阻塞队列(BlockingQueue)的实现和使用
阻塞队列(BlockingQueue)
文章目录
- 阻塞队列(BlockingQueue)
-
- 阻塞队列的梗概
-
- 解耦合和削峰填谷
- java代码实现一个阻塞队列
阻塞队列的梗概
众所周知,队列是一种数据结构,符合先进先出的结构,先进先出就是指先到达队列的元素最先出队列。队列对数据的操作一般有三种:入队列,出队列,获取队首元素。而这里的阻塞队列只有两种操作:入队列,出队列,一般是不需要获取队首元素的。阻塞队列是可以用于存放线程,因为阻塞队列可以对线程安全进行一种保护策略,当一个在队列中取一个线程时,如果阻塞队列中无线程,则会陷入等待状态,也就是阻塞,同样的,当队列空间满了之后,想要再加入线程,也会进入等待状态。无线程只有当加入线程才会解开无线程的阻塞,也就是解锁,线程满时只有当线程出队列才会解锁。
阻塞队列对多线程进行数据交互,非常友好。与队列相同,阻塞队列只是增加了阻塞特性,把查看队首元素功能去除,因为对于阻塞队列该功能用处不大。
使用官方的阻塞队列:
//这里的BlockingQueue是一个接口类型的类,不能直接new,所有可以new实现类,向下转型
//BlockingQueue主要有两个实现类(读者请根据需求创建)
//1.数组实现类
//2.链表实现类
BlockingQueue<String> queue = new ArrayBlockingQueue<>(10);
BlockingQueue<Integer> queue1 = new LinkedBlockingDeque<>();
注意这里对数组实现类必须指定大小,该实现类中只有三个构造方法。
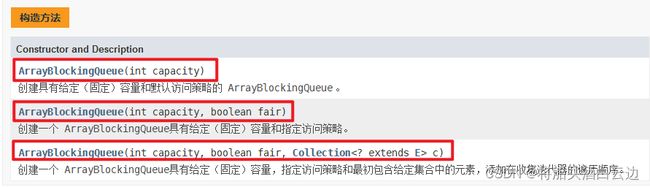
这里演示一个生产者消费者模型更有助于理解:
//阻塞出队列时队列为空时
public class ThreadDomeTest {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<Integer> queue = new ArrayBlockingQueue(10);
Thread t1 = new Thread(()->{
//取出元素
while (true){
try {
int value = queue.take();
System.out.println("消费"+value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread t2 = new Thread(()->{
int value = 0;
//输入数据
while(true){
System.out.println("生产"+(++value));
try {
queue.put(value);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
t2.start();
}
}
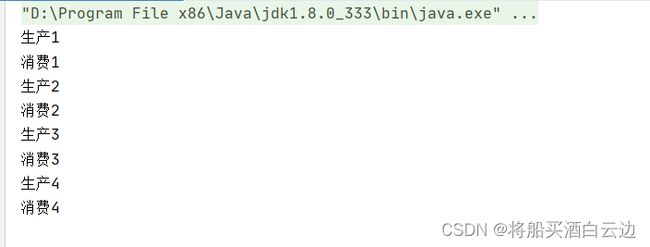
可以看见两个模块之间一个线程进行生产,一个线程进行消费,进程正常运行。
这里演示一个基于消费者模型,进入(入队列不过队列已经满)情况的阻塞状态,更有助于理解:
public static void main(String[] args) throws InterruptedException {
//这里将阻塞队列默认大小设置为10
BlockingQueue<Integer> queue = new ArrayBlockingQueue(10);
Thread t1 = new Thread(()->{
//取出元素
//这里我将出队列的循环语句注释,表示可以出,但是只出一个
// while (true){
try {
int value = queue.take();
System.out.println("消费"+value);
} catch (InterruptedException e) {
e.printStackTrace();
// }
}
});
Thread t2 = new Thread(()->{
int value = 0;
//输入数据
while(true){
System.out.println("生产"+(++value));
try {
queue.put(value);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
t2.start();
}

阻塞队列主要解决两部分的问题:
- 可以让上下两部分的模块实现更好的“解耦合”
- 削峰填谷
解耦合和削峰填谷
