11.网络爬虫—多线程详讲与实战
11.网络爬虫—多线程详讲与实战
-
- 程序
- 进程
- 线程
-
- 线程常用方法
- 多线程的优点
-
- join() 案例
- 共享全局变量资源竞争
- 互斥锁&死锁
-
- 互斥锁
- 死锁
- 多线程实战
-
- 某果多线程实战
前言:
️️个人简介:以山河作礼。
️️:Python领域新星创作者,CSDN实力新星认证
第一篇文章《1.认识网络爬虫》获得全站热榜第一,python领域热榜第一。
第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八。
第八篇文章《8.网络爬虫—正则表达式RE实战》全站热榜第十二。
第十篇文章《10.网络爬虫—MongoDB详讲与实战》全站热榜第八,领域热榜第二
《Python网络爬虫》专栏累计发表十篇文章,上榜四篇。欢迎免费订阅!欢迎大家一起学习,一起成长!!
悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
在第一章节我们讲过,每个爬虫都是你的分身,我们本章节就教大家怎么使用分身。

程序
程序是一系列指令或代码的集合,用于指导计算机执行特定的任务或操作。
程序可以是
计算机程序、应用程序、脚本程序等,可以用不同的编程语言编写。程序通过计算机的处理和执行,实现了人类所需要的各种功能和应用。
进程
进程是计算机中正在运行的程序的实例。
它是计算机为了完成某个任务而创建的一个执行单元,包含程序代码、数据和执行状态等信息。
- 每个进程都有自己的
内存地址空间、文件句柄、网络连接等资源。 - 进程可以与其他进程进行通信和协作,也可以被操作系统调度和管理。
- 在
多任务操作系统中,多个进程可以同时运行,共享计算机的资源,提高计算机的效率和性能。
线程
线程是进程中的一个执行单元,是计算机执行程序时的最小单位。
一个进程可以包含多个线程,每个线程都有自己的执行路径、堆栈和局部变量等。- 不同的线程可以同时执行不同的任务,共享进程的资源,提高计算机的效率和性能。
- 线程可以被操作系统调度和管理,也可以通过同步机制来协调各自的执行。
- 线程的优点
是可以充分利用多核处理器的并行性,提高程序的响应速度和并发处理能力。
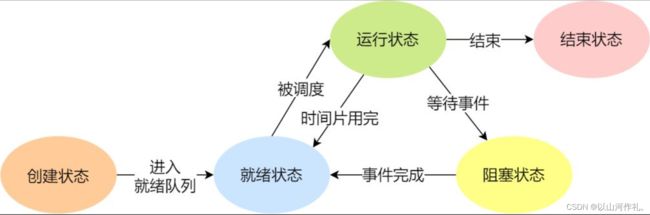
线程常用方法
线程常用方法包括:
start():启动线程,开始执行线程的run()方法。
2.run():线程的主体方法,包含线程要执行的代码。
-
join():等待线程结束,让主线程等待子线程执行完毕。 -
sleep():使线程暂停执行一段时间,以便其他线程有机会执行。 -
interrupt():中断线程,通知线程停止运行。 -
isAlive():判断线程是否还在运行。 -
setDaemon():将线程设置为守护线程,当主线程结束后,守护线程会自动结束。 -
yield():让出CPU,让其他线程有机会执行。 -
wait():使线程进入等待状态,直到其他线程调用notify()或notifyAll()方法唤醒它。 -
notify()和notifyAll():唤醒等待中的线程,使其继续执行。
多线程的优点
多线程的优点主要有以下几点:
-
提高爬取速度:使用多线程技术可以同时处理多个任务,从而提高爬取速度。在单线程模式下,程序需要一个一个地处理每个任务,而在多线程模式下,程序可以同时处理多个任务,从而节省了大量的时间。
-
提高效率:在处理大量数据时,使用多线程技术可以大大缩短程序的运行时间,从而提高效率。这对于需要处理大量数据的应用场景非常有用,比如搜索引擎、数据挖掘等。
-
降低资源占用率:使用多线程技术可以将任务分配到不同的线程中执行,从而降低了单个线程对资源的占用率,比如CPU、内存等。这样可以避免单个线程因为资源占用过高而导致程序崩溃或者运行缓慢的问题。
-
提高程序的可扩展性:使用多线程技术可以将任务分配到不同的线程中执行,从而方便程序的扩展和升级。如果需要增加新的功能或者处理更多的数据,只需要增加更多的线程即可。
join() 案例
为了方便理解,代码注释放在了代码片中。
from time import sleep, time # 导入需要使用的模块和函数
import threading # 多线程模块,内置模块
def main1():
print('开始运行main1')
sleep(3)
print('运行完成main1')
def main2():
print('开始运行main2')
sleep(3)
print('运行完成main2')
