yolov5部署以及训练10种中药材分类数据集
记录以下我使用yolov5来训练自己数据集的过程以及遇到的坑~~~
首先要部署yolov5的环境
首先去github上下载yolov5直达
安装依赖包
编译环境我是用的是anaconda 创建的虚拟环境,方便管理,如何创建虚拟环境就不细讲了。创建好之后根据yolov5中的requirment.txt安装它需要的依赖包。
方式一:之前第一次配置环境的时候,用的是pycharm来安装依赖,有几个包一直报错,还是通过pip install 包.whl的方式安装上的,特别是coco。
方式二:后来换了电脑,直接在anaconda prompt中通过pip就很顺利的就装好了。
还是推荐方式二安装依赖包,方便又好管理。
测试yolov5
进入anaconda的虚拟环境,进入到yolov5的路径下,执行:
python detect.py --source 0
--source 0 表示是用电脑的摄像头,采集视频。如果不想采集视频,可以不加上source,直接使用\data\images文件下的测试图片不管是图片还是视频,测试的结果会保存在yolov5项目中\runs\detect\exp文件夹下。
这样yolov5就部署好了,可以训练自己的数据集了。
准备训练集
yolov5的数据集的形式有很多种,我才用的是
图片与标签分开存放在不同的文件夹下,目录如下:

images中存放的是训练和验证的图片,labels中存放的是标签。之前存放图片的文件夹名称为img,在训练的时候老是报错not found labels,改成images就好了。
标签和图片是根据图片名称来对应的。
打标签用的是LabelImg,使用的方法就不介绍了,记得使用YOLO的标签格式
更改程序
一:将data/coco128.yaml文件更改三个地方:
1.train/val 的路径 更改为自己的图片的存放地址,标签的地址可以自动推断出来
2.nc 更改分类数目
3.names 更改分类名称
下面是根据我的数据集更改过后的文件
# COCO 2017 dataset http://cocodataset.org - first 128 training images
# Train command: python train.py --data coco128.yaml
# Default dataset location is next to YOLOv5:
# /parent_folder
# /coco128
# /yolov5
# download command/URL (optional)
download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../train_imgs/images/train # 1700 images
val: ../train_imgs/images/val # 100 images
# number of classes
nc: 10
# class names
names: [ 'aiye', 'ajiao', 'baifan', 'banxia', 'chenpi', 'honghua' ,'puhuang', 'shanzha' ,'xiakucao', 'xixin' ]
二:根据在train.py当中要使用的权重文件,比如更改yolo5s.yaml文件,这里只需要更改nc就可以了
下面是更过后的文件,只更改了nc
# parameters
nc: 10 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
训练模型
有了数据集可以开始训练了
进入虚拟环境,进入yolov5的目录,执行:
python train.py --device 0
--device 0表示使用gpu0来训练模型,如果没有gpu的话,不用加上 device,默认是cpu。
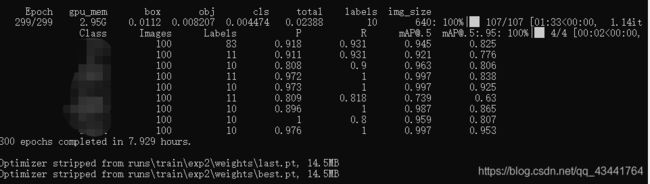
正常训练结束如下图,会产生两个模型文件best.pt和last.pt,保存在\runs\train\exp\weights文件夹下。
报错
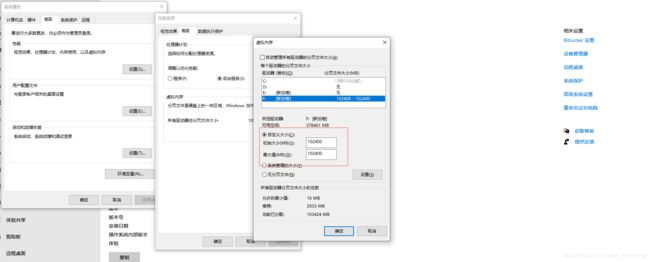
在训练的时候报错说:OSError: [WinError 1455] 页面文件太小,无法完成操作,这是内存太小,更改虚拟内存的页面大小,可以解决。
测试自己的模型
首先要更改train.py文件中的模型
测试模型还是使用detect.py文件,首先要更改使用的权重文件,把原来的yolov5s.pt更改为刚刚训练保存的last.pt或者best.pt文件。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='last.pt', help='model.pt path(s)')
更改之后可以使用跟之前一样的命令来测试。保存结果的目录和之前一样。
python detect.py --source 0