【图片】图片处理,图片压缩相关知识分享
今天接到一个任务,要简单把有关图像处理的内容理解一下做成容易理解的形式分享一下,随即给了我一些参考链接1234,后面我做的自然就是首先深入通读这几篇文章,最后总结提炼成文档或者PPT之类的形式进行一下分享,可能中间会有一些部分自成一体,需要另外开一篇博客来讲,届时我会标注好引用,争取做到知识解耦,单一篇博客又易于理解。
文章开始之前,先引用一句Image Worsener产品主页上面,对图片处理相关知识 (就是这篇文章的主题) 的描述,我个人觉得很贴切:
- a.k.a. Things I wish I’d known better when I started this
- 即:一些回头来看会唏嘘:“如果当初好好再弄清楚一点儿就好了!”的知识
文章目录
- 绪论 - 图片格式的介绍
- 绪论2 - 不同图片格式的选择
- 一 - 图片Resample(重采样)&Resize(调节大小)[^7]
-
-
- resize思路
- 色彩概念
- 筛选器
- 扩大和缩小
- 其他步骤及细节说明
-
- Post-processing 后期处理
- Optimization 优化
- Image edges 图片边缘
- Non-integer dimensions 非整数维度
- Clamping “夹紧中间sample”
- Which dimension to resize first? 应该先压缩哪一个维度?
- Fairness 算法对每一个点的作用是否等效?
-
绪论 - 图片格式的介绍
在android官方开发者文档中有一些关于如何压缩你APP中的图片的文档1,全文主要介绍了三种图片格式:JPG,PNG,WebP。有关于这些图片的根本区别,我可能会额外开一篇博客介绍,这里先简单理解一下:
参考博客园的一篇博客5得知:
jpg的优点是它支持百万种色彩。jpg是一种有损压缩的方式,它会放弃图片的某些细节。所以要是对图片质量的要求不是很高,可以采用jpg的保存方式。那么根据jpg的特点总结出:色彩丰富的照片适合jpg的保存方式,不适合小图标,线条的图片。png是20世纪90年代推出的一种图片格式,它采用的是无损压缩。其目的是为了取代gif。png分为png8,png24,png32.这几种主要区别是储存方式不同。png8只有256色,支持透明(要么全透明,要么不透明)。png24颜色很多,但是不支持透明。而在Photoshop中导出的png24实际是png32.png32有8位alpha通道,所以它支持透明度的设置。
webp是谷歌开发的旨在增加图片加载速度的图片格式,它压缩后的大小约为jpg的2/3。但是webp目前只有google39+,safari+等浏览器支持。
不过对于webp,其实那篇博客里面可能还是比较早,实际上按照知乎回答6的说法:
WebP 在各大互联网公司已经使用得很多了,国外的有 Google(自家的东西肯定要用啦,Chrome Store 甚至已全站使用 WebP)、Facebook 和 ebay,国内的有淘宝、腾讯和美团等。

综合下面对于WebP的评价,总结一下基本就是WebP体积最小,不考虑特殊情况的话也不会有严重失真。
最后可以参考6附加的测试,体验一下数据的直观感觉:


绪论2 - 不同图片格式的选择
精读Google的android开发者文档1,里面对于压缩图片的格式选择,总结起来有这么一张图:

具体的可以参考文档,这一块可能我后续丰富的时候会编辑一下,但是目前觉得这些细节不用浪费太多篇幅了。
// todo
一 - 图片Resample(重采样)&Resize(调节大小)7
我们这篇博客的主线就是沿着ImageWorsener的主页 4上面的教程来的,这第一节也是该教程的第一篇。
resize思路

↑↑↑pixels as rectangular regions, and samples as points located at the center of the corresponding pixel (indicated by the blue and green dots).
