Spark:SQL(一)
分布式计算平台Spar k:SQL(一)
一、回顾
-
Spark中RDD的常用函数
-
分区操作函数:mapPartitions、foreachPartition
- 功能:与map和foreach基本功能一致,这两个函数是对分区进行操作的
- 应用:对RDD数据处理时,需要构建资源时
-
重分区函数:repartition、coalesce
- 功能:调节RDD分区的个数
- 应用:repartition实现调大、coalesce降低分区个数
-
聚合函数:reduce/fold/aggregate
- 分布式聚合:先分区内聚合,再分区间聚合
- fold:初始值在每次聚合都要初始化构建一次
- aggregate(初始值)(分区内聚合逻辑,分区间聚合逻辑)
- 分布式聚合:先分区内聚合,再分区间聚合
-
二元组函数:reduceByKey、aggregateByKey、groupByKey、sortByKey
- groupByKey容易导致内存溢出问题,尽量避免使用
-
关联函数:join
-
二元组类型的RDD才可以实现join:按照Key进行join
RDD【(K,v)】.join(RDD【(K,w)】) => RDD【(K,(v,W))】
-
-
-
RDD的容错机制
-
依赖关系:当计算过程中如果RDD的数据丢失,可以依赖关系重新构建整个RDD的数据
-
缓存机制:persist(StorageLevel)
-
功能:将RDD缓存在内存中【可选缓存级别:mem_disk_ser_2】,如果内存不足,剩余的部分缓存在磁盘中

-
注意:如果RDD不再被使用,建议一定要尽早的手动释放掉
rdd.unpersist
-
-
checkpoint机制:checkpoint
- 功能:将RDD的数据持久化的存储在HDFS上
- 与persist区别
- 存储位置
- 存储内容
- 血脉存储
- checkpoint不存储依赖关系
-
-
数据源
- Spark作为分布式计算框架:读写数据来自于各种常见的数据源【分布式数据源】
- Core:HDFS、MySQL、HBASE
- SQL:Hive
- Streaming:Kafka、Redis、HBASE
- Spark作为分布式计算框架:读写数据来自于各种常见的数据源【分布式数据源】
-
反馈问题
- trim函数的功能:去除头尾的空格
二、课程目标
- Spark读写HBASE和MySQL
- 类似于写JavaAPI,通过Spark来实现分布式读写【将读写的API封装好了】
- Spark读写HBASE:通过调用MapReduce中封装的API
- Spark读写MySQL:封装了JDBC
- 共享变量
- RDD和累加器、广播变量共称为SparkCore两种抽象
- Spark整体程序的架构和调度
- SparkSQL
- 诞生以及设计思想:功能与应用场景
- 数据结果抽象
- SparkCore:RDD
- SparkSQL:DataFrame/DataSet
- SparkStreaming:DStream
- 开发接口:SQL、DSL
三、外部数据源
1、HBASE
-
Spark读写HBASE,自己没有封装API,通过调用Hadoop的API来实现的
- 写:TableOutputFormat
- 读:TableInputFormat
-
写HBASE:将Wordcount的结果通过spark写入HBASE
-
设计
-
表名:htb_wordcount
-
rowkey:唯一、散列、长度、组合
-
(如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位字节采用散列字段处理,由程序随即生成。低位放时间字段,这样将提高数据均衡分布,各个regionServer负载均衡的几率。
如果不进行散列处理,首字段直接使用时间信息,所有该时段的数据都将集中到一个regionServer当中,这样当检索数据时,负载会集中到个别regionServer上,造成热点问题,会降低查询效率。)
-
- 单词作为rowkey
-
列族:info
-
列名称:count
-
-
启动HBASE
start-dfs.sh zookeeper-daemons.sh start //quorumpeermian start-hbase.sh //HRegionServer hbase shell -
创建表
create 'htb_wordcount','info' -
开发
package bigdata.itcast.cn.spark.scala.core.hbase import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.Put import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.TableOutputFormat import org.apache.hadoop.hbase.util.Bytes import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @ClassName SparkCoreSimpleMode * @Description TODO 将Wordcount的结果写入HBASE的表中 * - 表名:htb_wordcount * - rowkey:唯一、散列、长度、组合 * - 单词作为rowkey * - 列族:info * - 列名称:count * @Date 2020/12/12 17:58 * @Create By Frank */ object SparkCoreWriteToHbase { def main(args: Array[String]): Unit = { /** * step1:初始化SparkContext */ val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[2]") // println(s"这是类名:${this.getClass.getSimpleName}") val sc = new SparkContext(conf) sc.setLogLevel("WARN") /** * step2:数据处理逻辑开发 */ //todo:1-读取数据 val inputRdd: