leetcode-数据结构类型的题
剑指offer https://sbaban.com/jzomulu.html
综合型
1.lru缓存 哈希+双向链表

力扣
题目描述

为什么要用双向链表:
因为get的时候,有一个把节点移动到头部的操作。要把节点拿出来,然后把节点的前后连接起来。双向链表有这个功能。
为什么要用哈希表:
查找的时间复杂度是o(1)
思路:
首先考虑put,put是把node(key,value)放到字典里。简洁的想法是,直接把node插入到双向链表的头节点,连接head和node。但是有两种特殊情况,1是node本来就存在于字典中的,不管node在哪里,都要删掉,然后重新插入,这样比较方便。2是node没在字典中,字典的容量已经达到了最大值,要删掉尾部的节点。删掉的过程是,先找到尾部节点,然后重新连接双向链表,把node从字典中删掉。
然后考虑get,get是返回key,并且把node移动到双向链表的头节点。插入到头部节点包括两个部分,1是连接node出去的箭头,2是连接指向node的箭头。
class listnode(object):
def __init__(self,key=None,value=None):
self.key=key
self.value=value
self.pre=None
self.next=None
class LRUCache(object):
def __init__(self, capacity):
"""
:type capacity: int
"""
self.capacity=capacity
self.keyvalue= dict()
self.head = listnode()
self.tail = listnode()
#连接起来
self.head.next=self.tail
self.tail.pre=self.head
def get(self, key):
"""
:type key: int
:rtype: int
"""
#如果在字典中,移动到双向链表的头部
if key in self.keyvalue:
node=self.keyvalue[key]
#连接原节点左右
node.pre.next = node.next
node.next.pre = node.pre
#插入到头节点
node.pre = self.head
node.next = self.head.next
self.head.next.pre = node
self.head.next = node
res = self.keyvalue.get(key, -1)
if res == -1:
return res
else:
return res.value
def put(self, key, value):
"""
:type key: int
:type value: int
:rtype: None
"""
node=listnode(key,value)
#如果字典容量超过了限制,先删除尾部节点
if key not in self.keyvalue and len(self.keyvalue) == self.capacity:
lastnode=self.tail.pre
#连接尾部节点的前后
lastnode.pre.next=self.tail
self.tail.pre = lastnode.pre
#在字典中删掉
self.keyvalue.pop(lastnode.key)
#如果在字典中,先删掉
if key in self.keyvalue:
oldnode=self.keyvalue[key]
#连接节点前后
oldnode.pre.next=oldnode.next
oldnode.next.pre=oldnode.pre
#插入
self.keyvalue[key]=node
#插入头部节点
node.pre=self.head
node.next=self.head.next
self.head.next.pre=node
self.head.next=node432 全o(1)的数据结构
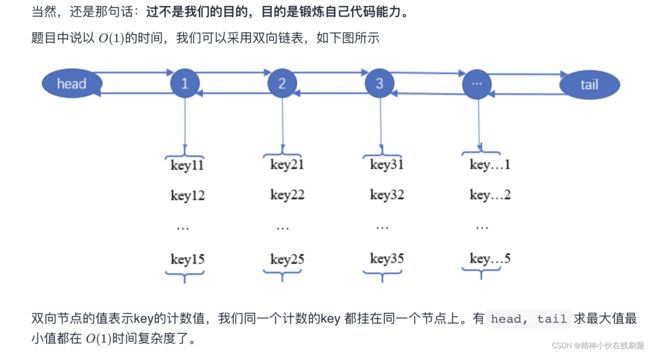
分类讨论:
key加一的时候:
当key在keycount字典中,说明key出现过,取出之前的节点,在之前的节点上把key去掉,然后把key加到count+1节点上,count+1节点分为出现过和没出现过2种情况,
当count+1节点出现过,取出count+1节点,在keyset中加上key。当count+1节点没出现过,创建一个node,然后把这个node加到count节点后面。
最后要判断count节点去掉key之后,keyset是不是空,如果是空需要remove掉。
key减一的时候:
当key在keycount字典中,说明key出现过,取出之前的节点。判断count是不是1,如果是1的话,直接在keyset里删除。如果不是1的话,当count-1节点出现过,取出count-1节点,在keyset中加上key。当count-1节点没出现过,创建一个node,然后把这个node加到count节点前面。
所以,key加一和key减一,count+1节点和,count-1节点的添加元素是可以合并代码的。
# 定义双向节点
class Node:
def __init__(self, cnt):