- 上面这张图片演示了灰度图像8(one sample per pixel,一个像素块内只有一个样本数据)的resize(调节大小)的方式。原文也只给了一张图,没有做任何解释,不过以这张图为理解,大概可以看出想表达的是利用每一个像素中的数据样本的值,和相邻样本做过度,进行平均或其他计算,以达到扩大或者缩小的目的。
而对于二维图片的压缩,也很简单,只要对数据样本里面的每一个参数依次进行上面的resize即可。订正!:这里正确的应该就是说,前面的一维指的是横向图片,这里的二维指的是横竖的二维图片,下面的RGB的问题其实和这里的一二维不是递进关系。- 而一般的彩色图片,(如果是RGB色彩标准),
则就是三维的图片,对Red,Green,Blue三种颜色分别做一次压缩就好了(as if you had three separate images,就好像压缩三张独立的灰度图片一样) - 带有透明度的图片,基本上也是将Alpha管道当作另一个维度,对于RGBA我们选择做四次resize,不过可能伴随一些细节上的特殊处理,后续第三节会说明。Alpha合成的具体只是可以参考wiki中的解释9,在本文暂时只要知道下面两点:1.它除了RGB三条管道又多了一个Alpha作为透明度参数。2.它的原理主要是将图像和背景相结合。
所以整体的压缩思路就是……一维图像直接将样本数值过渡,增加或减少样本数来resize,而多维图像只是对每一个维度进行上述的操作。
色彩概念
进行下面的学习前,为了更加清楚明晰,我们先在一开始之前就简单讨论一下色彩空间和色彩模型的概念10。
(相关概念:色彩空间10,色彩模型10,绝对色彩空间11,色域12,线性色彩空间)
- 色彩空间:是对色彩的组织方式。借助色彩空间和针对物理设备的测试,可以得到色彩的固定模拟和数字表示。色彩空间可以只通过任意挑选一些颜色来定义,比如像彩通系统就只是把一组特定的颜色作为样本,然后给每个颜色定义名字和代码;也可以是基于严谨的数学定义,比如 Adobe RGB、sRGB。色彩空间由色彩模型和色域共同定义。例如Adobe RGB和sRGB都基于RGB颜色模型,但它们是两个不同绝对色彩空间。
- 色彩模型:是一种抽象数学模型,通过一组数字来描述颜色(例如RGB使用三元组、CMYK使用四元组)。如果一个色彩模型与绝对色彩空间没有映射关系,那么它多少都是与特定应用要求几乎没有关系的任意色彩系统。
- 绝对色彩空间:不依赖任何外部因素就可以准确表示颜色的色彩空间。
- 色域:是对一种颜色进行编码的方法,也指一个技术系统能够产生的颜色的总合。
- 线性色彩空间:这一个完全找不到wiki或者百度上的标准答案,但是参考StackOverFlow中的这个回答13,我们可以知道这个所谓线性是说每一个sample中的value和它表示的色彩强度是否是线性关系
筛选器
了解完上述概念之后,我们回到原来的问题——How to resize an image?虽然我们已经将了整体的思路,但是下面我们开始完善细节:
在做resize之前,最好先把你的图片转化到线性色彩空间中去进行数值计算,然后运算结束之后再转化回来。不过对于Alpha信道不能这样做,因为Alpha信道默认就对不透明度进行了一些线性对应,如果随意转化的话可能会出现意料之外的错误。
并且我们会使用一个筛选器(emmmm,原文是Resampling Filters,或者叫过滤器or even滤波器之类的也完全ok~)对图片的数值进行转化。

这是一个比较经典的筛选器,【它的横向每一个单位长度表示一个pixel,纵向对于编程人员无须考虑,只要我们将它标准化,这个筛选器就能够自动压缩或扩大图片了】,满足下面几个性质:
- 标准化过的筛选器满足:
 【若不满足性质1,则会使压缩后的图片更亮或者更暗】
【若不满足性质1,则会使压缩后的图片更亮或者更暗】 - 对于性质1做一点扩展:取任意实数x,都满足:

- 若f(0) = 1 切 f(n) = 0(n是任意非0整数),则:只要新图片和源图片的size相同,则无损。
- 若筛选器沿y轴对称,则resize后图片正常。若筛选器沿着x=x0(x0≠0)直线对称,则resize后图片会左右偏移。要是筛选器根本不对称,那你resize一个对称的图片结果也会变得不对称。
扩大和缩小
先说扩大,扩大比较容易。(这里原文特别难懂,只有这么一段话我看了接近一个小时【也可能是我自己太菜了orz】。总之现在我把它总结成了一种更加清晰的步骤化的形式,希望你能和我一起顺着这个思路,看懂此步骤。)
扩大分为下面几个步骤【可以联系下图去读这个步骤】:

- 先将