RDD[String] = sc.textFile("datas/wordcount/wordcount.data") // println(inputRdd.first()) //todo:2-数据处理 val rsRdd: RDD[(String, Int)] = inputRdd .filter(line => null != line && line.trim.length > 0) .flatMap(line => line.split("\\s+")) .map(word => (word,1)) .reduceByKey(_+_) //todo:3-保存结果 // rsRdd.foreach(tuple => println(tuple._1+"\t"+tuple._2)) // rsRdd.saveAsTextFile("/datas/output/wordcount/wc-"+System.currentTimeMillis()) //写入HBASE //Spark中提供了专门调用Hadoop入输出类的方法 /** * def saveAsNewAPIHadoopFile( * path: String,:指定的一个临时存储路径 * keyClass: Class[_],:指定输出类的Key的类型 * 注意:TableOutputFormat中输出的Key的类型不重要,会被丢弃,一般给ImmutableBytesWritable类型 * 这个类型是HBASE中用于单独存储rowkey的类型 * valueClass: Class[_],:指定输出类的Value类型 * 注意:TableOutputFormat中输出的Value必须为Mutation的子类,如果是写入数据,就用Put类型 * outputFormatClass: Class[_ <: NewOutputFormat[_, _]], :指定调用Hadoop的哪种输出类 * conf: Configuration = self.context.hadoopConfiguration): Unit */ //将rsRDD转换为输出的类型:ImmutableBytesWritable,Put val putRdd: RDD[(ImmutableBytesWritable, Put)] = rsRdd .map{ case (word,numb) => { //Key为ImmutableBytesWritable:rowkey val key = new ImmutableBytesWritable(Bytes.toBytes(word)) //Value为Put类型,要存储的每一列 val value = new Put(Bytes.toBytes(word)) //添加列族、列族、值 value.addColumn( Bytes.toBytes("info"), Bytes.toBytes("count"), Bytes.toBytes(numb.toString) ) (key,value) }} //构建Hadoop的Configuration对象,存储一些HBASE的配置:ZK的地址,表的名称 val configuration = HBaseConfiguration.create() //指定HBASE的访问地址 configuration.set("hbase.zookeeper.quorum", "node1.itcast.cn") configuration.set("hbase.zookeeper.property.clientPort", "2181") configuration.set("zookeeper.znode.parent", "/hbase") //指定写入表的名称 configuration.set(TableOutputFormat.OUTPUT_TABLE,"htb_wordcount") //调用输出类来写入 putRdd.saveAsNewAPIHadoopFile( "datas/output/hbase", classOf[ImmutableBytesWritable], classOf[Put], classOf[TableOutputFormat[ImmutableBytesWritable]], configuration ) /** * step3:释放资源 */ Thread.sleep(1000000L) sc.stop() } }可以使用scan ‘表名’;查看信息
-
-
读HBASE
package bigdata.itcast.cn.spark.scala.core.hbase import org.apache.hadoop.hbase.{Cell, CellUtil, HBaseConfiguration} import org.apache.hadoop.hbase.client.Result import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat} import org.apache.hadoop.hbase.util.Bytes import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @ClassName SparkCoreMode * @Description TODO Spark Core读HBASE数据 * @Date 2020/12/17 9:32 * @Create By Frank */ object SparkCoreReadFromHbase { def main(args: Array[String]): Unit = { /** * step1:初始化一个SparkContext */ //构建配置对象 val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[2]") // TODO: 设置使用Kryo 序列化方式 .