了解HTTP与B/S架构并熟悉浏览器开发者工具与请求报文和响应报文格式等【非常详细】
作者简介:大学机械本科,野生程序猿,学过C语言,玩过前端,还鼓捣过嵌入式,设计也会一点点,不过如今痴迷于网络爬虫,因此现深耕Python、数据库、seienium、JS逆向、安卓逆向等等,,目前为全职爬虫工程师,学习的过程喜欢记录,目前已经写下15W字电子笔记,因此你看到了下面这篇文章~
技术栈:Python、HTML、CSS、JavaScript、C、Xpath语法、正则、、MySQL、Redis、MongoDB、Scrapy、Pyspider、Fiddler、Mitmproxy、分布式爬虫、JAVA等
个人博客:https://pythonlamb.github.io/
大学作品合集:https://sourl.cn/h9M2jX
欢迎点赞⭐️收藏关注留言呀
登高必自卑,行远必自迩.
我始终坚信越努力越幸运
⭐️ 那些打不倒我们的终将会让我们变得强大
希望在编程道路上深耕的小伙伴都会越来越好
文章目录
-
- HTTP协议概述【重点】
-
- 什么是HTTP协议
- HTTP协议的构成和作用
- 通过浏览器查看HTTP协议【重点】
-
- Edge浏览器查看HTTP协议(请求协议、响应协议)
- HTTP请求协议报文格式【重点】
-
- 一:请求协议的报文格式
- 请求行、请求头、请求空行和请求体的格式与代表的含义及注意事项
- 利用网络调试助手充当TCP网站服务器,在利用浏览器(客户端)对这个服务器进行请求协议
- HTTP响应协议报文格式内容
-
- 响应协议
- 响应协议的报文内容
- 响应协议的响应行的状态码为 404 的含义
- 网络调试助手模拟百度服务器向请求的浏览器发送数据(html)
- 长连接与短连接【重点】
-
- 长连接与短连接
- HTTP请求响应的短连接与长连接的优缺点
- 案例)模拟浏览器(网络调试助手)请求服务器的过程【重点】
-
- 利用代码将网站域名解析为IP地址
- python 编写代码模拟浏览器(客户端)请求百度服务器的流程
- 格式化字符“\r”与“\n”和 "\r\n" 的作用
- 访问网站服务器的固定html文件【重要】
-
- 访问网站服务器上的固定文件
- 字符串的分割——split()
- 案例)编写代码模拟Web服务器
- 终端启动WEB服务器(python代码)【重点】
-
- 在终端中运行 py 文件的两种方法
- sys模块的argv方法
- isdigit()函数的作用
- 在终端中运行特定端口号的 web 服务器(py程序)
- 游戏服务器的部署
-
- 解决利用py代码书写服务器,向服务器内发布html游戏,浏览器不能成功解析html代码的问题
- 类的注意事项
- 字典的keys()以及列表的enumerate()方法
-
- 字典的 keys()函数
- 列表、可迭代对象的 enumerate()函数
HTTP协议概述【重点】
什么是HTTP协议
概念:
HTTP(Hypertext Transfer Protocol)叫超文本传输协议,是互联网上应用最为广泛的网络协议,所有的WWW文件必须遵守这个标准,设计HTTP的目的是提供一种发送和接收HTML页面(网页)的方法,因此HTTP协议就是在网络上传输HTML文本的协议,用于浏览器与服务器的通信
HTTP是客户端和网站服务端请求与响应的标准(TCP),客户端与服务器建立TCP连接后(客户端可以是浏览器、爬虫工具),客户端(浏览器、爬虫等)向服务端发送一个指定端口(默认端口为80)的HTTP请求协议,服务端一定会做出HTTP响应协议
超文本传输协议(HTTP)是一种应用层协议,它是基于TCP(面向有连接)的一种网络协议
HTTP模式:请求(requset)—— 响应(response)模式
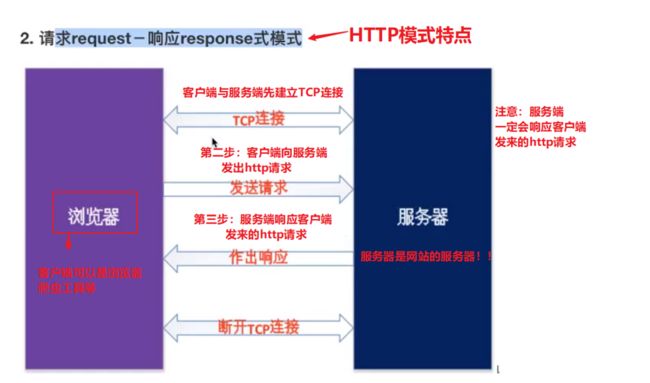
因此,HTTP协议分成了两个部分:请求协议、响应协议
HTTP协议的构成和作用
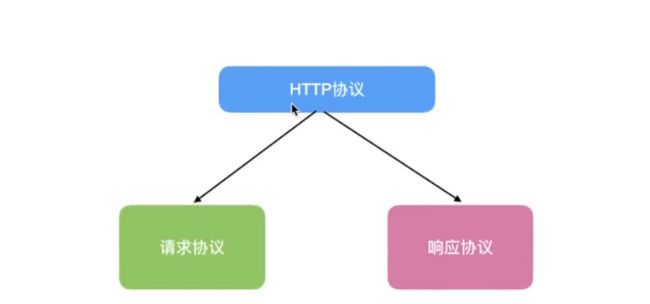
构成:不管是请求协议还是响应协议,都是由一个一个协议项所构成的,协议项形式如下:
协议名:协议内容(值)
例如:Host : www.gaoyang.com
注意事项:每一个协议项都要单独占一行!
通过浏览器查看HTTP协议【重点】
目标:学会使用 Edge 浏览器查看浏览器与百度网站的HTTP协议(请求协议、响应协议)!
Edge浏览器查看HTTP协议(请求协议、响应协议)
第一步:在Edeg浏览器内按下F12进入开发者模式