# 定义两个函数main1和main2,分别打印开始运行和运行完成的信息,并在函数中使用sleep函数模拟函数执行时间。
start = time() # 使用time函数记录程序开始运行的时间。
t1 = threading.Thread(target=main1)
t1.start()
t2 = threading.Thread(target=main2)
t2.start()
# 使用Thread函数创建两个线程t1和t2,分别执行main1和main2函数。
t1.join() # 阻塞主线程 等待t1线程运行完成
t2.join()
# 使用join方法阻塞主线程,等待t1和t2线程运行完成后再继续执行主线程
stop = time() # 使用time函数记录程序结束运行的时间。
print(stop - start) # 输出程序运行时间。
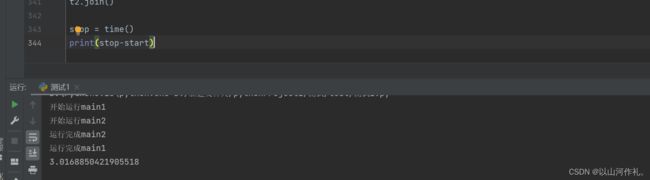
整体来说,就是创建了两个线程t1和t2,分别执行main1和main2函数。在主线程中,使用join方法阻塞主线程,等待t1和t2线程运行完成后再继续执行主线程。最后输出程序运行时间。
使用多线程模块threading实现并发执行多个函数的效果,提高程序的运行效率。
共享全局变量资源竞争
全局变量是在模块级别定义的,因此在多个线程或进程中访问全局变量可能会发生资源竞争
为了避免这种情况,可以使用线程锁或进程锁来同步对全局变量的访问。
在使用多线程的情况下,可以使用Python的threading模块中的Lock类来实现线程锁。在访问全局变量之前,线程可以调用acquire()方法来获取锁,并在完成后调用release()方法来释放锁。这样,只有一个线程可以同时访问全局变量,从而避免了资源竞争。
以下是一个使用线程锁来避免全局变量资源竞争的示例代码:
import threading
# 定义全局变量
count = 0
# 定义线程锁
lock = threading.Lock()
# 定义线程函数
def increment():
global count
# 获取线程锁
lock.acquire()
try:
# 访问全局变量
count += 1
finally:
# 释放线程锁
lock.release()
# 创建多个线程
threads = []
for i in range(10):
t = threading.Thread(target=increment)
threads.append(t)
# 启动线程
for t in threads:
t.start()
# 等待所有线程完成
for t in threads:
t.join()
# 输出结果
print("count = ", count)

在上面的代码中,我们定义了一个全局变量count和一个线程锁lock。然后,我们定义了一个increment()`函数,该函数通过获取线程锁来访问全局变量count,并将其递增。最后,我们创建了10个线程,并在每个线程中调用increment()函数。在访问全局变量之前,每个线程都会获取线程锁,并在完成后释放它。这样,我们可以确保只有一个线程可以同时访问全局变量count,从而避免了资源竞争。最后,我们输出count的值,以验证它是否正确地递增了。
互斥锁&死锁
互斥锁
互斥锁(Mutex)是一种同步机制,用于保护共享资源不被并发访问。在Python中,可以使用threading模块中的Lock类来实现互斥锁。
下面是一个简单的例子,说明如何使用互斥锁来保护共享变量:
import threading
x = 0
lock = threading.Lock()
def increment():
global x
for i in range(100000):
lock.acquire()
x += 1
lock.release()
t1 = threading.Thread(target=increment)
t2 = threading.Thread(target=increment)
t1.start()
t2.start()
t1.join()
t2.join()
print(x)

上述代码中,我们定义了一个全局变量x,然后创建了两个线程t1和t2,每个线程都会对x进行100000次加1操作。为了避免并发访问导致数据出错,我们使用了Lock类来保护x。具体来说,当一个线程获取到锁时,其他线程就不能获取锁,直到该线程释放锁为止。
死锁
死锁指的是两个或多个线程在等待对方释放资源的状态,从而导致程序无法继续执行。