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // TODO: 注册序列化的数据类型 .registerKryoClasses(Array(classOf[ImmutableBytesWritable], classOf[Result])) //构建SparkContext的实例,如果存在,直接获取,如果不存在,就构建 val sc = SparkContext.getOrCreate(conf) //调整日志级别 sc.setLogLevel("WARN") /** * step2:实现数据的处理过程:读取、转换、保存 */ //todo:1-读取 /** * def newAPIHadoopRDD[K, V, F <: NewInputFormat[K, V]]( * conf: Configuration = hadoopConfiguration, * fClass: Class[F],:指定调用Hadoop哪种输入类:InputFormat * kClass: Class[K],:输入类返回的Key * vClass: Class[V]):输入类返回的Value */ //构建Hadoop的Configuration对象,存储一些HBASE的配置:ZK的地址,表的名称 val configuration = HBaseConfiguration.create() //指定HBASE的访问地址 configuration.set("hbase.zookeeper.quorum", "node1.itcast.cn") configuration.set("hbase.zookeeper.property.clientPort", "2181") configuration.set("zookeeper.znode.parent", "/hbase") //指定写入表的名称 configuration.set(TableInputFormat.INPUT_TABLE,"htb_wordcount") //通过调用方法来调用Hadoop中的任何一种输入类:[ImmutableBytesWritable, Result] val hbaseRdd: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD( configuration, classOf[TableInputFormat], classOf[ImmutableBytesWritable], classOf[Result] ) //todo:2-转换 val dataRdd: RDD[Result] = hbaseRdd.map(tuple => tuple._2) //todo:3-保存 dataRdd //加了take,会将数据从Executor返回到Driver中的一个数组中,再进行打印,要求,传输的对象要进行序列化,在Spark构建时定义序列化机制 .take(3) //如果不加take,是对RDD的数据打印,这个是在Executor中执行的打印 .foreach(rs => { //每个Result存储的是每个Rowkey的所有数据,每个rowkey包含很多列,每一列就是一个Cell对象,所有的列都在cell数组中 val cells: Array[Cell] = rs.rawCells() //取出每一列进行打印 cells.foreach(cell => { //从cell中取出rowkey,列族、列名、值 val rowkey = Bytes.toString(CellUtil.cloneRow(cell)) val family = Bytes.toString(CellUtil.cloneFamily(cell)) val column = Bytes.toString(CellUtil.cloneQualifier(cell)) val value = Bytes.toString(CellUtil.cloneValue(cell)) println(rowkey+"\t"+family+"\t"+column+"\t"+value) }) }) /** * step3:释放资源 */ Thread.sleep(1000000L) sc.stop() } }
2、MySQL
-
读MySQL:SparkCore中的应用比较少【表读进来变成了RDD,没有schema】,一般用SparkSQL来做
-
写MySQL:将Wordcount的结果写入MySQL中
-
登录MySQL:node1
mysql -uroot -p -
MySQL中创建表
USE db_test ; drop table if exists `tb_wordcount`; CREATE TABLE `tb_wordcount` ( `word` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL, `count` varchar(100) NOT NULL, PRIMARY KEY (`word`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ; -
代码实现
package bigdata.itcast.cn.spark.scala.core.mysql import java.sql.{Connection, DriverManager, PreparedStatement} import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @ClassName SparkCoreSimpleMode * @Description TODO Spark实现写mySQL * @Date 2020/12/12 17:58 * @Create By Frank */ object SparkCoreWriteToMySQL { /** * 用于构建连接,将每个分区的数据写入MySQL表中 * @param part:每个分区的数据 */ def saveToMySQL(part: Iterator[(String, Int)]): Unit = { //todo:申明MySQL8的驱动 Class.forName("com.mysql.cj.jdbc.Driver") //todo:定义连接对象 var conn:Connection = null var pstm:PreparedStatement = null try{ //todo:构建连接 conn = DriverManager.getConnection("jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true", "root","123456") //定义SQL语句 