源图sample们和目标图sample们,用合适的方法对齐。这个方法是什么呢?就是你想让这个图片存储在什么位置就怎么对齐。此时的源sample是压缩前的图片,而目标sample是还没有存放样本数据的,所以也就不存在图片一说,只是你想怎样存放数据就是怎么样对齐,不要被这里所谓的“对齐”,“合适的方法”这种字眼给吓到了。
- 下面将filter拉抻,横向拉抻成保证一个单位长度(也就是x=0~1这段距离长度)等同于一个原图的一个像素长。至于说Y轴拉抻到多长,原文表示不用在意,不会影响结果。
谁动谁不动,这一点必须要搞清楚。第一步的时候把源sample和目标sample都固定起来了,可以想象它们俩摆在桌面上,但是这时候坐标系还没有出现。现在第二步把坐标系从桌面下面拿上来,因为像素密度不一定相同,所以一像素的绝对长度也不尽相同(对于像素,像素密度等概念如果不清楚的话,可以查看这篇博客14,只要简单读一下第一段就会基本理解了。),也就是说这个坐标系拿上来之后还需要进行拉抻才能确保和原图的一像素完全相同。
- 现在开始正式的resize——对于目标sample中的每一个点【就是上图里面那些绿点的每一个,先别管里面的那个大绿点】,依次进行下面的操作:
读原文的时候就是这里有点没转过来弯影响了很久。这里可以理解成一个循环:类似于
for(Sample s: targetSample){//下面的几个操作},这样的感觉。这是第三大步骤,是一个循环,下面开始讲一下里面的小步骤怎么做。- 移动filter,使它的原点(0,0)和当前所在的这个目标sample(就是刚才那个比喻的for语句中的
s)对齐。在上面这个图的示例中,我们恰好操作到那个绿色的大点的位置。(PS. 演示图里面的filter是一条Catmull-Rom曲线,虽然用什么曲线都不影响这个演示过程就是啦~) - 移动好了你的filter之后,你会发现这个filter大部分的地方都是 y = 0的对吧。所以我们现在只需要考虑 y ≠ 0的区域里面的那些点(也就是上图里面的阴影部分的那些源sample点,样例里面一共有四个符合的点)
The number of source samples that contribute to a target sample will be the same for each target sample (with the possible exception of samples near the edges of the image)
上面这句话我理解了好久,最后明白了,这句话的含义是说,现在按我的文档的比喻不是在一个for(Sample s: targetSample)中嘛,这里是说除了边界情况以外,对于每一个目标sample点,操作时候会起作用的(也就是在阴影中的)数量都是一样的。【当然啦,其实这算一句多余的废话,毕竟源sample点之间x轴方向等距,都是一像素】。 - 然后对阴影当中的全部点取下面这些值的求和(a running total)
norm值:源sample点所在的位置对应的filter曲线的值(之和)val值:源sample点所在位置对应的filter曲线的值,和现在的sample点保存的参数值的乘积,也就是加权值(之和)
- 然后就可以用
val ÷ norm作为这个目标sample点的参数值了。 - (PS:
norm加和的值一般都为1,不过一般还是算一下更清楚简单一些~)
- 移动filter,使它的原点(0,0)和当前所在的这个目标sample(就是刚才那个比喻的for语句中的
好的,至此呢,我们就完成了对图片的resize。不过上面的案例其实实用的卡特莫尔曲线(Catmull-Rom),主要是对图片做抗锯齿化处理还是什么的,总之这里将图片的大小扩大了。下面我们来看一下无损压缩的问题,基本上差不多,只是有一点稍微复杂了一丢丢~:
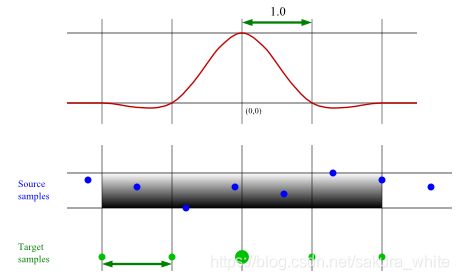
上述的第2大步(下面将filter拉抻,横向拉抻成保证一个单位长度…)那里,如果是为了压缩图片的时候,要注意这里要把filter横向拉抻成保证它的一个单位长度恰好符合目标sample的一个单位长度那么长(而不是对应源sample了)。导致,压缩的时候,通常,作用于一个目标sample时候的相关源sample数量都是不一样的了。
conclusion:无论压缩还是扩大,通常你都是要把filter调节成一像素更大的那个sample的长度。
<注意>:上图扩大时候的相关源sample点,可以看成是5个也可以看成是6个。但是最右面那个边界的点因为对应的filter的值恰好为0所以考虑不考虑都不要紧了。只是对于很多非连续性的过滤器(比如box-filter)这种情况还挺麻烦的,不过麻烦事儿一般都丢给设计filter的大佬啦,我们好像暂时不用很考虑、、、
其他步骤及细节说明
Post-processing 后期处理