在Python中,死锁通常发生在多个线程同时获取多个锁的情况下。为了避免死锁,我们应该尽量避免使用多个锁。
下面是一个简单的死锁例子:
import threading
lock1 = threading.Lock()
lock2 = threading.Lock()
def func1():
lock1.acquire()
lock2.acquire()
print("Func1")
lock2.release()
lock1.release()
def func2():
lock2.acquire()
lock1.acquire()
print("Func2")
lock1.release()
lock2.release()
t1 = threading.Thread(target=func1)
t2 = threading.Thread(target=func2)
t1.start()
t2.start()
t1.join()
t2.join()
上述代码中,我们定义了两个锁lock1和lock2,然后创建了两个线程t1和t2,每个线程都需要获取两个锁才能继续执行。由于t1和t2同时获取了一个锁,然后又试图获取另一个锁,导致两个线程都陷入了等待状态,无法继续执行,从而引发了死锁。
多线程实战
某果多线程实战
本次实战目的是使用多线程获取网站前十页数据的菜·
标题,作者,观看人数,收藏人数。
在这里,我们使用之前学过的知识,用最常用的方式先获取网站前十页的数据。如果有什么问题,可以阅读专栏之前的文章帮助理解学习。《Python网络爬虫》,累计阅读6w+。
获取数据完整代码如下:
import requests
from lxml import etree
from tabulate import tabulate
import time
for j in range(0, 217, 24):
url = f'https://www.douguo.com/jingxuan/{j}'
res = requests.get(url)
# print(res.text)
html = etree.HTML(res.text)
for i in range(1, 25):
name = html.xpath(f'//*[@id="jxlist"]/li[{i}]/div/a[1]/text()')
author = html.xpath(f'//*[@id="jxlist"]/li[{i}]/div/a[2]/text()')[1].strip()
watch = html.xpath(f'//*[@id="jxlist"]/li[{i}]/div/div/span[1]/text()')
Collection = html.xpath(f'//*[@id="jxlist"]/li[{i}]/div/div/span[2]/text()')
result = tabulate([[name, author, watch, Collection]],
headers=['Name', 'Author', 'Watch', 'Collection'], tablefmt='orgtbl')
print(result)
time.sleep(1)
运行结果展示部分,因为内容较多: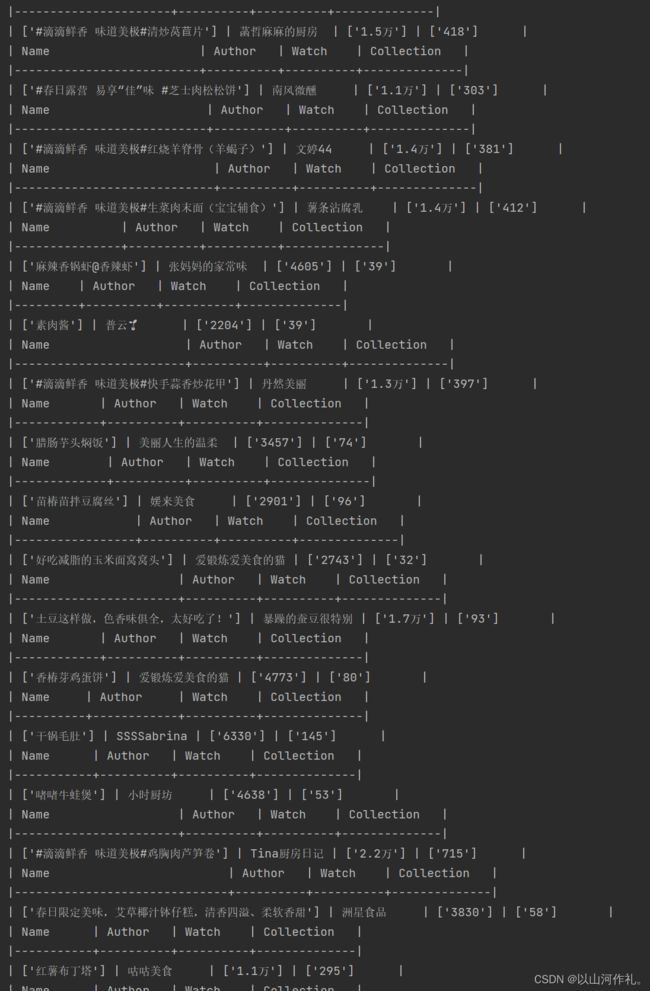
我在这里大概讲解一下代码的含义:
- 使用requests库向指定的网址发送请求,并获取网页的源代码。
- 使用lxml库中的etree类将源代码解析成HTML文档对象
- 使用for循环遍历每一页上的所有菜谱,通过xpath表达式提取出菜谱的名称、作者、浏览量和收藏量等信息。
- 使用tabulate库将提取出来的信息以表格形式打印出来。
- 为了防止爬取速度过快被网站封禁,代码中使用了time库中的sleep函数,每爬取一页后暂停1秒钟。
我们先计算一下,获取每一页数据需要多少时间和总体需要多少时间:
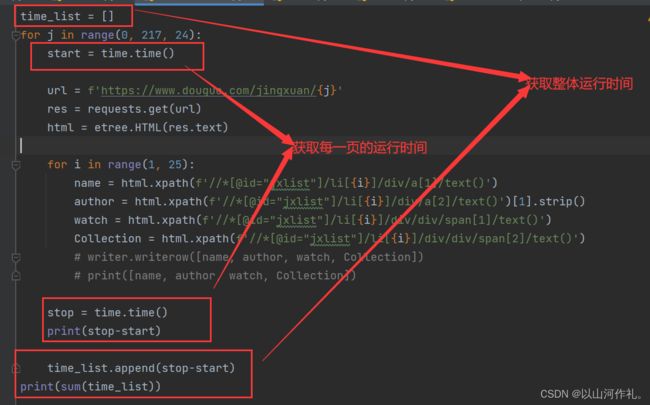

接下来我们使用多线程来操作,多线程运行的部分需要是一个函数,所以我们把主体部分封装成一个函数:
def save_data(url):
with codecs.open('douguo5.csv', 'a', 'utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
res = requests.get(url)
html = etree.HTML(res.text)