val sql = "insert into db_test.tb_wordcount values(?,?)" //初始化pstm pstm = conn.prepareStatement(sql) //给字段赋值 part.foreach{ case (word,numb) => { //给单词赋值 pstm.setString(1,word) //给个数赋值 pstm.setString(2,numb.toString) //将pstm放入批次中 pstm.addBatch() } } //执行batch中的所有语句 pstm.executeBatch() }catch { case e:Exception => e.printStackTrace() }finally { //最后如果不为null,就释放连接 if (pstm != null) pstm.close() if (conn != null) conn.close() } } def main(args: Array[String]): Unit = { /** * step1:初始化SparkContext */ val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[2]") // println(s"这是类名:${this.getClass.getSimpleName}") val sc = new SparkContext(conf) sc.setLogLevel("WARN") /** * step2:数据处理逻辑开发 */ //todo:1-读取数据 val inputRdd: RDD[String] = sc.textFile("datas/wordcount/wordcount.data") // println(inputRdd.first()) //todo:2-数据处理 val rsRdd: RDD[(String, Int)] = inputRdd .filter(line => null != line && line.trim.length > 0) .flatMap(line => line.split("\\s+")) .map(word => (word,1)) .reduceByKey(_+_) //todo:3-保存结果 rsRdd.foreach(tuple => println(tuple._1+"\t"+tuple._2)) // rsRdd.saveAsTextFile("/datas/output/wordcount/wc-"+System.currentTimeMillis()) //对每个分区调用方法将数据通过JDBC,写入MYSQL数据库中 rsRdd.foreachPartition(part => saveToMySQL(part)) /** * step3:释放资源 */ Thread.sleep(1000000L) sc.stop() } }
四、共享变量
1、Spark中的两种抽象

- RDD
- 共享变量:累加器、广播变量
2、广播变量:Broadcast Variables
- 功能:在Drive中定义一个变量,这个变量可以通过广播,放入每个Executor对应的内存中
- 类似于以前在MapReduce中的Map Join的原理
- 应用:如果每个Executor中的Task都需要用到一个变量
- 不做广播:每个Task都要向Driver进行请求获取这个变量的数据
- 做了广播:每个Task直接从自己所在的Executor中获取这个变量的数据即可
- 减少了Executor向Driver的请求和数据传输的次数
- 注意:一般可以用于避免产生宽依赖,避免shuffle
3、累加器:Accumulators
- 功能:做全局分布式的计数器
- 应用:一般用于测试开发调试代码时的验证
4、测试
-
需求:做Wordcount,过滤符号,只保留单词,显示符号出现的次数

-
正常的代码逻辑
inputRdd //先过滤空行 .filter(line => null != line && line.trim.length > 0) //取出每个单词 .flatMap(line => line.trim.split("\\s+")) //将符号过滤掉:判断当前的元素在不在符号集合中,在就不要 .filter(word => !list.contains(word)) //转换为二元组 .map(word => (word,1)) //分组聚合 .reduceByKey(_+_) .foreach(println)
-
广播变量与累加计数器
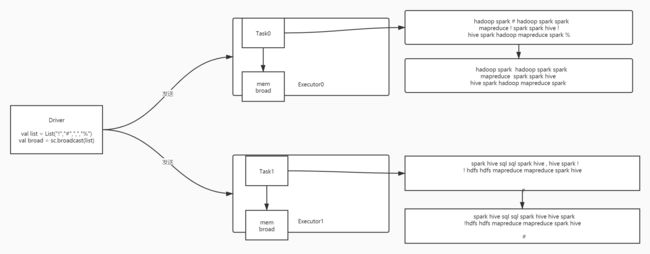
package bigdata.itcast.cn.spark.scala.core.share import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @ClassName SparkCoreMode * @Description TODO Spark Core中的广播变量与累加计数器 * @Date 2020/12/17 9:32 * @Create By Frank */ object SparkCoreShareVar { def main(args: Array[String]): Unit = { /** * step1:初始化一个SparkContext */ //构建配置对象 val conf = new SparkConf() .setAppName(this.getClass.getSimpleName.stripSuffix("$")) .setMaster("local[2]") //构建SparkContext的实例,如果存在,直接获取,如果不存在,就构建 val sc = SparkContext.getOrCreate(conf) //调整日志级别 sc.setLogLevel("WARN") /** * step2:实现数据的处理过程:读取、转换、保存 */ //todo:1-读取 //定义一个符号的集合:数据构建在Drive内存中 val list = List("!","#",",","%") //将这个list构建广播变量 val broad = sc.broadcast(list) //构建一个累加计数器 val