self.cnt = cnt
# 记录该cnt(计数)下key包括哪些?
self.keySet = set()
# 前后指针
self.prev = None
self.next = None
class AllOne:
def __init__(self):
"""
Initialize your data structure here.
"""
# 记录头尾 便于求最小值最大值
self.head = Node(float("-inf"))
self.tail = Node(float("inf"))
# 首尾相连
self.head.next = self.tail
self.tail.prev = self.head
# 个数对应的节点
self.cntKey = {}
# key 对应的个数
self.keyCnt = {}
def inc(self, key: str) -> None:
"""
Inserts a new key with value 1. Or increments an existing key by 1.
"""
if key in self.keyCnt:
self.changeKey(key, 1)
else:
self.keyCnt[key] = 1
# 说明没有计数为1的节点,在self.head后面加入
if self.head.next.cnt != 1:
self.addNodeAfter(Node(1), self.head)
self.head.next.keySet.add(key)
self.cntKey[1] = self.head.next
def dec(self, key: str) -> None:
"""
Decrements an existing key by 1. If Key's value is 1, remove it from the data structure.
"""
if key in self.keyCnt:
cnt = self.keyCnt[key]
if cnt == 1:
self.keyCnt.pop(key)
self.removeFromNode(self.cntKey[cnt], key)
else:
self.changeKey(key, -1)
def getMaxKey(self) -> str:
"""
Returns one of the keys with maximal value.
"""
return "" if self.tail.prev == self.head else next(iter(self.tail.prev.keySet))
def getMinKey(self) -> str:
"""
Returns one of the keys with Minimal value.
"""
return "" if self.head.next == self.tail else next(iter(self.head.next.keySet))
# key加1或者减1
def changeKey(self, key, offset):
cnt = self.keyCnt[key]
self.keyCnt[key] = cnt + offset
curNode = self.cntKey[cnt]
newNode = None
if cnt + offset in self.cntKey:
newNode = self.cntKey[cnt + offset]
else:
newNode = Node(cnt + offset)
self.cntKey[cnt + offset] = newNode
self.addNodeAfter(newNode, curNode if offset == 1 else curNode.prev)
#要放在最后,不如有可能curnode被remove了。
newNode.keySet.add(key)
self.removeFromNode(curNode, key)
# 在prevNode后面加入newNode
def addNodeAfter(self, newNode, prevNode):
newNode.prev = prevNode
newNode.next = prevNode.next
prevNode.next.prev = newNode
prevNode.next = newNode
# 在curNode删除key
def removeFromNode(self, curNode, key):
curNode.keySet.remove(key)
if len(curNode.keySet) == 0:
self.removeNodeFromList(curNode)
self.cntKey.pop(curNode.cnt)
# 删掉curNode节点
def removeNodeFromList(self, curNode):
curNode.prev.next = curNode.next
curNode.next.prev = curNode.prev
curNode.next = None
curNode.prev = None
作者:powcai
链接:https://leetcode-cn.com/problems/all-oone-data-structure/solution/python-shuang-xiang-lian-biao-map-by-powcai/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 class Node:
def __init__(self,count):
self.count=count
self.keyset=set()
self.pre=None
self.nexts=None
class AllOne:
