PySpark基础之算子
文章目录
- 1. 简介
-
- 1.1 什么是算子?
- 1.2 算子分类
- 2. 常用的Transformation算子
-
- 2.1 key类型算子
- 2.2 Key-Value类型算子
- 2.3 分区设置算子
- 2.4 分区操作算子
- 3. 常用的Action算子
-
- 3.1 Key 类型算子
- 3.2 Key-Value类型算子
- 3.3 分区操作算子
1. 简介
1.1 什么是算子?
分布式集合对象(RDD)的API称为算子,本地对象的API,叫做方法或函数;但是分布式对象的API就叫做算子。
1.2 算子分类
RDD的算子分成2类:Transformation转换算子,Action动作算子
Transformation算子:
RDD的算子,返回值仍然是一个RDD,称之为转换算子。这类算子是lazy 懒加载的,如果没有Action算子,Transformation算子是不工作的。
Action算子:
返回值不是rdd的就是action算子

对于这两类算子来说,Transformation算子,相当于在构建执行计划,action算子是一个指令让这个执行计划开始工作。如果没有action和transformation算子之间的迭代关系,就是一个没有通电的流水线。只有action到来,这个数据处理的流水线才开始工作。
2. 常用的Transformation算子
import pyspark
from pyspark import SparkContext, SparkConf
import findspark
findspark.init()
conf = SparkConf().setAppName('test').setMaster('local[*]')
sc = SparkContext(conf=conf)
2.1 key类型算子
map算子:将RDD的数据一条条处理(处理的逻辑基于map算子中接收的处理函数),返回新的RDD
rdd = sc.parallelize(range(10))
rdd.collect()
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 对每个元素映射一个函数操作,如求平方
rdd.map(lambda x: x**2).collect()
# [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
flatMap:对rdd执行map操作,然后进行解除嵌套操作

rdd = sc.parallelize(["hello world", "hello python"])
rdd.collect()
# flat展平
# ['hello world', 'hello python']
# 先以空格拆分为二维结构
rdd.map(lambda x: x.split(" ")).collect()
# [['hello', 'world'], ['hello', 'python']]
# 对每个元素映射一个函数操作
# 并将结果数据进行扁平化(展平)
rdd.flatMap(lambda x: x.split(" ")).collect()
# ['hello', 'world', 'hello', 'python']
filter:过滤想要的数据进行保留,返回是True的数据被保留,False的数据被丢弃
# 筛选数据,如筛选大于5的元素
rdd.filter(lambda x: x > 5).collect()
# [6, 7, 8, 9]
distinct:对RDD数据进行去重,返回新的RDD
rdd = sc.parallelize([1, 1, 2, 2, 3, 3, 4, 5])
# 去重
rdd.distinct().collect()
# [4, 1, 5, 2, 3]
union:2个rdd合并成1个rdd返回,只是合并,不会去重,不同类型的rdd依旧可以合并
# 并集,a+b
a.union(b).collect()
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
intersection:求2个rdd的交集,返回一个新的rdd
# 交集
a.intersection(b).collect()
# [8, 9, 5, 6, 7]
sortBy:对RDD数据进行排序,基于指定的排序依据
rdd = sc.parallelize([(1, 2, 3), (3, 2, 2), (4, 1, 1)])
# 按第3列排序,默认升序
rdd.sortBy(
keyfunc=lambda x: x[2],
ascending=True
).collect()
# [(4, 1, 1), (3, 2, 2), (1, 2, 3)]
2.2 Key-Value类型算子
reduceByKey:自动按照key分组,然后根据提供的聚合逻辑,完成组内数据(value)的聚合操作
聚合逻辑:
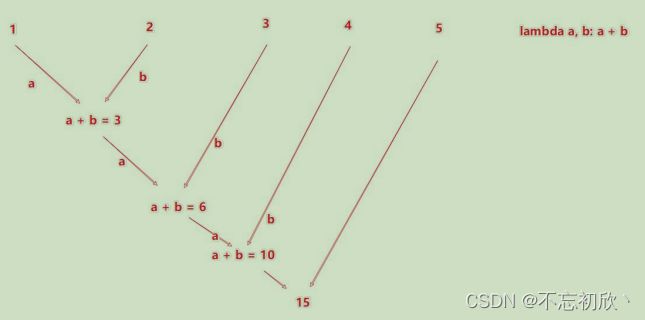
rdd.collect()
# [('python', 1), ('python', 2), ('pandas', 3), ('pandas', 4)]
# 以key分组对value执行二元归并操作,比如求和
rdd.reduceByKey(lambda x, y: x+y).collect()
# [('python', 3), ('pandas', 7)]
groupBy:将rdd的数据进行分组
rdd = sc.parallelize(range(10))
# 将RDD转换为迭代器
iterator = rdd.toLocalIterator()
type(iterator)
# generator
# groupBy:以函数返回值分组合并,合并后返回迭代器
# 如奇数为一个迭代器,偶数为一个迭代器
rdd_new = rdd.groupBy(lambda x: x % 2).collect()
rdd_new
'''
[(0, ),
(1, )]
'''
[[x, list(y)] for x, y in rdd_new]
# [[0, [0, 2, 4, 6, 8]], [1, [1, 3, 5, 7, 9]]]
groupByKey:自动按照key分组
rdd = sc.parallelize(