numb_acc = sc.longAccumulator("numb_acc") val inputRdd: RDD[String] = sc.textFile("datas/filter/datas.input") //todo:2-转换 inputRdd //先过滤空行 .filter(line => null != line && line.trim.length > 0) //取出每个单词 .flatMap(line => line.trim.split("\\s+")) //将符号过滤掉:判断当前的元素在不在符号集合中,在就不要 .filter(word => { //从广播变量中将数据取出 val list1: Seq[String] = broad.value //如果是一个符号,就让全局累加计数器加1 if(list1.contains(word)){ numb_acc.add(1L) } //判断在不在集合中 !list1.contains(word) }) //转换为二元组 .map(word => (word,1)) //分组聚合 .reduceByKey(_+_) .foreach(println) println(s"acc_num = ${numb_acc.value}") //todo:3-保存 /** * step3:释放资源 */ Thread.sleep(1000000L) sc.stop() } }
五、SparkCore内核调度
1、宽窄依赖
-
RDD在转换过程中有两个概念
- 新的RDD:子RDD
- 来源RDD:父RDD
-
窄依赖:父RDD的一个分区的数据只给了子给了子RDD的一个分区
-
情况


-
特征:不需要经过shuffle过程
-
如果子rdd有个别的分区数据丢失,只要重新的构建父RDD对应的分区数据即可,不需要构建完整的父RDD
-
-
宽依赖:父RDD的一个分区的数据给了多个子RDD的分区
- 出链:父RDD的分区的出链有多条

- 特征:会经过shuffle过程,尽量避免宽依赖的产生
- 宽依赖也用于划分Stage
2、Spark Shuffle
-
Shuffle机制:1.6以后的版本全部选用了Sort Shuffle来实现,这种shuffle与MapReduce中的shuffle是一致的
-
Spark Shuffle阶段划分
- Shuffle Write:类似于Map阶段
- Shuffle Read:类似于Reduce阶段
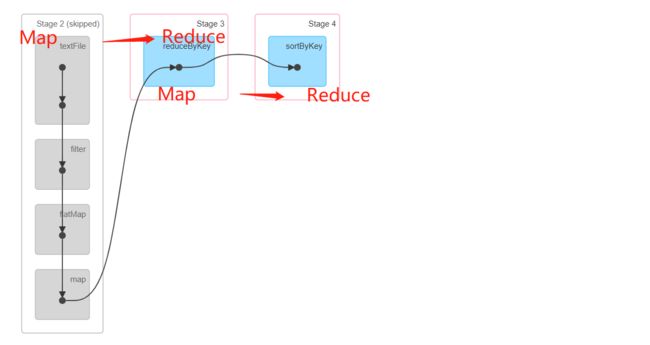
-
DAG图中对应的Stage划分

3、基本概念
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9oMHoDIK-1617857504868)(Day41_分布式计算平台Spark:SQL(一).assets/image-20201220120539337.png)]
- Application:用户基于Spark开发提交的一个程序,程序运行时会在集群中创建Driver和Executor进程
- MapReduce中的一个Application就是一个Job
- Spark中的一个Application中有多个job
- Application jar:用于自己打成jar包,永远不能包含Hadoop和Sparkjar 包,会导致jar包冲突
- Cluster manager:集群主节点
- Standalone:Master
- YARN:ResourceManager
- Work node:集群从节点
- Standalone:Worker
- YARN:NodeManger
- Driver Programe:每个Spark程序都会包含这个进程,主要构件实现的对象:SparkContext
- 申请资源
- 解析代码构建Task
- 调度Task
- 监控Task运行
- Executor:启动在Worker节点上,负责根据Driver的Task分配去执行Task
- deploy mode:决定了driver进程启动的位置
- client:客户端
- cluster:从节点上
- Task:真正的执行的任务,每个Task由1Core来运行
- Task运行Executor中
- Job:Spark程序中的触发执行单元,一旦job触发,就会构建DAG,每一个Job有一个DAG图
- driver代码解析程序遇到Action算子时,就会触发job
- DAG:有向无环图,先构建执行计划,所有RDD都是Lazy模式,定义所有RDD之间的关系
- 每个DAG会划分Stage,每个Stage会划分Task
- Stage:Job执行流程中的最小执行单元,每个Stage由单独的Task来完成
- Stage按照算子的宽依赖进行划分,通过回溯算法,遇到shuffle,就构建新的Stage
- 每个Stage会解析得到一个TaskSet:放了这个Stage需要执行的所有Task
- 每个TaskSet中对应的Task的个数由什么决定?
- 由RDD的最大分区数
4、调度流程

5、并行度
- 资源并行度:Executor的资源分配:Executor能够使用的资源来自于Worker
- 几个Executor
- 每个时刻都充分的利用所有分布式资源
- 决定于资源的使用率
- 每个Executor分配多少资源
- CPU的core数尽量为2个以上:保证每个Executor中的Task可以并行
- 内存的值一般建议给定CPU的两倍
- 几个Executor
- 数据并行度:分区的个数 = Task的个数
- 原则:某个时间提交的程序的Task的个数 = CPU核数的2 ~ 3 倍
- 程序中的RDD为所有Executor的核数 2 ~ 3倍
- 举个栗子
- 当前整个集群:100核
- 提交第一个程序:100分区 = 100Task = 100核
- 如果有些task提前结束,CPU当前就是空闲的
- 提交程序:200分区 = 200Task = 200核
- 同一时刻并行只能运行100Task
- 原则:某个时间提交的程序的Task的个数 = CPU核数的2 ~ 3 倍
六、SparkSQL介绍
1、问题与功能
-
SparkCore整体的使用与MapReduce是非常类似,通过代码开发的方式对数据文件进行处理
-
问题:公司中所有数据都放在数据仓库中Hive,Spark怎么处理数据仓库中的数据呢?