def __init__(self):
self.head=Node(float("-inf"))
self.tail=Node(float("inf"))
self.head.nexts=self.tail
self.tail.pre=self.head
self.keycount={}
self.countkey={}
def inc(self, key: str) -> None:
#如果key出现过
if key in self.keycount:
self.changekey(key,1)
else:
self.keycount[key]=1
# 说明没有计数为1的节点,在self.head后面加入
if self.head.nexts.count != 1:
newnode=Node(1)
self.head.nexts.pre=newnode
newnode.nexts=self.head.nexts
self.head.nexts=newnode
newnode.pre=self.head
self.head.nexts.keyset.add(key)
self.countkey[1] = self.head.nexts
def dec(self, key: str) -> None:
if key in self.keycount:
count = self.keycount[key]
if count == 1:
self.keycount.pop(key)
curnode=self.countkey[1]
curnode.keyset.remove(key)
if len(curnode.keyset)==0:
self.countkey.pop(count)
curnode.pre.nexts=curnode.nexts
curnode.nexts.pre=curnode.pre
curnode.pre=None
curnode.nexts=None
else:
self.changekey(key, -1)
def getMaxKey(self) -> str:
return "" if self.tail.pre == self.head else next(iter(self.tail.pre.keyset))
def getMinKey(self) -> str:
return "" if self.head.nexts == self.tail else next(iter(self.head.nexts.keyset))
def changekey(self,key,offset):
count=self.keycount[key]
self.keycount[key]=count+offset
curnode=self.countkey[count]
newnode=None
if count+offset in self.countkey:
newnode=self.countkey[count+offset]
else:
newnode=Node(count+offset)
self.countkey[count+offset]=newnode
# self.addNodeAfter(newnode, curnode if offset == 1 else curnode.pre)
# #连接
if offset==1:
#newnode连接到curnode后面
curnode.nexts.pre=newnode
newnode.nexts=curnode.nexts
curnode.nexts=newnode
newnode.pre=curnode
if offset==-1:
#newnode连接到curnode.pre后面
curnode.pre.nexts=newnode
newnode.pre=curnode.pre
curnode.pre=newnode
newnode.nexts=curnode
#newnode添加key
newnode.keyset.add(key)
#curnode删除key,如果删除之后为空,去掉curnode
curnode.keyset.remove(key)
if len(curnode.keyset)==0:
#记得在self.countkey里删掉
self.countkey.pop(count)
curnode.pre.nexts=curnode.nexts
curnode.nexts.pre=curnode.pre
curnode.pre=None
curnode.nexts=None
# 在prevNode后面加入newNode
# def addNodeAfter(self, newNode, prevNode):
# newNode.pre = prevNode
# newNode.nexts = prevNode.nexts
# prevNode.nexts.pre = newNode
# prevNode.nexts = newNode
# Your AllOne object will be instantiated and called as such:
# obj = AllOne()
# obj.inc(key)
# obj.dec(key)
# param_3 = obj.getMaxKey()
# param_4 = obj.getMinKey()380 o(1)时间复杂度插入/删除和获取随机元素
random.randint时间复杂度是o(1)

哈希表/列表的时间复杂度_林冲风雪山神庙的博客-CSDN博客
力扣

class RandomizedSet:
# 用哈希表来实现o(1)时间复杂度的插入和删除,用列表的索引查找来实现getRandom
# 列表里存储的是val,难点在于删除的时候,不做处理的话,列表删除源元素时间复杂度是o(n),
# 可以把要删除的元素交换到列表末尾,pop()末尾的元素时间复杂度是o(1)
def __init__(self):