一般图片被压缩之后,因为变得粗糙了,为了防止这种粗糙,一般都会进行锐化处理(使用sharpening filter,这个filter这一节暂时不讨论)。这一个操作其实值得商榷,这里只是提及一下——这个操作的核心目的是为了认为的强调照片中的物体边界,这样的话如果这张压缩的图片被用来当很小的小图标那会看起来很好,除此之外的情况虽然不能说很差,但是也值得深思再选择要不要这样做——毕竟得到的好处是,可以让这张压缩过的图片第一眼看过去,感觉不错~但是是以一定程度的失真为代价的。
It does tend to make images look better at first glance, but at the expense of realism.
Optimization 优化
这里的优化指的是这个算法的实现速度。就是直接跑一下上述步骤可能得跑很久,但是你想啊,你resize的时候那个加权值经常是都一样的,只是要加的是哪几个的问题,类似的可以存储一些变量用来提高压缩速度,减少乘法次数(众所周知乘法消耗 >> 加法消耗)。当然现在只是简单介绍压缩流程,你只要知道这个优化的整体思路好了,如果后续有需要我可能会专门开一个博客讲这一块(看大家的反应和我的理解力了orz)
Image edges 图片边缘
处理到图片边缘的时候,很多filter中不为0的地方本来下面应该有用来操作的源sample点的,可是因为到了图片边缘就找不到了,应该怎么办呢?这里主要提供了两种策略,第一种叫 standard method标准方法(原文作者说这是因为他想不到怎么起名了2333333),第二种叫virtual pixels虚拟像素法:
-
standard method标准方法
说实话这个方法几乎可以说什么都没做,按上面的图来看,如果平均每个点需要4个加权值来算,那么其实就算到了图片边缘你也最多有2~3个加权值取不到,正常这个范围其实是很小的。
正常情况下,不会有图形太尖锐的筛选器,一般都是很圆滑的,值都在-1~1之间,通常情况下,源sample点都是够用的。【我怎么感觉这里一点都不巧妙的逃避了一个问题????】
但是还有一种情况必须要特殊解决——等大的图片的话,就是说源sample和目标sample的1像素长度正好相同,这时候一旦你的图形变化有一点点的对于图片的位移或者是扩大,那源sample就不够用啦【这好像和图片压缩的事情关系不大诶…】
总之,原文的作者认为,可能每一种压缩的实现,都有他们自己独特的处理方式——比如可以在这个目标sample点附近的源sample点不是很够的时候,直接把源sample点copy过去。可是他说,他搞不清楚这个不是很够究竟是怎么去明确定义的。 -
virtual pixels虚拟像素法
这个方法的核心思想就是把那些在屏幕外面没有sample点的地方弄一些虚假的点放进去。- 其中一个策略就是复制。把边缘的点复制到屏幕外。风险是这样做会使得边缘点的权重变得很大。
- 还有的是在那些屏幕外的点使用预设的颜色(黑呀白呀灰呀什么的,甚至可以设置成透明)
- 利用周围一两个像素的内容推断出屏幕外的那个点的情况(这种状况下切记千万不要忘记考虑极小,比如1~2px大小的图片的情况)
- 当且仅当图片要使用平铺方法的时候,你可以把另一个边缘折叠过来当成是屏幕外的点。
Non-integer dimensions 非整数维度
The dimensions of the source image are by definition an integral number of pixels, but it’s easy to overlook the fact that this is not really the case for the target image. By that, I mean that if you want to reduce a 99-pixel row to half that size, you don’t have to round it and change the image features’ size by a factor of 50/99. There’s nothing stopping you from changing them by a factor of exactly 0.5 (49.5/99). Assuming you then use 50 pixels to store the resized row, the outermost pixels would not be as well-defined as usual; refer to the Image edges section above.