-
数据仓库中数据的形式:表
-
SparkCore处理数据的方式:将所有的数据读取进来变成RDD
-
Hive中表:emp
empno,ename,salary,hiredate,deptno -
SparkCore读取数据
RDD[String]
-
-
RDD来处理结构化数据的分析处理是非常不方便的
inputRdd = sc.textFile(emp.txt) inputRdd .map(line => { val arr = line.split (arr(7),1) }) .reduceByKey
-
-
原因:SparkCore中所有数据是存储RDD中,RDD只存储数据的本身的内容,而不会存储数据的Schema
- 什么是Schema:表的字段定义:列的名称、列的类型
-
需求:需要一种更加方便的开发结构去对结构化的数据进行处理
- 对于结构化数据的处理和分析,最合适的语言:SQL
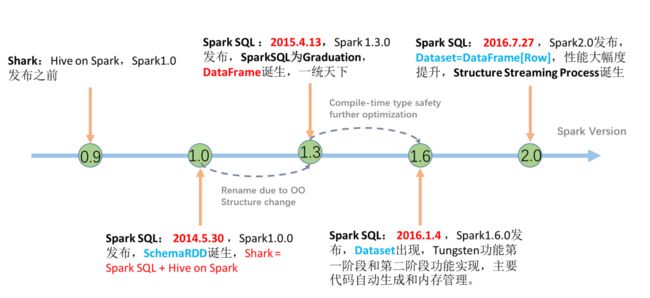
2、诞生于发展
- 诞生
- Shark:将Hive的源码进行了修改,将底层的翻译和解析转换为SparkCore程序
- DataBricks:后来发布Spark的时候,直接将Shark做了重构,基于Spark来实现解析
- SparkSQL
-
发展:解决RDD没有Schema问题
-
Spark1.0:SchemaRDD
-
Spark1.3:DataFrame
-
Spark1.6:DataSet,依旧保留了DataFrame
-
Spark2.0:DataSet【DataFrame成为了DataSet的一种特殊形式】

-
3、官方定义及特点
-
功能:通过结构化的开发接口来实现大数据的分布式计算的处理:底层SparkCore
-
官方:http://spark.apache.org/sql/
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CVz5QhEw-1617857504870)(Day41_分布式计算平台Spark:SQL(一).assets/image-20201220154438898.png)]
- SparkSQL专门用于对结构化数据做处理计算的Spark的模块
- 常见的结构化的数据
- 表
- 结构化:Json、tsv、csv、parquet
-
特点
- 高度集成了通用的SQL语句在Spark程序中
- 开发接口:SQL、DSL(特定领域的语言)
- SparkSQL支持各种结构化数据源的读写
- Hive、MySQL、文件
- 直接与Hive集成,访问数据仓库中的数据
- 支持各种标准的连接接口
- JDBC:与Hive的JDBC是一致的
- 直接使用Hive的源代码
- Hive中的服务端:hiveserver2:10000
- beeline
- SparkSQL服务端:ThriftServer:10000
- beeline
- JDBC:与Hive的JDBC是一致的
- 高度集成了通用的SQL语句在Spark程序中
-
设计
- SparkCore:将所有数据读取进来以后变成RDD【分布式集合】
- SparkSQL:将所有数据读取进来变成DataSet/DataFrame【分布式表】
- 通过SQL语句或者DSL函数来对表中的数据进行处理
- 分布式表与分布式集合有什么区别?
- 集合:数据
- 表:数据 + Schema[列的名称和列的类型]
4、应用场景
-
一般用于实现数据的处理
-
数据分析开发实现
-
同类型产品:Impala、Presto、Kylin
-
开发实时计算程序:Spark StructStreaming
5、DSL实现WordCount
-
理解:DSL就是将SQL语句的关键字变成了函数
select where groupBy orderBy having limit 都是对列处理的函数- 非常类似于RDD的函数式开发,与RDD开发的区别
- 将SQL中的关键词变成了函数,对列进行操作
-
代码实现
package bigdata.itcast.cn.spark.scala.sql.wordcount import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} import org.apache.spark.sql.functions._ /** * @ClassName SparkSQLWordCount * @Description TODO 通过sparkSQL的DSL方式来实现词频统计 * @Date 2020/12/20 16:00 * @Create By Frank */ object SparkSQLWordCountDSL { def main(args: Array[String]): Unit = { /** * step1:初始化资源:SparkSession * 理解:里面封装了SparkContext和SparkConf */ val spark = SparkSession //获取一个建造器 .builder() //设置程序名称 .appName(this.getClass.getSimpleName.stripSuffix("$")) //设置Master地址 .master("local[2]") //获取一个SparkSession对象 .getOrCreate() //导入当前sparkSession的隐式转换 import spark.implicits._ //调整日志级别 spark.sparkContext.setLogLevel("WARN") /** * step2:实现处理 */ //todo:1-读取数据:DS或者DF val inputData: Dataset[String] = spark.read.textFile("datas/wordcount/wordcount.data") //打印schema信息 /** * root * |-- value: string (nullable = true) */ // inputData.printSchema() //打印数据:默认显示前20行 // inputData.show(20,false) // inputData.show(20,false):第一个参数表示显示这张表的前多少行,第二个参数表示如果列的数据过长,是否用省略号代替显示 //todo:2-数据处理 val rsData = inputData //过滤 .filter(line => line != null && line.trim.length > 0) //分词 .flatMap(line => line.trim.split("\\s+")) //分组:列名的前面加上$表示这是一列 .groupBy($"value") //聚合:按照分组的字段自动进行聚合 .count() //todo:3-输出结果 rsData.printSchema() rsData.show() /** * step3:释放资源 */ spark.stop() } }
6、SQL实现WordCount
-
流程
- step1:读取数据,将数据变成DS或者DF
- step2:将DS或者DF注册为一个视图【只读的表】
- step3:使用SQL语句对视图进行处理
-
SparkSession:用于替代SparkContext的对象
- 提供更丰富的数据接口
- 以及SQL一些处理的规则
- 设计:基于SparkContext封装了
-
代码实现
