Android 断点续传实现原理
转载请标明出处:http://blog.csdn.net/zhaoyanjun6/article/details/120956134
本文出自【赵彦军的博客】
文章目录
- 下载原理
- 断点续传原理
-
- 1、java.io.RandomAccessFile
- 2、请求响应码及Header
- 3、处理请求资源发生改变的问题
- 4、文件可复用判断
下载原理
在介绍断点续传之前,我们先说说下载的原理。代码示例用 OkHttp 作为示例。
下载核心思路是把 responseBody 写入文件,核心代码如下:
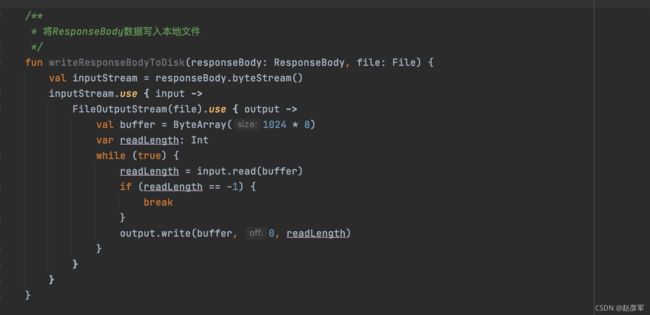
但是这种做法有个明显的问题,假如手机在下载文件的时候下载了80%,某些原因断网了,如果不支持断点续传,那就只有被迫重头开始下载。但是如果有断点续传的加持,就只需要下载最后 20% 的资源,避免重新下载。
断点续传原理
1、java.io.RandomAccessFile
断点续传/下载需要使用到 java.io.RandomAccessFile 类,RandomAccessFile 的实例支持读取和写入随机访问文件,它也可以 seek(long pos) 设置从此文件的开头开始测量的文件指针偏移量,在该位置进行下一次读取或写入操作。简单点说就是可以通过 seek(long pos)方法跳过pos字节开始写入字节。
如何创建一个 RandomAccessFile ?
//rw:支持可读可写
val file = RandomAccessFile(file, "rw")
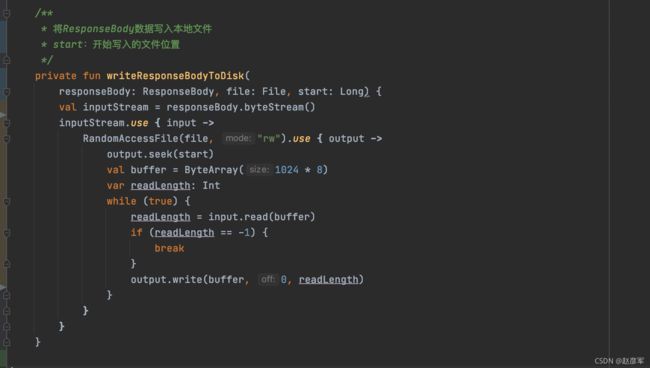
假如我有一段文本要写入文件,但是需要从文件的第100个字节开始写,那么需要调用 seek(long pos ) 方法跳过前 100 个字节, 具体实现如下:
val file = RandomAccessFile(file, "rw")
file.seek(100)
file.writeBytes(.....)
所以,我们可以把 responseBody 写入文件的实现改成如下实现:
2、请求响应码及Header
正常情况下,我们下载一个文件,响应码是 200