第二步:点击网络进入

第三步:点击浏览器的刷新后点击www.baidu.com
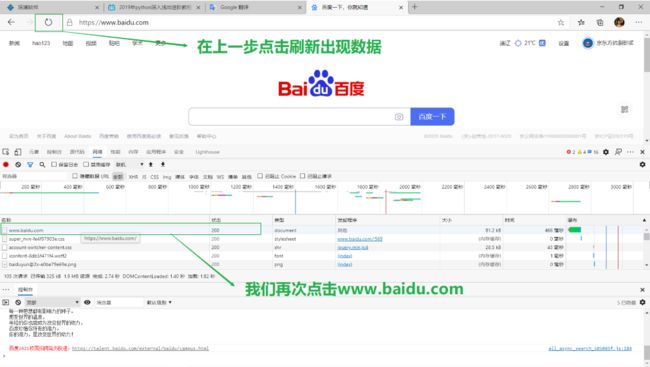
第四步:点击标头,查看请求协议与响应协议
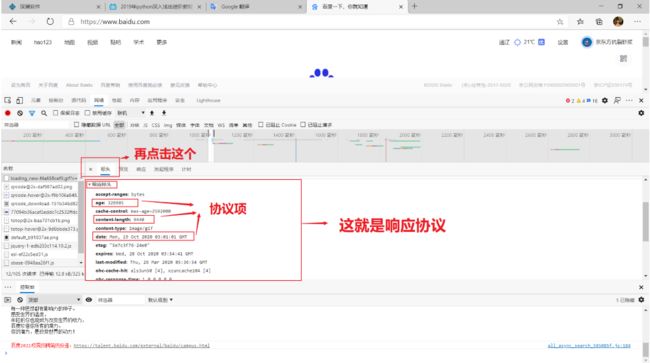
第五步:查看响应协议与请求协议的协议源(服务器发给客户端的原数据,没有被浏览器加工过的)