package bigdata.itcast.cn.spark.scala.sql.wordcount import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} /** * @ClassName SparkSQLWordCount * @Description TODO 通过sparkSQL来实现词频统计 * @Date 2020/12/20 16:00 * @Create By Frank */ object SparkSQLWordCount { def main(args: Array[String]): Unit = { /** * step1:初始化资源:SparkSession * 理解:里面封装了SparkContext和SparkConf */ val spark = SparkSession //获取一个建造器 .builder() //设置程序名称 .appName(this.getClass.getSimpleName.stripSuffix("$")) //设置Master地址 .master("local[2]") //获取一个SparkSession对象 .getOrCreate() //导入当前sparkSession的隐式转换 import spark.implicits._ //调整日志级别 spark.sparkContext.setLogLevel("WARN") /** * step2:实现处理 */ //todo:1-读取数据:DS或者DF val inputData: Dataset[String] = spark.read.textFile("datas/wordcount/wordcount.data") //打印schema信息 /** * root * |-- value: string (nullable = true) */ // inputData.printSchema() //打印数据:默认显示前20行 // inputData.show(20,false) // inputData.show(20,false):第一个参数表示显示这张表的前多少行,第二个参数表示如果列的数据过长,是否用省略号代替显示 //todo:2-数据处理 /** * etl:将每一行的每个单词变成一行 */ val etlData: Dataset[String] = inputData .filter(line => line != null && line.trim.length > 0) .flatMap(line => line.trim.split("\\s+")) // etlData.printSchema() // etlData.show() /** * 方式一:使用SQL来进行处理 */ //将当前的etldata注册为视图 etlData.createOrReplaceTempView("tmp_view_wc") //写SQL语句来对视图进行处理 val rs1: DataFrame = spark.sql( """ | select value,count(1) as numb from tmp_view_wc group by value """.stripMargin) //todo:3-输出结果 /** * root * |-- value: string (nullable = true) * |-- numb: long (nullable = false) */ rs1.printSchema() rs1.show() /** * step3:释放资源 */ spark.stop() } }
七、数据结构抽象

1、RDD、DataFrame、DataSet
-
区别
-
RDD:只能存储数据的内容,支持泛型
- 定义:RDD[T]
-
DataFrame:既能存储数据的内容,会包含数据的Schema信息,没有泛型,所有DataFrame中存储的数据都是Row类型
-
定义:DataFrame
-
2.x开始:没有DataFrame类,直接使用Dataset构建的别名
type DataFrame = Dataset[Row]
-
-
DataSet:既能存储数据的内容,会包含数据的Schema信息,支持泛型
- 定义:DataSet[T]
-
-
上传测试文件
cd /export/server/spark hdfs dfs -put examples/src/main/resources /datas/ -
RDD的类型

- 只能将每一条数据作为一个String对象存储,不知道每条数据中会包含人的属性
-
DataFrame类型

- 解析数据,并且得到对应的每列的信息,但是DataFrame中没有泛型
-
DataSet类型

- 解析数据或者为数据添加列的信息,并且有泛型
2、Row类型
-
DataFrame中的数据类型就是Row类型
scala> val row1 = dfData.first row1: org.apache.spark.sql.Row = [null,Michael] -
创建两种方式
* // Create a Row from values. * Row(value1, value2, value3, ...) * // Create a Row from a Seq of values. * Row.fromSeq(Seq(value1, value2, ...))- 直接创建对象
- 构建集合来创建
-
读取数据
//方式一:一般不用 scala> row1.get(1) res0: Any = Michael //方式二 scala> row1.getString(1) res1: String = Michael //方式三 scala> row1.getAs[String](1) res2: String = Michael scala> row1.getAs[String]("name") res3: String = Michael
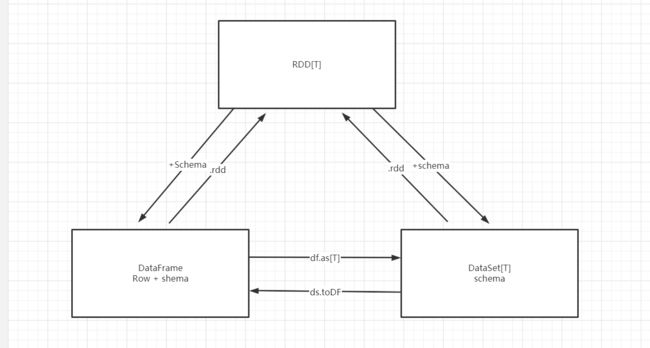
3、关系转换
-
RDD[T] + Schema=> DataSet[T]
-
RDD[Row] + Schema => DataFrame
-
DataSet[Row] = DataFrame
-
如何从DS或者DF中转换为RDD
-
函数:ds/df.rdd
scala> val dfRdd = dfData.rdd dfRdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[14] at rdd at:25 -
从DS或者DF中取出Schema:.schema
scala> val schema = dfData.schema schema: org.apache.spark.sql.types.StructType = StructType(StructField(age,LongType,true), StructField(name,StringType,true))
-
-
如何将RDD转换为DS或者DF
Spark SQL supports two different methods for converting existing RDDs into Datasets. The first method uses reflection to infer the schema of an RDD that contains specific types of objects. the second method for creating Datasets is through a programmatic interface that allows you to construct a schema and then apply it to an existing RDD- 方式一:通过反射的方式构建:将RDD中的类型变成一个样例类
- 方式二:自己将RDD和schema合并为一个DS或者DF
-
代码实现