self.maps = {}
self.nums = []
def insert(self, val: int) -> bool:
if val in self.maps:
return False
self.maps[val] = len(self.nums)
self.nums.append(val)
return True
def remove(self, val: int) -> bool:
if val not in self.maps:
return False
index = self.maps[val]
last_index = len(self.nums) - 1
last_value = self.nums[-1]
self.maps[last_value] = index
if index != last_index:
self.nums[index], self.nums[last_index] = self.nums[last_index], self.nums[index]
self.nums.pop()
del self.maps[val]
return True
def getRandom(self) -> int:
random_index = random.randint(0, len(self.nums) - 1)
return self.nums[random_index]字典树
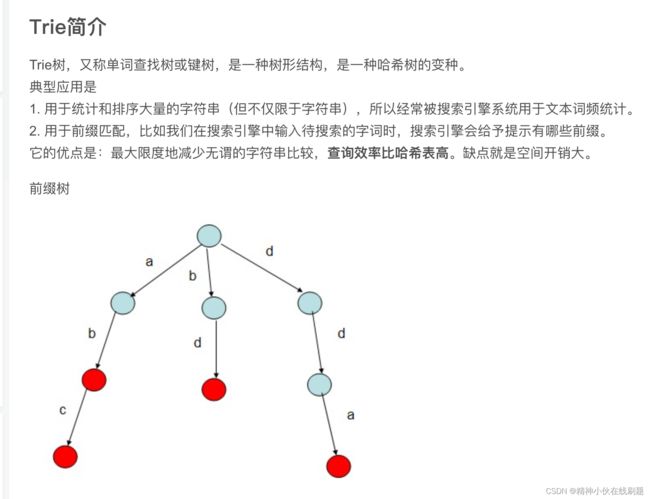
leetcode 208.实现Trie(前缀树) python 字典树模板_xxx_gt的博客-CSDN博客
思路:用字典嵌套的形式,一个单词是一个字典嵌套。比如单词“apple",insert之后是这种形式:
![]()
再插入新的单词时,如果前缀有重复的,就跳过,如果没有重复的再插入。比如在apple之后,插入als:

插入cls:

首先考虑插入(insert),对单词遍历,用cur=cur[w]在嵌套字典中遍历。最后用一个#号表示结束。
然后考虑search,用cur来对嵌套字典遍历,最后遍历到#号,说明这个单词是存在的。
考虑startwith,也是用cur来对嵌套字典遍历,如果最后len(cur)不为0,说明有这个前缀。
class Trie(object):
def __init__(self):
"""
Initialize your data structure here.
"""
#字典嵌套
#key是当前层的字母,value是下一层的字母
self.trie = {}
def insert(self, word):
"""
Inserts a word into the trie.
:type word: str
:rtype: None
"""
#插入一个单词,例如是apply
cur=self.trie
for w in word:
if w not in cur:
#当前字母的value是一个字典,这个字典的值是下一个字母决定的
cur[w]={}
cur=cur[w]
#遍历完了字典之后,,最后一个字母的value是一个空字典
#这个空字典的key和value定义为#
cur["#"]="#"
def search(self, word):
"""
Returns if the word is in the trie.
:type word: str
:rtype: bool
"""
curr = self.trie
for w in word:
if w not in curr.keys():
return False
curr = curr[w]
return '#' in curr.keys()
def startsWith(self, prefix):
"""
Returns if there is any word in the trie that starts with the given prefix.
:type prefix: str
:rtype: bool
"""
curr = self.trie
for w in prefix:
if w not in curr.keys():
return False
curr = curr[w]
return len(curr)!=0
{"a": {"p": {"p": {"l": {"e": {"#": "#"}}}}}}字典树的应用:421. 数组中两个数的最大异或值
异或性质贪心+二叉前缀树

力扣
力扣
建了二叉前缀树之后,进行搜索。
从根节点开始遍历当前值。根据贪心的思想,找和当前值不一样的二进制值。比如当前值是1,就找0,当前值是0,就找1。当前值和前缀树上的值进行异或,结果在这个位置上肯定是1(因为1和0异或结果是1)
if index==0:
if cur_node.right:
#结果加上这个值
cur_res |= (1 << i)
cur_node=cur_node.right
else:
cur_node=cur_node.left
if index==1:
if cur_node.left:
# 结果加上这个值
cur_res |= (1 << i)
cur_node = cur_node.left
else:
cur_node = cur_node.right
————————————————
版权声明:本文为CSDN博主「林冲风雪山神庙」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/MaYingColdPlay/article/details/108161212class TreeNode:
def __init__(self,value,left=None,right=None):
self.value = value
self.left = left