[("python", 1),
("python", 2),
("pandas", 3),
("pandas", 4)])
# 以key分组合并value,合并后返回迭代器
rdd_new = rdd.groupByKey().collect()
[[x, list(y)] for x, y in rdd_new]
# [['python', [1, 2]], ['pandas', [3, 4]]]
join:对两个rdd执行join操作,可以实现SQL的内外连接,join算子只能用于二元元组
- join:内连接
- leftOuterJoin:左连接
- rightOuterJoin:右连接
age = sc.parallelize(
[("jack", 20),
("rose", 18),
("tony", 20)])
gender = sc.parallelize(
[("jack", "male"),
("rose", "female"),
("tom", "male")])
# 按key内连接
age.join(gender).collect()
# [('jack', (20, 'male')), ('rose', (18, 'female'))]
sortByKey:按照key进行排序
rdd = sc.parallelize(
[("python", 1),
("python", 2),
("pandas", 3),
("pandas", 4)])
# 按key排序
rdd.sortByKey().collect()
# [('pandas', 3), ('pandas', 4), ('python', 1), ('python', 2)]
mapValue:针对二元元组,对其内部的二元元组的Value执行map操作
dd = sc.parallelize(
[("python", [1, 2]),
("pandas", [3, 4])])
# 对value应用一个函数操作,比如求和
rdd.mapValues(sum).collect()
# [('python', 3), ('pandas', 7)]
groupByKey和ReduceByKey的区别
功能上:
- groupByKey仅仅有
分组的功能而已 - reduceByKey除了有ByKey的分组功能外,还有reduce聚合功能,所以是一个
分组+聚合的算子
性能上:如果对数据执行分组+聚合操作,reduceByKey的性能是远大于groupByKey+聚合逻辑的
- 因为groupByKey只能分组,所以在执行上是先分组(shuffle)后聚合
- reduceByKey由于自带聚合逻辑,所以会现在分区内做预聚合,然后再走分组流程,分组后再做最终聚合
对于groupByKey算子,reduceByKey最大的提升在于,分组前进行了预聚合,那么在shuffle分组节点,被shuffle的数据可以极大的减少,提升了性能。因此分组+聚合,首先reduceBykey算子。
2.3 分区设置算子
glom:将RDD的数据,加上嵌套,这个嵌套按照分区来进行
rdd = sc.parallelize(range(10), 2)
rdd.collect()
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 将每个分区的元素转换为列表
rdd.glom().collect()
# [[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
2.4 分区操作算子
mapPartitions:一次被传递的是一整个分区的数据,作为一个迭代器(一次性list)对象传入过来
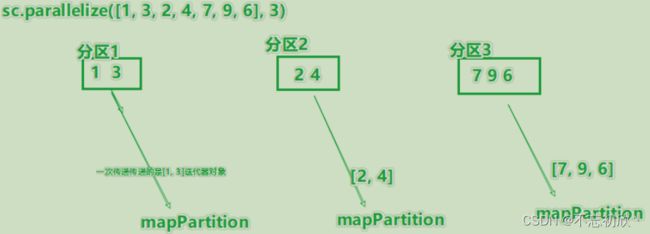
rdd = sc.parallelize(range(10), 2)
# 对每个分区分别应用一个函数,如求和
# 函数必须使用yield关键字(即生成器), 生成器返回迭代器
def func(x): yield sum(x)
rdd.mapPartitions(func).collect()
# [10, 35]
partitionBy:对RDD进行自定义分区操作
# 键值对RDD重置分区数量
rdd2 = sc.parallelize(
[("a", 1),
("a", 2),
("a", 3),
("c", 4)])
# 相同key一定在同一个分区
rdd2.partitionBy(2).glom().collect()
# [[('c', 4)], [('a', 1), ('a', 2), ('a', 3)]]
rdd = sc.parallelize([('hadoop', 1), ('spark', 1), ('hello', 1), ('flink', 1), ('hadoop', 1), ('spark', 1)])
# 使用partitionBy 自定义 分区
def process(k):
if 'hadoop' == k or 'hello' == k: return 0
if 'spark' == k: return 1
return 2
print(rdd.partitionBy(3, process).glom().collect())
repartition:对RDD的分区执行重新分区(仅数量)
一般情况下,写Spark代码除了要求全局排序设置为1个分区外,多数的时候所有API中关于分区相关的代码都不用理会
如果修改了分区数,会影响并行计算(内存迭代的并行管道数量);分区如果增加,极大可能导致shuffle
# 单元素RDD重置分区数量
rdd1 = sc.parallelize(range(10), 3)
# 键值对RDD重置分区数量
rdd2 = sc.parallelize(
[("a", 1),
("a", 2),
("a", 3),
("c", 4)])
# 增加分区数量,实际上调用coalesce(shuffle=True)
# 减少分区数量,实际上调用coalesce(shuffle=False)
rdd1.repartition(4).glom().collect()
# [[6, 7, 8, 9], [3, 4, 5], [], [0, 1, 2]]
# 按key打乱,相同key不一定在同一分区
rdd2.repartition(2).glom().collect()