for i in range(1, 25):
name = html.xpath(f'//*[@id="jxlist"]/li[{i}]/div/a[1]/text()')
author = html.xpath(f'//*[@id="jxlist"]/li[{i}]/div/a[2]/text()')[1].strip()
watch = html.xpath(f'//*[@id="jxlist"]/li[{i}]/div/div/span[1]/text()')
Collection = html.xpath(f'//*[@id="jxlist"]/li[{i}]/div/div/span[2]/text()')
writer.writerow([name, author, watch, Collection])
print([name, author, watch, Collection])
然后我们使用多线程技术加速爬取数据的速度。
- 先定义了一个名为
t_list的列表,用于存储线程对象。 - 使用一个
for循环遍历所有需要爬取的网页,将每个网页的爬取任务分配给一个线程,并将该线程对象添加到t_list列表中。 - 使用
threading.Thread方法创建一个名为t1的线程对象,将save_data函数作为target参数传入,并将url作为args参数传入。 - 调用
t1.start()方法启动线程,并将t1添加到t_list列表中。 - 使用另一个for循环遍历t_list列表中的所有线程对象,并调用
i.join()方法等待所有线程执行完毕。 join方法会阻塞当前线程,直到被调用的线程执行完毕。
在这个for循环中,主线程会等待所有子线程都执行完毕后再继续执行下面的代码。
最后,代码计算并输出了程序的运行时间,即
stop - start的值。这个值表示程序从开始执行到结束所用的时间,可以用来评估程序的效率和性能。
完整代码如下:
import codecs
import csv
import time
import requests
from lxml import etree
def save_data(url):
with codecs.open('douguo5.csv', 'a', 'utf-8-sig') as csvfile:
writer = csv.writer(csvfile)
res = requests.get(url)
html = etree.HTML(res.text)
for i in range(1, 25):
name = html.xpath(f'//*[@id="jxlist"]/li[{i}]/div/a[1]/text()')
author = html.xpath(f'//*[@id="jxlist"]/li[{i}]/div/a[2]/text()')[1].strip()
watch = html.xpath(f'//*[@id="jxlist"]/li[{i}]/div/div/span[1]/text()')
Collection = html.xpath(f'//*[@id="jxlist"]/li[{i}]/div/div/span[2]/text()')
writer.writerow([name, author, watch, Collection])
print([name, author, watch, Collection])
import threading
start = time.time()
t_list = []
for j in range(0, 217, 24):
url = f'https://www.douguo.com/jingxuan/{j}'
# save_data(url)
t1 = threading.Thread(target=save_data, args=(url,))
t1.start()
t_list.append(t1)
for i in t_list:
i.join()
stop = time.time()
print(stop - start)
我们可以看到,运行时间大大缩短。
提高爬取速度和效率。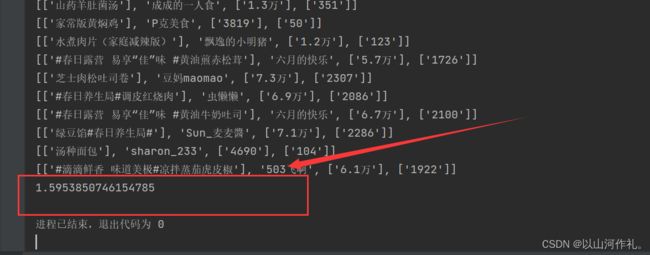
写在最后:
本专栏所有文章是博主学习笔记,仅供学习使用,爬虫只是一种技术,希望学习过的人能正确使用它。博主也会定时一周三更爬虫相关技术更大家系统学习,如有问题,可以私信我,没有回,那我可能在上课或者睡觉,写作不易,感谢大家的支持!!