responseBody 返回的是整个文件的内容。如何才能返回部分内容?
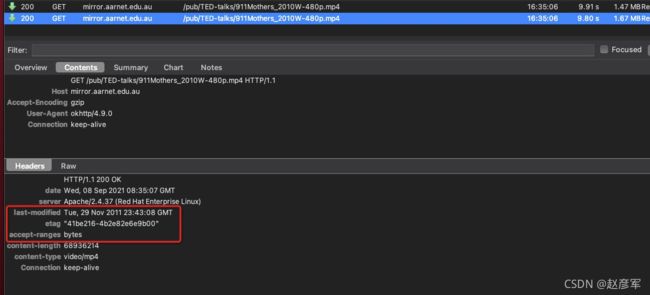
在实现分块请求之前,首先要判断服务器是否支持分块返回,标志是 Access-Ranges ,值为 bytes 就代表服务器支持分块返回,也就是支持断点续传。
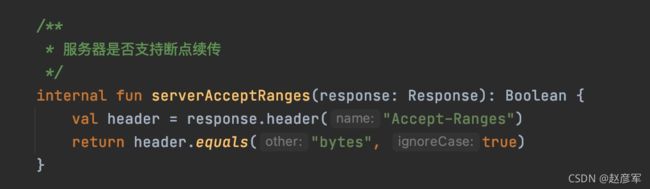
所以,我们可以封装一个方法,来判断服务是否支持断点续传
在确定了服务器支持分块传输后,我们就可以在请求资源的时候,添加 header 请求 Range 字段,来指定请求实体的范围。它的范围取值是在 0-Content-Length 之间,使用 - 分割。
例如已经下载了 1000 bytes 的资源内容,想接着继续下载之后的资源内容,只要在 HTTP 请求头部,增加 Range:bytes=1000- 就可以了。
Range 还有几种不同的方式来限定范围,可以根据需要灵活定制:
- 500-1000:指定开始和结束的范围。
- 500- :指定开始区间,一直传递到结束。这个就比较适用于断点续传、或者在线播放等等。
- -500:无开始区间,只意思是需要最后 500 bytes 的内容实体。
- 100-300,1000-3000:指定多个范围,这种方式使用的场景很少,了解一下就好了。
具体举例如下:
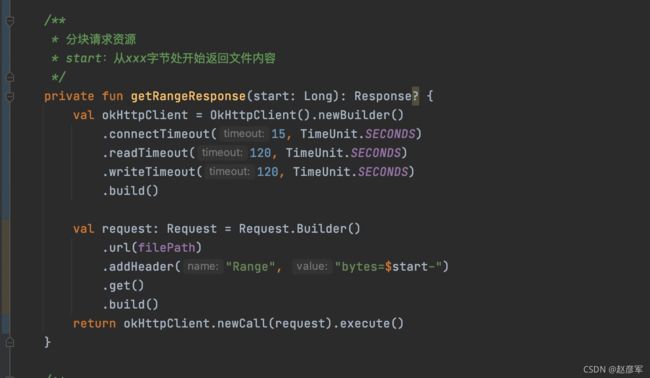
通过抓包我们发现,添加了 Range 后,请求响应码变成了 206
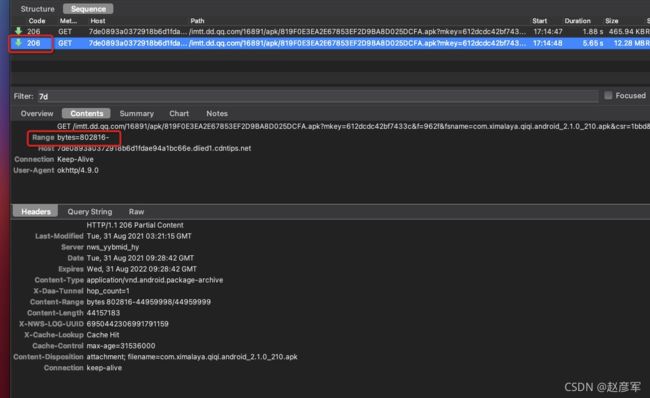
并且添加 Range 后,响应的 responseBody 就不再是整个文件的内容了,而是一个片段,我们只需要把这个片段的数据直接写入文件就可以。
注意事项,如何计算 Range 请求头的开始值,一般取用缓存文件的长度值,如下
val start = targetFile.length()
3、处理请求资源发生改变的问题
在现实的场景中,服务器中的文件是会有发生变化的情况的,那么我们发起续传的请求肯定是失败的
那么为了处理这种服务器文件资源发生改变的问题,在 RFC2616 中定义了 Last-Modified和 Etag 来判断续传文件资源是否发生改变。
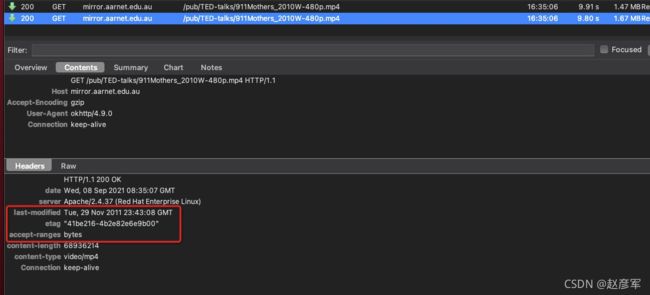
- Last-Modified:记录 Http 页面最后修改时间的 Http 头部参数,Last-Modified 是由服务端发送给客户端的
- Etag:作为文件的唯一标志,这个标志可以是文件的 hash 值或者是一个版本
我们封装一个方法用来获取这两个值

if-Range:用于判断实体是否发生改变,如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体。一般格式:
If-Range: Etag | HTTP-Date
If-Range 可以使用 Etag 或者 Last-Modified 返回的值。当没有 ETage 却有 Last-modified 时,可以把 Last-modified 作为 If-Range 字段的值。实现举例如下:

关于 Etag 、Last-Modified 注意事项:
- 当第一次请求资源的时候,获取
Etag/Last-Modified值,并且保存到本地 - 当下一次需要断点续传的时候,把
Etag/Last-Modified值取出,添加到请求头If-Range字段
4、文件可复用判断
在文件下载完成后,如果又发起了一次下载请求,那么此时不应该重复下载的。需要做可复用判断,思路如下
- 1、获取目前已下载文件的大小
- 2、获取文件url 获取服务器文件大小
- 3、如果已下载大小等于服务器文件大小,则复用已下载的文件
举例如下:
//获取已下载文件长度
val downloadLength = targetFile.length()
//获取服务器文件长度
val contentLength = responseBody.contentLength()
//两者长度对比
if(downloadLength == contentLength){
//复用已下载文件,不再重复下载
}