第六步:协议源(服务器发给客户端没有经过浏览器加工过的数据)截图

HTTP请求协议报文格式【重点】
一:请求协议的报文格式
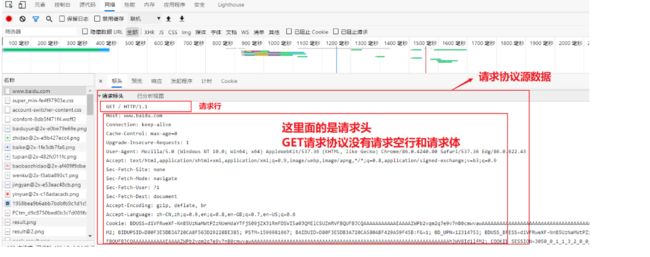
你问我答:在HTTP请求协议中,有两种常用的HTTP请求方式即 GET 模式与 POST 模式,那么它们两个在请求协议报文格式上有什么不同呢?
GET请求方式包含的内容:请求行、请求头、请求空行
POST请求方式包含的内容:请求行、请求头、请求空行、请求体
请求行、请求头、请求空行和请求体的格式与代表的含义及注意事项
请求行:
格式示例:GET / HTTP/1.1
代表含义:其中GET代表请求方式、/ 代表浏览器(客户端)请求访问服务器上资源的路径 、HTTP/1.1是请求协议及版本
注意事项:
1:请求行需要单独占一行,来说明当前请求协议的基本信息
2:浏览器请求服务器的资源路径不包括域名
3:HTTP以前的版本是1.0,现在的版本是1.1
请求头******(很重要)**:

请求空行:用来分隔请求头和请求主体
请求主体:只有请求协议的方式是 POST 的时候,请求协议才有请求主体,请求主体是服务器发给浏览器的HTML数据
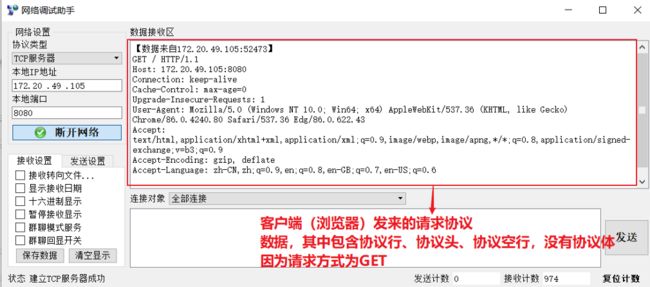
利用网络调试助手充当TCP网站服务器,在利用浏览器(客户端)对这个服务器进行请求协议
注意事项:客户端(浏览器)与网站服务器先要建立TCP连接,客户端才能向服务端发起请求协议
网络调试助手截图

浏览器(客户端)与调试助手建立 TCP 连接后发送请求协议截图

调试助手(服务端)接收到来自客户端的请求协议截图
HTTP响应协议报文格式内容
响应协议
概念:响应协议就是服务器收到客户端的请求协议后返回给浏览器数据的协议
响应协议的报文内容
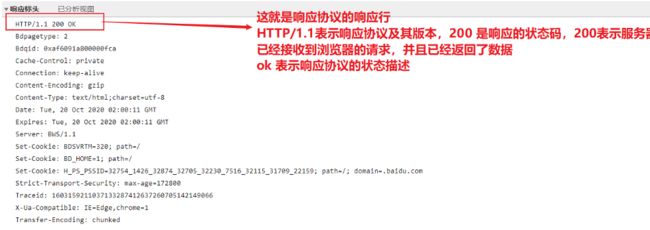
响应行(状态行):
响应行格式:响应的协议及版本 响应状态码 响应状态的描述
响应行示例:HTTP/1.1 200 ok
响应行截图(百度服务器):
状态码的分类及含义

注意事项:响应协议的响应行的状态码和状态码描述是一一对应的
响应头:由一些协议项所构成
响应头格式:协议名:协议值
响应头截图:

响应空行:分隔响应头与响应主体(响应数据)
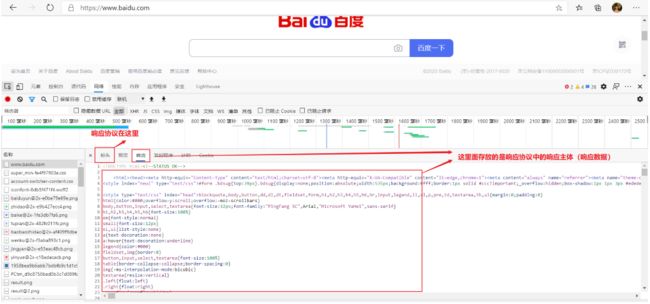
响应体(响应数据):即网站服务器接收到浏览器(客户端)的请求后响应,发送给客户端的HTML数据!
响应协议的响应行的状态码为 404 的含义
答:响应行状态码为 404 代表浏览器请求的服务器页面(服务器资源),在服务器内找不到,即请求的资源在服务器内不存在
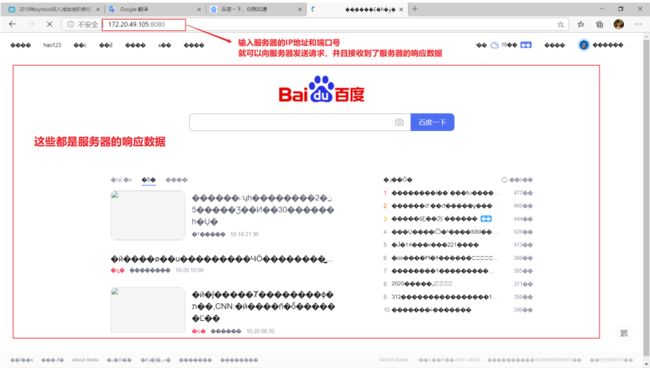
网络调试助手模拟百度服务器向请求的浏览器发送数据(html)
调试助手截图

浏览器(客户端)的截图
长连接与短连接【重点】
长连接与短连接
短连接:在HTTP1.0中,默认使用连接方式是短连接,浏览器与服务器每进行一次HTTP操作,就会建立、关闭一次TCP连接,即传输一个数据就要建立一次连接,两个就是建立两次连接

长连接:在HTTP1.1版本后,默认使用的是长连接,使用长连接的的HTTP协议,在响应头里面会有下面这段代码
Connection : keep—alive

HTTP请求响应的短连接与长连接的优缺点
长连接:长连接可以省去较多的TCP建立、关闭连接的操作,节省时间,并且响应客户端的时间比短连接快很多,但是如果服务器访问人数过多的情况下会造成服务器负载过大而不可用(比如一台服务器同时支持500人访问,且长连接持续时间为10分钟,那么第501个人连接这台服务器,就要等十分钟以内的时间才可以访问即不可用,网站打不开)
短连接:短连接服务器实现起来比较简单,创建的都是有用的TCP连接,但是如果请求服务器的人数过多,就会在短时间内创建大量的连接(因为要建立连接、断开连接),会造成服务器响应客户端速度变慢(网站可以打开,但是速度贼慢,比如说民大选课官网)
总结:
1:一般小型Web网站都采用短连接,因为消耗服务器资源小
2:中大型Web网站一般采用长连接,优点是响应客户端的请求快,用户体验好
3:数据库的连接是长连接,因为短连接会频繁的建立、断开TCP连接,可能会造成socket错误
案例)模拟浏览器(网络调试助手)请求服务器的过程【重点】
利用代码将网站域名解析为IP地址
代码方法:套接字 . connect((“网站域名”,80)) 在 connect()方法底层,会自动将填写的域名解析为IP地址,从而与网站服务器建立 TCP 连接
注意事项:
1:浏览器请求网站服务器的步骤:与网站服务器建立TCP连接→浏览器向服务器发送请求协议→网站服务器响应浏览器发送响应协议→关闭TCP连接
2:在 python 中编写TCP客户端的 connect()方法会自动网站域名解析为IP地址,用来与网站服务端创建TCP连接
3:网站服务器的端口默认为 80
快速代码体验