self.right = right
class Solution:
def findMaximumXOR(self, nums):
#建树,0在左子树,1在右子树
root=TreeNode(-1)
for num in nums:
#每个数字都从根结点开始往下遍历
cur_node=root
# 取出num中第i + 1位的状态
for i in range(31,-1,-1):
index = (num >> i) & 1
if index==0:
if not cur_node.left:
cur_node.left=TreeNode(0)
cur_node=cur_node.left
if index==1:
if not cur_node.right:
cur_node.right=TreeNode(1)
cur_node=cur_node.right
#查询
res=0
for num in nums:
cur_node=root
cur_res=0
for i in range(31,-1,-1):
index = (num >> i) & 1
if index==0:
if cur_node.right:
#结果加上这个值
cur_res |= (1 << i)
cur_node=cur_node.right
else:
cur_node=cur_node.left
if index==1:
if cur_node.left:
# 结果加上这个值
cur_res |= (1 << i)
cur_node = cur_node.left
else:
cur_node = cur_node.right
res=max(res,cur_res)
return res6018. 根据描述创建二叉树
看一下lru: lru也是用哈希表来存储,key是节点值,value是节点node

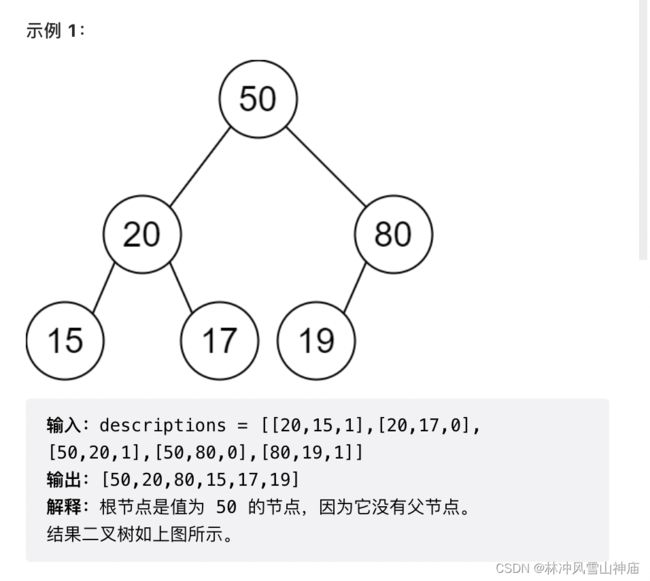
用哈希表记录以node为根节点,对应的节点值。为了找整个树的根用。
for k in node.keys():
if k not in c:
return node[k]
if x == 1:
ns.left = ne
else:
ns.right = ne
会改变原哈希表的值
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def createBinaryTree(self, descriptions: List[List[int]]) -> Optional[TreeNode]:
def f(i):
s, e, x = descriptions[i]
c[e] = c.get(e, 0) + 1
if s not in node:
ns = TreeNode(s)
node[s] = ns
else:
ns = node[s]
if e not in node:
ne = TreeNode(e)
node[e] = ne
else:
ne = node[e]
if x == 1:
ns.left = ne
else:
ns.right = ne
node = {}
c = {}
for i in range(len(descriptions)):
f(i)
for k in node.keys():
if k not in c:
return node[k]
作者:qin-qi-shu-hua-2
链接:https://leetcode-cn.com/problems/create-binary-tree-from-descriptions/solution/python-ha-xi-by-qin-qi-shu-hua-2-b768/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。427 建立四叉树


注意边界条件
先求出来行和列的距离
dx = c - a + 1
dy = d - b + 1
黄色的,行坐标是 a+dx/2 - 1,注意要减去1,因为是往里面缩一位的
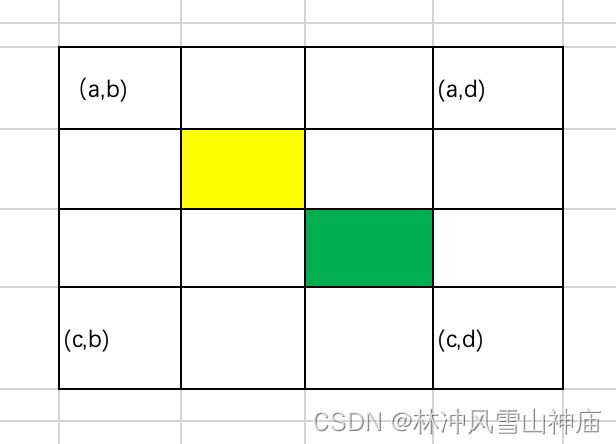
class Node:
def __init__(self, val, isLeaf, topLeft, topRight, bottomLeft, bottomRight):
self.val = val
self.isLeaf = isLeaf
self.topLeft = topLeft
self.topRight = topRight
self.bottomLeft = bottomLeft
self.bottomRight = bottomRight
class Solution:
def construct(self, grid: List[List[int]]) -> 'Node':
def dfs(a, b, c, d):
ok = True
t = grid[a][b]
for i in range(a, c + 1):
for j in range(b, d + 1):
if grid[i][j] != t:
ok = False
if ok:
return Node(t == 1, True)
root = Node(t == 1, False)
dx = c - a + 1
dy = d - b + 1
root.topLeft = dfs(a, b, a + dx // 2 - 1, b + dy // 2 - 1)
root.topRight = dfs(a, b + dy // 2, a + dx // 2 - 1, d)
root.bottomLeft = dfs(a + dx // 2, b, c, b + dy // 2 - 1)
root.bottomRight = dfs(a + dx // 2, b + dy // 2, c, d)