package bigdata.itcast.cn.spark.scala.sql.typeTrans import org.apache.spark.rdd.RDD import org.apache.spark.sql.types._ import org.apache.spark.sql.{DataFrame, Row, SparkSession} /** * @ClassName SparkSQLWordCount * @Description TODO 将RDD转换为DF或者DS * @Date 2020/12/20 16:00 * @Create By Frank */ object SparkSQLTypeTrans { def main(args: Array[String]): Unit = { /** * step1:初始化资源:SparkSession * 理解:里面封装了SparkContext和SparkConf */ val spark = SparkSession //获取一个建造器 .builder() //设置程序名称 .appName(this.getClass.getSimpleName.stripSuffix("$")) //设置Master地址 .master("local[2]") //获取一个SparkSession对象 .getOrCreate() //导入当前sparkSession的隐式转换 import spark.implicits._ //导入SparkSQL的函数库 // import org.apache.spark.sql.functions._ //调整日志级别 spark.sparkContext.setLogLevel("WARN") /** * step2:实现处理 */ //todo:1-读取数据:DS或者DF val inputRdd: RDD[String] = spark.sparkContext.textFile("datas/ml-100k/u.data") //todo:2-数据处理 /** * 方式一:反射构建的方式:让RDD中存储的类型变成样例类 */ val dataRdd: RDD[MovieRating] = inputRdd .map(line => { //先分割得到每个元素 val Array(userId,itemId,rating,timestamp) = line.trim.split("\\s+") //返回一个样例类对象 MovieRating(userId,itemId,rating.toDouble,timestamp.toLong) }) //构建DF或者DS // val df1 = dataRdd.toDF() // val ds1 = dataRdd.toDS() // df1.printSchema() // ds1.printSchema() // df1.show() // ds1.show() /** * 方式二:RDD + Schema = DS,自定义一个Schema就可以了 */ //创建row类型的RDD val rowRdd: RDD[Row] = inputRdd .map(line => { //先分割得到每个元素 val Array(userId,itemId,rating,timestamp) = line.trim.split("\\s+") //返回一个样例类对象 Row(userId,itemId,rating.toDouble,timestamp.toLong) }) //根据RDD的数据内容创建Schema:StructField:每一列的信息 val schema = StructType(Array( StructField("userId",StringType,false), StructField("itemId",StringType,false), StructField("rating",DoubleType,false), StructField("timestamp",LongType,false) )) //RDD + Schema val df2: DataFrame = spark.createDataFrame(rowRdd,schema) val ds2 = df2.as[MovieRating] df2.printSchema() // ds2.printSchema() df2.show() ds2.show() //todo:3-输出结果 /** * step3:释放资源 */ spark.stop() } }
八、DSL与SQL分析
1、DSL
2、SQL
3、性能
附录一:Spark Maven依赖
<repositories>
<repository>
<id>aliyunid>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
repository>
<repository>
<id>clouderaid>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/url>
repository>
<repository>
<id>jbossid>
<url>http://repository.jboss.com/nexus/content/groups/publicurl>
repository>
repositories>
<properties>
<scala.version>2.11.12scala.version>
<scala.binary.version>2.11scala.binary.version>
<spark.version>2.4.5spark.version>
<hadoop.version>2.6.0-cdh5.16.2hadoop.version>
<hbase.version>1.2.0-cdh5.16.2hbase.version>
<mysql.version>8.0.19mysql.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive-thriftserver_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-avro_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-mllib_${scala.binary.version}artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>${hbase.version}version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-hadoop2-compatartifactId>
<version>${hbase.version}version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>${hbase.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>${mysql.version}version>
dependency>
dependencies>
<build>
<outputDirectory>target/classesoutputDirectory>
<testOutputDirectory>target/test-classestestOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resourcesdirectory>
resource>
resources>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.0version>
<configuration>
<source>1.8source>
<target>1.8target>
<encoding>UTF-8encoding>
configuration>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.0version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
plugins>
build>