这里消费者和生产者是两个不同的个体,也就是上下的两部分,我们常说的“高内聚低耦合”,高内聚是指代码的分布比较均匀,一个功能的代码就聚合在一起,使得程序员想修改一段代码时,可以轻易找到,也就是指关联代码分门别类的规制起来。低耦合是两个不同模块代码的相互影响程度,主要是想将两段代码的影响程度降低,也就是两个模块的关联关系的强弱之分。
削峰填谷是当一个任务量足够大的时候会出现一个任务波峰,而另一个与其关联的代码段并不知道对方出现了任务波峰。而当该任务空间足够大时,就可以将其波峰降低。
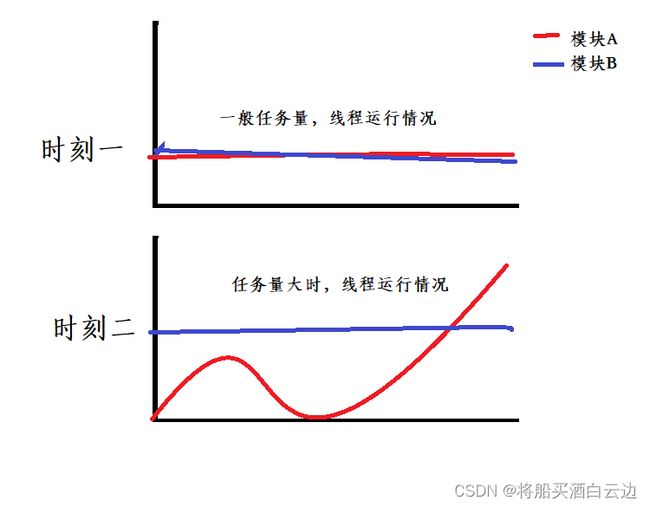
要满足上图,需要在满足阻塞队列的前提下,扩展更多功能,使得其变成单独服务器,一般要使得上图顺利进行,可以选择扩充阻塞队列的大小,也可以增加一个额外的中转站,相当于模块A中任务要经过C中转站进入到B线程中,A和B在不知道对方存在的情况下交换数据,进一步的保障了线程安全,也提高了处理任务的效率。
分析削峰填谷,主要是针对上图时刻二时,在爆发式变高的峰值中两个模块会互相影响,在B模块模块中如果没有设置请求峰值处理机制或是B模块资源不足情况下,程序可能会崩溃!!如果在模块A与B中加入服务器模块,则由服务器承担A模块中的任务压力,B模块按正常速度运行即可,削峰就是如此。填谷是指,当业务在减少前有一波波峰在前,B模块依旧可以以平稳的效果处理业务。(相当于水利工程——三峡大坝,在雨水充足时,挡住水对农田的冲击,在干旱时,适当放低坝的高度)
java代码实现一个阻塞队列
我们知道阻塞队列是一个相当于队列的数据结构,主要与队列不同的地方就是可以产生阻塞。
实现一个阻塞队列主要分为3步:
- 实现一个普通队列
- 加上线程安全
- 实现阻塞功能
这里我用数组来表示阻塞队列,如果读者想用其他方法,欢迎交流。
public class blockQueue01 {
private int[] array= new int[1000];//数组的总大小
private int usesize;//使用了的大小
private int input;//输入的下标
private int output;//输出的下标
//输入队列方法,直接对方法进行加锁操作
synchronized public void put( int val) throws InterruptedException {
if(isFull()){
this.wait();
}
array[input]=val;
input++;
usesize++;
//判断是否越界
if(input == array.length){
input=0;
}
this.notify();
}
//判断队列是否满
private boolean isFull(){
return usesize==array.length;
}
//输出队列方法
synchronized public int take() throws InterruptedException {
if(isEmpty()){
this.wait();
}
int value = array[output];
output++;
//判断是否越界
if(output == array.length){
output = 0;
}
usesize--;
this.notify();
return value;
}
}
使用自己创建的阻塞队列写一个生产者消费者模型:
class Test{
public static void main(String[] args) throws InterruptedException {
blockQueue01 queue = new blockQueue01();
Thread t1 = new Thread(()->{
//取出元素
while (true){
try {
int value = queue.take();
System.out.println("消费"+value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread t2 = new Thread(()->{
int value = 0;
//输入数据
while(true){
System.out.println("生产"+(++value));
try {
queue.put(value);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
t2.start();
}
}
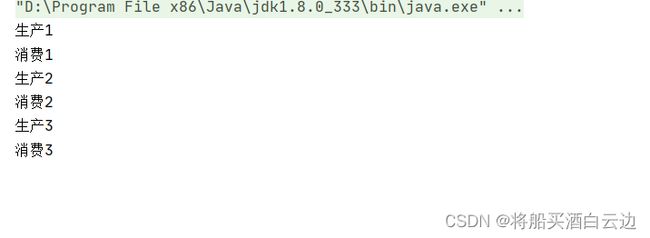
可以正常使用,这里我们主要讲解了阻塞队列的实现以及使用,和阻塞队列与普通队列的区别,还有阻塞队列的线程安全问题。这里提出一个小建议,在Java官方中不建议在if中使用wait方法,可能会因为系统随机调度而中断notify的使用,使得wait无法获得唤醒也就会导致死等的存在。
如果还有其他想法的小伙伴欢迎交流(。・∀・)ノ。