python 编写代码模拟浏览器(客户端)请求百度服务器的流程
流程:导入socket模块→创建TCP套接字→利用connect()方法与百度网站的服务器创建TCP连接→客户端利用套接字的send()方法向服务端发起请求协议→百度服务器响应客户端的请求协议,客户端利用套接字的recv()方法接收服务器响应协议→利用字符串的切片将响应体从响应协议内分离出来→将响应体(有用文件)保存到文件内→关闭套接字
快速代码体验:
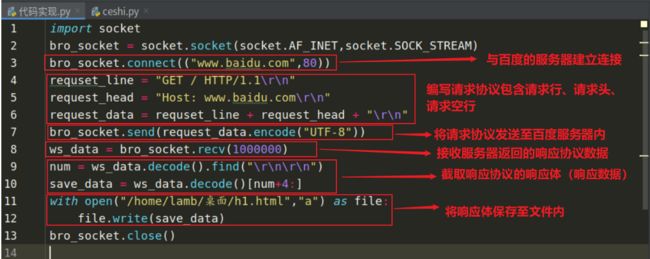
注意事项:
1:截取响应体的时候为什么要查找“\r\n\r\n”呢?因为响应协议中响应体和响应头中间相隔了“\r\n\r\n”,查找出“\r\n\r\n”位置截取字符串即可
2:查找“\r\n\r\n”的时候,原始数据必须是字符串,而不是二进制数据,也就是代码中的 ws_data.decode().find(“\r\n\r\n”),将ws_data二进制数据转为字符串
3:代码模拟浏览器客户端向服务器发送请求协议时,请求行的 HTTP 一定要大写!!!,否则会出现400错误

格式化字符“\r”与“\n”和 “\r\n” 的作用
“\r”:不换行,将光标移动到本行行首
“\n”:换行,但是光标不移动到行首
“ \r\n”:相当于回车,换行并且光标移动至行首
访问网站服务器的固定html文件【重要】
访问网站服务器上的固定文件
访问方法:网站域名/文件名
访问示例:www.baidu.com/a/b/ceshi.html
注意事项:
1:浏览器请求网站服务器(在浏览器上面仅输入网站域名),会自动打开服务器(服务器主机)根目录(Linux)下的 index.html 这个文件,www.baidu.com 与www.baidu.com/index.html 其实是一样的
2:浏览器想要访问服务器上面的其他文件需要在域名后面跟上服务器的文件路径,比如说www.baidu.com/a/b/1.html,就是打开百度服务器中根目录下的a文件夹下b文件夹下的1.html文件
3:因为网站服务器也是计算机,一般操作系统都是Linux,所以访问网站服务器上的固定文件,都是访问这台计算机上面目录下的文件
快速代码体验

字符串的分割——split()
功能:根据某个分隔符将字符串分割成一个列表,假入有n个分割符就有n+1个列表元素
快速代码体验

案例)编写代码模拟Web服务器
网站服务器向浏览器返回固定数据! 黑马程序员 P91
网站服务器向浏览器返回固定页面! 黑马程序员 P92
网站服务器向浏览器返回指定页面! 黑马程序员 P93
面向对象编程实现文件:

注意事项:在创建一个类的时候,在__init__ 方法下面,如果定义的变量在这个类的其他方法内要使用,就要将其变为这个类的实例化属性,即 self.xxxxx ,如果在其他方法内不使用,则不需要变为实例化属性
快速代码体验

网站服务器向浏览器返回指定页面中存在的问题! 黑马程序员 P94
终端启动WEB服务器(python代码)【重点】
在终端中运行 py 文件的两种方法
第一种方法:. /py文件名 方法
运行流程:
1:利用 pycharm 打开 py 文件后在文件代码第一行加上 # ! Python 解释器路径,关闭文件
2:打开终端,利用 cd 指令进入需要运行 py 文件的相对文件路径,利用 chmod u+x 指令将py文件改为可运行
3:在终端输入 ./py文件名 运行文件(必须是./py文件名格式,否则报错)
第二种方法:
1:打开终端,利用 cd 指令进入需要运行 py 文件的相对文件路径,不需要将文件改为可运行文件!
2:在终端输入 python3 py文件名 即可运行(python3为python解释器,可以更改为其他版本)
sys模块的argv方法
功能:获取在终端命令行输入的参数(注意是参数,不是指令),并且返回一个列表传递给运行的py程序
代码格式:list1 = sys . argv
注意事项:
1:argv方法将命令行的参数保存至列表内后,传递给命令行中正在运行的那个程序
2:argv方法没有括号!!
3:命令行参数指的是参数,不是指令
快速代码体验
py代码