Don’t think of resampling an image as simply changing the number of pixels. Sometimes that is what you want. But in general, think of it as painting a resized image onto a canvas, where the canvas could be larger, smaller, or the same size as the resized image.
Clamping “夹紧中间sample”
有的filter可能会让图片更亮或者更暗。不要觉得这是小事儿,因为有时候这个更亮或者更暗的值甚至可能超过了你能保存和识别的色度范围。具体可以参考这个原文15
Which dimension to resize first? 应该先压缩哪一个维度?
- 首先,不管你先压缩哪一个维度,其实对你的压缩速度,要进行的运算数量,还有图片的质量都没啥大关系。
- 其次,如果你的filter包含了负值,而且你像上一部分说的一样使用了“clamping中间sample”15的方法,那么先压哪一个维度就会造成一些结果上的不同,不过一般也不会有某一种比另外的顺序用起来更好的说法。
- 然后,如果你要压缩的图片是要写入文件保存的话,还是推荐你先一列列压(vertical dimension first),再一行行压,这样你最后完成的时候恰好是一行一行文件写入的。
- 要是你想看看大部分人是怎么压的话,我从经验来看,可以告诉你,大部分人还是先压了horizontal dimension,正好和上一点说的相反。
- 最后,如果压缩效率和压缩损耗是你最在意的事情的话,那你就得了解一下CPU的运作了。离得近的sample点数据算的也更快一点。一般情况下你的图片的每一行的所有sample在内存中的位置会更近一些,也就是说horizontal resize跑起来会更快,像是下面的引用所说:
so you should try to minimize the amount of work done by the vertical resize. If you are reducing the image, resize it horizontally first. If you are enlarging the image, resize it vertically first. 如果你要压缩图片,就先一行一行来,如果你是想要扩大图片(细化操作之类的),你就先一列一列来。
Fairness 算法对每一个点的作用是否等效?
参考这篇文章——“Resampling Filters and Fairness”16,可以知道一般情况下是不等效的,通常是有些点作用得多,有些点作用得少。
https://developer.android.com/topic/performance/network-xfer ↩︎ ↩︎ ↩︎
https://medium.com/@duhroach/reducing-png-file-size-8473480d0476 ↩︎
https://medium.com/@duhroach/smaller-pngs-and-android-s-aapt-tool-4ce38a24019d ↩︎
http://entropymine.com/imageworsener/ ↩︎ ↩︎
https://www.cnblogs.com/alichengyin/p/4638629.html?tvd ↩︎
https://www.zhihu.com/question/27201061, https://isparta.github.io/compare-webp/index_a.html#12, https://isparta.github.io/compare-webp/index.html#12345 ↩︎ ↩︎
http://entropymine.com/imageworsener/resample/ ↩︎
https://en.wikipedia.org/wiki/Grayscale ↩︎
https://zh.wikipedia.org/wiki/Alpha合成 ↩︎
https://zh.wikipedia.org/wiki/色彩空間 ↩︎ ↩︎ ↩︎
https://zh.wikipedia.org/wiki/绝对色彩空间 ↩︎
https://zh.wikipedia.org/wiki/色域 ↩︎
https://stackoverflow.com/a/12894053/9555577 ↩︎
https://www.cnblogs.com/biglucky/p/4128362.html ↩︎
http://entropymine.com/imageworsener/clamp-int/ ↩︎ ↩︎
http://entropymine.com/imageworsener/filterfairness/ ↩︎