# [[('a', 1), ('a', 3), ('c', 4)], [('a', 2)]]
coalesce:对分区进行数量增减
# hive: coalesce空值处理
rdd = sc.parallelize(range(10), 3)
rdd.glom().collect()
# [[0, 1, 2], [3, 4, 5], [6, 7, 8, 9]]
# 重置分区数量
# shuffle=True,增加至指定分区数量
# shuffle=False,减少至指定分区数量
rdd_new = rdd.coalesce(2, shuffle=False)
rdd_new.glom().collect()
# [[0, 1, 2], [3, 4, 5, 6, 7, 8, 9]]
3. 常用的Action算子
3.1 Key 类型算子
collect:将RDD各个分区内的数据,统一收集到Driver中,形成一个List对象。RDD是分布式对象,数据量可能很大,所以在用这个算子之前要了解结果数据集不会很大,不然Driver内存会溢出
rdd = sc.parallelize(range(10))
# 查看所有的元素
rdd.collect()
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
reduce:对RDD数据按照传入的逻辑进行聚合
rdd = sc.parallelize(range(10))
# 二元归并操作,如累加
# 逐步对两个元素进⾏操作
rdd.reduce(lambda x, y: x + y)
from operator import add
rdd.reduce(add)
# 45
fold:和reduce一样,接受传入逻辑进行聚合,聚合是带有初始值的,这个初始值聚合,会作用在分区内聚合,分区间聚合。
rdd = sc.parallelize(range(1, 10), 3)
print(rdd.fold(10, lambda a, b: a + b))
# 85
数据分布在3个分区,分区1中123聚合的时候带上10作为初始值得到16;分区2中456聚合的时候带上10作为初始值得到25;分区3中789聚合的时候带上10作为初始值得到34;最后3个分区的结果做聚合也带上初始值10,所以最终的结果就是10+16+25+34=85
first:取出RDD的第一个元素
rdd = sc.parallelize(range(10))
# 获取第1个元素
rdd.first()
# 0
take:取RDD的前N个元素,组合成list返回给你
rdd = sc.parallelize(range(10))
# 查看指定数量的元素
rdd.take(4)
# [0, 1, 2, 3]
top:对RDD数据集进行降序排序,取前N个
rdd = sc.parallelize(range(10))
# 获取top n的元素
rdd.top(3)
# [9, 8, 7]
count:计算RDD有多少条数据,返回值是一个数字
rdd = sc.parallelize(range(10))
# 查看元素数量
rdd.count()
# 10
takeSample:随机抽样RDD的数据,可以设置随机数种子
rdd = sc.parallelize(range(10))
# 随机抽取指定数量的元素
# 第1个参数,是否重复抽样
# 第2个参数,抽样数量
# 第3个参数,随机种子
rdd.takeSample(False, 5, 0)
# [7, 8, 1, 5, 3]
takeOrdered:对RDD进行排序取前N个,可以指定排序规则
rdd = sc.parallelize([10, 7, 6, 9, 4, 3, 5, 2, 1])
# 按指定规则排序后,再抽取指定数量的元素
# 升序后抽取
rdd.takeOrdered(num=5)
# [1, 2, 3, 4, 5]
# 降序后抽取
rdd.takeOrdered(num=5, key=lambda x: -x)
# [10, 9, 7, 6, 5]
foreach:对RDD的每一个元素,执行你提供的逻辑操作(和map一个意思),但是这个方法没有返回值
rdd = sc.parallelize(range(10))
# 对每个元素执行一个函数操作
# accumulator累加器
acc = sc.accumulator(value=0)
rdd.foreach(lambda x: acc.add(x))
acc.value
# 45
saveAsTextFile:将RDD的数据写入文本文件中,支持写入本地、hdfs等文件系统
rdd = sc.parallelize(range(5))
# 保存rdd为text文件到本地
# 如文件已存在, 将报错
rdd.saveAsTextFile("./data/rdd.txt")

saveAstextFile算子是分布式执行的,执行数据不经过driver,写出的时候,每个分区所在的Executor直接控制数据写出到目标文件系统中,所以才会一个分区产生1个结果文件。
3.2 Key-Value类型算子
countByKey:统计key出现的次数,一般适用于kv型RDD
# 以key分组计数,返回字典
rdd.countByKey().items()
# dict_items([('python', 2), ('pandas', 2)])
3.3 分区操作算子
foreachPartition:和普通的foreach一致,但是一次处理的是一整个分区数据。foreachPartition就是一个没有返回值的mapPartition
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 3, 2, 4, 7, 9, 6], 3)
def process(iter):
result = list()
for it in iter:
result.append(it * 10)
print(result)
rdd.foreachPartition(process)
# [10, 30]
# [20, 40]
# [70, 90, 60]
在所有的Action算子中,foreach、saveAsTextFile算子是分区在Executor上直接执行的,跳过了Driver,有分区所在的Executor直接执行,反之其余的Action算子都将会将结果发送到Driver