终端运行这个文件结果

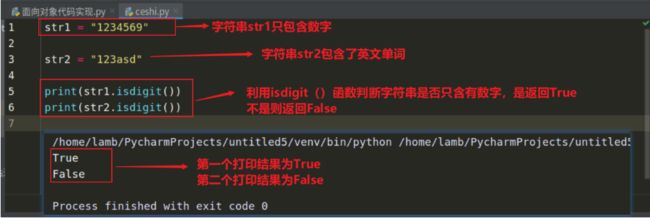
isdigit()函数的作用
功能:判断某个字符串中是否只含有数字,如果只含有数字返回True,含有其他的(字母、单词等)则返回False
使用格式:字符串 . isdight( )
扩展应用:在终端运行web服务器(py文件),用于判断终端命令行输入的端口号是否为纯数字字符串,是则启动服务器,不是则写好的web服务器不启动
快速代码体验
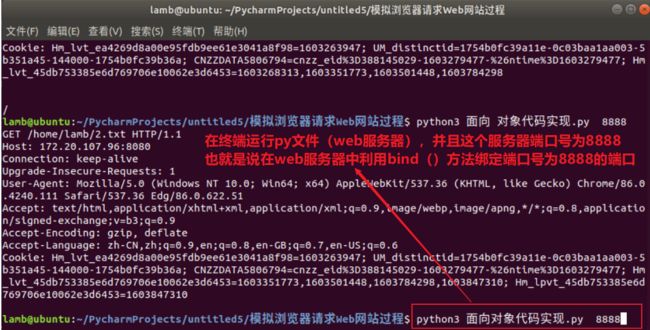
在终端中运行特定端口号的 web 服务器(py程序)
示例:
功能:部署服务器的时候,服务器上面没有 pycharm,这时候我们就要用终端来运行写好的服务器文件了
运行语法格式:python3 py文件 绑定的端口号
注意事项:终端输入的端口号利用sys模块的argv方法传给py文件,服务器从而绑定端口号的时候绑定终端输入的端口号!
快速代码体验
游戏服务器的部署
解决利用py代码书写服务器,向服务器内发布html游戏,浏览器不能成功解析html代码的问题
注意事项:
1:服务器向浏览器发布html游戏就是向浏览器(客户端)发送游戏的html代码(响应体)
2:浏览器不能成功解析html代码的问题就是,没有将游戏的html代码解析为html代码,而是解析为text文本
问题截图:

解决办法:
在服务器的响应头内加上这段代码即可让浏览器优先使用html解析服务器返回的数据,Content-Type:text/html
类的注意事项
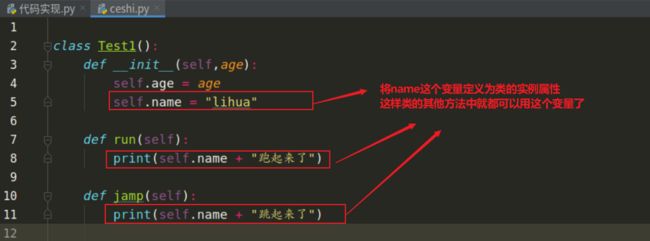
在利用类的时候,类的某个方法中有一个局部变量,但是我们想要这个局部变量在整个类中使用(其他类方法中),那我们就可以将它定义为类的实例属性,即 self . xxx = xxx
快速代码体验
没有将变量修改为实例属性前
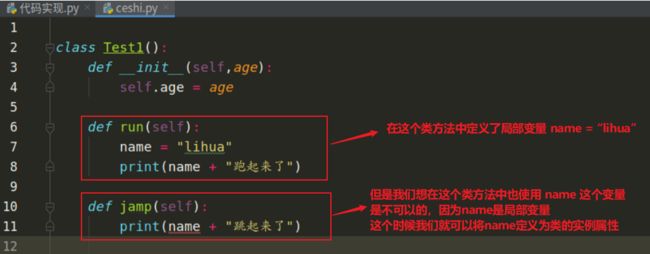
修改为实例属性后
字典的keys()以及列表的enumerate()方法
字典的 keys()函数
功能:将字典中所有的key值保存到一个可迭代对象中(不是列表)
语法:dict1.keys()
快速代码体验

列表、可迭代对象的 enumerate()函数
功能:将列表或者可迭代对象的元素列出来,并且将每个元素的索引和数据保存至元组内后再次保存至可迭代对象中
语法:enumerate(list1,start = 0):
注意事项:
1:start = 0 可以省略,默认下标为 0
2:数据返回的下标值是整形(int)
快速代码体验

未完待续…