return root
return dfs(0, 0, len(grid) - 1, len(grid) - 1)sortedlist
6130. 设计数字容器系统

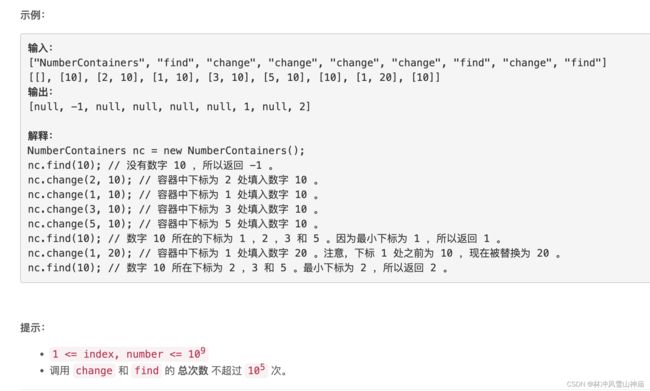
超时写法
import collections
class NumberContainers(object):
def __init__(self):
self.map1 = collections.defaultdict(dict)
self.map2 = {}
def change(self, index, number):
"""
:type index: int
:type number: int
:rtype: None
"""
if index in self.map2:
pre_num = self.map2[index]
self.map2[index] = number
#删掉以前的数字
pre_num_indexs = self.map1[pre_num]
del pre_num_indexs[index]
#加上现在的
self.map1[number][index]=0
else:
# 加上现在的
self.map1[number][index]=0
self.map2[index] = number
def find(self, number):
"""
:type number: int
:rtype: int
"""
if number in self.map1 and len(self.map1[number]) > 0:
indexs = self.map1[number]
alist = sorted(indexs.keys())
return alist[0]
return -1
obj = NumberContainers()
obj.change(2,10)
obj.change(1,10)
obj.change(3,10)
obj.change(1,20)from sortedcontainers import SortedList
class NumberContainers:
def __init__(self):
self.lst = {}
self.d = {}
def change(self, index: int, number: int) -> None:
if index in self.lst:
self.d[self.lst[index]].remove(index)
self.lst[index] = number
if number not in self.d:
self.d[number] = SortedList()
self.d[number].add(index)
def find(self, number: int) -> int:
if number in self.d and len(self.d[number]) > 0:
return self.d[number][0]
return -1
作者:小羊肖恩
链接:https://leetcode.cn/circle/discuss/6jXNsy/view/fAD43m/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。6126. 设计食物评分系统

我的错误的解法
import collections
from sortedcontainers import SortedList
class FoodRatings(object):
def __init__(self, foods, cuisines, ratings):
"""
:type foods: List[str]
:type cuisines: List[str]
:type ratings: List[int]
"""
# cate = SortedList()
self.food_cate = {}
self.cate_food = collections.defaultdict(list)
self.food_rating = {}
self.cate = {}
self.rating_food = collections.defaultdict(list)
self.rating_cate = collections.defaultdict(list)
for i in range(len(foods)):
cur_cate = cuisines[i]
if cur_cate not in self.cate:
self.cate[cur_cate] = SortedList()
if ratings[i] not in self.cate[cur_cate]:
self.cate[cur_cate].add(ratings[i])
self.rating_cate[ratings[i]].append(cur_cate)
self.rating_food[ratings[i]].append(foods[i])
self.food_cate[foods[i]] = cur_cate
self.food_rating[foods[i]] = ratings[i]
self.cate_food[cur_cate].append(foods[i])
def changeRating(self, food, newRating):
"""
:type food: str
:type newRating: int
:rtype: None
"""
old_rating = self.food_rating[food]
this_cate = self.food_cate[food]
old_rating_food_list = self.rating_food[old_rating]
