本单元。所以,一个surface对应一个Layer。
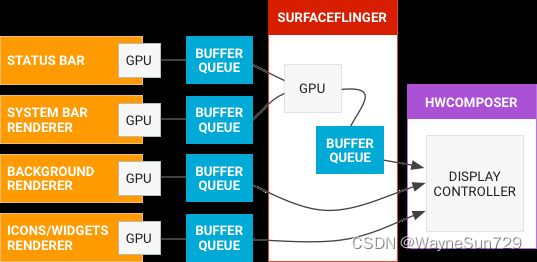
- 左侧的对象是生成图形缓冲区的渲染器,如主屏幕、状态栏和系统界面。
- SurfaceFlinger 是合成器,接受多个来源的图形显示数据,将他们合成,然后发送到显示设备。
- 硬件混合渲染器HWC是制作器。SurfaceFlinger与HWC配合用来将 Surface 合成到屏幕
总结
总的来说,Android图像渲染流程可如下图所示:
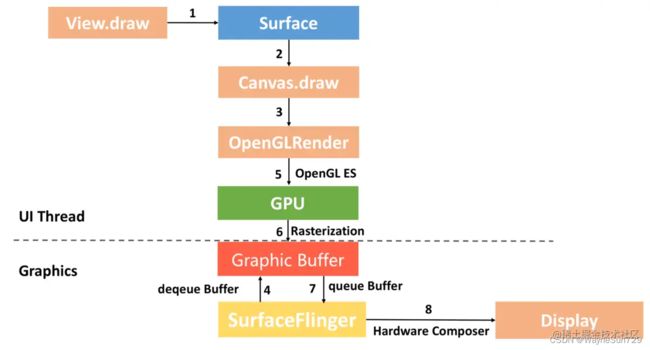
- onMeasure、onLayout计算出view的大小和摆放的位置,这都是UI线程要做的事情,在draw方法中进行绘制,但此时是没有真正去绘制。而是把绘制的指令封装为displayList,进一步封装为RenderNode,在同步给RenderThread。
- RenderThread通过dequeue拿到graphic buffer,根据绘制指令直接操作OpenGL的绘制接口,最终通过GPU设备把绘制指令渲染到了离屏缓冲区graphic buffer。
- 完成渲染后,把缓冲区交还给SurfaceFlinger的BufferQueue。SurfaceFlinger会通过硬件设备进行layer的合成,最终展示到屏幕。
推荐阅读
生产者消费者问题、读者写者问题、哲学家问题细致讲解_Infinity_and_beyond的博客-CSDN博客_生产者消费者问题和读者写者问题
【Android 源码】Android 系统服务的获取_WayneSun729的博客-CSDN博客_android 获取系统服务
SurfaceFlinger服务启动与初始化 - 简书 (jianshu.com)
SurfaceFlinger与Hardware Composer_慢慢的燃烧的博客-CSDN博客
ImageReader实现原理_DJLZPP的博客-CSDN博客
[译]理解 RenderThread - 掘金 (juejin.cn)
Gralloc 总结_颇锐克的博客-CSDN博客_gralloc
图形 | Android 开源项目 | Android Open Source Project