python爬取招聘,Flask、Echarts数据展示案例分享
今天分享一下用python爬取51job智联招聘网站的学习研究成果,招聘网站扒一扒,你才知道干点啥,看看不同行业薪资水平究竟咋样。
51job网站数据抓取有一定难度,相比上一期分享的豆瓣电影网站上了一些反爬技术手段,岗位的链接地址不在html标签里,藏在了js的变量中,不能直接通过解析网页来获得。
今天主要分享用python爬取智联招聘网站的六个城市(北京、上海、广州、深圳、武汉、成都)、六个岗位(人工智能、大数据、图像处理、java、python、机械工程师)的薪资待遇等数据信息,并用SQLite数据库保存数据,用Flask框架、Echarts模块进行数据分析与展示。
一、构造URL地址
1.构造搜索页地址:
打开网站首页,https://www.51job.com/,在搜索框输入python,城市选择北京,转到以下搜索结果网页:
https://search.51job.com/list/010000,000000,0000,00,9,99,python,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
把上述地址?及以后的内容删掉,你会发现搜索结果页面没啥变化。Ok,我们就以此为基准分析网页地址的构造方法。

当我们搜索python时,链接地址里就有python字段,说明这是一个岗位字段,当我们输入人工智能时,岗位字段变成了一个奇怪的东西:
https://search.51job.com/list/010000,000000,0000,00,9,99,%25E4%25BA%25BA%25E5%25B7%25A5%25E6%2599%25BA%25E8%2583%25BD,2,1.html
这个字段是个什么鬼?这是对中文进行编码之后的结果,我们可以通过urllib库的parse.quote()命令进行编码转换,构造出相同的岗位字段。
一个搜索页面只有50个岗位,点击下一页,发现链接地址里的2,1变成了2,2,ok,页面地址的变化规律也找到了,这样我们想抓多少岗位就抓多少了。
再就是城市的不同导致的链接地址的变化,可以选择不同的城市搜索,你会发现城市的不同对应着0100这四位的变化,找几个城市,找出对应的四位代码,构造搜索页地址时,将不同的城市代码替换即可。
2.提取详情页地址:
查看网页源代码,查看搜索网页的元素结构和内容,发现岗位信息都不在网页的元素里面,随便搜索一个岗位名称,发现岗位信息都藏在JavaScript的window.__SEARCH_RESULT__变量里,ok,我们只要通过正则表达式,就可以找到相应岗位的详情页地址了。
def get_link(html):
links_in_page = []
pat = 'window.__SEARCH_RESULT__ = (.*?)'
r1 = re.findall(pat, html)[0]
r2 = json.loads(r1)
engine_search_result = r2['engine_search_result']
for item in engine_search_result:
links_in_page.append(item['job_href'])
return links_in_page
二、提取数据
岗位信息都在详情页的源代码里面,结构不太复杂,我们可以直接用XPATH进行解析。
res = etree.HTML(html)
title = res.xpath('//div[@class="tHeader tHjob"]//h1/@title')
company = res.xpath('//div[@class="tHeader tHjob"]//a[@class="catn"]/text()')[0]
info = res.xpath('//div[@class="tHeader tHjob"]//p[@class="msg ltype"]/text()')
area = info[0].strip()
data.append(area)
temp = ''.join(info)
experience = re.findall('(\d.*?)经验', temp)
education = re.findall('大专|本科|硕士|博士', temp)
jobnum = re.findall('招(.*?)人', temp)
releasetime = re.findall('(\d*-\d*)发布', temp)
salary = res.xpath('//div[@class="tHeader tHjob"]//strong/text()')
这里面有几个坑要注意规避:
1.提取详情页的时候,经常会无缘无故提取到广告页地址,可能是一种反爬机制吧,在连续爬取时,检测一下,直接跳过即可。这是在程序反复出错中断后才总结出来的。
2.有些信息是缺失的,比如工作经验、学历、工资等,提取不到的话,列表就会超出索引范围而报错。
3.职位信息所在的网页结构不完全一致,要找到多种提取规则。另外,职位信息里包含很多冒号,这玩意在保存数据库的时候非常容易出错,我最终放弃了提取保存职位信息,实在要提取的,建议先把冒号全都去掉。
由于抓取的数据太多,上述各种坑一定要注意规避,要不然又得重新来过。
三、数据展示
保存数据库就不过多介绍了,感兴趣的可以看我以前的文章。重点介绍一下数据展示。
此番爬取了六个城市六个工作,每个工作100条招聘岗位,共3600条数据。采用Flask框架搭建了一个简易的网站,在前端用Echarts模块里的不同图表进行了数据展示。
1.堆叠折线图
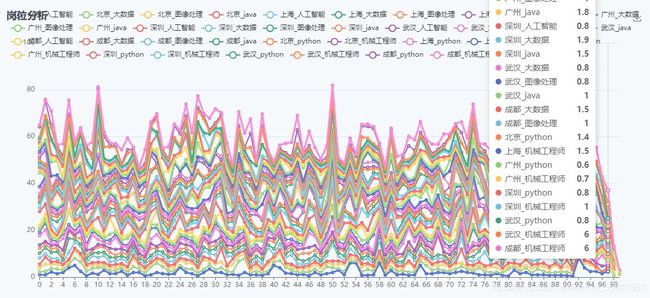
2.堆叠柱状图
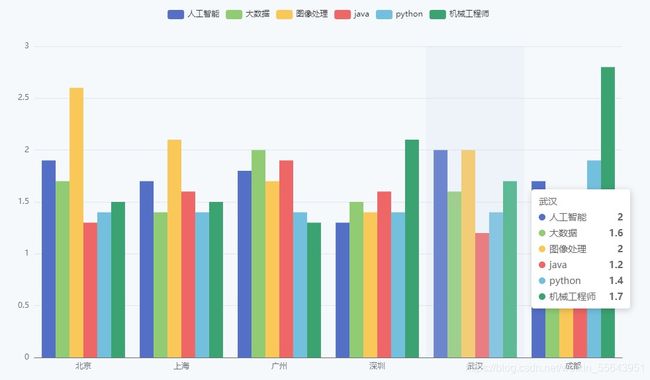
原本以为机械是天坑专业,没想到工资还挺高,入了坑的同志还是好好干吧,还是有前途。
3.可滚动饼图

四、小结
多扒一扒招聘网站,掌握一下行业动态,用数据来检验自己的认知,用认知来调整方向,用行动来贯彻方向。
这是python爬虫进阶一点的内容,篇幅有限,发送请求、保存数据、数据展示、错误处理等很多技术细节没法详述,刚开始学,水平有限,喜欢的朋友可以关注头条号和wei信公众号交流。