old_rating_cate_list = self.rating_cate[old_rating]
old_rating_food_index = old_rating_food_list.index(food)
del old_rating_cate_list[old_rating_food_index]
del old_rating_food_list[old_rating_food_index]
#这里考虑的有问题。如果当前类别下,还有其他食物的评分是old rating,也不删除
# del_cate_rating_flag = True
# for i in range(len(old_rating_cate_list)):
# if old_rating_cate_list[i] == this_cate:
# del_cate_rating_flag = False
# break
# if del_cate_rating_flag:
# self.cate[this_cate].remove(old_rating)
del_cate_rating_flag = True
# for i in range(len(old_rating_cate_list)):
# if old_rating_cate_list[i] == this_cate:
# del_cate_rating_flag = False
# break
#当前类别下的食物
other_foods = self.cate_food[this_cate]
for other_food in other_foods:
if other_food != food:
if self.food_rating[other_food] == old_rating:
del_cate_rating_flag = False
break
if del_cate_rating_flag:
self.cate[this_cate].remove(old_rating)
#更新新的分数
if newRating not in self.cate[this_cate]:
self.cate[this_cate].add(newRating)
self.rating_food[newRating].append(food)
self.rating_cate[newRating].append(this_cate)
self.food_rating[food] = newRating
# #是否在类别分数字典里删掉这个分数
# del_cate_flag = True
# if len(old_rating_cate_foods) > 1:
# del_cate_flag = False
# old_rating_cate_foods.remove(food)
def highestRated(self, cuisine):
"""
:type cuisine: str
:rtype: str
"""
high_score = self.cate[cuisine][-1]
foods = self.rating_food[high_score]
tmp = []
for food in foods:
if self.food_cate[food] == cuisine:
tmp.append(food)
tmp.sort()
return tmp[0]字典排序
按照value排序
alist = sorted(maps2.items(),key = lambda x:x[1],reverse=False)
按照key排序
alist = sorted(maps2.items(),key = lambda x:x[0],reverse=False)
from sortedcontainers import SortedList
class FoodRatings:
def __init__(self, foods: List[str], cuisines: List[str], ratings: List[int]):
self.map1 = dict() # 记录 food: [cuisine, rating]
self.map2 = dict() # 记录 cuisine: [[-rating1, food1], [-rating2, food2], ...]
# 注:rating前负号的存在,使得第一条记录即为cuisine对应的最大评分且字典序较小的食物
for food, cuisine, rating in zip(foods, cuisines, ratings):
self.map1[food] = [cuisine, rating]
if cuisine not in self.map2:
self.map2[cuisine] = SortedList()
self.map2[cuisine].add([-rating, food])
def changeRating(self, food: str, newRating: int) -> None:
cuisine, rating = self.map1[food] # food对应的cuisine和原评分rating
if rating == newRating: # 新老评分一样,无需更新
return
self.map1[food] = [cuisine, newRating] # 更新food对应的评分为newRating
self.map2[cuisine].remove([-rating, food]) # 删除老记录
self.map2[cuisine].add([-newRating, food]) # 添加新记录
def highestRated(self, cuisine: str) -> str:
return self.map2[cuisine][0][1]